Recently, the project needs to crawl the historical weather data of Hefei City, analyze several weather data websites, and finally select Weather post website . discuss the problems encountered in the implementation process for future reference.
Step analysis
Here, I use the requests library beautifulsop Library in Python to crawl. The implementation process can be divided into the following steps.
1. Be familiar with the use of requests library and beautifulsop:
Requests are mainly related to HTTP requests. In our crawler, they are mainly used to request HTML content of web pages. For novices, please refer to the document: http://docs.python-requests.org/zh CN / latest / user / quickstart.html
The beautiffursop library is a Python library that can extract data from HTML files. Because the HTML files we get contain the entire web page content, we also need to locate the data we need to obtain. Beautiffursop provides a series of powerful functions, including find and find all, to help us quickly search and locate. Tutorial: https://www.crm.com/software/b eautifulSoup/bs4/doc/index.zh.html .
2. Analysis of web page structure
The second step I think is to open the web page we want to crawl first, use Google browser and other developer tools to quickly locate the HTML content we need:
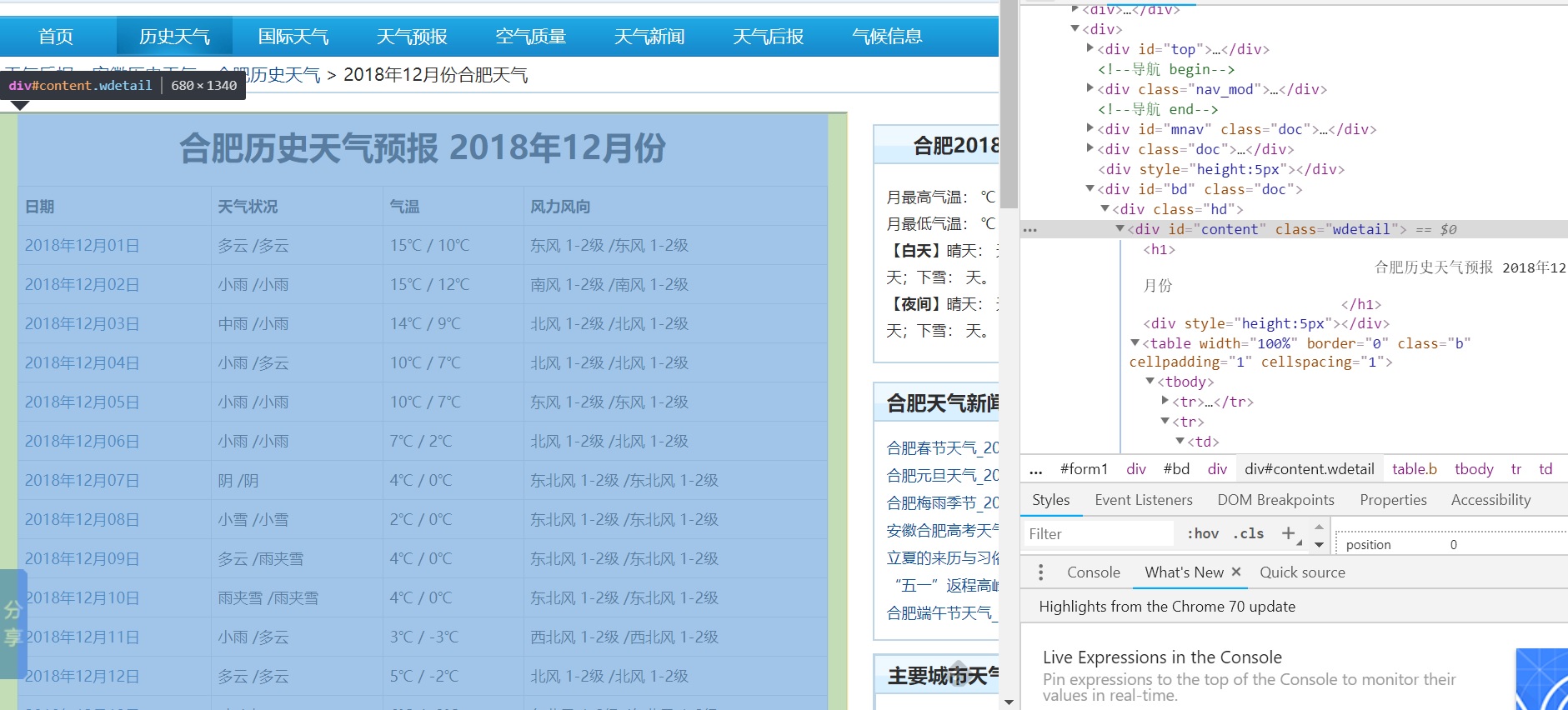
3. Store data
After the data is acquired, it needs to store the data in a structured way, which can be a CSV file or a database. When storing, it is also necessary to pay attention to preprocessing in advance to avoid special characters such as spaces, line breaks, etc. or the problem of Chinese random code.
