Take Baidu-Discover Colorful World as an Example
1. First thing to do is to analyze the website
Enter the Baidu Pictures website page as follows:
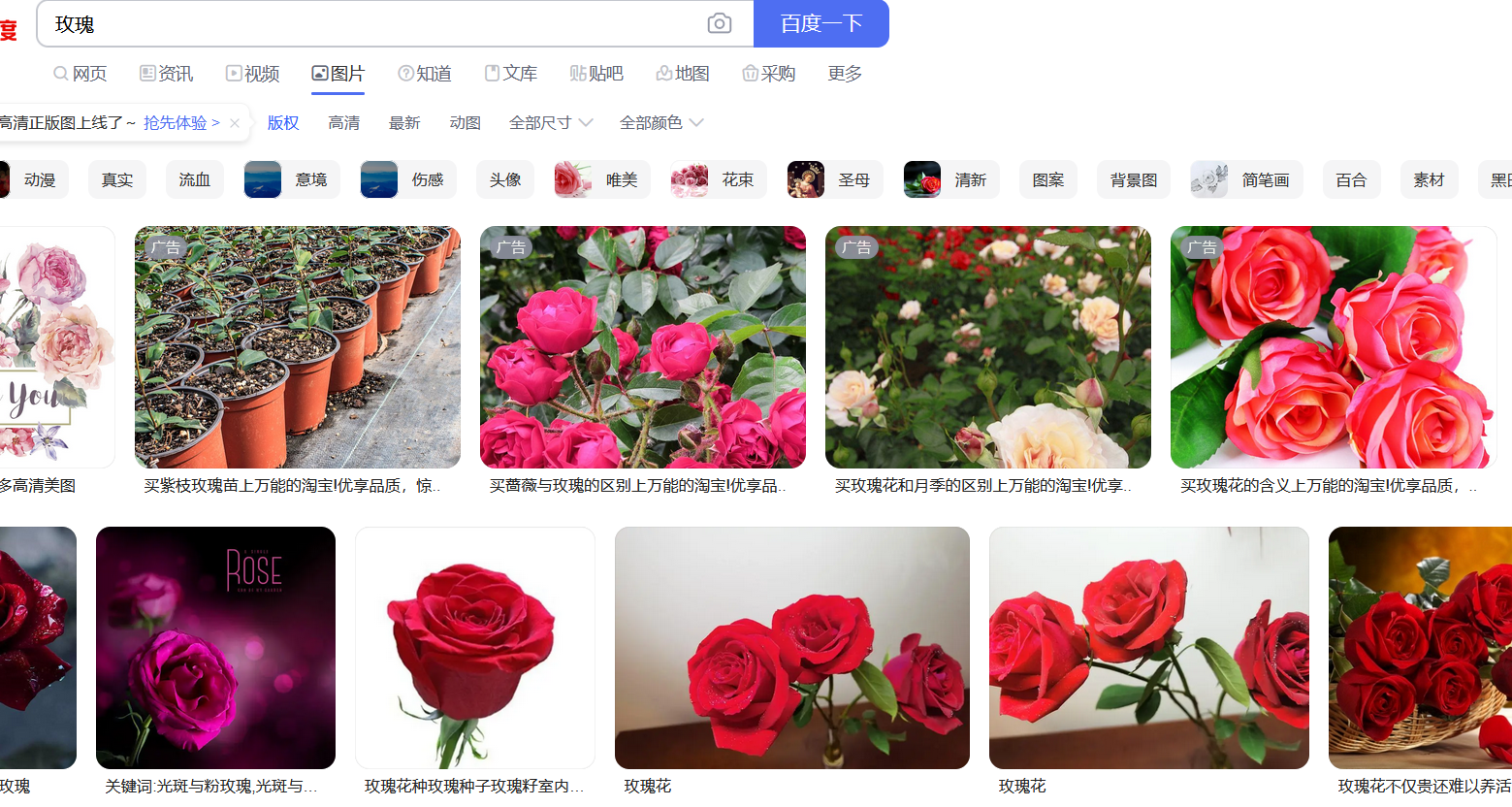
You can see that the pictures we want to crawl appear in the picture and we can download them directly, but is it too time-consuming to download one by one? So let's F12 into the developer options.
