Python handles json and dict data
The difference between json and dict
python's dict is a data structure, and json is a data transfer format. json is a pure string written according to a certain agreed format and does not have any characteristics of data structure. The string representation rules of python's dict look similar to json, but dict itself is a complete data structure and implements all its own algorithms.
The key of Python dict can be any hash object, and json can only be a string. It is similar in form, but json is plain text and cannot be operated directly.
json format requires that you must and can only use double quotation marks as the boundary symbol of key or value, not single quotation marks, and "key" must use boundary characters (double quotation marks), but dict doesn't matter.
python's dict Key is unique, while json's Key can be repeated.
python's dict can nest tuples, and JSON has only array.
Conversion method of json and dict in python
json data processing in python:
1. Serialization: dic object ➡ json string (storage, transmission) encoding
2. Deserialization: json ➡ dic (analysis, processing) decoding
import json json.loads() # Convert json data into dict data json.dumps() # Convert dict data into json data json.load() # Read the json file data and convert it into dict data json.dump() # Convert the dict data into json data and write it to the json file
python read / write json
Read the json file and convert it to dict
with open('.../XXX.json','r') as f:
data= json.load(f)
Or:
data = json.load(open('.../XXX.json','r'))
Convert the dict data into json and write it to the json file
with open('json_data.txt','w+') as f:
json.dump(dict_data,f)
python processing dict data
Take key, value and key value pair
# The dictionary only outputs key by default in the for iteration
for k in dict_data:
print(k)
# Iterative output key
for k in dict_data.keys():
print(k)
# Iterative output value
for v in dict_data.values():
print(v)
# Iterative output key value pair
for k,v in dict_data.items():
print(k,v)
Addition, deletion and modification of dict:
# Add a key value pair:
dd['new_key'] = 'XXX'
# Change key value
dd['key'] = 'XX'
# Delete key value pair
del['key'] # Delete key value pairs at the first level of the dictionary
del['key1']['key2']['key3'] # Delete key value pairs in multi-level nesting
dd.pop('key') # Delete the key value pair and return the corresponding value
# Determine whether it is in dictionary format
isinstance(data,dict)
Get key value pairs of multi-level nested dict:
def get_all_dict(data):
if isinstance(data,dict):
for x in range(len(data)):
temp_key = list(data.keys())[x]
temp_value = data[temp_key]
print('KEY --> {}\nVALUE --> {}'.format(temp_key,temp_value))
print('\t')
get_all_dict(temp_value) # Iterative output results
Compare the differences between the two dictionaries
dict1 = {'a':1,'b':2,'c':3,'d':4}
dict2 = {'a':1,'b':2,'c':5,'e':6}
differ = set(dict1.items()) ^ set(dict2.items())
print(differ)
#All differences
#Output: {('c ', 3), (E', 6), (C ', 5), (d', 4)}
diff = dict1.keys() & dict2
diff_vals = [(k, dict1[k], dict2[k]) for k in diff if dict1[k] != dict2[k]]
print(diff_vals)
#Same key, different value
#Output: [('c', 3, 5)]
Other references
a = {
"x":1,
"y":2,
"z":3
}
b = {
"x":1,
"w":11,
"z":12
}
print(a.items())
>>>dict_items([('x', 1), ('y', 2), ('z', 3)])
# View key s shared by two dictionaries
print(a.keys() & b.keys())
>>>{'x', 'z'}
# View the key s that dictionary a and dictionary b do not share
print(a.keys() ^ b.keys())
>>>{'y'}
# Check the key in dictionary a but not in dictionary b
print(a.keys() - b.keys())
>>>{('x', 1)}
# View the same key value pairs of dictionary a and dictionary b
print(a.items() & b.items())
>>>{'w', 'y'}
Replace None with null in json
import json
d = {"name":None}
s = json.dumps(d)
s = s.replace('null', '\"null\"')
d = json.loads(s)
print(d)
>> {'name':'null'}
Other instructions:
In pandas, if other data types are numeric, pandas will automatically replace None with NaN, and even invalidate the effects of s[s.isnull()]= None and s.replace(NaN, None) operations. In this case, you need to use the where function to replace.
