This article mainly introduces the example code of Python's multi-threaded crawler to grab web page pictures. Xiaobian thinks it's very good. Now I'll share it with you and give you a reference. Let's follow Xiaobian and have a look
target
Well, we know that there are many beautiful and beautiful pictures when searching or browsing websites.
When we download, we have to download one by one with the mouse and turn the page.
So, is there a way to automatically identify and download pictures in a non manual way. Meimeida.
Then please use python language to build a crawler to capture and download web page images.
Of course, in order to improve efficiency, we use multi-threaded parallel mode at the same time.
Train of thought analysis
Python has many third-party libraries that can help us achieve a variety of functions. The problem is that we figure out what we need:
1) http request library, according to the website address, you can get the web page source code. You can even download pictures and write them to disk.
2) Analyze the web page source code and identify the picture connection address. Such as regular expressions, or simple third-party libraries.
3) Support for building multithreads or thread pools.
4) If possible, you need to fake the browser or bypass the website verification. Well, the website may be anti crawler 😉)
5) If possible, you also need to automatically create directories, random numbers, date and time, etc.
So, we started doing things. O(∩_∩)O~
Environment configuration
Operating system: windows or linux
Python version: Python 3.6 (not Python 2. X)
Third party Library
urllib.request
threading or concurrent.futures multithreading or thread pool (Python 3.2 +)
re regular expression built-in module
os operating system built-in module
Coding process
Let's break down the process. The complete source code is finally provided in the blog.
Disguised as a browser
import urllib.request
# ------Disguised as a browser---
def makeOpener(head={
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:57.0) Gecko/20100101 Firefox/57.0'
}):
cj = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
Get web page source code
# ------Get web page source code---
# url web page link address
def getHtml(url):
print('url='+url)
oper = makeOpener()
if oper is not None:
page = oper.open(url)
#print ('-----oper----')
else:
req=urllib.request.Request(url)
# Crawler camouflage browser
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64; rv:57.0) Gecko/20100101 Firefox/57.0')
page = urllib.request.urlopen(req)
html = page.read()
if collectHtmlEnabled: #Collect html
with open('html.txt', 'wb') as f:
f.write(html) # Collect local files for analysis
# ------Modify the character encoding in the html object to UTF-8------
if chardetSupport:
cdt = chardet.detect(html)
charset = cdt['encoding'] #Content analysis with chardet
else:
charset = 'utf8'
try:
result = html.decode(charset)
except:
result = html.decode('gbk')
return result
Download a single picture
# ------Download the picture according to the picture url------
# folderPath defines the directory imgUrl where pictures are stored. The index of the link address of a picture indicates the number of pictures
def downloadImg(folderPath, imgUrl, index):
# ------Exception handling------
try:
imgContent = (urllib.request.urlopen(imgUrl)).read()
except urllib.error.URLError as e:
if printLogEnabled : print ('[Error] the current picture cannot be downloaded')
return False
except urllib.error.HTTPError as e:
if printLogEnabled : print ('[Error] current picture download exception')
return False
else:
imgeNameFromUrl = os.path.basename(imgUrl)
if printLogEnabled : print ('Downloading page'+str(index+1)+'Picture, picture address:'+str(imgUrl))
# ------IO processing------
isExists=os.path.exists(folderPath)
if not isExists: # Directory does not exist, create
os.makedirs( folderPath )
#print ('create directory ')
# Picture name naming rules, random string
imgName = imgeNameFromUrl
if len(imgeNameFromUrl) < 8:
imgName = random_str(4) + random_str(1,'123456789') + random_str(2,'0123456789')+"_" + imgeNameFromUrl
filename= folderPath + "\\"+str(imgName)+".jpg"
try:
with open(filename, 'wb') as f:
f.write(imgContent) # Write to local disk
# If printlogenabled: Print ('download completed '+ str(index+1) +' picture ')
except :
return False
return True
Download a batch of pictures (both multithreading and thread pool modes are supported)
# ------Batch download pictures------
# folderPath defines the directory where pictures are stored imgList the link addresses of multiple pictures
def downloadImgList(folderPath, imgList):
index = 0
# print ('poolSupport='+str(poolSupport))
if not poolSupport:
#print ('multithreading mode ')
# ------Multithreaded programming------
threads = []
for imgUrl in imgList:
# If printlogenabled: Print ('ready to download the '+ str(index+1) +' picture ')
threads.append(threading.Thread(target=downloadImg,args=(folderPath,imgUrl,index,)))
index += 1
for t in threads:
t.setDaemon(True)
t.start()
t.join() #Parent thread, waiting for all threads to end
if len(imgList) >0 : print ('After downloading, save the picture Directory:' + str(folderPath))
else:
#print ('thread pool mode ')
# ------Thread pool programming------
futures = []
# Create a thread pool that can hold up to N task s. thePoolSize is a global variable
with concurrent.futures.ThreadPoolExecutor(max_workers=thePoolSize) as pool:
for imgUrl in imgList:
# If printlogenabled: Print ('ready to download the '+ str(index+1) +' picture ')
futures.append(pool.submit(downloadImg, folderPath, imgUrl, index))
index += 1
result = concurrent.futures.wait(futures, timeout=None, return_when='ALL_COMPLETED')
suc = 0
for f in result.done:
if f.result(): suc +=1
print('Download completed, total:'+str(len(imgList))+',Number of successes:'+str(suc)+',Directory for storing pictures:' + str(folderPath))
Call example
Take Baidu Post Bar as an example
# ------Download all pictures in Baidu Post------
# folderPath defines the url of the directory where pictures are stored Baidu Post Bar link
def downloadImgFromBaidutieba(folderPath='tieba', url='https://tieba.baidu.com/p/5256331871'):
html = getHtml(url)
# ------Using regular expressions to match web content to find image addresses------
#reg = r'src="(.*?\.jpg)"'
reg = r'src="(.*?/sign=.*?\.jpg)"'
imgre = re.compile(reg);
imgList = re.findall(imgre, html)
print ('Number of pictures found:' + str(len(imgList)))
# Download pictures
if len(imgList) >0 : downloadImgList(folderPath, imgList)
# Program entry
if __name__ == '__main__':
now = datetime.datetime.now().strftime('%Y-%m-%d %H-%M-%S')
# Download all pictures in Baidu Post
downloadImgFromBaidutieba('tieba\\'+now, 'https://tieba.baidu.com/p/5256331871')
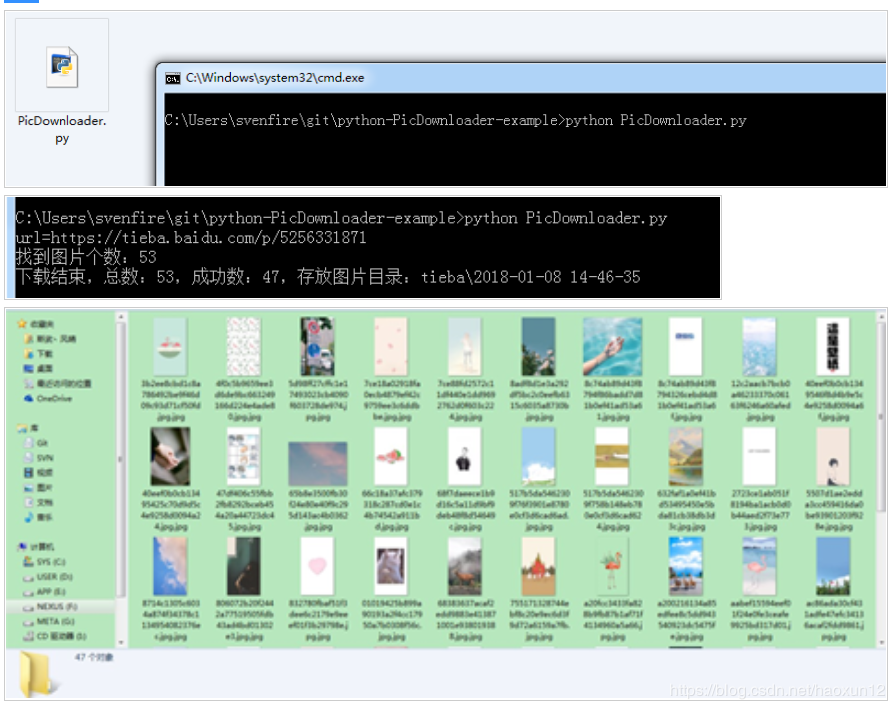
The effect is shown in the figure
Click to learn more about Python web development, data analysis, crawler, artificial intelligence and other learning knowledge,
- The receiving data are as follows:
- 1. Like + comment
- 2. Pay attention to Xiaobian and receive the background private letter "01" for free