As follows:
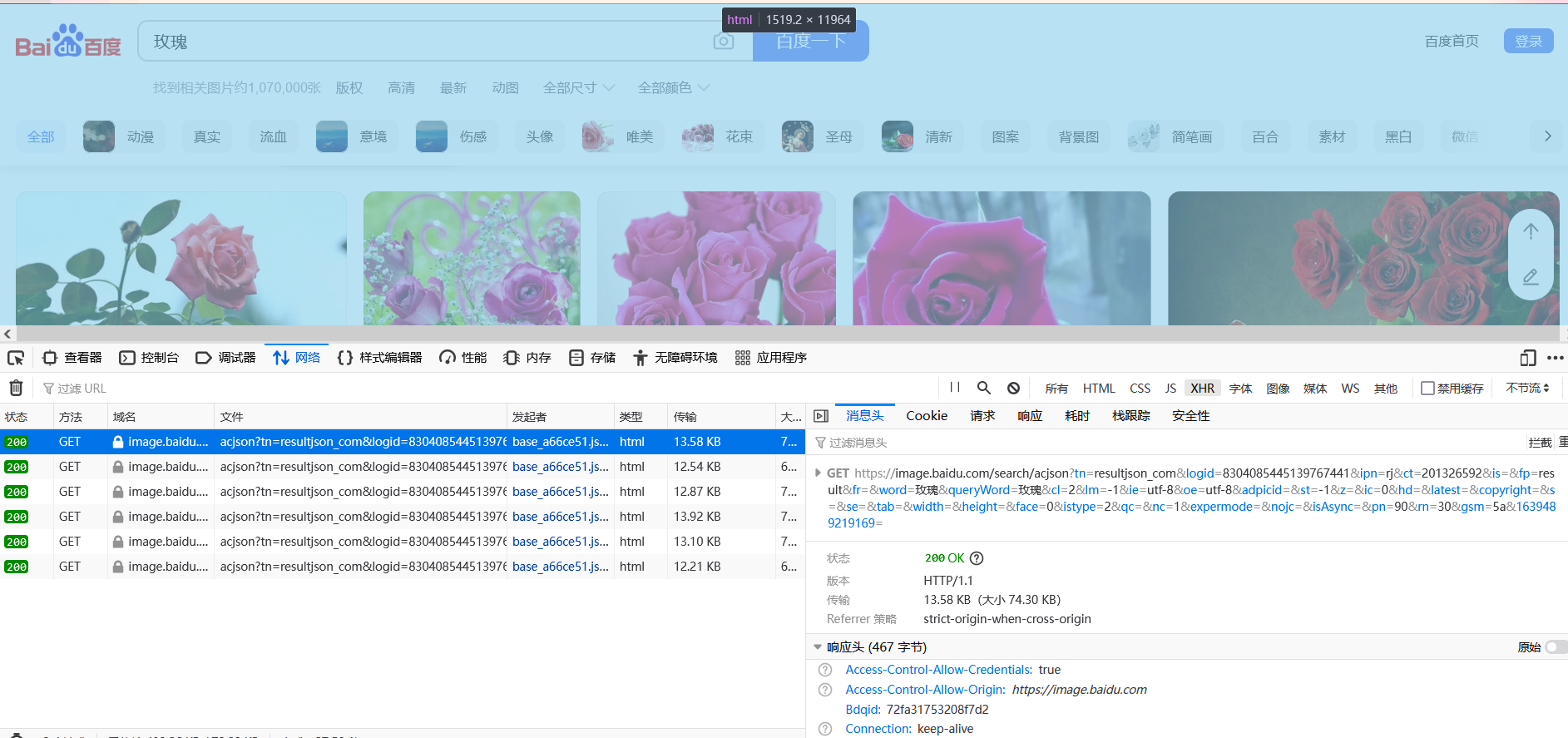
2. Knock Code
1. Get headers
In order for websites to think that our crawlers are visiting websites artificially. We need to get the headers and use them to simulate human-made visits to websites to prevent websites from giving our IP s down and causing us to lose access to websites.
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0X-Requested-WithXMLHttpRequest=9'}2. Get Web Page URL
After analysis, we want to visit the initial page of the web page, then find the url of the target page in the initial interface, then visit the target page, and locate the specific picture link in the page, then we can download the picture
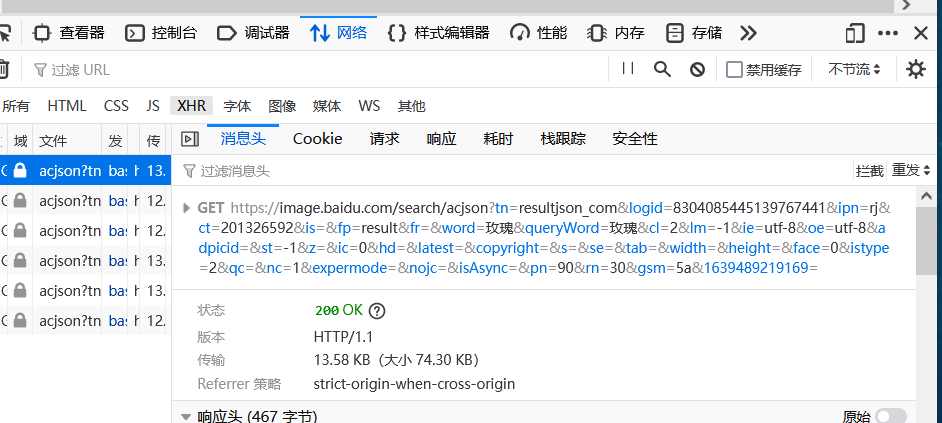
The string following the GET in the screenshot is our crucial URL, which we get.
