Python linked CSV and MySQL
1, Make sure MySQL is available
After MySQL is installed (the simplest installation method is to download the installation package from the official website and then install it step by step), it's time to operate ~
% mysql --version % zsh: command not found: mysql Copy code
command not found: mysql appears mostly because you haven't added environment variables after installing mysql, so this error occurs. resolvent:
# 1. Enter the following command to enter the environment variable file (be careful not to%) % vim ~/.bash_profile # 2. Press the A key to enter the editing state and paste the following contents export PATH=$PATH:/usr/local/mysql/bin # 3. Press ESC, then shift +: # Enter wq to save the edits # 4. Run the following code to restart the configuration file % source ~/.bash_profile Copy code
Enter the following command again, and you can see the relevant information of mysql version ~
% mysql --version % mysql Ver 8.0.22 for macos10.15 on x86_64 (MySQL Community Server - GPL) Copy code
2, Simply get some data to CSV
2.1 page view and analysis
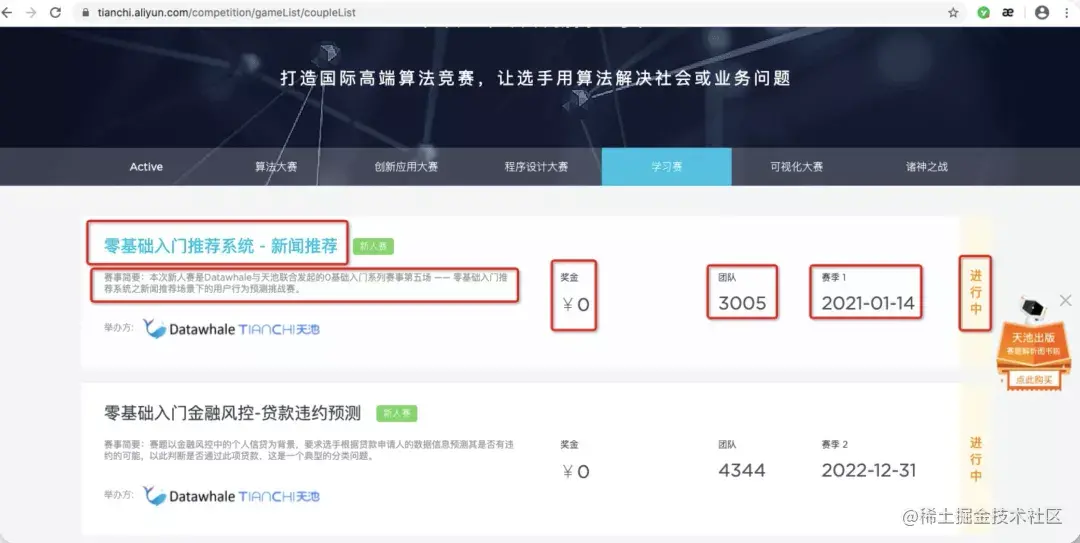
Here, we climb down the learning contest page data of Alibaba cloud Tianchi
| chinese | english | data type | remarks |
|---|---|---|---|
| Event name | raceName | string | character string |
| Event ID | raceId | string | 531842 |
| Event introduction | brief | string | Long string |
| Event start time | currentSeasonStart | date | 2020-11-19 17:00:00 |
| Event end time | currentSeasonEnd | date | 2021-01-14 23:55:00 |
| Event status | raceState | int | 1 in progress |
| 0 has ended | |||
| Number of participating teams | teamNum | int | integer |
| Event type | type | int | integer |
| Event bonus | currency | int | integer |
| Event bonus symbol | currencySymbol | string | character string |
Hey hey, after planning the data you need, you can start page analysis. Press and hold F12 to refresh the page. Refresh, refresh, look at the page data loading in the Network, find it one by one, bang, you find a listbrief? pageNum=1&pageSize..., This is fate. The data are here. Click Headers to view the Request URL, and you will find that this is actually a data interface, comfortable ~
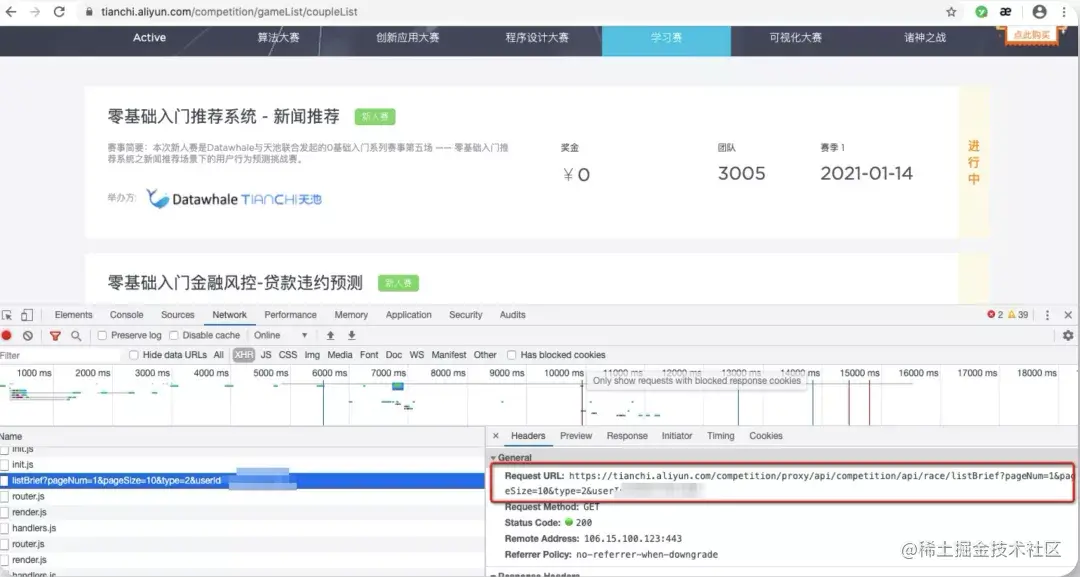
In this way, data acquisition is much easier ~!

2.2 write a few lines of code
First import a series of packages to be used
'''
