What is K-nearest neighbor algorithm?
K-nearest neighbor algorithm (KNN) is one of the classification algorithms. KNN classifies new data by calculating the distance between new data and data points of different categories in historical sample data. Simply put, it is to classify and predict the new data through the k data points closest to the new data points. K-Neighborhood classification algorithm is one of the simplest algorithms in data mining (classification) technology. Its guiding ideology is "those who are close to each other are red and those who are close to each other are black", that is, your neighbors infer your category.
Working principle of k-proximity algorithm
There is a sample data set, also known as the training sample set, and each data in the sample set has a label, that is, we know the corresponding relationship between each data in the sample set and its classification. After entering the new data without a label, compare each feature of the new data with the corresponding feature of the data in the sample set, and then the algorithm extracts the data with the most similar feature in the sample set (nearest) In general, we only select the first k most similar data in the sample data set, which is the source of K in the k-proximity algorithm. Generally, K is an integer not greater than 20. Finally, we select the classification that appears most in the k most similar data as the classification of new data. The k-proximity model is determined by three basic elements - distance measurement, K value selection and classification decision rules.
A classical example of K-nearest neighbor algorithm
Based on the funny, hugging and fighting scenes in the film, the subject types of the film can be automatically divided by using the k-nearest neighbor algorithm to construct the program. (figure comes from the detailed explanation of KNN (k-nearest neighbor) algorithm of machine learning)
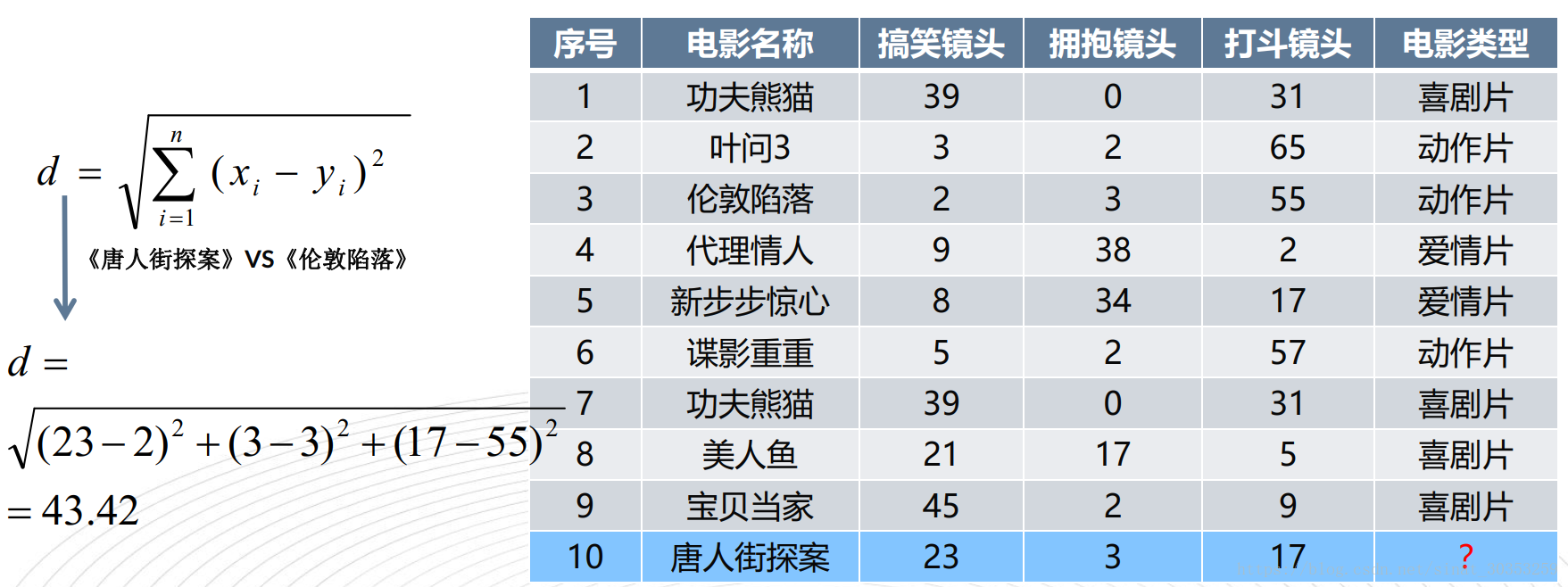
d is the Euclidean distance between Chinatown detective and each film in the list
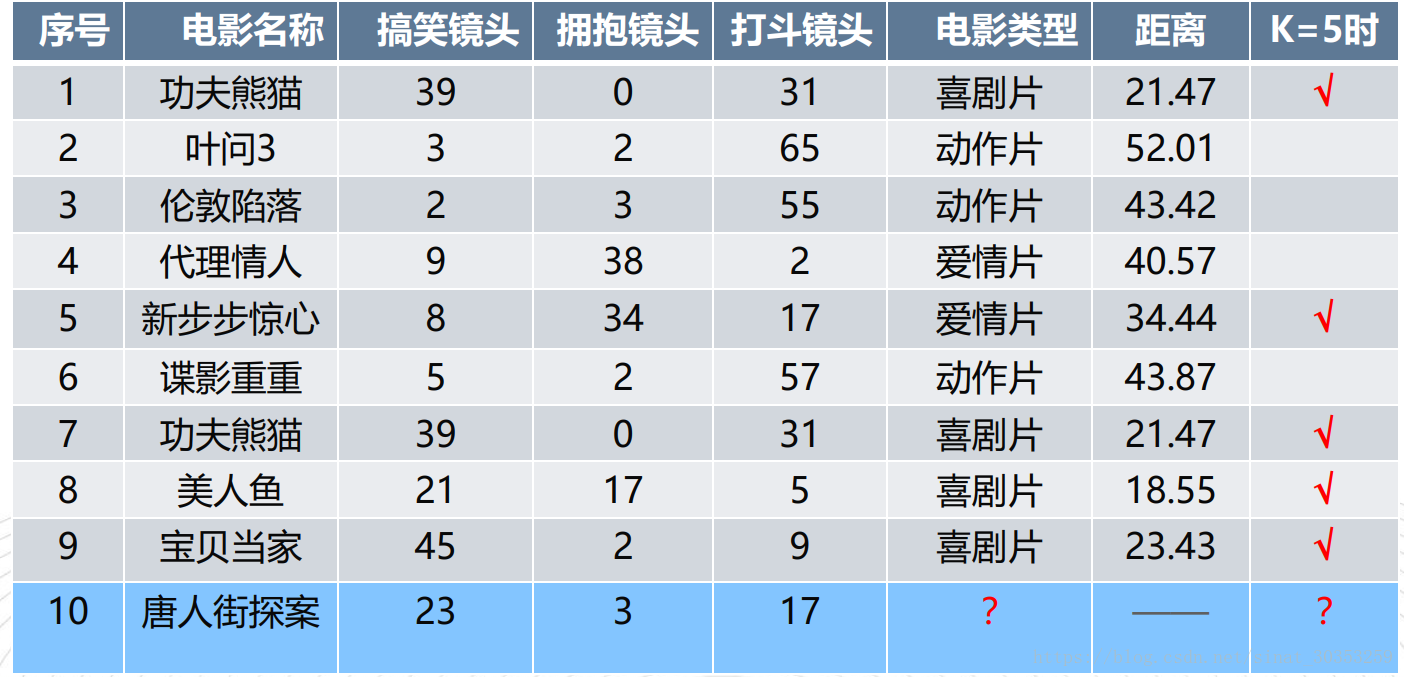
As shown in the figure, there are four comedies and one love film among the five films closest to Chinatown detective. Therefore, Chinatown detective is a comedy.
Two methods for distance calculation of K-nearest neighbor algorithm
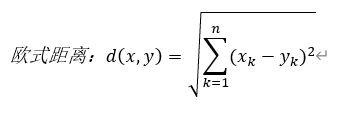
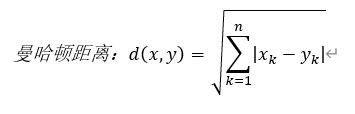
General flow of K-nearest neighbor algorithm
(1) Collect data: any method can be used.
(2) Prepare data: the value required for distance calculation, preferably in a structured data format.