Implementation process
Get web content
The code is as follows:
def get_soup(url): try: r = requests.get(url, timeout=30) r.raise_for_status() #If the request is not successful, an HTTPError exception is thrown #r.encoding = 'gbk' #Match this site code soup = BeautifulSoup(r.text, 'lxml') return soup except HTTPError: return "Request Error"
**Note: * * 1. If the website code is not utf8, but other, you need to set r.encoding to the corresponding code; 2. It is better to handle exceptions, otherwise the crawler may be interrupted.
Analyze the content of the web page and get the data
def get_data(): soup = get_soup(url) all_weather = soup.find('div', class_="wdetail").find('table').find_all("tr") data = list() for tr in all_weather[1:]: td_li = tr.find_all("td") for td in td_li: s = td.get_text() data.append("".join(s.split())) res = np.array(data).reshape(-1, 4) return res
Because the weather data is wrapped in the tr of table, each TR is a row, and each row has four columns of td (date, weather condition, temperature, wind direction)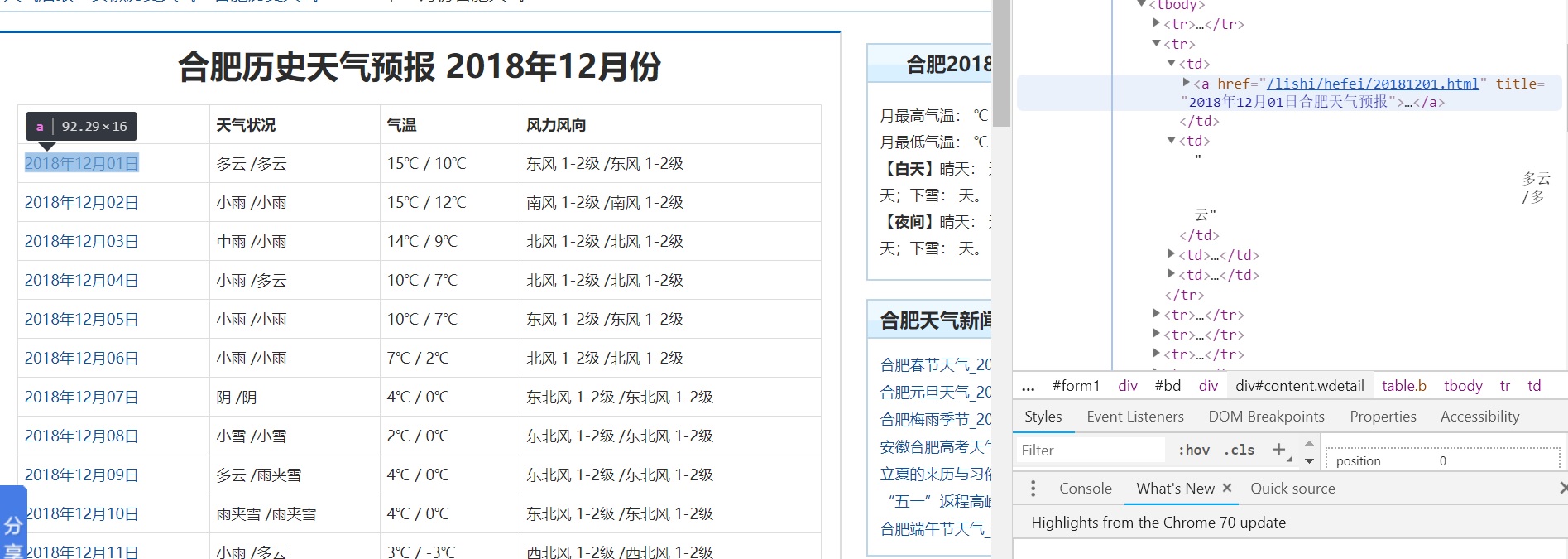
Above, I reshape the whole data list with 4 columns as a group to facilitate the storage of later data, and then I also exclude the space line breaks in the data, etc.:. join(s.split()). Note that it is better to search several layers in the process of parsing. Do not get the innermost element directly, or it may fail to parse or conflict, such as soup. Find ('div ', class "=" wdetail "). Find ('table'). Find_all (" tr ") rather than directly soup.find_all("tr ")
data storage
Finally, data is stored. There are two ways to store data to CSV file and MySQL:
1.CSV file
def saveTocsv(data, fileName): ''' //Save weather data to csv file ''' result_weather = pd.DataFrame(data, columns=['date','tq','temp','wind']) result_weather.to_csv(fileName, index=False, encoding='gbk') print('Save all weather success!')