What are the learning competitions and related data for climbing Alibaba cloud's big data platform Tianchi
Address: https://tianchi.aliyun.com/competition/gameList/coupleList
'''
import warnings
warnings.filterwarnings("ignore")
# Ignore warning
import requests
# Import page request module
from fake_useragent import UserAgent
# Import the module that randomly generates the request header
import json
# Import json data processing package
import pandas as pd
# Import data processing module
import pymysql
# Import database processing module
Copy code
If you find no module name, you can directly pip insatll. You're welcome.
'''
Crawling data
'''
def get_data():
# Request header
headers = {
"User-Agent": UserAgent(verify_ssl=False,use_cache_server=False).random
}
# List for storing data
csv_data = []
# Header, data items you need
head_csv = ['raceName', 'raceId', 'brief', 'currentSeasonStart', 'currentSeasonEnd', 'raceState', 'teamNum', 'type', 'currency', 'currencySymbol']
# After page analysis, there are 4 pages and 32 pieces of data, which are crawled in a circular way
for i in range(1,5):
# Data api and rules found through page analysis
competition_api = 'https://tianchi.aliyun.com/competition/proxy/api/competition/api/race/listBrief?pageNum=%d&pageSize=10&type=2'%i
# print(competition_api)
# Send get request
response_data = requests.get(competition_api,headers=headers)
# Convert the acquired data into json format, and then process the data like a dictionary
json_data = response_data.text
json_data = json.loads(json_data)
# Print observation data
# print(type(json_data['data']['list']))
# Loop through each data and get the data you need
for i in json_data['data']['list']:
one_csv_data = []
one_csv_data.append(i['raceName'])
one_csv_data.append(i['raceId'])
one_csv_data.append(i['brief'])
one_csv_data.append(i['currentSeasonStart'])
one_csv_data.append(i['currentSeasonEnd'])
one_csv_data.append(1 if i['raceState']=='ONGOING' else 0)
one_csv_data.append(i['teamNum'])
one_csv_data.append(i['type'])
one_csv_data.append(i['currency'])
one_csv_data.append('RMB' if i['currencySymbol']=='¥' else 'dollar')
csv_data.append(one_csv_data)
return head_csv,csv_data
data = get_data()
Copy code
The logic of the whole code is very clear. Through the discovered data interface, obtain the data, convert it into json format data, and then traverse it, take out the data you need and store it in the list first.
Then we can save the data to CSV file while it is hot. The code is as follows:
'''
Store list data as csv Format file
'''
def save_to_cvs(data):
# Parse data
head_csv = data[0] # Header
csv_data = data[1] # Data in table
# Convert data to DataFrame format
csv_data =pd.DataFrame(columns=head_csv,data=csv_data,)
# print(csv_data)
# Call to_ The CSV function stores the data as a CSV file
csv_data.to_csv('tianchi_competition.csv',index=False, encoding='gbk')
save_to_cvs(data)
Copy code
The data are as follows: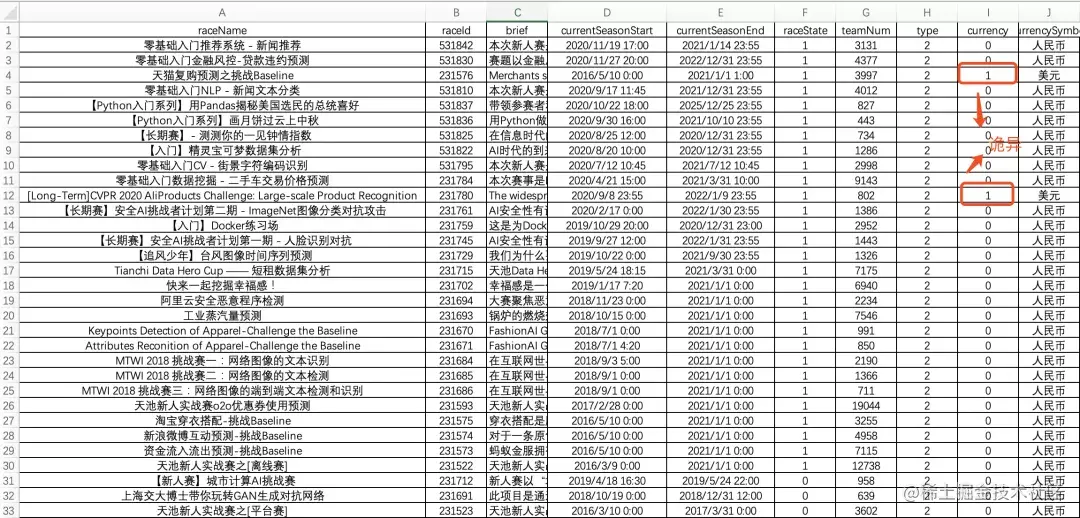
3, Linkage of Python, CSV and MySQL
3.1 about pymysql
Pymysql is a package (module) in python that can connect to MySQL. It requires Python version 3 or above. It is easy to use. It was introduced in the crawler article long ago. For example, xxx also uses pymysql to write data related to medical devices into mysql.
3.2 basic operation code of MySQL
'''
Create a new database
'''
def create_database(database, cursor):
# Create a database, delete the database if it exists, and then create a new one
cursor.execute("drop database if exists %s;"%database)
cursor.execute("create database %s;"%database)
print("Successfully created database:%s"%database)
'''
Create a new data table in the formulation database
'''
def create_table(table_name, table_sql, database, cursor):
# Select database database
cursor.execute("use %s;"%database)
# Create a database named table
# If the table exists, it will be deleted
cursor.execute("drop table if exists %s;"%table_name)
# Create table
cursor.execute(table_sql)
print("Success in database{0}To create a data table in:{1}".format(database,table_name))
'''
Add, delete, query and modify in the data table of the specified database
'''
def sql_basic_operation(table_sql, database, cursor):
# Select database database
cursor.execute("use %s"%database)
# Execute sql statement
cursor.execute(table_sql)
print("sql Statement executed successfully")
'''
Later, we will continue to enrich relevant functions and add web frame flask Linkage in
'''
Copy code
3.3 connect and store data to MySQL
- Connect to MySQL and create a new database
# Connect to the database and add cursor cursor conn = pymysql.connect(host = "localhost",port = 3306,user = "Your username", password = "Yours MySQL password",charset="utf8") cursor = conn.cursor() # Data sheet name database = "tianchi" # Create database create_database(database, cursor) Copy code
- Create a data table
table_name = "competition"
# Create a data table and set raceId as the primary key
table_sql = """create table %s(
raceId int not null auto_increment,
raceName varchar(200),
brief varchar(1000),
currentSeasonStart date,
currentSeasonEnd date,
raceState int,
teamNum int,
type int,
currency int,
currencySymbol char(3),
PRIMARY KEY(raceId));
"""%table_name
create_table(table_name, table_sql, database, cursor)
Copy code
- Read data from CSV
'''
read csv file data
'''
def read_csv(filepath):
# Read the csv file and directly call the read of pandas_ csv function
data = pd.read_csv(filepath, encoding='gbk')
# print(type(data)) # <class 'pandas.core.frame.DataFrame'>
sql_data = []
# Traverse the data in DataFrame format and take out the data in one row
for row in data.itertuples():
# print(type(row)) # <class 'pandas.core.frame.Pandas'>
# print(getattr(row,'raceName')) # Zero basic introduction recommendation system - news recommendation
sql_data.append([getattr(row,'raceId'), getattr(row,'raceName'), getattr(row,'brief'), getattr(row,'currentSeasonStart'), getattr(row,'currentSeasonEnd'),
getattr(row,'raceState'), getattr(row,'teamNum'), getattr(row,'type'), getattr(row,'currency'), getattr(row,'currencySymbol')])
return sql_data
filepath = 'tianchi_competition.csv'
sql_data = read_csv(filepath)
Copy code
- Traverse the data and store it in MySQL
# Circular insert data
for row in sql_data:
# Splicing and inserting sql statements
sql_insert = '''insert into {0} values({1},'{2}','{3}','{4}','{5}',{6},{7},{8},{9},'{10}');
'''.format(table_name,row[0],row[1],row[2],row[3],row[4],row[5],row[6],row[7],row[8],row[9])
# print(sql_insert)
sql_basic_operation(sql_insert, database, cursor)
conn.commit()
# Close connection
conn.close()
cursor.close()
Copy code
3.4 view data storage in MySQL
- Terminal enters mysql
mysql -hlocalhost -uroot -p Copy code
- Select database and view table data
# Select database: tianchi use tianchi; # View data in data table competition select * from competition; Copy code

This completes the linkage among python, csv and mysql.
4, For learning, small analysis
One small demand: the ID, name, number of participants and brief introduction of the top five participants in the learning competition
- Python
filepath = 'tianchi_competition.csv' # Read the csv file and directly call the read of pandas_ csv function data = pd.read_csv(filepath, encoding='gbk') # ID, name, number of participants and introduction of the top five learning competitions currently in progress in the learning competition # 1. Remove closed games data = data[data['raceState']==1] # 2. Sort according to teamNum, in descending order data = data.sort_values(by='teamNum', axis=0, ascending=False) # 3. Take the first 5 and output the specified column data.head(5).ix[:, ['raceId', 'raceName', 'teamNum', 'brief']] Copy code
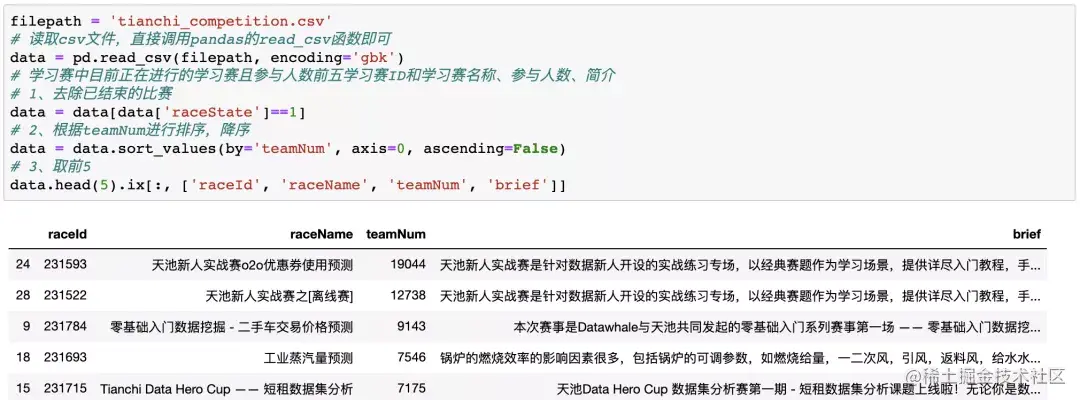
- SQL
select raceId, raceName, teamNum, brief from competition where raceState=1 order by teamNum DESC limit 5; Copy code

- Excel
step1 select the raceState column, click Sort and filter, and select filter
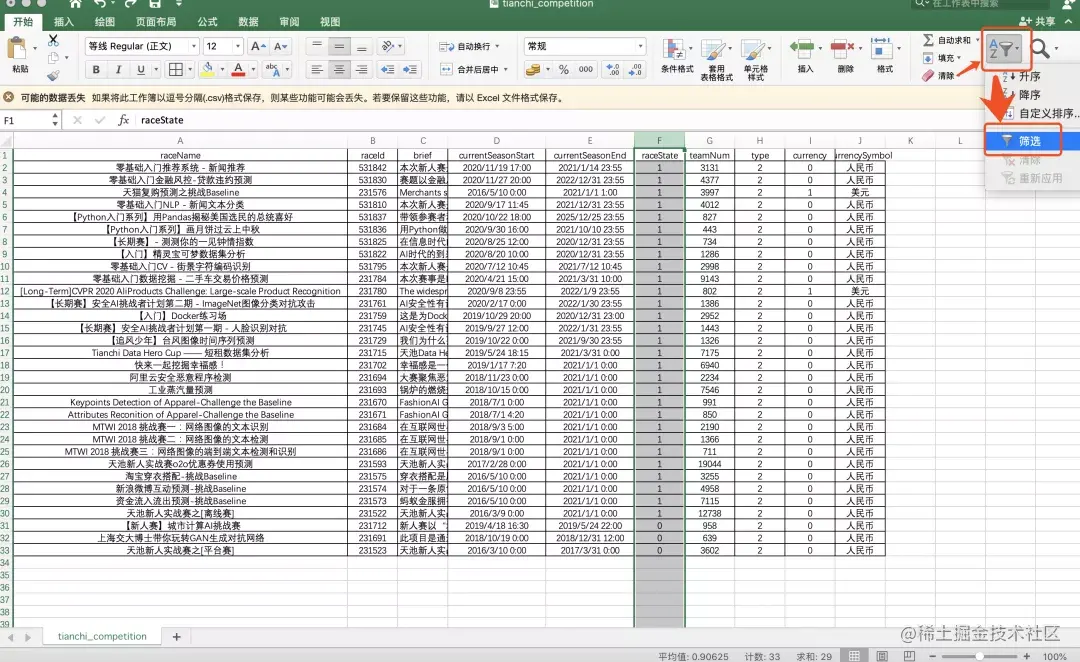
setp2 selects the raceState with a value of 1, indicating the ongoing game
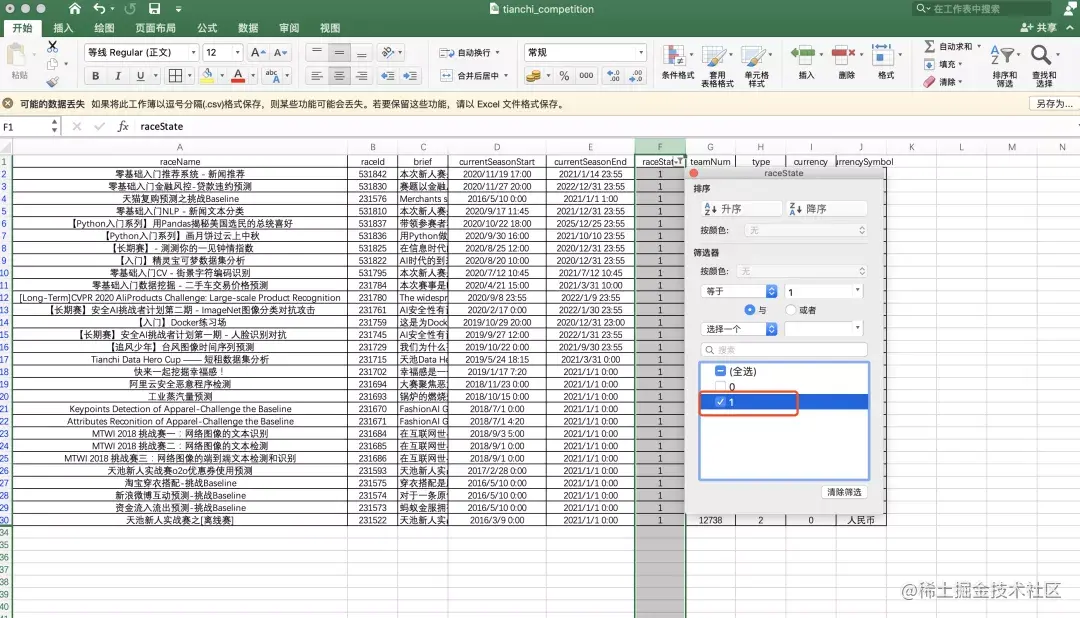
step3 hold down the control key, select and right-click to hide unnecessary columns
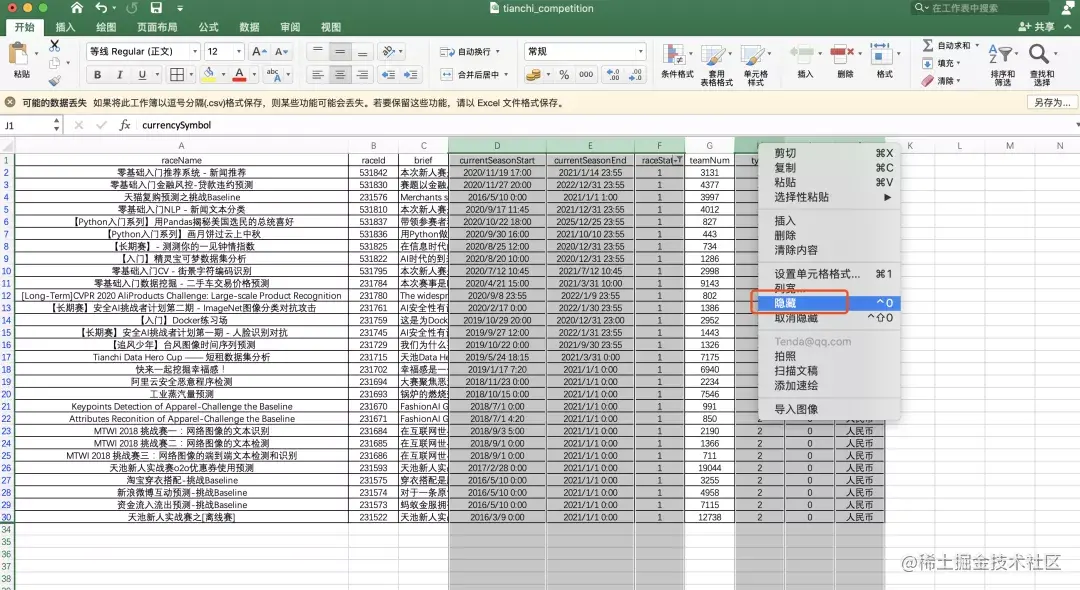
step4 select the teamNum column and click Sort and filter to sort in descending order
step5 copy the first five data to the new table and finish
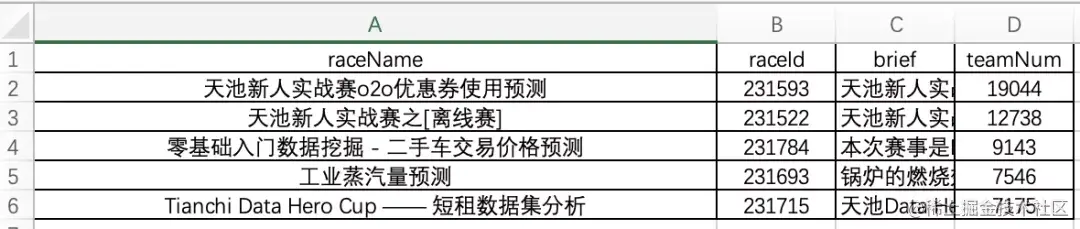
In terms of simplicity and difficulty, SQL may be the most convenient. One SQL statement is done. In terms of universality, Excel has a low threshold, what you see is what you get, and what you want is what you get.
Python is more convenient, especially for learners like me who use Python more. In addition, Python is obviously much more flexible.