None can be directly imported into the database as a null value, and errors will be reported when importing data containing NaN.
Many functions of numpy and pandas can handle NaN, but they will report an error if they encounter None.
Neither None nor NaN can be processed by the group by function of pandas. Groups containing None or NaN will be ignored.
In short, None comes with python, while NaN is supported by numpy and pandas
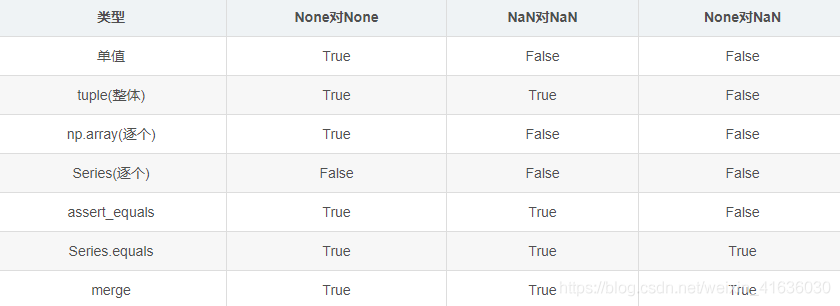
Summary of equivalence comparison: (True indicates that it is determined to be equal)
Convert the key in the dictionary list from str to float
trip[0]:
{'pickup_latitude': '40.64499',
'pickup_longitude': '-73.78115',
'trip_distance': '18.38'}
Treatment method:
for list_dict in list_of_dicts:
for key, value in list_dict.items():
list_dict[key] = float(value)
Traversal inserts a dictionary (dic) into a list
nid = "1,2"
print(nid.split(','))
datas = []
for i in nid.split(','):
mydict = {}
mydict["id"] = str(i)
mydict["checked"] = True
datas.append(mydict)
print(str(datas))
Output:
['1', '2']
[{'id': '1', 'checked': True}, {'id': '2', 'checked': True}]
The sql statement counts the number of non empty columns per row
--empty
select id , num =
(case when col1 is null then 1 else 0 end) +
(case when col2 is null then 1 else 0 end) +
(case when col3 is null then 1 else 0 end) +
(case when col4 is null then 1 else 0 end)
from tb
--Non empty
select id , num =
(case when col1 is not null then 1 else 0 end) +
(case when col2 is not null then 1 else 0 end) +
(case when col3 is not null then 1 else 0 end) +
(case when col4 is not null then 1 else 0 end)
from tb
The table that generates the most non empty columns in the project
select id , case when filed !='' then 1 else 0 end as num from ods_crd_ddt_external_dev.vira_ft_ods_issue_s3_di_pt vfoisdp order by num desc limit 10
Convert two lists into Dictionaries
>>> keys = ['a', 'b', 'c']
>>> values = [1, 2, 3]
>>> dictionary = dict(zip(keys, values))
>>> print(dictionary)
{'a': 1, 'b': 2, 'c': 3}
There is no zip writing
l1 = [1,2,3,4,5]
l2 = ['a','b','c','d','e']
d1 = {}
for l1_ in l1:
for l2_ in l2:
d1[l1_] = l2_
l2.remove(l2_)
break
print (d1)
{1: 'd', 2: 'b', 3: 'e', 4: 'a', 5: 'c'}
Take the dict key to form a list
students = {
'Small armour':18,
'Xiao B':20,
'Xiao C':15
}
1,Just take the dictionary keys to form a new list
b = [ key for key,value in students.items() ]
b = [ 'Small armour', 'Xiao B','Xiao C' ]
2,The key value pairs of the dictionary are exchanged to form a new dictionary;
