1. Write before
Today, I've sorted out several Python cases about file operations, including reading and writing files with python, getting file names, getting file suffixes, and modifying file suffixes in bulk.Several methods of this collation are still from the point of view of use.For example, I need to count the number of occurrences of each word in a txt file, and I need to modify the suffixes of files in batches.Later on, the python file reads and writes will be added to this article.
Ok, let's go!
2. python reads and writes files
Reading and writing files are common in python. When reading a file, it is important to first determine whether the file exists or not. If the file is manipulated, it will be read. Otherwise, errors will occur.
2.1 File Read Operation
read(), which reads the entire file, and readlines(), which is a line to read and save to the list.The following code goes directly up:
import os def read_file(filename): if os.path.exists(filename) is False: raise FileNotFoundError('%s not exists' % (filename,)) f = open(filename, encoding='utf-8') # The latter is the specified encoding generic platform default encoding format utf-8 content = f.read() f.close() return content # Another way of writing def read_file(filename): if os.path.exists(filename) is False: raise FileNotFoundError('%s not exists' % (filename,)) with open(filename, encoding='utf-8') as f: content = f.read() # Automatically close after reading return content content = read_file('a.txt') content ## 'Hey, Python\n\nI just love Python so much,\nand want to get the whole Python stack by this 60-days column\nand believe Python !'
Here is the effect of line reading:
"""File read by line""" def read_file_line(filename): if not os.path.exists(filename): raise FileNotFoundError('%s not exists' % filename) with open(filename, encoding='utf-8') as f: content = f.readlines() return content con = read_file_line('a.txt') con ## ['Hey, Python\n', '\n', 'I just love Python so much,\n', 'and want to get the whole Python stack by this 60-days column\n', 'and believe Python !']
Okay, based on this, you can write a statistics file about the number of occurrences of all words.Go through this process once: I get the contents of the file, and then participle it before counting the number.
# Here is an example of counting words from collections import defaultdict #Defaultdict (function_here)Factory) is building a dictionary-like object. #Where the value of keys determines the assignment itself, but the type of values is function_Class instance of factory, #It also has a default value.For example, default(int) creates a dictionary-like object in which any values are instances of int. #Even if a key does not exist, d[key] has a default value, which is the default value of 0 for int(). import re rec = re.compile('\s+') # Match one or more spaces dd = defaultdict(int) with open('a.txt', 'r+') as f: for line in f: clean_line = line.strip() if clean_line: words = rec.split(clean_line) for word in words: dd[word] += 1 dd = sorted(dd.items(), key=lambda x: x[1], reverse=True) dd ## The results are as follows: [('Python', 4), ('and', 2), ('Hey,', 1), ('I', 1), ('just', 1), ('love', 1), ('so', 1), ('much,', 1), ('want', 1), ('to', 1), ('get', 1), ('the', 1), ('whole', 1), ('stack', 1), ('by', 1), ('this', 1), ('60-days', 1), ('column', 1), ('believe', 1), ('!', 1)]
The above case is sometimes useful.
2.2 File write operations
When writing to a file, you need to first determine if the path to the file you want to write exists.If it does not exist, create a path through mkdir; otherwise, write directly to the file:
def write_to_file(file_path, file_name): if not os.path.exists(file_path): os.mkdir(file_path) whole_path_filename = os.path.join(file_path, file_name) to_write_content = ''' Hey, Python I just love Python so much, and want to get the whole python stack by this 60-days column and believe! ''' with open(whole_path_filename, mode='w', encoding='utf-8') as f: f.write(to_write_content)
3. Get the file name and suffix name of the file
Sometimes when we get a file name, the name has a path on it, so we can use itOs.path.splitMethod separates path from file name.
file_ext = os.path.split('./data/py/test.py') ipath, ifile = file_ext print(ipath, ifile) ## ./data/py test.py
Os.pathModule, splitext can elegantly extract file suffixes.
file_extension = os.path.splitext('./data/py/test.py') file_extension # .py
Based on this operation above, you can get a file with the specified suffix name under a directory
# Gets the file with the specified suffix name in a directory def find_file(work_dir, extension='jpg'): lst = [] for filename in os.listdir(work_dir): #print(filename) splits = os.path.splitext(filename) ext = splits[1] # Get Extension if ext == '.'+extension: lst.append(filename) return lst r = find_file('E:\Jupyter Notebook\Python', 'ipynb') print(r) ## Result ['Day1-Day2.ipynb', 'Day10_python Document Operation Cases.ipynb', 'Day3-Day4.ipynb', 'Day5-Day6.ipynb', 'Day7-Day8.ipynb', 'Day9_String operations and regularization.ipynb']
This is still useful, for example, in some tasks of CNN, many pictures are stored in folders in the form of.jpg. At this time, we need to get all.jpg files first, and then convert the pictures into matrix representation through some ways, so that our network will recognize.
