catalogue
Features of performance test tools
Locust performance test tool
Features of performance test tools
loadRunner:
loadrunner is a well-known commercial paid performance testing tool, which is very powerful and complex to use. At present, most books on performance testing are based on this tool, and even some books introduce the use of loadrunner as a whole
JMeter:
JMeter is also a famous open source performance testing tool with perfect functions. Most people use it for interface testing and performance testing
Locust:
locust is also a performance testing tool, but it is quite different from the previous two tools. Compared with the previous two tools, it is much worse in function, but it is not without advantages;
Locust is completely based on Python to become a language, pure python is used to describe the test script, and http requests are completely based on requests library. In addition to the HTTP/HTTP protocol, locust can also test the system of other protocols, just use Python to call the corresponding library for request description;
loadrunner and jmeter use process and thread testing tools, which are difficult to simulate high concurrency pressure on a single machine. The concurrency mechanism of lockust abandons processes and threads and adopts the mechanism of gevent. Cooperative process avoids system level resource scheduling, so it can greatly improve the concurrency of single machine;
For this reason, we chose locust for performance testing. Another reason is that it allows us to understand performance testing in another way, which makes it easier to see the essence of performance testing.
Install Locust
1. Although lockust can still be installed using pip, if you are Python 3, it is recommended to install from GitHub clone project: https://github.com/locustio/locust
2. When we install lockust, we will check whether some dependent libraries are installed in our python environment. If not, they will be installed automatically, and there are requirements for the versions of these libraries, some are equal to a certain version, and some are greater than a certain version. We can install them all according to the requirements, so that we can install locust much faster.
The following are the main uses of these libraries:
Gevent: a third-party library that implements collaborative processes in python. Coroutine, also known as micro thread. High concurrency performance can be achieved with gevent
Flash: a lightweight web backend framework for python
requests: the third-party library used to request interfaces
Msgpack Python: a fast and compact binary serialization format suitable for JSON like data
six: provides some simple tools to encapsulate the differences between python2 and python3
pyzmq: if you plan to run locust on multiple processes / machines, it is recommended to install this
3. Verify the installation through lockust -- help. Note that if there are errors between version numbers here, you can refer to my version number. I'm Python 3 Version 6. Of course, not all of the following packages need to be downloaded. If you report a version error in one of your locust packages, you can refer to and modify my version number. For example, jinja2 and locust have versions corresponding to each other
asgiref==3.3.4 atomicwrites==1.3.0 attrs==19.3.0 certifi==2020.12.5 cffi==1.14.5 chardet==4.0.0 click==7.1.2 colorama==0.4.3 ConfigArgParse==1.4.1 dataclasses==0.8 Django==3.2.2 djangorestframework==3.12.4 Flask==1.1.2 Flask-BasicAuth==0.2.0 gevent==21.1.2 geventhttpclient==1.4.4 greenlet==1.1.0 idna==2.10 itsdangerous==2.0.0 Jinja2==2.10.3 locust==1.4.3 lxml==4.6.3 MarkupSafe==2.0.0 more-itertools==8.2.0 msgpack==0.6.2 mysqlclient==2.0.3 packaging==20.1 pluggy==0.13.1 psutil==5.8.0 pycparser==2.20 PyMySQL==1.0.2 pyparsing==2.4.7 pytest==6.2.4 pytest-metadata==1.8.0 python-docx==0.8.11 pytz==2021.1 pywin32==300 pyzmq==22.0.3 requests==2.25.1 six==1.16.0 sqlparse==0.4.1 toml==0.10.2 typing==3.7.4.3 urllib3==1.26.4 wcwidth==0.1.8 Werkzeug==1.0.1 zipp==3.0.0 zope.event==4.5.0 zope.interface==5.4.0
Performance test cases
1. Create a py file for presentation
If importerror appears: the httplocate class has been renamed to HttpUser in version 1.0 An error is reported. The class HttpLocust has been renamed as HttpUser in version 1.0
task_set is deprecated since version 1.0_ Set = userbehavior changed to task_create=UserBehavior, because instantiation is not supported after version 1.0
use the @task decorator or set the tasks property of the User_ Change create to tasks setting
from locust import HttpUser, TaskSet, task, between
# Define user behavior classes
class UserBehavior(TaskSet):
@task#Task item
def baidu_page(self):
res = self.client.get("/")
print(res)
class WebsiteUser(HttpUser):
#task_create=UserBehavior
tasks = [UserBehavior]
# min_wait=3000
# max_wait=6000
wait_time = between(3, 7)
if __name__ == '__main__':
import os
os.system("locust -f test_locust.py --host=https://www.baidu.com")
#-f specify the file
#--host specifies the url to be tested 2. Start lockust:
4. adopt http://localhost:8088/ Access, Number of total users to simulate, set the number of simulated users, and the number of virtual users started per second by the span rate (users spawned/second)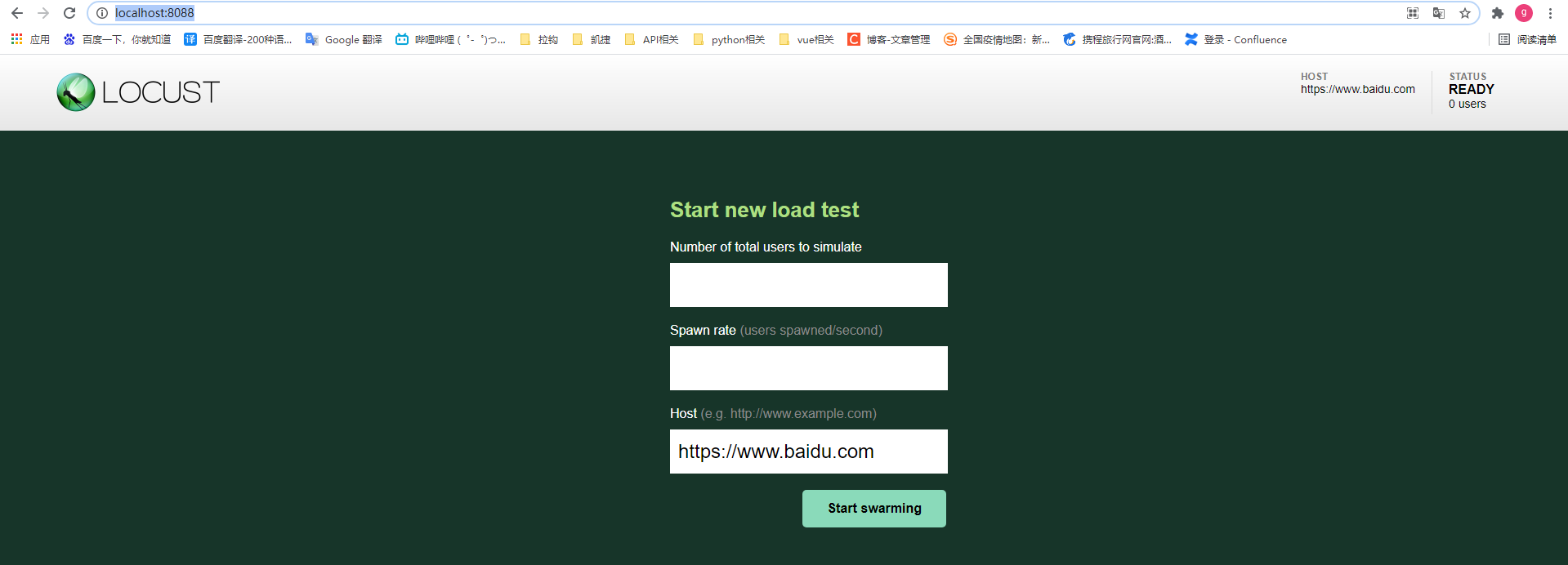
5. Enter the number of users and the number of users started per second. Set 1 here to access Baidu; The performance parameters are as follows:
Type: request type, such as Get/Post
Name: request path
Requests: current number of requests
Failures: number of failed requests
Median: the median value is milliseconds. Half of the server responses are lower than this value and half are higher than this value
90%: 90% request response time
Average: the average value, in milliseconds, and the average response time of all requests
Min: minimum response time of the requested server
Max: maximum response time of the requested server
Average size: the size of a single request, in bytes
RPS: number of requests that can be processed per second

15. Some commonly used instruction parameters of lockust
-h, --help view help -H HOST, --host=HOST Domain name of the server under test --web-host=WEB_HOST locust Service web Interface -P PORT, --port=PORT, --web-port=PORT appoint –web-host The default port is 8089 -f Script path. You can write relative paths or absolute paths. If the script is in the current directory, write the relative path. If not, write the Jedi path. --csv=CSVFILEBASE, --csv-base-name=CSVFILEBASE with CSV Store the current requested test data in the format, csv File storage current directory --master Mark which host is used for pressure measurement. The host is only used for statistics, not for pressure. The task of pressure is left to slave Extension. If you want to put pressure on the host, you should also start one on the host slave. --slave When doing distributed pressure measurement, mark which are used as extensions. The main task of the extension is to exert pressure. --master-host When doing distributed pressure measurement, specify the of the host IP. Only for slave. If not specified, the default is "127".0.0.1". --master-port When doing distributed pressure measurement, specify the of the host port. Only for slave. If it is not specified and the host is not modified, the default is 5557. --master-bind-host When doing distributed pressure measurement, specify the extension IP. Only for master. If not specified, the default is all available IP(All tagged hosts IP of slave) --master-bind-port When doing distributed pressure measurement, specify the extension port. The default is 5557 and 5558. --heartbeat-liveness=HEARTBEAT_LIVENESS set number of seconds before failed heartbeat from slave --heartbeat-interval=HEARTBEAT_INTERVAL set number of seconds delay between slave heartbeats to master --expect-slaves=EXPECT_SLAVES How many secondary hosts need to be connected before starting the test(only --no-web use). --no-web no-web Specify mode, requirements-c and-r. -c NUM_CLIENTS, --clients=NUM_CLIENTS Number of concurrent users. Only used togetherwith --no-web -r HATCH_RATE, --hatch-rate=HATCH_RATE The per second rate of users generated. and--no-web Use together -t RUN_TIME, --run-time=RUN_TIME Stop after specified time, as (300s,20m, 3h, 1h30m, etc.). and--no-web Use together -L LOGLEVEL, --loglevel=LOGLEVEL Log level( DEBUG/INFO/WARNING/ERROR/CRITICAL.default INFO.) --logfile=LOGFILE The path to the log file. If not set, the log will go to stdout/stderr --print-stats Print statistics in the console --only-summary Print summary statistics only --no-reset-stats [DEPRECATED] Do not reset statistics once hatching has been completed. This is now the default behavior. See --reset-stats to disable --reset-stats Reset statistics once hatching has been completed. Should be set on both master and slaves when running in distributed mode -l, --list Show possible locust Class list and exit --show-task-ratio Print locust Class task execution rate table --show-task-ratio-json Print locust Implementation rate of class tasks JSON data -V, --version locust edition
Well, locust is here first, because it's not a professional to do this. It's just to record a learning process. There's time later. I'll give a tutorial on the web, mobile UI and interface automation, PO framework, data-driven keywords, underlying code encapsulation and distributed multithreading, as well as the complete scheme of docking test platform that has been implemented, Continuous update maintenance