b = { value:key for key,value in students.items() }
b = {
18:'Small armour',
20:'Xiao B',
15:'Xiao C'
}
Write the list into the json file (the list element is a dictionary)
[{'LT/C_score': 0.44917283324979085, 'class_uncertainty': 0.060122907161712646, 'image_id': 286849}, {'LT/C_score': 0.8943103022795436, 'class_uncertainty': 0.009622752666473389, 'image_id': 540932}, {'LT/C_score': 0.8732056996282929, 'class_uncertainty': 0.00022846460342407227, 'image_id': 32901}, {'LT/C_score': 0.8979904106858694, 'class_uncertainty': 0.002511739730834961, 'image_id': 324614}, {'LT/C_score': 0.8679021984870174, 'class_uncertainty': 0.0019818544387817383, 'image_id': 270474}, {'LT/C_score': 0.7331004226857969, 'class_uncertainty': 0.00713348388671875, 'image_id': 139}, {'LT/C_score': 0.11941635694217467, 'class_uncertainty': 0.0169374942779541, 'image_id': 241677}, {'LT/C_score': 0.02415653156423425, 'class_uncertainty': 0.014993846416473389, 'image_id': 528399}, {'LT/C_score': 0.1769359589898254, 'class_uncertainty': 0.2365768551826477, 'image_id': 565391}, {'LT/C_score': 0.866919080778817, 'class_uncertainty': 0.0014355778694152832, 'image_id': 196754}]
import json
import os
def write_list_to_json(list, json_file_name, json_file_save_path):
"""
take list Write to json file
:param list:
:param json_file_name: Written json File name
:param json_file_save_path: json File storage path
:return:
"""
os.chdir(json_file_save_path)
with open(json_file_name, 'w') as f:
json.dump(list, f)
Read json data in txt
txt text file can store all kinds of data, including structured two-dimensional table, semi-structured json and unstructured plain text.
The two-dimensional tables stored in excel and csv files can be directly stored in txt files.
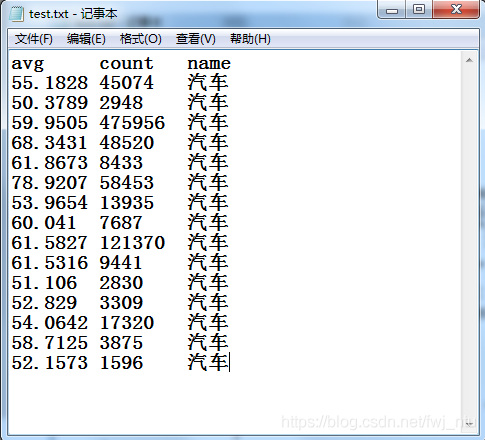
Semi structured json can also be stored in txt text files.
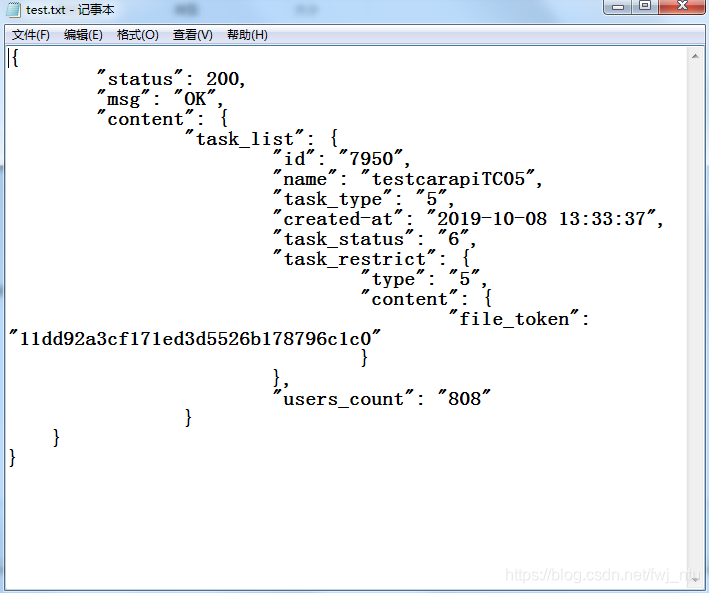
The most common is to store a group of unstructured data in txt files:
Read json type semi-structured data from txt
import pandas as pd
import json
f = open("../data/test.txt","r",encoding="utf-8")
data = json.load(f)
It should be noted that json must be double quotation marks: '' to operate
Get the data type with the following command
type(data) # print(type(data))
Read the Json file by line and write it into the list (dictionary data of each line in the list)
json files in the following format
{"ID": "001", "name": "a", age: "12"}
{"ID": "002", "name": "b", age: "23"}
{"ID": "003", "name": "c", age: "42"}
...
