1, Explain
Although there are many things that can be done by scratch, it is difficult to achieve large-scale distributed applications. Someone has changed the queue scheduling of the sweep and changed the starting URL from start_ It is separated from URLs and read from redis instead. Multiple clients can read the same redis at the same time, so as to realize distributed crawler. Even on the same computer, multi process crawlers can be run, which is very effective in the process of large-scale crawling.
2, Distributed crawler principle
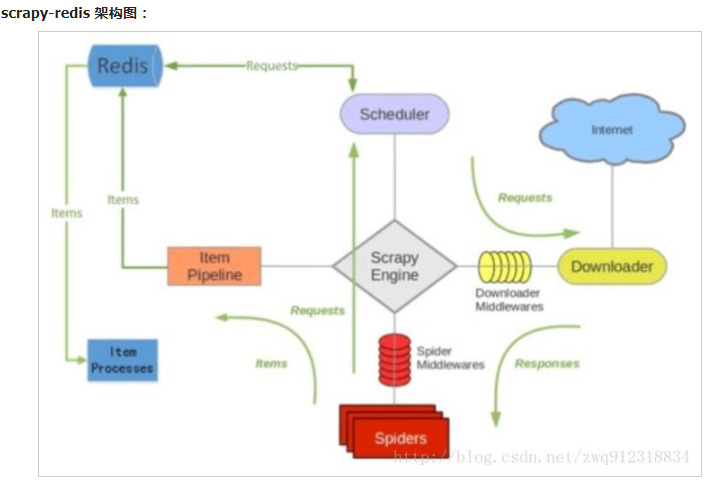
The addition of a redis component mainly affects two places: the first is the scheduler. The second is data processing.
Scripy redis distributed strategy.
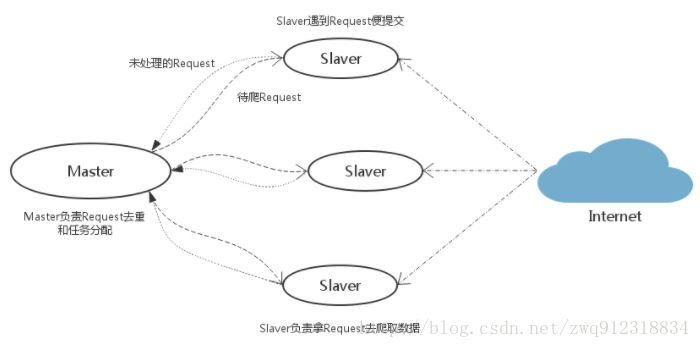
As a distributed crawler, it is necessary to have a Master side (core server). On the Master side, a redis database will be built to store start_urls,request,items. The Master is responsible for url fingerprint duplication, request allocation and data storage (generally, a mongodb will be installed on the Master side to store items in redis). In addition to the Master, another role is the slave (crawler execution end), which is mainly responsible for executing the crawler to crawl data and submitting new requests in the crawling process to the redis database of the Master.
As shown in the figure above, suppose we have four computers: A, B, C and D, and any one of them can be used as the Master terminal or slave terminal. The whole process is:
First, the slave takes the task (Request, url) from the Master to grab the data. While the slave grabs the data, the Request for a new task is submitted to the Master for processing;
There is only one Redis database on the Master side, which is responsible for de duplication and task allocation of unprocessed requests, adding the processed requests to the queue to be crawled, and storing the crawled data.