Here's another example of batch file suffix modification, such as converting all.xls into.xlsx files in a directory.What should I do about this?Still, first comb the logic:
- First iterate through the given directory
- Get the suffix names for each file
- See if the suffix name is a suffix name that needs to be modified and rename if so
With this logic, the code is easier to write.
def batch_rename(work_dir, old_ext, new_ext): for filename in os.listdir(work_dir): # Get File Suffix split_file = os.path.splitext(filename) file_ext = split_file[1] if old_ext == file_ext: # Locate files that need to modify suffix names newfile = split_file[0] + new_ext # Full name of modified file # rename os.rename( os.path.join(work_dir, filename), os.path.join(work_dir, newfile) )
Here's a little bit of new information based on this. If I want to write the above into a.py file and run the.py file from the command line to pass in the three parameters above, how do I transfer them?
At this point, you need to use a python module called argparse, which is python's standard module for parsing command line parameters and options. I don't know much about it at this time, but I've seen three basic steps when using it in general:
- Create ArgumentParser() object
- Call add_argument() method adds a parameter
- Using parse_args() parses the added parameters
The way to switch to code is:
import argparse parser = argparse.ArgumentParser() parser.add_argument("x", type=int) parser.add_argument('y', type=int) args = parser.parse_args() # This passes the parameter x y through the command line, which we can get from the following code x=args.x y=args.y print(x,y)
If you want to know more about what the specific parameters in each function are for, go to the official website https://docs.python.org/2/howto/argparse.html
So the main point here is to record how this stuff actually works, and in this example we can write it like this.test.py):
def batch_rename(work_dir, old_ext, new_ext): print(new_ext) for filename in os.listdir(work_dir): # Get File Suffix split_file = os.path.splitext(filename) file_ext = split_file[1] if old_ext == file_ext: # Locate files that need to modify suffix names newfile = split_file[0] + new_ext # Full name of modified file # rename os.rename( os.path.join(work_dir, filename), os.path.join(work_dir, newfile) ) print("Complete Rename") print(os.listdir(work_dir)) def main(): # Command Line Parameters parser = argparse.ArgumentParser(description='Working Directory File Suffix Name Modification') parser.add_argument('work_dir', metavar='WORK_DIR', type=str, nargs=1, help='Modify Suffix Name File Directory') parser.add_argument('old_ext', metavar='OLD_EXT', type=str, nargs=1, help='Original suffix') parser.add_argument('new_ext', metavar='NEW_EXT', type=str, nargs=1, help='New Suffix') args = vars(parser.parse_args()) # Resolve arguments from command line arguments in turn work_dir = args['work_dir'][0] old_ext = args['old_ext'][0] if old_ext[0] != '.': old_ext = '.' + old_ext new_ext = args['new_ext'][0] if new_ext[0] != '.': new_ext = '.' + new_ext batch_rename(work_dir, old_ext, new_ext) if __name__ == '__main__': main()
So how should we use it?Open the command line and enter:
python test.py E:\test xls xlsx # The last three parameters are the directory, the old suffix name, and the new suffix name.
That code doesn't explain.
Why should I introduce argparse?Of course, if you're writing a little python demon with a tool like jupyter notebook or building some neural networks with keras or something, you don't usually need it.But if it's from a project perspective, we're usually used to breaking up the entire task into many small pieces and writing a.py file for each block, which is organized into a large project.For example, if you train a complex neural network to make a time series prediction, the code written will be very long and difficult to read and maintain if you use jupyter. At this time, you can consider four blocks, data set construction, model building, model training and model prediction.Each block is written to a.py file.This makes code easier to maintain and read, so larger projects are generally divided into many.py projects.
So what does that have to do with argparse?This is better for me to run from the command lineTrain.pyWhen such code trains a neural network, it passes some necessary parameters in the past, such as batch_size, epoch, lr, dimension of input and output, etc.You might also say why not declare some variables directly and save the parameters first, in which case Python is used directly from the command lineTrain.pyDon't finish?Of course, this is possible, but if you want to change the parameters frequently and under the black window of Linux, it's really cumbersome to turn on and off the.Py file repeatedly, so you might want to use this library at this time.Like the beginning of this code below (train.py):
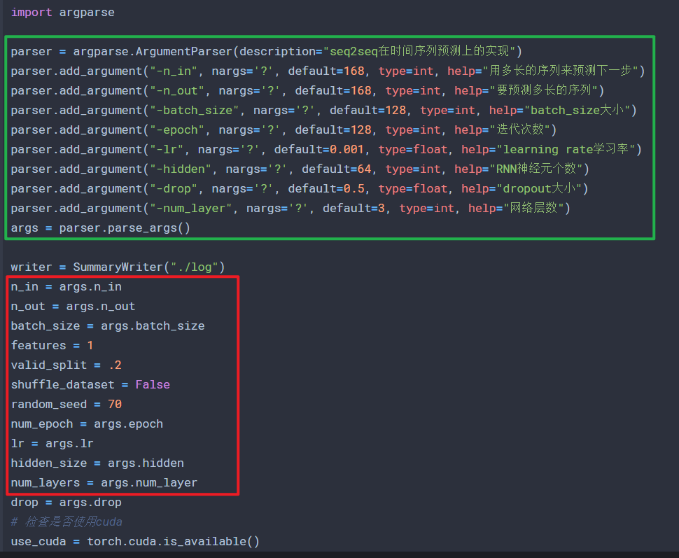
At this point, we can Python directly from the command lineTrain.pyThen carry the appropriate parameters behind.