Python - pandas module - DataFrame data structure
pandas
- Numpy is more suitable for dealing with unified numerical array data
- pandas is specially designed to handle tables and mixed data
- panda has two data structures:
- Series
- DataFrame
DataFrame
- DataFrame is a tabular (similar to Excel) data structure, which contains a set of ordered columns. Each column can be of different value types (value, string, bool, etc.)
- Compared with Series (only row index), DataFrame has both row index and column index
- It can be regarded as a dictionary composed of multiple Series sharing a column index
Create DataFrame object
Create function
obj = pandas.Dataframe()#Create function
Create from dictionary
- Define a dictionary
- The key of the dictionary is the column name of the DataFrame
- The value of the dictionary is a serise values
- When the index of the Dataframe is not set, it is transmitted to 0~N by default
Take an example:
'''establish DataFrema'''
import pandas as pd
#Define a dictionary
dic = {'state':['Ohio','Ohio','Ohio','Nevada','Nevada','Nevada'],'year':[2000,2001,2002,2001,2002,2003],'pop':[1.5,1.7,3.6,2.4,2.9,3.2]}
#Create objects through DataFrame()
frame = pd.DataFrame(dic)
print('Create a dictionary without passing in a specified index of DataFrame Object:')
print(frame)

Created from a two-dimensional array
It's just that the elements created through a two-dimensional array are of the same type
If the index columns and index are not re passed in, they are assigned from 0 to n
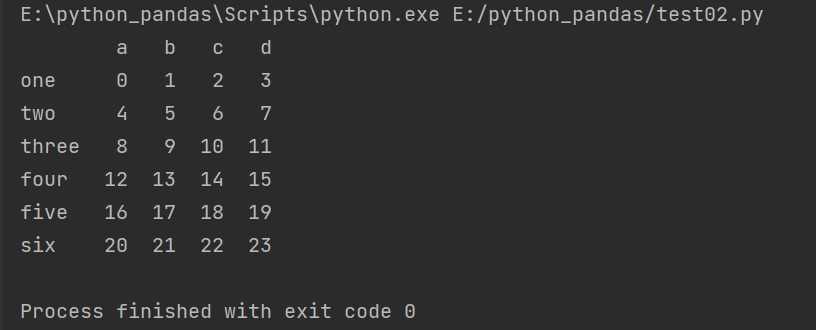
import pandas as pd import numpy as np arr = np.arange(24).reshape(6,4) frame = pd.DataFrame(arr,columns=['a','b','c','d'],index=['one','two','three','four','five','six']) print(frame)
