Crawling pictures, analysis of key information about dynamic pages
Python version: 3.9 six
ide: PyCharm 2021.1.3
Take Baidu pictures as an example. Open the home page of Baidu pictures and click the topic of urban architectural photography. You can see many beautiful pictures. After reviewing the elements in F12, you can find that all the pictures are under the < div id = "imglist" > tag.
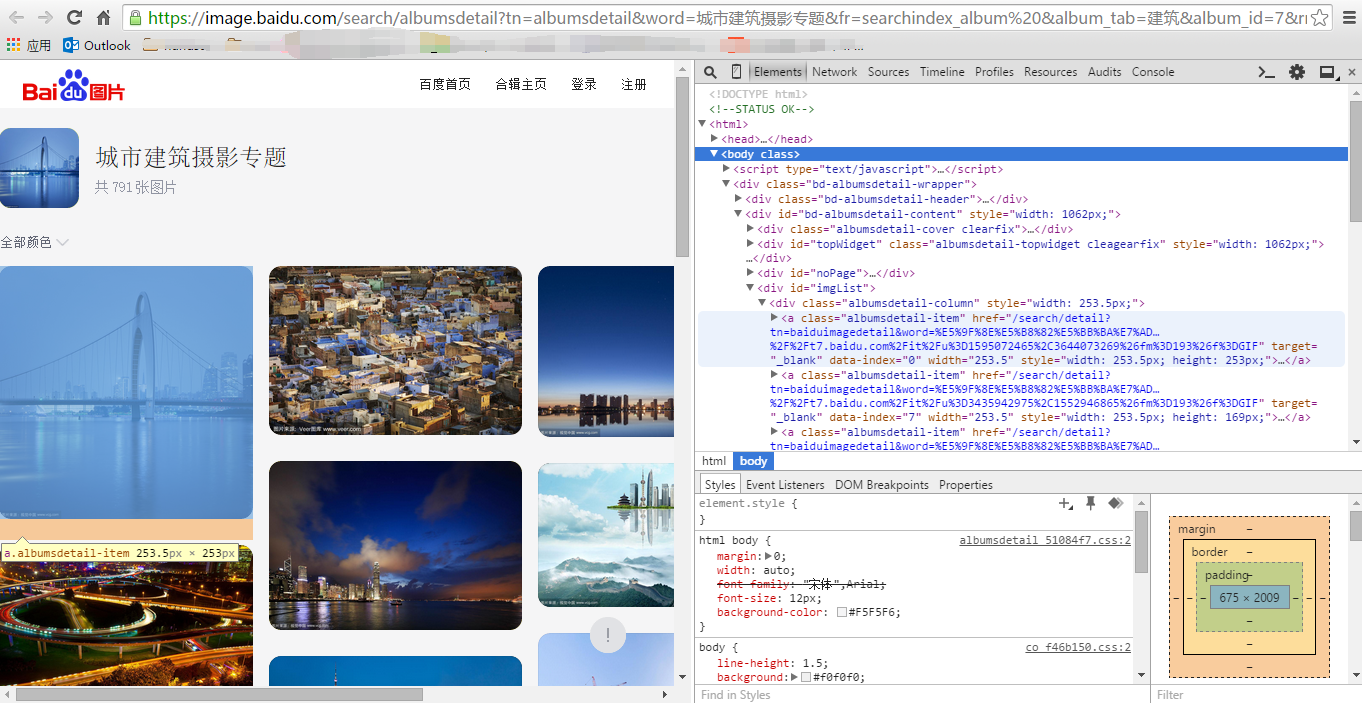
Similarly, try using the requests library to get links to html content parsing images.
import requests
from bs4 import BeautifulSoup
url = 'https://image.baidu.com/search/albumsdetail?tn=albumsdetail&word=%E5%9F%8E%E5%B8%82%E5%BB%BA%E7%AD%91%E6%91%84%E5%BD%B1%E4%B8%93%E9%A2%98&fr=searchindex_album%20&album_tab=%E5%BB%BA%E7%AD%91&album_id=7&rn=30'
req = requests.get(url)
html = BeautifulSoup(req.text, 'lxml')
print(html)
div = html.find('#imgList').find_all('a', class_='albumsdetail-item')
urls = []
for each in div:
urls.append(each.get('href'))When the program is running, you will see the following error reports:

This error can be reported to Baidu. It is because redirection is too many times. Just add "allow_redirects=False" to the get request to prohibit redirection. We add the attribute, print the html obtained, and run the program again.
import requests
from bs4 import BeautifulSoup
url = 'https://image.baidu.com/search/albumsdetail?tn=albumsdetail&word=%E5%9F%8E%E5%B8%82%E5%BB%BA%E7%AD%91%E6%91%84%E5%BD%B1%E4%B8%93%E9%A2%98&fr=searchindex_album%20&album_tab=%E5%BB%BA%E7%AD%91&album_id=7&rn=30'
req = requests.get(url, allow_redirects=False)
html = BeautifulSoup(req.text, 'lxml')
print(html)
div = html.find('#imgList').find_all('a', class_='albumsdetail-item')
urls = []
for each in div:
urls.append(each.get('href'))The output results are as follows:
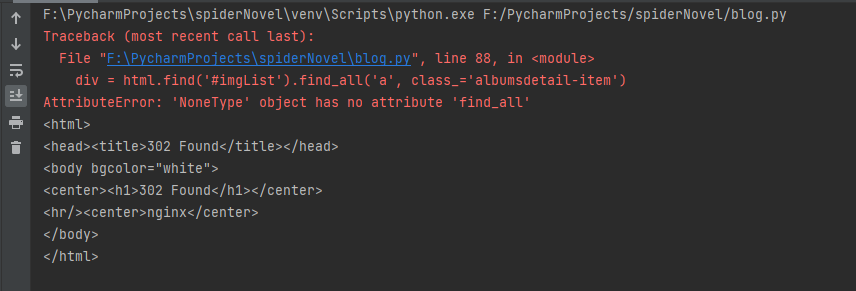
First, we can see the error report that the corresponding tag cannot be found. Through printing, we can see that the obtained web page is 302 code, not the html we want. This usually occurs when there are too many visits. The page requires the input of verification code. In order to solve this problem, we can package the header information when requesting, so that the server can identify the user information. By reviewing the request link of the element, we can find the Headers information.
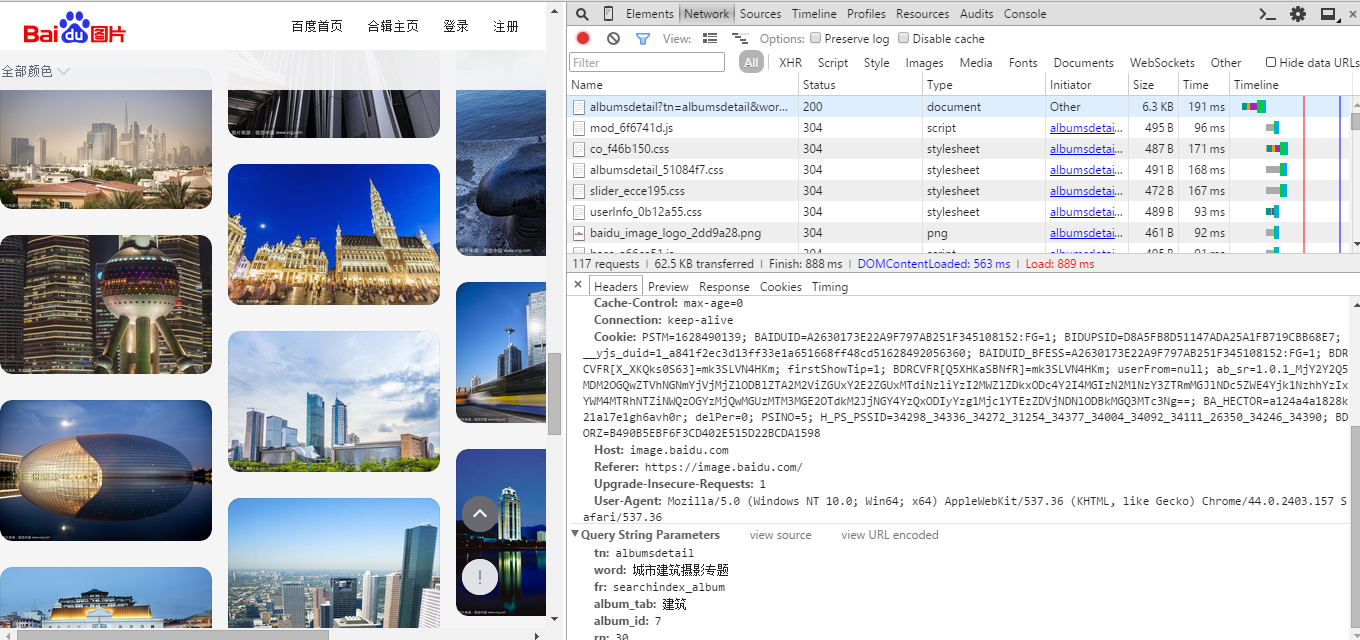
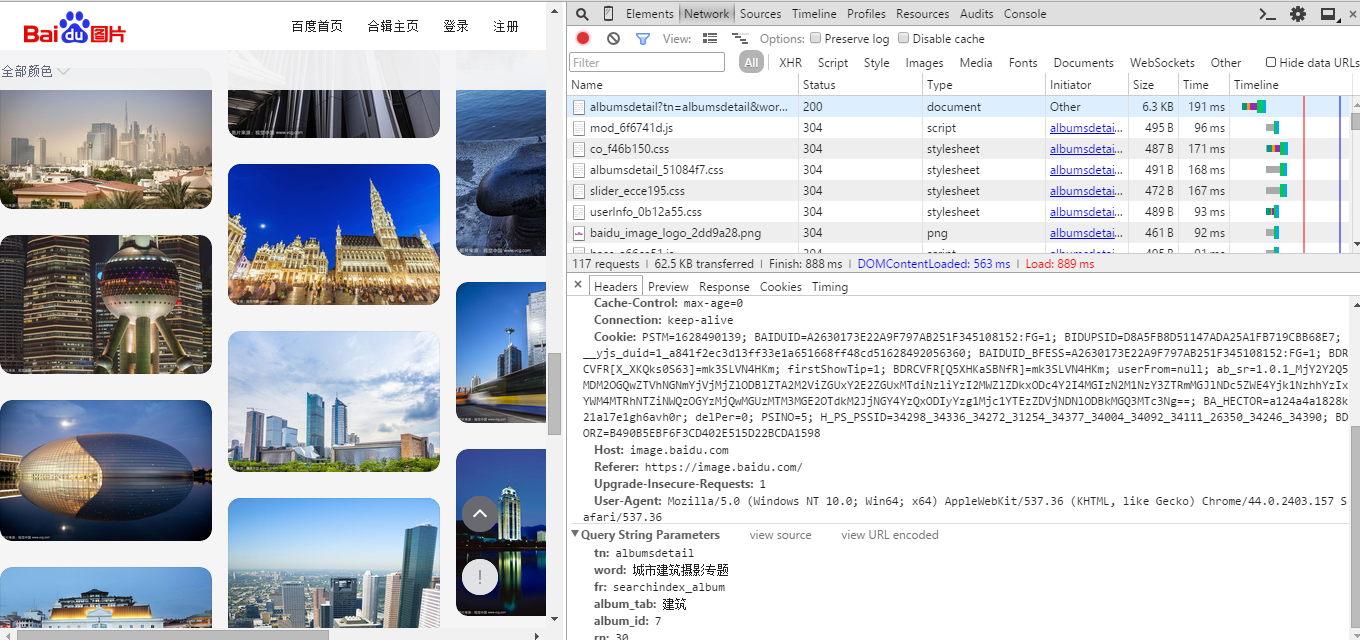
Generally, user agent and Referer can be added to the request header (you can search the header in the Http request to understand the role of each attribute).
import requests
from bs4 import BeautifulSoup
url = 'https://image.baidu.com/search/albumsdetail?tn=albumsdetail&word=%E5%9F%8E%E5%B8%82%E5%BB%BA%E7%AD%91%E6%91%84%E5%BD%B1%E4%B8%93%E9%A2%98&fr=searchindex_album%20&album_tab=%E5%BB%BA%E7%AD%91&album_id=7&rn=30'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Referer': 'https://image.baidu.com/'}
req = requests.get(url, headers=headers, allow_redirects=False)
html = BeautifulSoup(req.text, 'lxml')
print(html)
div = html.find('#imgList').find_all('a', class_='albumsdetail-item')
urls = []
for each in div:
urls.append(each.get('href'))The output results are as follows:

We can see that the printed result is very similar to the html we see, but the error is still reported and the corresponding label cannot be found. Carefully check the printed result and you can see that the content in the < div class = "BD albumsdetail content" > label is empty.
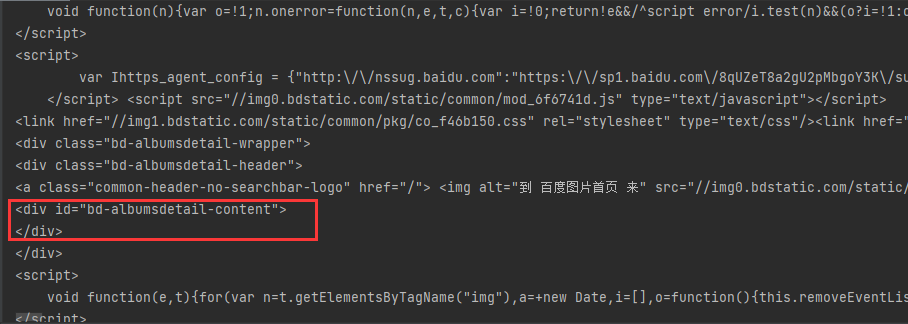
Then we can conclude that these contents are loaded dynamically (quickly find out whether they are loaded dynamically. You can view the contents in html format by Ctrl+u).
It is impossible for us to manually copy the links one by one and then download them. Therefore, next, we try to find the js request and obtain the link of the picture through the content of the js request.
Press F5 to reload the interface. You can see all requests in the network. Filter the requests before image links, and only find the following related requests.

As we can see when reviewing elements, the content in the < div class = "BD albumsdetail content" > tag is empty, and there is no useful information in other requests.
It is found that new pictures can be loaded when the interface scrolls down. At this time, we continue to filter requests in the network.
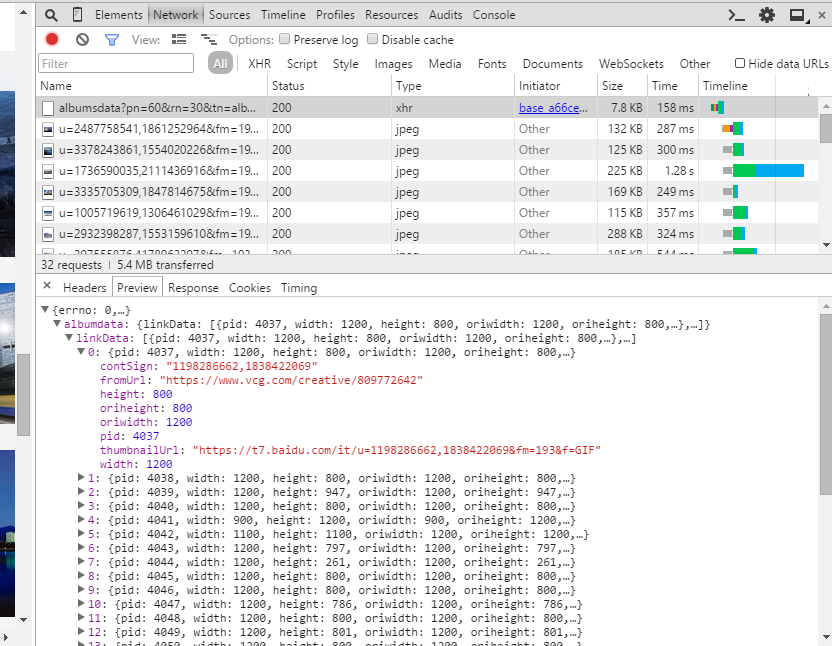
It is found that the response of the first request returns json format data. The level-by-level expansion shows that the data we need is in linkData, and the image url we need is in the value corresponding to the thumbnailUrl. There are 30 records in total. Therefore, we only need to parse the json format data to get the image url for download.
The code is as follows:
import os
import sys
import requests
url = 'https://image.baidu.com/search/albumsdata?pn=30&rn=30&tn=albumsdetail&word=%E5%9F%8E%E5%B8%82%E5%BB%BA%E7%AD%91%E6%91%84%E5%BD%B1%E4%B8%93%E9%A2%98&album_tab=%E5%BB%BA%E7%AD%91&album_id=7&ic=0&curPageNum=1'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Referer': 'https://image.baidu.com/search/albumsdetail?tn=albumsdetail&word=%E5%9F%8E%E5%B8%82%E5%BB%BA%E7%AD%91%E6%91%84%E5%BD%B1%E4%B8%93%E9%A2%98&fr=searchindex_album%20&album_tab=%E5%BB%BA%E7%AD%91&album_id=7&rn=30'}
req = requests.get(url, headers=headers, allow_redirects=False).json()
# Get Picture Dictionary collection
link_data = req.get('albumdata').get('linkData')
# Save each picture link
urls = []
for each in link_data:
if each:
urls.append(each.get('thumbnailUrl'))
# New folder
if not os.path.exists('Baidu pictures'):
os.mkdir('Baidu pictures')
# Download pictures
index = 0
for url in urls:
index += 1
with open('Baidu pictures' + '\\{}.jpg'.format(index), 'wb') as f:
f.write(requests.get(url, headers=headers, allow_redirects=False).content)
sys.stdout.write("Downloaded:%.2f%%" % float(index * 100 / len(urls)) + '\r')
sys.stdout.flush()Through the above code, we can download all the pictures in this request triggered by page turning. What if we want to download a specified number of pictures?
Let's compare the contents of two page turning request URLs:
1,
2,
Through comparison, it can be found that only the values of pn and curPageNum are different in each request. It can be guessed that pn represents the number of requested pictures, and curPageNum represents the current number of requested pages. Through such rules, we can obtain any number of pictures.
The complete code is as follows:
"""
function: Picture crawling
author: w.royee
date: 2021-08-08
"""
import os
import sys
import urllib
import requests
class Image:
def __init__(self):
# Baidu picture address prefix
self.target = 'https://image.baidu.com/search/albumsdata?'
# Number of pages, 30 articles per page
self.page = 3
# key word
self.word = 'Special topics of urban architectural photography'
self.album_tab = 'Architecture'
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Referer': 'https://image.baidu.com/'}
def get_urls(self):
# Format symbol
keyword = urllib.parse.quote(self.word)
urls = []
for i in range(1, self.page + 1):
urls.append(self.target + 'pn={}&rn=30&tn=albumsdetail&word={}&album_tab={}&album_id=7&ic=0&curPageNum={}'.format(30 * i, self.word, self.album_tab, i))
return urls
def get_image_urls(self, urls):
image_urls = []
for url in urls:
# Get json format
req = requests.get(url, headers=self.headers, allow_redirects=False).json()
# Get Picture Dictionary collection
link_data = req.get('albumdata').get('linkData')
# Save each picture link
for each in link_data:
if each:
image_urls.append(each.get('thumbnailUrl'))
return image_urls
def download(self, image_urls):
# New folder
if not os.path.exists('Baidu pictures'):
os.mkdir('Baidu pictures')
# Download pictures
index = 0
for url in image_urls:
index += 1
with open('Baidu pictures' + '\\{}.jpg'.format(index), 'wb') as f:
f.write(requests.get(url, headers=self.headers, allow_redirects=False).content)
sys.stdout.write("Downloaded:%.2f%%" % float(index * 100 / len(image_urls)) + '\r')
sys.stdout.flush()
if __name__ == '__main__':
Image = Image()
v_urls = Image.get_urls()
v_image_urls = Image.get_image_urls(v_urls)
Image.download(v_image_urls)
Note: actual word and album found_ The two parameters tab are actually useless. If you want to download pictures of other categories, you can analyze the constituent elements of the url.