Official website: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.aggregate.html
objective
The main line of this article is to explore the basic usage of agg and the corresponding applicable scenarios, and finally make a simple exploration of the source code layer.
1. This paper introduces the parameters of agg and its demo
2. agg usage case of GroupBy
3. By viewing the route principle of the underlying deduction agg
1. This paper introduces the parameters of agg and its demo
agg is an alias for aggregate
DataFrame.aggregate(func=None, axis=0, args,kwargs)
| Parameter name | explain | Parameter transfer format | for example |
|---|---|---|---|
| func | Function for summarizing data. If it is a DataFrame function, it must be passed to DataFrame Apply works. | Function, str, list or dictionary | [np.sum, 'mean'] |
| axis | If it is 0 or 'index': apply the function to each column. If 1 or column: applies the function to each row. | {0 or 'index', 1 or 'columns'}, default 0 | 1 |
The data types it return s are generally scalar (value), Series and DataFrame.
Corresponding can be used
Scalar: use a single function to call series agg
Series: use a single function to call dataframe agg
DaFrame: call dataframe with multiple functions agg
Return example
scalar
s_df = pd.Series([1,2,3]) print(s_df) print(s_df.agg(sum)) ---------return---------- 0 1 1 2 2 3 dtype: int64 6
Seires
df = pd.DataFrame([[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[np.nan, np.nan, np.nan]],
columns=['A', 'B', 'C'])
print(df)
-----return------
A B C
0 1.0 2.0 3.0
1 4.0 5.0 6.0
2 7.0 8.0 9.0
3 NaN NaN NaN
print(df.agg(sum))
----return------
A 12.0
B 15.0
C 18.0
dtype: float64
DataFrame
# Summarize these functions on the line
print(df.agg(['sum', 'min'])
----return----
A B C
sum 12.0 15.0 18.0
min 1.0 2.0 3.0
# Different aggregations per column
print(df.agg({'A' : ['sum', 'min'], 'B' : ['min', 'max']}))
----return----
A B
sum 12.0 NaN
min 1.0 2.0
max NaN 8.0
# Aggregate different functions on the column and rename the index of the resulting DataFrame
print(df.agg(x=('A', max), y=('B', 'min'), z=('C', np.mean)))
----return----
A B C
x 7.0 NaN NaN
y NaN 2.0 NaN
z NaN NaN 6.0
2. agg usage case of GroupBy
Data structure
import pandas as pd
df = pd.DataFrame({'Country':['China','China', 'India', 'India', 'America', 'Japan', 'China', 'India'],
'Income':[10000, 10000, 5000, 5002, 40000, 50000, 8000, 5000],
'Age':[5000, 4321, 1234, 4010, 250, 250, 4500, 4321]})
----return----
Age Country Income
0 5000 China 10000
1 4321 China 10000
2 1234 India 5000
3 4010 India 5002
4 250 America 40000
5 250 Japan 50000
6 4500 China 8000
7 4321 India 5000
Next, we will group according to cities and use the print() method to give the grouping logic of cognitive groupby
df.groupby(['Country']).apply(lambda x: print(x,type(x))) ----print---- Country Income Age 4 America 40000 250 <class 'pandas.core.frame.DataFrame'> Country Income Age 0 China 10000 5000 1 China 10000 4321 6 China 8000 4500 <class 'pandas.core.frame.DataFrame'> Country Income Age 2 India 5000 1234 3 India 5002 4010 7 India 5000 4321 <class 'pandas.core.frame.DataFrame'> Country Income Age 5 Japan 50000 250 <class 'pandas.core.frame.DataFrame'>
In fact, it's very clear here. The result of grouping is the dataframes after grouping. Therefore, the usage of agg after Groupby is DataFrame The usage of agg, needless to say, is still passed in the form of list and dictionary.
List transfer parameter
df_agg = df.groupby('Country').agg(['min', 'mean', 'max'])
print(df_agg)
----print----
Income Age
min mean max min mean max
Country
America 40000 40000.000000 40000 250 250.000000 250
China 8000 9333.333333 10000 4321 4607.000000 5000
India 5000 5000.666667 5002 1234 3188.333333 4321
Japan 50000 50000.000000 50000 250 250.000000 250
Dictionary reference
print(df.groupby('Country').agg({'Age':['min', 'mean', 'max'], 'Income':['min', 'max']}))
---print---
Age Income
min mean max min max
Country
America 250 250.000000 250 40000 40000
China 4321 4607.000000 5000 8000 10000
India 1234 3188.333333 4321 5000 5002
Japan 250 250.000000 250 50000 50000
==Summary: = = first understand what form of func can be transmitted by agg, and then clarify the form of groupby to know the usage of the combination of groupy+agg.
3. By viewing the route principle of the underlying deduction agg
Why check this bottom layer? I'm mainly curious about these kinds of transmission parameters when transmitting func. I want to know why I can transmit like this and trace back to the source.