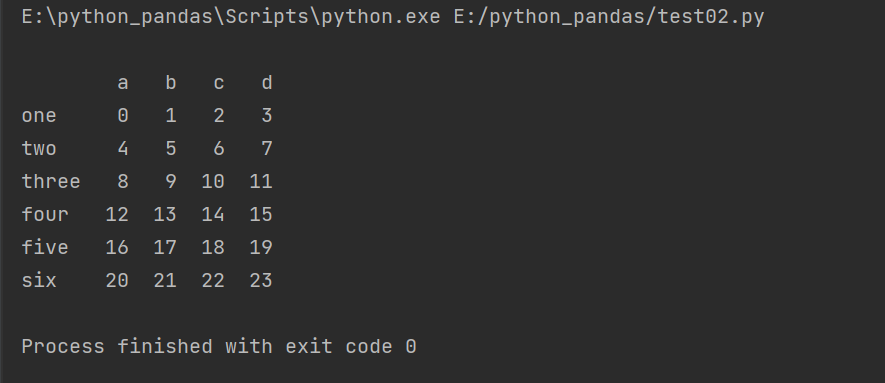
columns = specify column name, index = specify row index
Modify the column name of the frame
It is actually indexed in the dictionary according to the value passed in by columns
When the specified column name is included in the dictionary key
'''Specify column name'''
frame2 = pd.DataFrame(dic,columns=['pop','year','state'])
print('After modifying the column name DataFrame')
print(frame2)
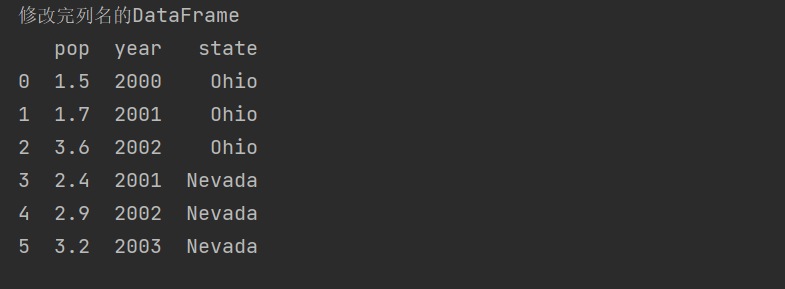
When the specified column name is not included in the dictionary key
When the specified column name is not included in the dictionary key and the index cannot be found,
Create a new column with the value set to NaN (resulting in missing values)
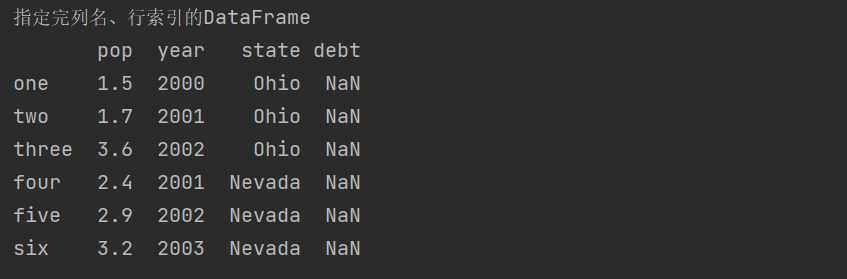
'''The specified column names are not all in key in'''
frame3 = pd.DataFrame(dic,columns=['pop','year','state','debt'],index=['one','two','three','four','five','six'])
print('Specify the column name and row index DataFrame')
print(frame3)
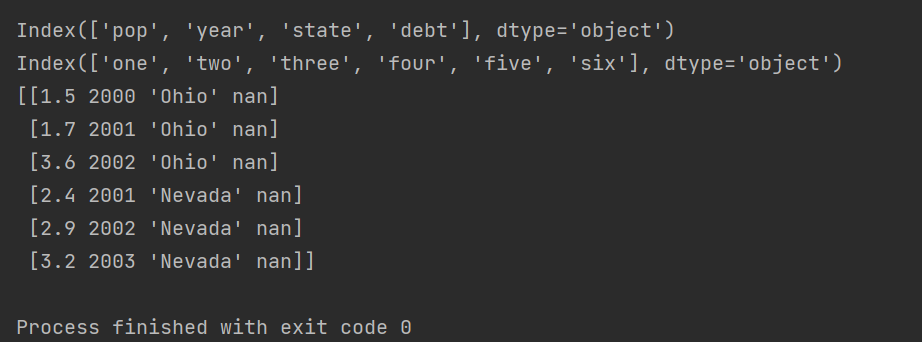
View attribute values
View columns (column index)
print(frame3.columns)
View index (row index)
print(frame3.index)
View values (element array)
print(frame3.values)
Index column: view the specified column (return a Series)
Returns a Series
DataFrema.column
print('yera Columnar Series')
print(frame.year)
To view the specified column type:
print('year The data type of the column')
print(type(frame.year))

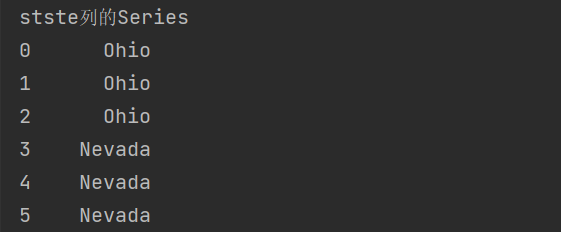
DataFrema[column]
#DataFrema[column]
print('stste Columnar Series')
print(frame['state'])
Index row: view the specified row
In Sreies, we use series [index], but in DataFrema, this method has been occupied by index columns, so we use another method to index columns
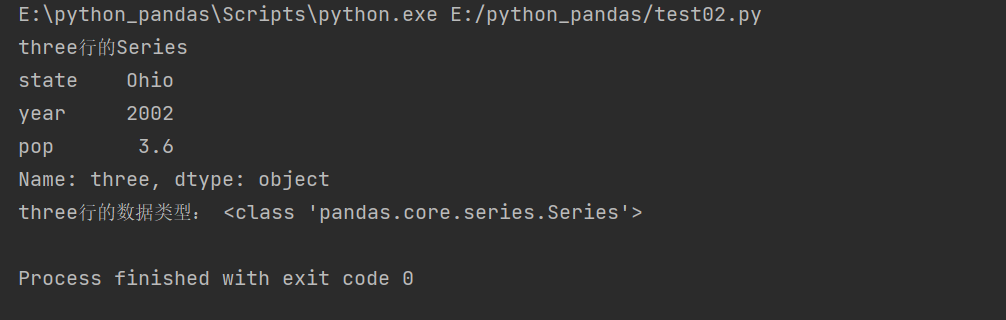
DataFrame.loc[index]
The data type of the row element is also a Series
import pandas as pd
dic = {'state':['Ohio','Ohio','Ohio','Nevada','Nevada','Nevada'],'year':[2000,2001,2002,2001,2002,2003],'pop':[1.5,1.7,3.6,2.4,2.9,3.2]}
frame = pd.DataFrame(dic,index=['one','two','three','four','five','six'])
print('three OK Series')
print(frame.loc['three'])
print('three Data type of row:',type(frame.loc['three']))
DataFrame.iloc [line number]
Line number starts at 0
print('Data in row 0 Series:')
print(frame.iloc[0])
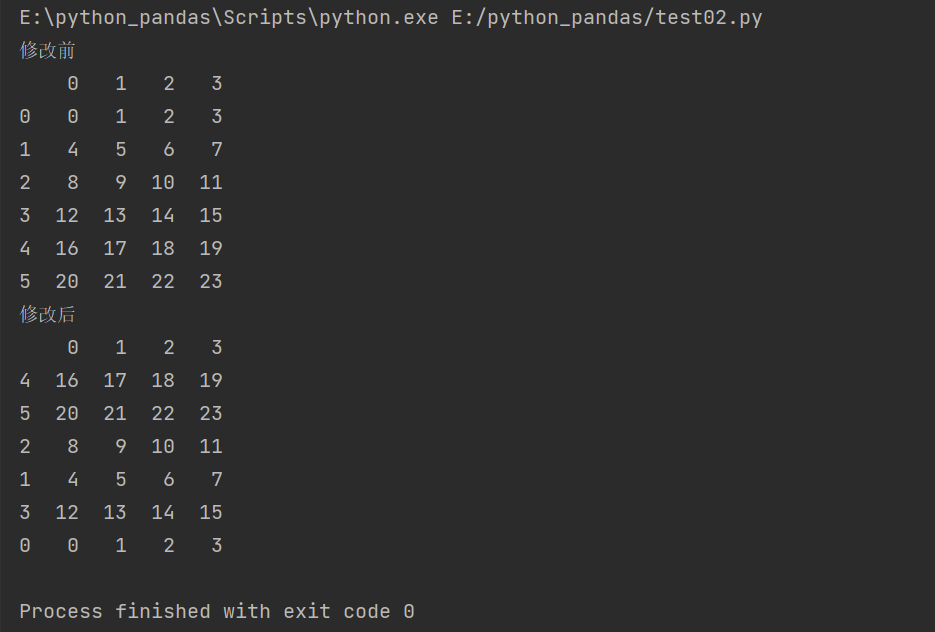
Re index row dataframe reindex()
Change row position
'''Modify the row index. Column index'''
import pandas as pd
import numpy as np
arr = np.arange(24).reshape(6,4)
frame = pd.DataFrame(arr)
print('Before modification')
print(frame)
#Modify row index
frame2 = frame.reindex([4,5,2,1,3,0])
print('After modification')
print(frame2)
DataFrame.index = [] modify row index
DataFrame.columns = [] modify column index
Modify index
#Modify index name import pandas as pd import numpy as np arr = np.arange(24).reshape(6,4) frame = pd.DataFrame(arr) #Modify index name frame.columns=['a','b','c','d'] frame.index=['one','two','three','four','five','six'] #After modifying the index name print(frame
Addition, deletion and modification of rows and columns
appoint:
axis = 1 indicates the column
Default representation line
data = DataFrame.drop(Listing, axis = 1) data = DataFrame.drop(Row name)