Convert the json file into dictionary data by line and store it in the list
#!/usr/bin/python3
# coding=utf-8
import json
papers = [] # Each row of the array is dictionary data {}
file = open("E:\\pycharm1\\testset2.json", 'r', encoding = 'utf-8')
# The above path is the location of my json file, followed by the Chinese code
for line in file.readlines():
dic = json.loads(line)
papers.append(dic)
Take key "name" as an example to analyze the extracted data according to attributes:
for line in range(0, len(papers)):
S1 = (papers[line])['name'] # Read value with key as name
Write list object to txt file
list1 = ['1','2','3','4']
fileObject = open('list.txt','w')
for word in list1:
fileObject.write(word)
fileObject.write('\n')
fileObject.close()
txt file readout
Here, a txt file is read with the open function, "encoding" indicates that the reading format is "utf-8", and the error code can be ignored.
In addition, it is a good habit to use the with statement to operate file IO, eliminating the need to close() every time you open it
with open("list.txt","r",encoding="utf-8",errors='ignore') as f:
data = f.readlines()
for line in data:
word = line.strip() #list
print(word)
Read the array with numpy data, which can be further converted into a list object
array_ = numpy.loadtxt('list.txt')
list_ = list(array_)
Read each row of TXT and coexist in LIST
Example 1
In this way, the json data in the txt file will be stored in str
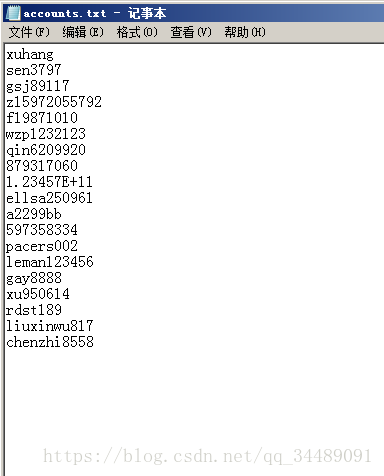
Method 1:
import sys
result=[]
with open('accounts.txt','r') as f:
for line in f:
result.append(list(line.strip('\n').split(',')))
print(result)
Output:

Method 2:
Processing data:
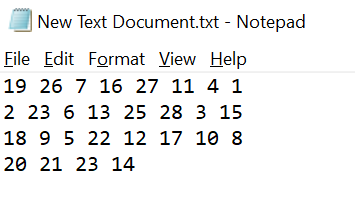
Step 1: read the data in the file
It is easy to read the data in the file. The code runs as follows:

After reading the data of the file, it is found that these are detailed strings. You can see the following effects through printing:

The printed result is more like the content in txt text, but it is stored as a series of strings in python. Each number is cut into a separate string with the split function of the string

Step 2: data conversion

The above can be reduced to three lines of code:
file = open ('....txt','r')
S = file.read().split()
P = list(int(i) for i in S)
Example 2

Method 1:
f=open('One hundred Tang Poems.txt', encoding='gbk')
txt=[]
for line in f:
txt.append(line.strip())
print(txt)
line.strip() removes leading and trailing spaces
Encoding encoding format utf-8,gbk
Method 2:
f=open('One hundred Tang Poems.txt')
line = f.readline().strip() #Read the first line
txt=[]
txt.append(line)
while line: # Until the file is read
line = f.readline().strip() # Read one line of file, including line breaks
txt.append(line)
f.close() # Close file
print(txt)
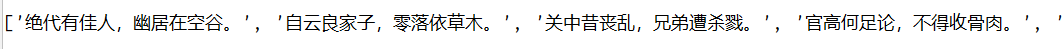
Write dict object to json file
import json
dictObj = {
'andy':{
'age': 23,
'city': 'shanghai',
'skill': 'python'
},
'william': {
'age': 33,
'city': 'hangzhou',
'skill': 'js'
}
}
jsObj = json.dumps(dictObj)
fileObject = open('jsonFile.json', 'w')
fileObject.write(jsObj)
fileObject.close()
Read json file
with open('data.json', 'r') as f:
data = json.load(f)
Write json file
with open('data.json', 'w') as f:
json.dump(data, f)
Read txt content as list
file_path = 'C:/...'