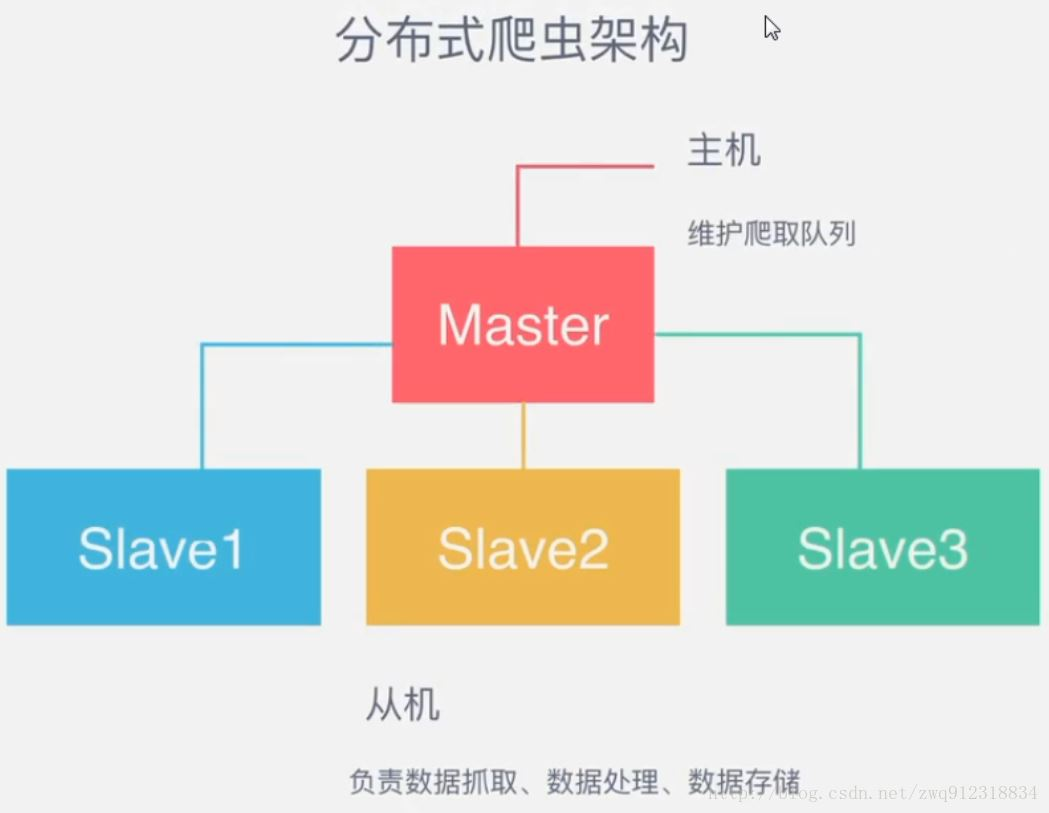
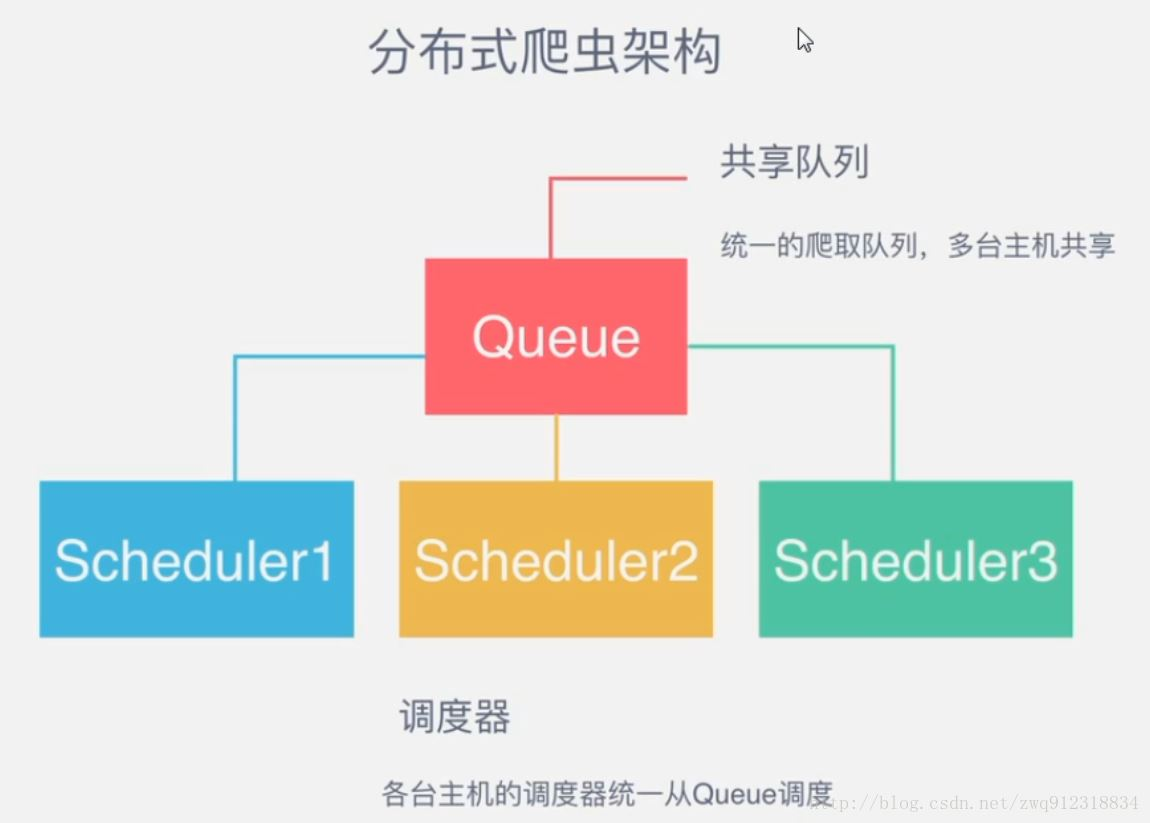
Scripy redis uses this strategy by default. Our implementation is very simple, because scripy redis has helped us with task scheduling and other work. We only need to inherit RedisSpider and specify redis_ Just key.