2. Store to MySQL
def saveToMysql(data): ''' //Save weather data to MySQL database ''' #Establish connection conn = pymysql.connect(host="localhost", port=3306, user='root', passwd='pass', database='wea', charset="utf8") #Get cursor cursor = conn.cursor() sql = "INSERT INTO weather(date,tq,temp,wind) VALUES(%s,%s,%s,%s)" data_list = np.ndarray.tolist(data) #Convert a numpy array to a list try: cursor.executemany(sql, data_list) print(cursor.rowcount) conn.commit() except Exception as e: print(e) conn.rollback() cursor.close() conn.close()
The storage results are as follows: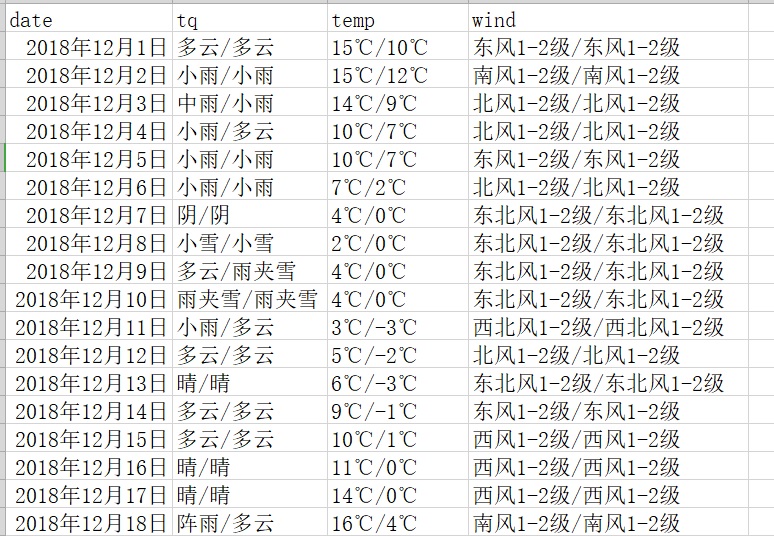
Complete code
#coding=utf-8 import io import sys import requests from bs4 import BeautifulSoup import numpy as np import pandas as pd sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') #Change the default code of the standard output to prevent the console from printing random code url = "http://www.tianqihoubao.com/lishi/hefei/month/201812.html" def get_soup(url): try: r = requests.get(url, timeout=30) r.raise_for_status() #If the request is not successful, an HTTPError exception is thrown #r.encoding = 'gbk' soup = BeautifulSoup(r.text, 'lxml') return soup except HTTPError: return "Request Error" def saveTocsv(data, fileName): ''' //Save weather data to csv file ''' result_weather = pd.DataFrame(data, columns=['date','tq','temp','wind']) result_weather.to_csv(fileName, index=False, encoding='gbk') print('Save all weather success!') def saveToMysql(data): ''' //Save weather data to MySQL database ''' #Establish connection conn = pymysql.connect(host="localhost", port=3306, user='root', passwd='pass', database='wea', charset="utf8") #Get cursor cursor = conn.cursor() sql = "INSERT INTO weather(date,tq,temp,wind) VALUES(%s,%s,%s,%s)" data_list = np.ndarray.tolist(data) #Convert a numpy array to a list try: cursor.executemany(sql, data_list) print(cursor.rowcount) conn.commit() except Exception as e: print(e) conn.rollback() cursor.close() conn.close() def get_data(): soup = get_soup(url) all_weather = soup.find('div', class_="wdetail").find('table').find_all("tr") data = list() for tr in all_weather[1:]: td_li = tr.find_all("td") for td in td_li: s = td.get_text() data.append("".join(s.split())) res = np.array(data).reshape(-1, 4) return res if __name__ == '__main__': data = get_data() saveTocsv(data, "12.csv")
Reference resources:
1.https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
2.https://blog.csdn.net/jim7424994/article/details/22675759