These parameters refer to:
df = pd.DataFrame([[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[np.nan, np.nan, np.nan]],
columns=['A', 'B', 'C'])
print(df.agg([sum, 'sum', np.sum]))
------print-----
A B C
sum 12.0 15.0 18.0
sum 12.0 15.0 18.0
sum 12.0 15.0 18.0
sum,"sum",np.sum has the same function and effect, and their expression forms are different.
Start looking at the underlying code
1. agg = aggregate, agg is the alias of aggregate, because the underlying code has this assignment statement at the beginning.
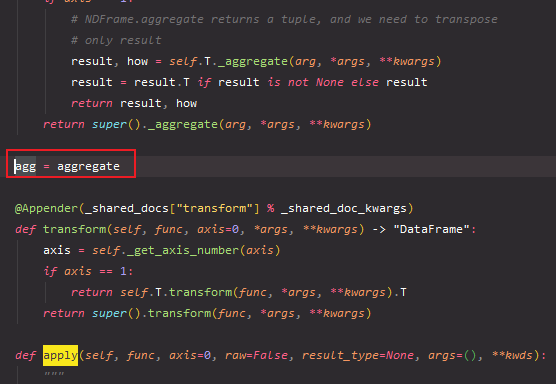
2. agg is actually calling the apply function, that is, it can also be used if the apply function can be used
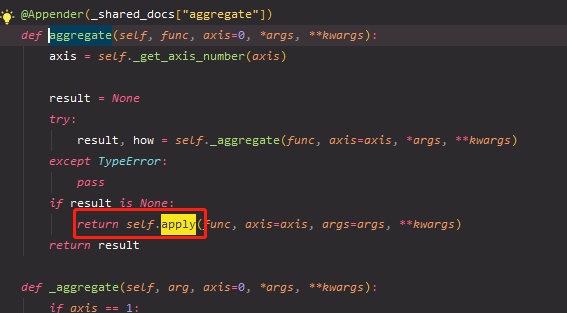
-
Make a test and see that the returned results are the same.
-
print(df.apply([sum, 'sum', np.sum])) ----return---- A B C sum 12.0 15.0 18.0 sum 12.0 15.0 18.0 sum 12.0 15.0 18.0
3. So sum, 'sum', NP Sum focuses on the function of func parameter analysis, not the function itself.
Look for comments about func
func : function
Function to apply to each column or row.
# Interpretation functions can only be used for rows or columns
If you are just applying a NumPy reduction function this will
achieve much better performance.
# Here we say that if we use the function of numpy, we can have better performance, which can explain NP Sum and sum are functions that call different modules
After looking for it for a long time, I guessed that 'sum' was converted to sum, but I still couldn't find it, so try this.
4,_ try_aggregate_string_function find the reason for conversion!
print(df.apply([sum, 'sum', np.sum,'np.sum']))
----error----
...
File "D:\r\Anaconda3\lib\site-packages\pandas\core\series.py", line 3688, in aggregate
result, how = self._aggregate(func, *args, **kwargs)
File "D:\r\Anaconda3\lib\site-packages\pandas\core\base.py", line 477, in _aggregate
return self._aggregate_multiple_funcs(arg, _axis=_axis), None
File "D:\r\Anaconda3\lib\site-packages\pandas\core\base.py", line 507, in _aggregate_multiple_funcs
new_res = colg.aggregate(a)
File "D:\r\Anaconda3\lib\site-packages\pandas\core\series.py", line 3688, in aggregate
result, how = self._aggregate(func, *args, **kwargs)
File "D:\r\Anaconda3\lib\site-packages\pandas\core\base.py", line 311, in _aggregate
return self._try_aggregate_string_function(arg, *args, **kwargs), None
File "D:\r\Anaconda3\lib\site-packages\pandas\core\base.py", line 282, in _try_aggregate_string_function
f"'{arg}' is not a valid function for '{type(self).__name__}' object"
AttributeError: 'np.sum' is not a valid function for 'Series' object
Focus on_ try_ aggregate_ string_ Error reporting of function.
The function is as follows
def _try_aggregate_string_function(self, arg: str, *args, **kwargs):
"""
if arg is a string, then try to operate on it:
- try to find a function (or attribute) on ourselves
- try to find a numpy function
- raise
"""
assert isinstance(arg, str)
f = getattr(self, arg, None) # Transformed here
if f is not None:
if callable(f):
return f(*args, **kwargs)
# people may try to aggregate on a non-callable attribute
# but don't let them think they can pass args to it
assert len(args) == 0
assert len([kwarg for kwarg in kwargs if kwarg not in ["axis"]]) == 0
return f
f = getattr(np, arg, None)
if f is not None:
if hasattr(self, "__array__"):
# in particular exclude Window
return f(self, *args, **kwargs)
raise AttributeError(
f"'{arg}' is not a valid function for '{type(self).__name__}' object"
)
The transformed function is f = getattr(np, arg, None), which can find out whether there is a corresponding function. The comment also says that if arg is in string format, it will find out whether it has this function. If it cannot be found, it will find the numpy module and report an error if it cannot be found.