fi=open(file_path,'r')
txt=fi.readlines()
a=[]
for w in txt:
w=w.replace('\n','')
a.append(w)
print(a)
Delete the same elements of two lists (one-to-one deletion)
c=[10,20,20,20,20,100,30,50,50,50]
d=[20,20,30,40,50]
for i in range(len(c)):
for j in c:
if j in d:
c.remove(j)
d.remove(j)
print(c)
print(d)
#[10, 20, 20, 100, 50, 50]
#[40]
Delete dictionary element
- clear() method of Python Dictionary (delete all elements in the dictionary)
#!/usr/bin/python
# -*- coding: UTF-8 -*-
dict = {'name': 'My blog address', 'number': 10000, 'url':'http://blog.csdn.net'}
dict.clear(); # Empty all dictionary entries
- pop() method of Python Dictionary (delete the value corresponding to the key given in the dictionary, and the return value is the deleted value)
#!/usr/bin/python
# -*- coding: UTF-8 -*-
site= {'name': 'My blog address', 'number': 10000, 'url':'http://blog.csdn.net'}
pop_obj=site.pop('name') # Delete the key value pair to be deleted, such as {'name': 'my blog address'}
print pop_obj # Output: my blog address
- popitem() method of Python Dictionary (randomly returns and deletes a pair of keys and values in the dictionary)
#!/usr/bin/python
# -*- coding: UTF-8 -*-
site= {'name': 'My blog address', 'number': 10000, 'url':'http://blog.csdn.net'}
pop_obj=site.popitem() # Randomly return and delete a key value pair
print pop_obj # The output result may be {'url','http://blog.csdn.net/uuihoo '}
- del global method (you can delete a single element or empty the dictionary. Emptying requires only one operation)
#!/usr/bin/python
# -*- coding: UTF-8 -*-
site= {'name': 'My blog address', 'alexa': 10000, 'url':'http://blog.csdn.net/uuihoo/'}
del site['name'] # Delete the entry whose key is' name '
del site # Clear all entries in the dictionary
Removing dictionary key / value pairs - rookie tutorial
Given a dictionary, remove the dictionary key / value pair.
Remove using del
test_dict = {"Runoob" : 1, "Google" : 2, "Taobao" : 3, "Zhihu" : 4}
# Output original dictionary
print ("Before dictionary removal : " + str(test_dict))
# Remove Zhihu with del
del test_dict['Zhihu']
# Output removed dictionary
print ("After dictionary removal : " + str(test_dict))
# Removing an empty key will result in an error
#del test_dict['Baidu']
Execute the above code and the output result is:
Before dictionary removal : {'Runoob': 1, 'Google': 2, 'Taobao': 3, 'Zhihu': 4}
After dictionary removal : {'Runoob': 1, 'Google': 2, 'Taobao': 3}
Remove using pop()
test_dict = {"Runoob" : 1, "Google" : 2, "Taobao" : 3, "Zhihu" : 4}
# Output original dictionary
print ("Before dictionary removal : " + str(test_dict))
# Remove Zhihu using pop
removed_value = test_dict.pop('Zhihu')
# Output removed dictionary
print ("After dictionary removal : " + str(test_dict))
print ("Removed key Corresponding value by : " + str(removed_value))
print ('\r')
# If you use pop() to remove a key that does not exist, no exception will occur. You can customize the prompt information
removed_value = test_dict.pop('Baidu', 'There is no such key(key)')
# Output removed dictionary
print ("After dictionary removal : " + str(test_dict))
print ("The removed value is : " + str(removed_value))
Execute the above code and the output result is:
Before dictionary removal : {'Runoob': 1, 'Google': 2, 'Taobao': 3, 'Zhihu': 4}
After dictionary removal : {'Runoob': 1, 'Google': 2, 'Taobao': 3}
Removed key Corresponding value by : 4
After dictionary removal : {'Runoob': 1, 'Google': 2, 'Taobao': 3}
The removed value is : There is no such key(key)
Remove using items()
test_dict = {"Runoob" : 1, "Google" : 2, "Taobao" : 3, "Zhihu" : 4}
# Output original dictionary
print ("Before dictionary removal : " + str(test_dict))
# Remove Zhihu using pop
new_dict = {key:val for key, val in test_dict.items() if key != 'Zhihu'}
# Output removed dictionary
print ("After dictionary removal : " + str(new_dict))
Execute the above code and the output result is:
Before dictionary removal : {'Runoob': 1, 'Google': 2, 'Taobao': 3, 'Zhihu': 4}
After dictionary removal : {'Runoob': 1, 'Google': 2, 'Taobao': 3}
Difference between pop and del
Del statements that delete key value pairs in the dictionary are the same as pop methods. Del statements and pop() functions have the same function. Pop() function has a return value, which is the corresponding value, and del statements have no return value. Pop() function syntax: pop(key[,default]), where key: the key value to delete, default: if there is no key, the default value is returned
dic = {"Zhang San": 24, "Li Si": 23, "Wang Wu" : 25, "Zhao Liu" : 27}
del dic["Zhang San"]
print(dic)
print(dic.pop("Li Si"))
print(dic)
Output:
{"Li Si": 23, "Wang Wu" : 25, "Zhao Liu" : 27}
23
{"Wang Wu" : 25, "Zhao Liu" : 27}
Updated on February 22, 2019:
From Python 3 7, the dictionary is in order according to the insertion order. Modifying the value of an existing key does not affect the order. If you delete a key and add it, the key will be added to the end. dump(s)/load(s) of the standard json library is also ordered
https://docs.python.org/3/library/stdtypes.html#dict.values
The order of the elements in the list remains the same, where each element is repeated the same number of times
list_before = [1, 2, 3, 4, 5] list_after = [val for val in list_before for i in range(2)]
Output:
list_after = [1, 1, 2, 2, 3, 3, 4, 4, 5, 5]
Expand multiple nested complex data (lists, dictionaries, etc.)
def data_flatten(key,val,con_s='_',basic_types=(str,int,float,bool,complex,bytes)):
"""
Data expansion generator,Data based on key value pairs
param key: Key. The default is basic type data. No further analysis is required
param val: Value, which determines the data type of the value. If it is a complex type, it will be further analyzed
param con_s: Splicer, the connector spliced between the current level key and the parent key. The default is_
param basic_types: The basic data type is tuple. If the value type is within tuple, it can be output
return: Key value pair tuple
"""
if isinstance(val, dict):
for ck,cv in val.items():