3. Get the source code of the web page
Once we get the url of the page, we can try to get the source code of the page
Let's try to get the source code of the web page first:
import requests #Import Module
url = ' https://Image. Baidu. Com/search/acjson? Tn=resultjson_ Com&logid=8304080854454513979767441&ipn=8304084513979767441&ipn=rj&ct=201326592&is=&fp=result&fr=&word=rose&word=rose&queryWord=rose&cl=rose&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&utf-8&adpicid=&st=&st=-1&z=&ic=&ic=&0&hd=&latest=©right=&s=&tab=&height=&width=&width=&&&istype=2&qc=&qypypypype=&face=&expermode=&experm=nojc=&isAsync=&pn=90&rn=30&gsm=5a&1639489219169='
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0X-Requested-WithXMLHttpRequest=9'}
response=requests.get(url,headers=headers)#Visit Web Page
html=response.text
print(html)
Output result is Web page source code
3. Get links to pictures
We locate the target page and get links to pictures
#Crawl Pictures
from requests_html import HTMLSession
import requests#Request impersonation post get
import urllib
import json
from bs4 import BeautifulSoup#Parse Library
from PIL import Image
#1 First simulated request GET request gets several required parameters
session = requests.session()#To keep all sessions in your code uniform (session control)
url = """https://Image. Baidu. Com/search/acjson? Tn=resultjson_ Com&logid=8304080854454513979767441&ipn=8304084513979767441&ipn=rj&ct=201326592&is=&fp=result&fr=&word=rose&word=rose&queryWord=rose&cl=rose&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&utf-8&adpicid=&st=&st=-1&z=&ic=&ic=&0&hd=&latest=©right=&s=&tab=&height=&width=&width=&&&istype=2&qc=&qypypypype=&face=&expermode=&experm=nojc=&isAsync=&pn=90&rn=30&gsm=5a&1639489219169=""
headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36 Edg/96.0.1054.43'}
res = requests.get(url,headers=headers)#Get to Get Web Page Data
#print(res.text)#Output Page Link
jsonInfo = json.loads(res.text)#Decode using json
for index in range(30):
print(jsonInfo['data'][index]['thumbURL'])
#soup = BeautifulSoup(res.text,'html.parser')#Resolve with html parser
#print(soup.select('img'))
Once we get a link to a web page, we can access the corresponding picture through the link to the web page we get
The output is a link to a web page
https://img0.baidu.com/it/u=3790394977,1650517858&fm=26&fmt=auto https://img1.baidu.com/it/u=1929383178,891687862&fm=26&fmt=auto https://img0.baidu.com/it/u=82069894,371572825&fm=26&fmt=auto https://img1.baidu.com/it/u=3143784284,2910826804&fm=26&fmt=auto
Copy the web page and link to the browser. We can get the following results:
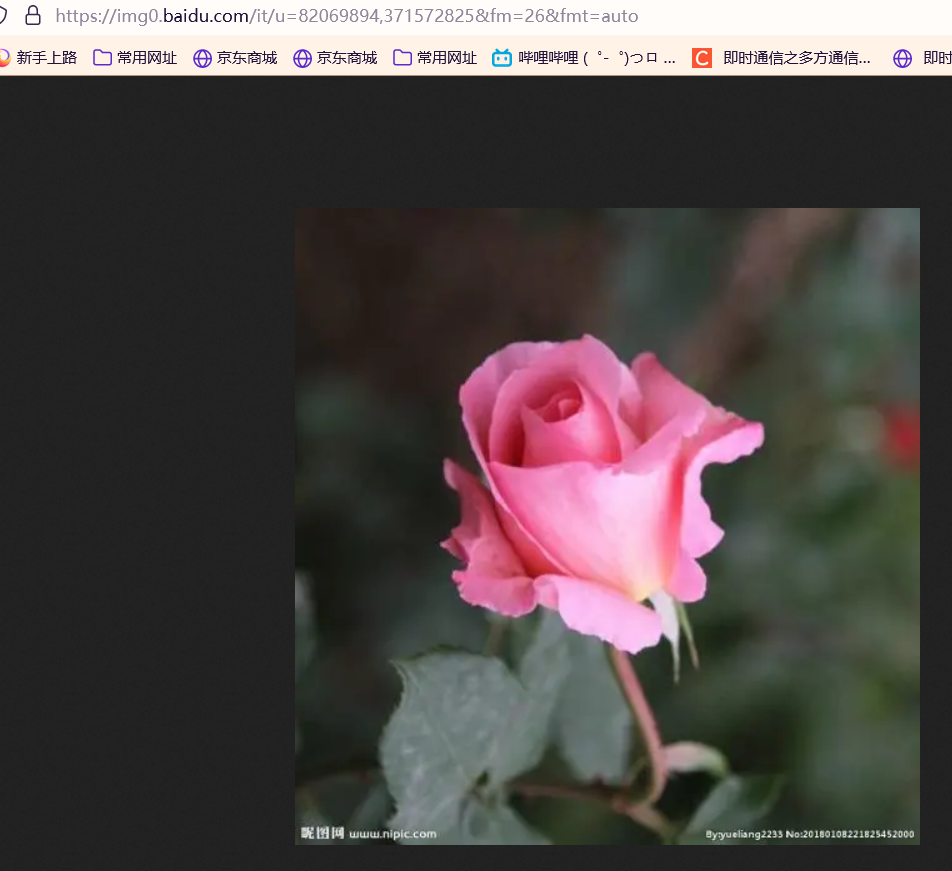
Of course, to achieve this, it's crucial that we choose Get, URL,
After the above analysis, our programming ideas will be clear
Now we can program
The overall code is as follows:
#Crawl Pictures
import requests#Simulate Request
import json#Lightweight data exchange format for easy reading and writing
from urllib import parse #Parsing, merging, encoding, decoding for URLs
import os#Module for manipulating files
import time#Time Module
class BaiduImageSpider(object):#Create a class
def __init__(self):