The disadvantage is that the task of scrapy Redis scheduling is the Request object, which contains a large amount of information (including not only URLs, but also callback functions, headers and other information). The result may be to reduce the crawler speed and occupy a large amount of storage space in Redis. Therefore, if you want to ensure efficiency, you need a certain level of hardware.
3, Case preparation
1. One for windows (from: scene)
2. One linux (Main: scratch \ redis \ Mongo)
ip:192.168.184.129
3,python3.6
Configuration steps of scratch under linux:
1,install python3.6 yum install openssl-devel -y solve pip3 Problems that cannot be used(pip is configured with locations that require TLS/SSL, however the ssl module in Python is not available) download python Software package, Python-3.6.1.tar.xz,After decompression ./configure --prefix=/python3 make make install Add environment variables: PATH=/python3/bin:$PATH:$HOME/bin export PATH After installation, pip3 The default installation is complete(Before installation yum gcc) 2,install Twisted download Twisted-17.9.0.tar.bz2,After decompression cd Twisted-17.9.0, python3 setup.py install 3,install scrapy pip3 install scrapy pip3 install scrapy-redis 4,install redis See blog redis Installation and simple use Error: You need tcl 8.5 or newer in order to run the Redis test 1,wget http://downloads.sourceforge.net/tcl/tcl8.6.1-src.tar.gz 2,tar -xvf tcl8.6.1-src.tar.gz 3,cd tcl8.6.1/unix ; make; make install cp /root/redis-3.2.11/redis.conf /etc/ Start:/root/redis-3.2.11/src/redis-server /etc/redis.conf & 5,pip3 install redis 6,install mongodb Start:# mongod --bind_ip 192.168.184.129 & 7,pip3 install pymongo
Deployment steps of scratch on windows:
1,install wheel
pip install wheel
2,install lxml
https://pypi.python.org/pypi/lxml/4.1.0
3,install pyopenssl
https://pypi.python.org/pypi/pyOpenSSL/17.5.0
4,install Twisted
https://www.lfd.uci.edu/~gohlke/pythonlibs/
5,install pywin32
https://sourceforge.net/projects/pywin32/files/
6,install scrapy
pip install scrapy
4, Case deployment code
Take the movie crawling of so and so paradise as a simple example. Let's talk about the distributed implementation. One copy of the code is placed on linux and windows respectively. The configuration is the same. Both can run crawling at the same time.
List only the areas that need to be modified:
settings
Set the storage database (mongodb) for crawling data, and the database (redis) for fingerprint and queue storage
ROBOTSTXT_OBEY = False # Prohibit robot s
CONCURRENT_REQUESTS = 1 # The maximum concurrency of the scene debug queue is 16 by default
ITEM_PIPELINES = {