(3) Analyze data: any method can be used
(4) Training algorithm: this algorithm is not applicable to K-neighbor algorithm
(5) Test algorithm: calculate error rate
(6) Using the algorithm: first, input the sample data and structured output results, then run the K-neighbor algorithm to determine which classification the input data belongs to respectively, and finally perform subsequent processing on the calculated classification.
Example of K-proximity algorithm: recognition of digital handwriting
# -*- coding:utf-8 -*-
# -*- author: zzZ_CMing
# -*- 2017/12/25
# -*- python3.5
import numpy as np
from image import image2onebit as it
import sys
from tensorflow.examples.tutorials.mnist import input_data
import math
import datetime
#KNN algorithm main body: calculate the distance between test samples and each training sample
def get_index(train_data,test_data, i):
#1, np.argmin(np.sqrt(np.sum(np.square(test_data[i]-train_data),axis=1)))
#2. a array storage: the distance between the test sample and each training sample
all_dist = np.sqrt(np.sum(np.square(test_data[i]-train_data),axis=1)).tolist()
return all_dist
#Main body of KNN algorithm: calculate and find the predicted values corresponding to the nearest K training sets
def get_number(all_dist):
all_number = []
min_index = 0
#print('distance list: ', all_dist,)
for k in range(Nearest_Neighbor_number):
# Minimum index value = subscript number of the minimum distance
min_index = np.argmin(all_dist)
#According to the minimum index value (the subscript number of the minimum distance), the predicted value is mapped and found
ss = np.argmax((train_label[min_index])).tolist()
print('The first',k+1,'Secondary predicted value:',ss)
#Change the predicted value into a string and store it in the new element group bb
all_number = all_number + list(str(ss))
#In the distance array, delete the smallest distance value
min_number = min(all_dist)
xx = all_dist.index(min_number)
del all_dist[xx]
print('Predicted value overall result:',all_number)
return all_number
#Main body of KNN algorithm: among the K predicted values, find the mode, find the category that belongs to the most, and output
def get_min_number(all_number):
c = []
#Convert string to int and pass in a new list c
for i in range(len(all_number)):
c.append(int(all_number[i]))
#Find mode
new_number = np.array(c)
counts = np.bincount(new_number)
return np.argmax(counts)
t1 = datetime.datetime.now() #Timing start
print('Note: the value range of the number of training sets is[0,60000],K Best value<10\n' )
train_sum = int(input('Enter number of training sets:'))
Nearest_Neighbor_number = int(input('Select the nearest K Values, K='))
#Find and read the image data set for training and testing according to the file name
mnist = input_data.read_data_sets("./MNIST_data", one_hot=True)
#Take out the training set data and training set label
train_data, train_label = mnist.train.next_batch(train_sum)
#Call the read_image() function in the self created module: pass in the image processing according to the path and convert the image information into numpy.array type
x1_tmp = it.read_image("png/55.png")
test_data = it.imageToArray(x1_tmp)
test_data = np.array(test_data)
#print('test_data',test_data)
#Call the function show_ndarray() in the self created module: print pictures with character matrix
it.show_ndarray(test_data)
#KNN algorithm body
all_dist = get_index(train_data,test_data,0)
all_number = get_number(all_dist)
min_number = get_min_number(all_number )
print('The final predicted value is:',min_number)
t2=datetime.datetime.now()
print('Time consuming = ',t2-t1)
Evaluation: the training set and test set data used are from the classic MNIST handwritten numeral data set of Google. The program limits the size of picture data to 28 * 28, that is, there are 784 pixels in total, so the defect is (it should be said that the KNN algorithm is flawed)
Most of the pixels occupied by data pictures are very close, and the distance discrimination is relatively low;
The internal structural characteristics between different numbers are not considered
Summarize the advantages and disadvantages of K-nearest neighbor algorithm
Advantages: simple, easy to understand, without modeling and training, easy to implement; suitable for classification of rare events; suitable for multi classification problems, such as judging its functional classification according to gene characteristics.
Disadvantages: inert algorithm, large memory overhead, large amount of calculation and low performance when classifying test samples; poor interpretability, unable to give rules like decision tree.