self.directory = r"H:\Python\Crawler Code\First crawl\images{}" # Storage Directory You need to modify the directory you want to save here {} Don't lose it
self.json_count = 0 # Number of json files requested (one json file contains 30 image files)
self.url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&logid=5179920884740494226&ipn=rj&ct' \
'=201326592&is=&fp=result&queryWord={' \
'}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word={' \
'}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&nojc=&pn={' \
'}&rn=30&gsm=1e&1635054081427= '
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.30 '
}
# Get Image Links
def get_image_link(self, url):
list_image_link = []#Create a list of images
strhtml = requests.get(url, headers=self.header) # Get to Get Web Page Data
jsonInfo = json.loads(strhtml.text)#json.loads decodes the encoded JSON string into a Python object
#Links to get images are saved in the list
for index in range(30):
#Put data from jsonInfo in the list
list_image_link.append(jsonInfo['data'][index]['thumbURL'])#Add a new object at the end of the list and place a link to the image in the list
return list_image_link
# Create Storage Folder
def create_directory(self, name):
self.directory = self.directory.format(name)#Complete Folder Name
# Create if directory does not exist
if not os.path.exists(self.directory):#If there is no path
os.makedirs(self.directory)#Create the directory using the os module
self.directory += r'\{}'
# Download Pictures
def save_image(self, img_link, filename):
#img_link is a link to an image
res = requests.get(img_link, headers=self.header)#Simulate get request to return information res object
if res.status_code == 404:
print(f"picture{img_link}Download error------->")
with open(filename, "wb") as f:#Overwrite Write Files in Binary Form
f.write(res.content)#content in requests module returns binary data
print("Storage path:" + filename)#Print Storage Path
# Entry function
def run(self):
name = input("Pictures you want:")
searchName_parse = parse.quote(name) # Encoding Converts Chinese to url encoding format
self.create_directory(name)#Call the function to create a folder to create a file based on the query
pic_number = 0 # Number of images
for index in range(self.json_count):
pn = (index+1)*30#pn represents a set of files, a set of 30 image contents
#Image web page links are mostly the same, different url codes (serrchName_parse) are entered, and different image types are obtained
#Get new links from different url codes
request_url = self.url.format(searchName_parse, searchName_parse, str(pn))
#The str() function takes an integer as a string, keeping it consistent with the string types on both sides
list_image_link = self.get_image_link(request_url)#Call the Image Link function with a new url to get a new image link
for link in list_image_link:
pic_number += 1
self.save_image(link, self.directory.format(str(pic_number)+'.jpg'))
time.sleep(0.2) # Hibernate for 0.2 seconds to prevent ip blocking
print(name+"Image download successful")
print("Picture storage{}".format(self.directory))
if __name__ == '__main__':#Code as a module does not run the entire script directly when called by other files
spider = BaiduImageSpider()
spider.json_count = 1 # Download a set of 30 pictures by default
spider.run()