yield from data_flatten(con_s.join([key,ck]).lstrip('_'), cv)
elif isinstance(val, (list,tuple,set)):
for item in val:
yield from data_flatten(key,item)
elif isinstance(val, basic_types) or val is None:
yield str(key).lower(),val
Sample data:
test_dict = {
'a':1,
'b':2,
'c':[1,2,3,4,{'a':1,'b':2,'c':3}],
'd':{
'a':2,
'b':3,
'c':('1','2','3'),
'd':{
'a':1,
'b':['True','False']
}
},
'e':{123,3,34,'les'}
}
Call:
for i in data_flatten('',test_dict):
print(i)
Output:
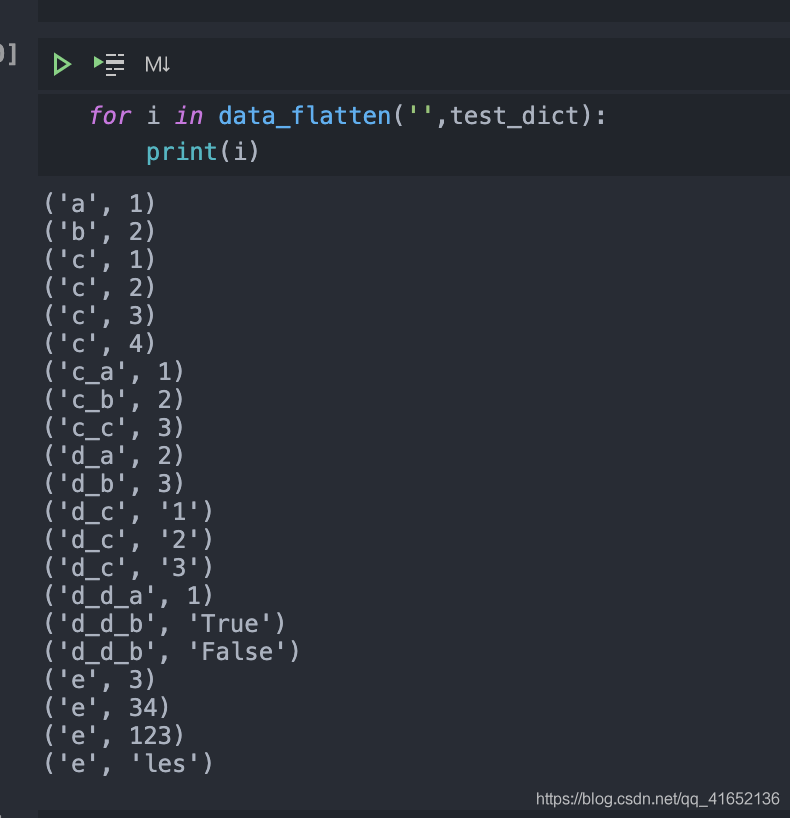
Tiling (including nested) dict s
def prefix_dict(di_, prefix_s=''):
"""
Put every word in the dictionary key All prefixed prefix_s
:param di_:
:param prefix_s:
:return:
"""
return {prefix_s + k: v for k, v in di_.items()}
def spear_dict(di_, con_s='.'):
"""
open dict(If the lower floor is still dict),Recursion is required until the underlying data type is not a dictionary
Where it may be useful: it may be useful to format the data of the document class into a more relational look
:param di_: Input dictionary
:param con_s: Connection symbols between levels
:return: For dictionaries with a depth not greater than 1, other nested data types remain the same
"""
ret_di = {}
for k, v in di_.items():
if type(v) is dict:
v = spear_dict(v)
# There may be a better way to write without writing this layer
# for k_, v_ in v.items():
# ret_di.update({con_s.join([k, k_]): v_})
ret_di.update(prefix_dict(v, prefix_s=k + con_s))
else:
ret_di.update({k: v})
return ret_di
>>> di_
{'title': 'Xintian Commercial Street', 'reliability': 7, 'addressComponents': {'streetNumber': '', 'city': 'Shenzhen City', 'street': '', 'province': 'Guangdong Province', 'district': 'Longhua District'}, 'location': {'lng': 114.09127044677734, 'lat': 22.700519561767578}, 'adInfo': {'adcode': '440309'}, 'level': 11, 'more_deep': {'loca': {'lng': 114.09127044677734, 'lat': 22.700519561767578}}}
>>> spear_dict(di_)
{'title': 'Xintian Commercial Street', 'reliability': 7, 'addressComponents.streetNumber': '', 'addressComponents.city': 'Shenzhen City', 'addressComponents.street': '', 'addressComponents.province': 'Guangdong Province', 'addressComponents.district': 'Longhua District', 'location.lng': 114.09127044677734, 'location.lat': 22.700519561767578, 'adInfo.adcode': '440309', 'level': 11, 'more_deep.loca.lng': 114.09127044677734, 'more_deep.loca.lat': 22.700519561767578}
spear_dict(di_, '_')
{'title': 'Xintian Commercial Street', 'reliability': 7, 'addressComponents_streetNumber': '', 'addressComponents_city': 'Shenzhen City', 'addressComponents_street': '', 'addressComponents_province': 'Guangdong Province', 'addressComponents_district': 'Longhua District', 'location_lng': 114.09127044677734, 'location_lat': 22.700519561767578, 'adInfo_adcode': '440309', 'level': 11, 'more_deep_loca.lng': 114.09127044677734, 'more_deep_loca.lat': 22.700519561767578}
Nested list expansion
Question 1: for a list, such as list_1 = [[1, 2], [3, 4, 5], [6, 7], [8], [9]] convert to list_2 = [1, 2, 3, 4, 5, 6, 7, 8, 9].