'meiju.pipelines.MongoPipeline': 300,
}
MONGO_URI = '192.168.184.129' # mongodb connection information
MONGO_DATABASE = 'mj'
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # Using scratch_ Redis scheduling
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # De duplication (url) in redis Library
# REDIS_URL = 'redis://root:kongzhagen@localhost:6379 '# if redis has a password, use this configuration
REDIS_HOST = '192.168.184.129' #redisdb connection information
REDIS_PORT = 6379
SCHEDULER_PERSIST = True # Don't empty fingerprints
piplines
Code stored in MongoDB
import pymongo
class MeijuPipeline(object):
def process_item(self, item, spider):
return item
class MongoPipeline(object):
collection_name = 'movies'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.collection_name].insert_one(dict(item))
return item
items
data structure
import scrapy
class MeijuItem(scrapy.Item):
movieName = scrapy.Field()
status = scrapy.Field()
english = scrapy.Field()
alias = scrapy.Field()
tv = scrapy.Field()
year = scrapy.Field()
type = scrapy.Field()
Script MJ py
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
class MjSpider(scrapy.Spider):
name = 'mj'
allowed_domains = ['meijutt1.com']
# start_urls = ['http://www.meijutt1.com/file/list1.html']
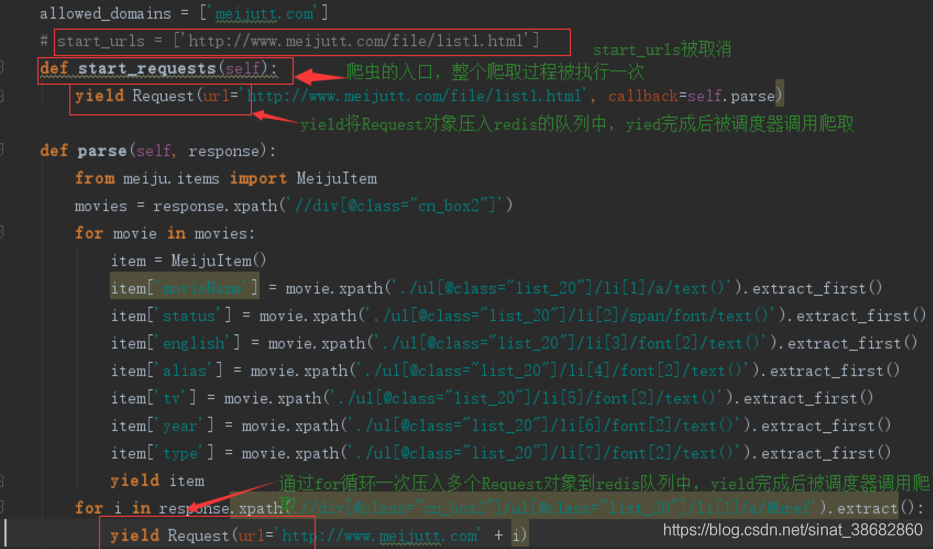
def start_requests(self):
yield Request(url='http://www.meijutt1.com/file/list1.html', callback=self.parse)
def parse(self, response):
from meiju.items import MeijuItem
movies = response.xpath('//div[@class="cn_box2"]')
for movie in movies:
item = MeijuItem()
item['movieName'] = movie.xpath('./ul[@class="list_20"]/li[1]/a/text()').extract_first()
item['status'] = movie.xpath('./ul[@class="list_20"]/li[2]/span/font/text()').extract_first()
item['english'] = movie.xpath('./ul[@class="list_20"]/li[3]/font[2]/text()').extract_first()
item['alias'] = movie.xpath('./ul[@class="list_20"]/li[4]/font[2]/text()').extract_first()
item['tv'] = movie.xpath('./ul[@class="list_20"]/li[5]/font[2]/text()').extract_first()
item['year'] = movie.xpath('./ul[@class="list_20"]/li[6]/font[2]/text()').extract_first()
item['type'] = movie.xpath('./ul[@class="list_20"]/li[7]/font[2]/text()').extract_first()
yield item
for i in response.xpath('//div[@class="cn_box2"]/ul[@class="list_20"]/li[1]/a/@href').extract():
yield Request(url='http://www.meijutt1.com' + i)
# next = 'http://www.meijutt.com' + response.xpath("//a[contains(.., 'next')] / @ href") [1] extract()
# print(next)
# yield Request(url=next, callback=self.parse)
Insert picture description here
Take a look at the situation in redis:

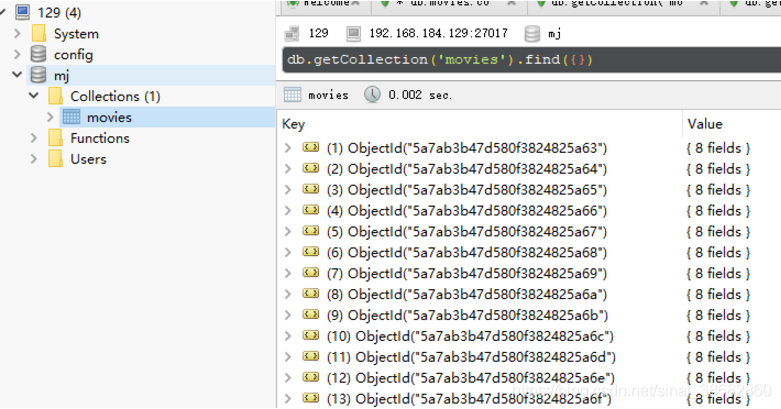
Look at the data in mongodb: