Foreign Key
If there's a table today with a lot of job information on it
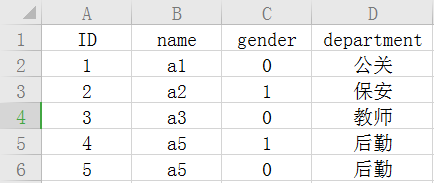
We can associate two tables by using foreign keys
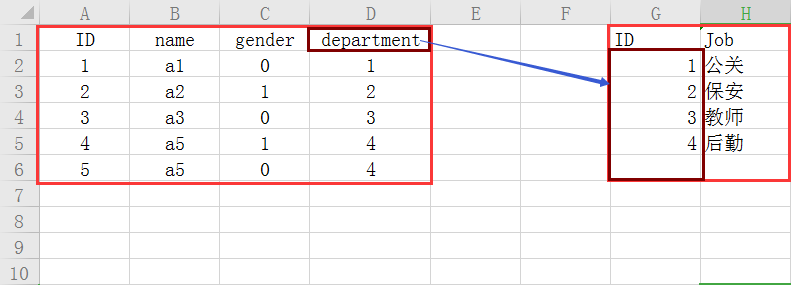
Such benefits can save space, for example, you have a long job title today, it is a waste of space to repeat the name of the job in a table; besides, it can also play a restraining role.
Departments, for example, are foreign keys.
Execute code:
create table t1( uid bigint auto_increment primary key, name varchar(32), department_id int, gender int, constraint fk_user_depar foreign key ("department_id",) references department("id") )engine=innodb default charset=utf8; create table t2( id bigint auto_increment primary key, job char(15), )engine=innodb default charset=utf8;
When do I use the primary key? The function of the primary key?
To preserve the integrity of data, a table can only have one primary key, a primary key can be synthesized by multiple columns and the primary key can not be empty.
create table t1( uid bigint auto_increment, name varchar(32), department_id int, gender int, primary key(uid,gender) #Combine the two columns into one primary bond constraint fk_user_depar foreign key ("department_id",) references department("id") )engine=innodb default charset=utf8;
ps: The name of the foreign key cannot be repeated.
The primary key values of multiple columns and combinations correspond to multiple columns of another table:
create table t1( uid bigint auto_increment, name varchar(32), department_id int, gender int, primary key(department_id,gender) #Combine the two columns into one primary bond constraint fk_user_depar foreign key ("department_id","gender") references department("id","num_gender") )engine=innodb default charset=utf8; create table t2( id bigint auto_increment primary key, job char(15), num_gender bigint, )engine=innodb default charset=utf8;
Starting values of self-incremental columns
desc table name;
show create table table name:
Suppose the original table:
Execution statement command
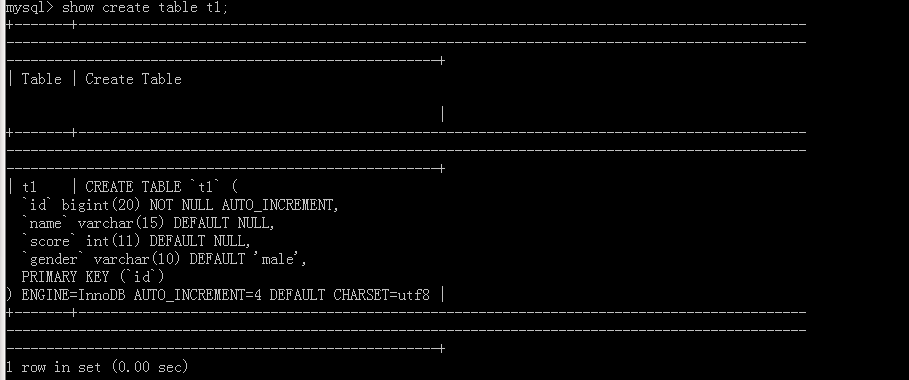
Attach commandsG
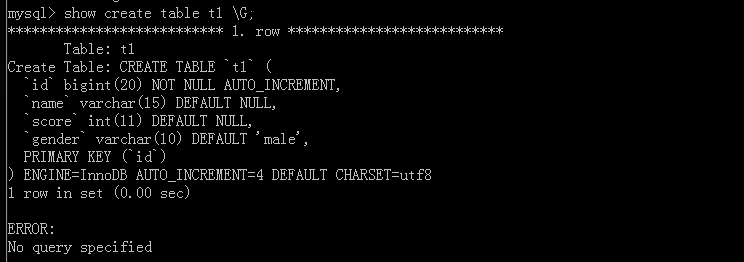
You can see that this is the SQL statement we wrote, but there is no'AUTO_INCREMENT=4', because there are three data in the original table, which means that the next self-increment is 4.
Let's add two more figures to see how self-increment here becomes.
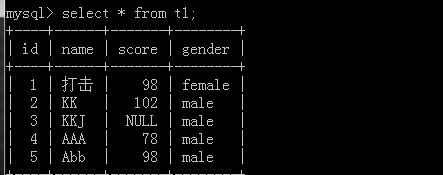
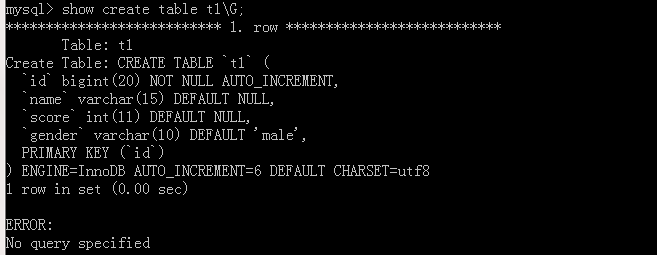
If you want to modify this self-increment, use the alter table table table name AUTO_CREMENT = value;
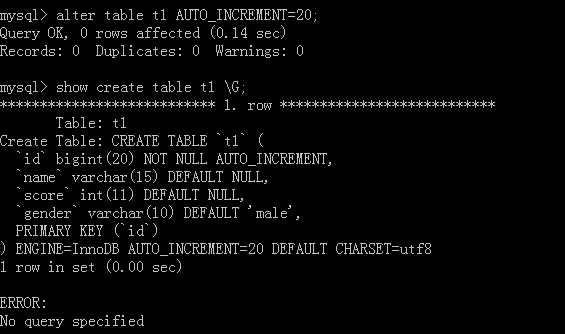
The Step Length of Self-Incremental Column
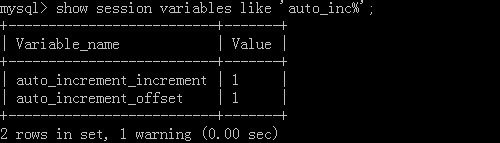
Mysql's self-increment step is not good because it is based on session level, and a login is a session.
< 1 > Based on session level:
Statement: show session variables like'auto_inc%'to view global variables
Set the step size: set session auto_increment_increment = value;
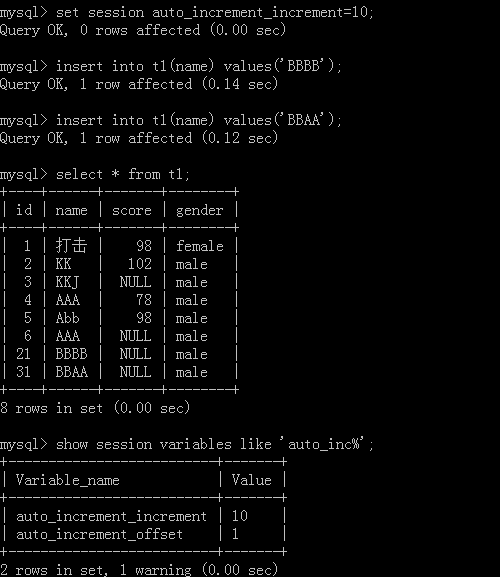
Note that the step size of each session is independent unless the global variables of each session are unified with the global variables.
Modify the starting value of the current session:
set session auto_increment_offset=value;
<2> Based on the global level:
It allows everyone to log in with the step size changed to a uniform value.
set global auto_increment_increment=200;
View global variables:
show global variables like 'auto_inc%';
Modify the global starting value:
set global auto_increment_offset=value;
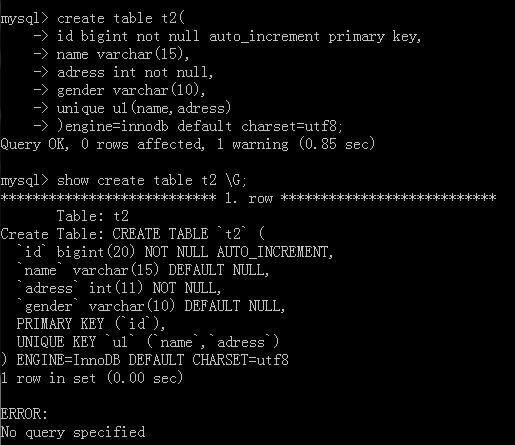
unique index
The only function of an index is to speed up search and to act as a constraint.
Variants of foreign bonds
<1> one to many
For example, the relationship between users and departments
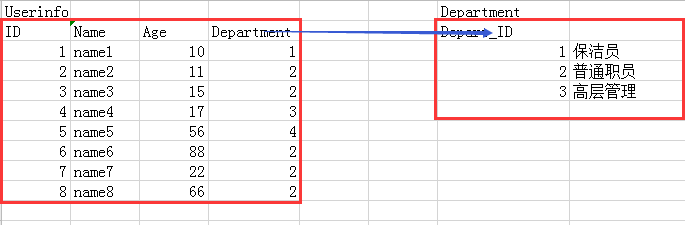
<2> one to one
For example, user and blog tables
Foreign key and unique index need to be used to constrain

If you want to create an employee form that corresponds to their authority relationship, only executives can have authority to view employee information.
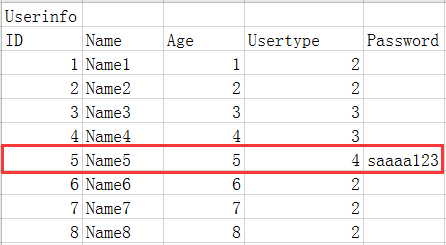
Usertype here is a foreign key, which corresponds to another employee's job list, but in fact only 4 in Usertype has the right to view employee's information, so the password column of other employees will cause waste of resources, so here we can use another way to optimize:
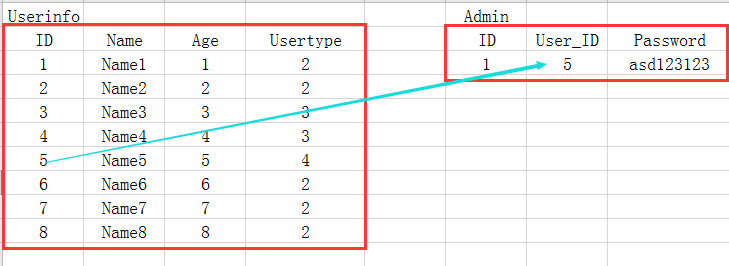
<3> many to many
A table shows:
For example, the matchmaking record of Lily Net
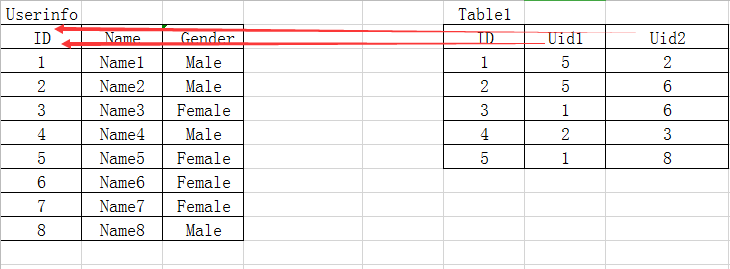
There are two foreign keys, Uid1 and Uid2, pointing to the ID.
Two tables indicate:
For example, the relationship table between host and user, what type of host a user can control.
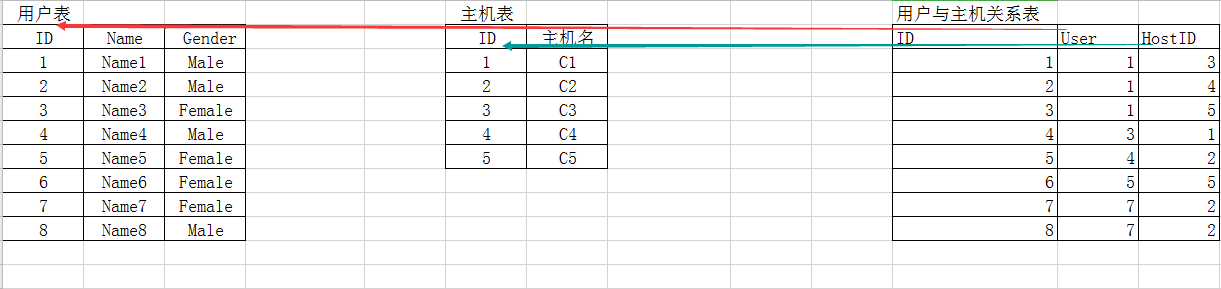
The benefits of the main presentation enable us to see clearly a user who has several hosts and what users are responsible for the host. User and HostID must be unique.
Some Supplementations to Data Lines of SQL Statements
<1>. increase
Suppose there is a table.
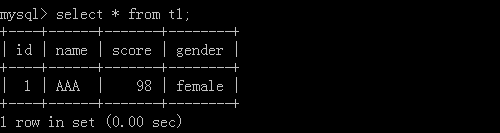
Through grammar: insert into table name (first column data name, second column data name...) values (corresponding first column value 1, corresponding second column value 1...), (corresponding first column value 2, corresponding second column value 2...),...; in this way, multiple values can be inserted.

Check out the new data:
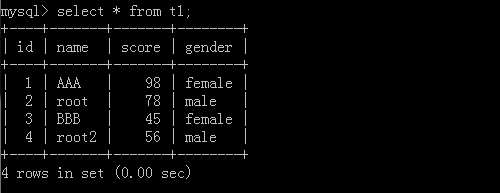
Similarly, we can extract data from one table into another.
The original table is the table with new data added above, and then we go to create a new table:
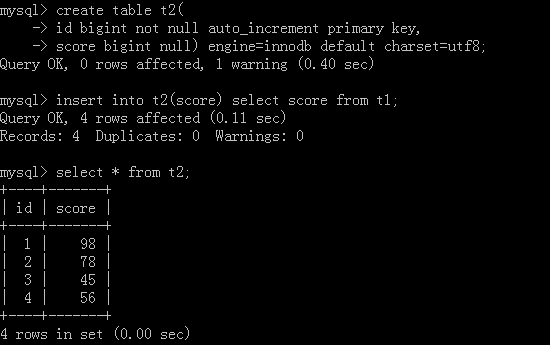
<2>. delete
Divided into unconditional and conditional situations
Unconditional:
delete from table name;
Conditionally:
1.delete from Table name where ID != 2; 2.delete from Table name where ID = 2; 3.delete from Table name where ID > 2; #It can also be less than, greater than or equal to, less than or equal to 4.delete from Table name where ID < 2 and name = 'name1'; 5.delete from Table name where ID >= 2 or name = 'name1;
<3>. modification
1. change one.
update Table name set name = 'name1' where id > 2 and name = 'AAA';
2. more than one.
update Table name set name = 'name1',age = 20 where id > 2 or name = 'AAA';
<4>. check
1.select * from Table name; 2.select id,name from Table name; 3.select id,name from Table name where id > 10 or name = 'name1';
4.select id,name as New name from Table name where id > 10 or name ='nam1';
Original form:
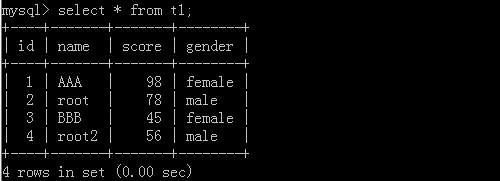
After implementation:
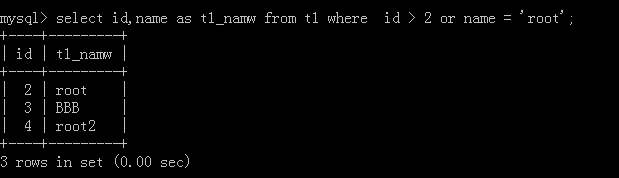
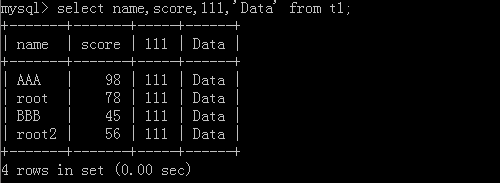
5.select name,age,'data' from Table name;
Original form:
After implementation:
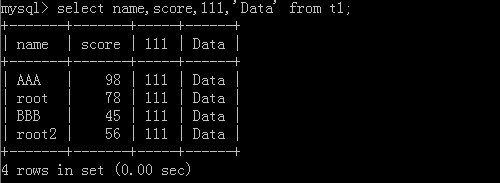
Other:
Original table:
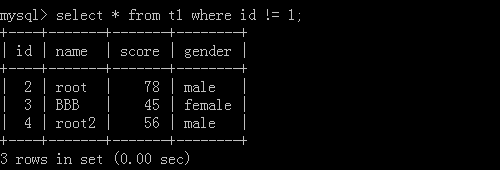
1.select * from t1 where id != 1;
Implementation results:
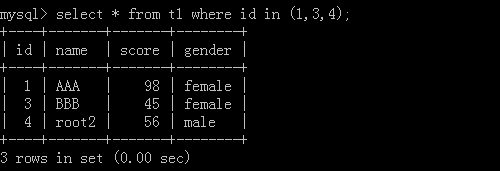
2.select * from t2 where id in (1,3,4);
Implementation results:
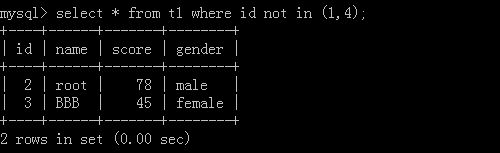
3.select * from t1 where id not in (1,4);
Implementation results:
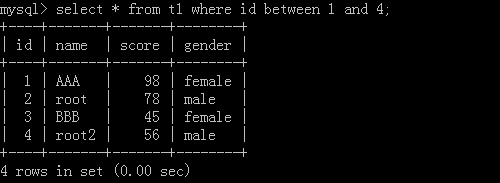
4.select * from t1 where id between 1 and 4; --->[1,4]
Implementation results:
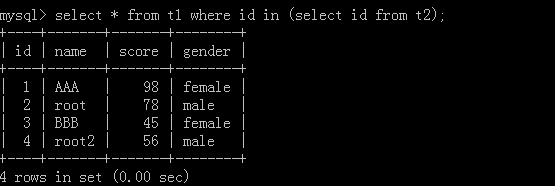
5. select * from t1 where id in (select score from t2);
t2 table:

Implementation results:
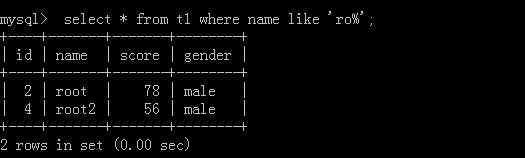
Wildcard:
'%': For example, a% and a can be followed by any number of characters.
'': For example, a, a can only be followed by an arbitrary character
1.select * from t1 where name like 'ro%';
Implementation results:
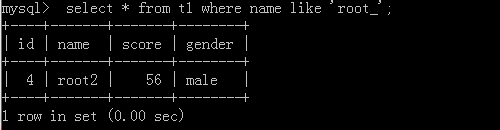
2.select * from t1 where name like 'root_';
Implementation results:
Restrictions:
For example, if you go through the data, you will be able to pagination at the back and see ten or twenty at a time. This will not cause computer resources to fail.
Original form:
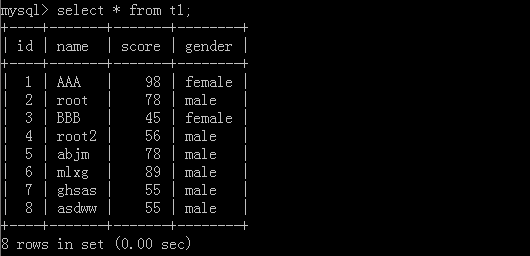
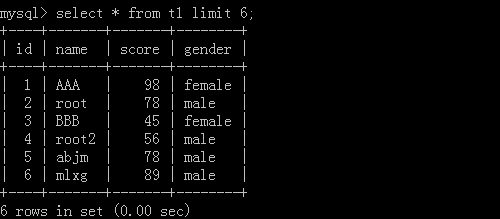
1.select * from t1 limit 6;
Implementation results:
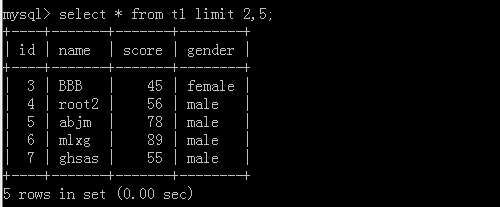
2.select * from t1 limit 2,5;
Here, 2 represents the starting address and 5 represents a total of several references.
Implementation results:
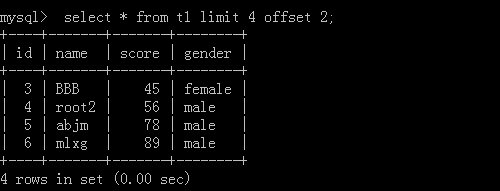
3.select * from t1 limit 10 offset 20;
This means starting from 20 and looking up 10 data later.
Implementation results:
If you want to find the last 10 pieces of data, you have to flip the whole data and then look up the 10 pieces.
Sort:
From big to small:
1.select * from t1 order by id desc;
Use id to arrange data from large to small, and execute the results:
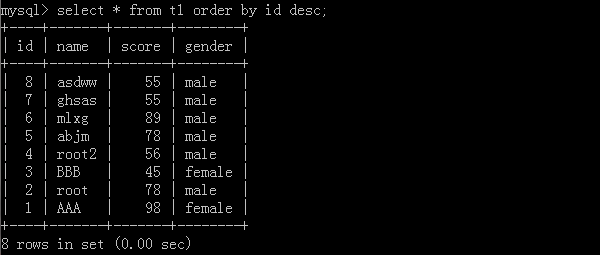
From big to small:
2.select * from t1 order by id asc;
Use id to arrange data from small to large, and execute the results:
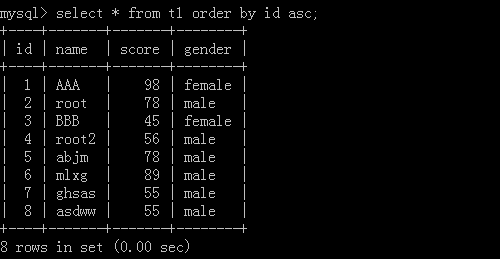
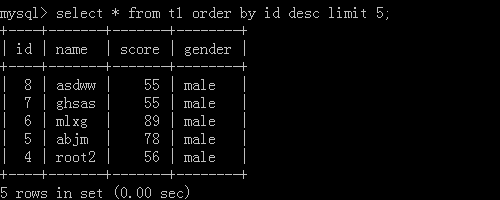
Five pieces of data were retrieved:
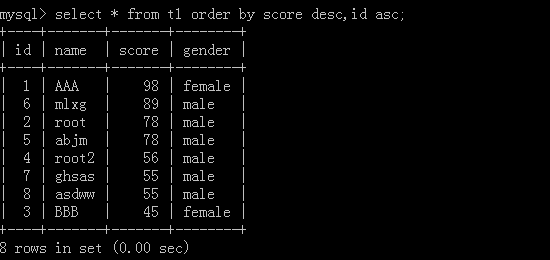
Multi-column sorting:
Arrange the scores in the order of priority. First arrange the scores in the order of large to small. If there are the same scores, then arrange them in the order of small to large according to their IDs.
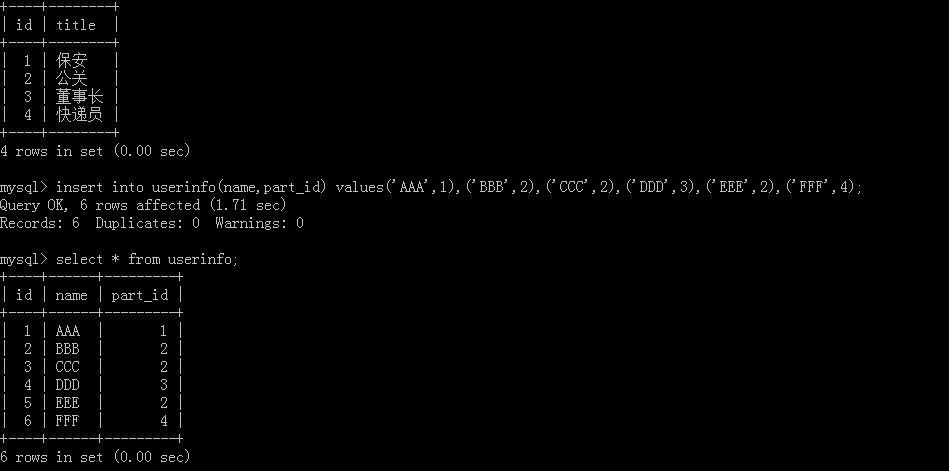
Combination:
Take employees and departments as examples, first create department tables:

Create another employee table:

Add employee and department information:


View the added employee information table and department information table:
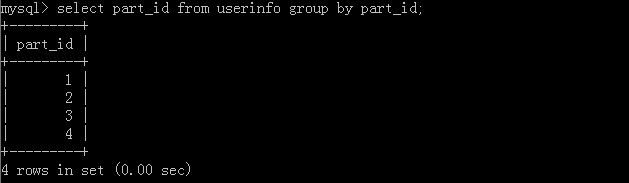
1.select part_id from userinfo group by part_id;
Implementation results:
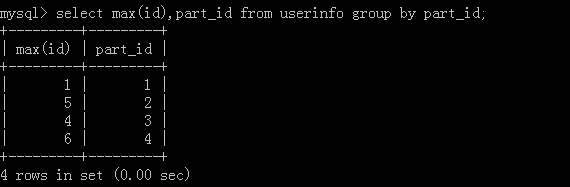
2.select max(id),part_id from userinfo group by part_id;
Implementation results:
3.select min(id),part_id from userinfo group by part_id;
Implementation results:

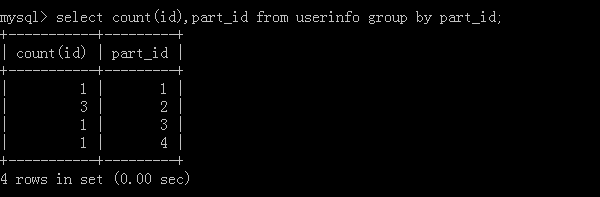
4.select count(id),part_id from userinfo group by part_id;
Implementation results:
5.select sum(id),part_id from userinfo group by part_id;
Implementation results:

6.select avg(id),part_id from userinfo group by part_id;
Implementation results:

7.select count(id),part_id from userinfo group by part_id having count(id) > 1;
If the result of aggregation function is filtered twice, the hasing keyword must be used to execute the result:

8.select count(id),part_id from userinfo where id = 1 or id < 4 group by part_id having count(id) > 1;
Implementation results:

Connecting table operation:
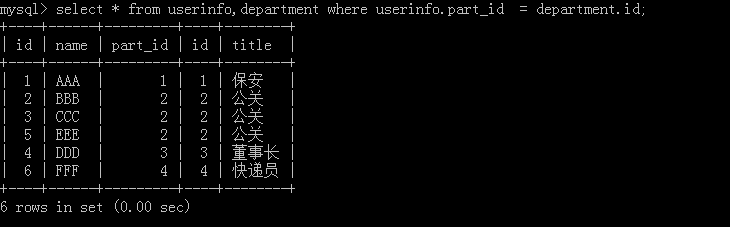
1.select * from userinfo,department where userinfo,part_id = department_id;
If two tables are joined in one operation, there will be confusion if there are no conditions later. Implementation results:
2.select * from userinfo left join department on userinfo.part_id = department.id;
This method will be different according to the previous version of SQL, but it is not much different in reality, but it is recommended to use this to join tables. Features: The table userinfo on the left will display all of them. Implementation results:
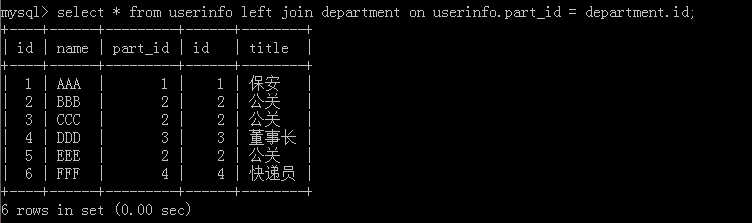
3.select * from userinfo right join department on userinfo.part_id =department.id;
Features: All data in the department table on the right will be displayed.
4.select * from userinfo inner join department where userinfo.part_id = department.id;
If NULL appears when a table is linked to data from another table, the whole row of data is hidden.