# Common method
list_1 = [[1, 2], [3, 4, 5], [6, 7], [8], [9]]
list_2 = []
for _ in list_1:
list_2 += _
print(list_2)
# List derivation
list_1 = [[1, 2], [3, 4, 5], [6, 7], [8], [9]]
list_2 = [i for k in list_1 for i in k]
print(list_2)
# Using sum
list_1 = [[1, 2], [3, 4, 5], [6, 7], [8], [9]]
list_2 = sum(list_1, [])
print(list_2)
Problem 2: for some complex, such as: list =[1,[2],[[3]],[[4,[5],6]],7,8,[9]], the above method is not easy to use. We have to change the method. Here we use the recursive method to solve it.
def flat(nums):
res = []
for i in nums:
if isinstance(i, list):
res.extend(flat(i))
else:
res.append(i)
return res
Two verification methods were learned during the internship:
Token authentication and user name plus password authentication
1. What is Token authentication?
Token is a user authentication method, which is usually called token authentication. When the user logs in successfully for the first time, the server will generate a token and return it to the user. In the future, the user only needs to bring this token to request data without using the user name and password.
2. Token verification process
① When logging in for the first time, the client requests login through user name and password
② The server receives the request and verifies the user name and password
③ If the verification passes, the server will issue a Token, which will be saved in the database of the server and returned to the client
④ The client receives the Token and stores it, such as cookies, SessionStorage and LocalStorage.
⑤ Every time the client requests resources from the server, it will bring a Token
⑥ The server receives the request, then verifies the Token carried in the client request, that is, compares the client's Token with the Token in the local database. If the two tokens are the same, it indicates that the user has successfully logged in, the verification passes, and the server returns the request data to the client.
⑦ If the two tokens are different, the authentication fails and you need to log in through your user name and password
3. Why use Token authentication?
When the client requests data from the server many times, the server needs to query the user name and password from the database many times and compare them, judge whether the user name and password match correctly, and give corresponding prompts. Querying the database consumes more resources, which will undoubtedly increase the running pressure of the server. In order to verify the user login and reduce the pressure on the server, Token authentication is introduced. Tokens are generally stored in memory, so there is no need to query the database, which reduces the frequent query of the database and makes the server more robust.
What are incremental table, full scale, snapshot table
According to the data stored every day and whether it is partitioned by day, it can be divided into incremental table, full table and snapshot table
Item | Value | a|
-------- | ----- ||
Computer | $1600||
Mobile phone | $12||
Conduit | $1 ||
| Full scale | Incremental table | Snapshot table | |
|---|---|---|---|
| data | Include the full amount of data to the previous day | Incremental data of the previous day | Include the full amount of data to the previous day |
| partition | No partition (ymd is the current date) | Partition by day | Partition by day |
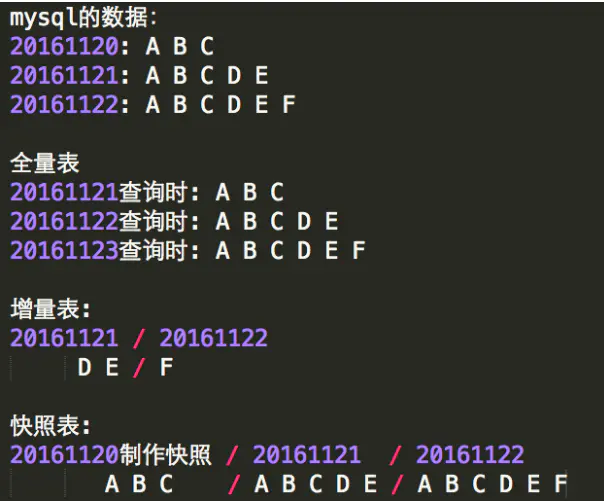
For details:
https://blog.csdn.net/Jun2613/article/details/106688930
In addition, full outer join