Selenium case exercise
1. Crawl cat's eye movie data
Page requirements
Use selenium to crawl the top 100 of cat's eye, the ranking, film name, starring, release time and score of each film.
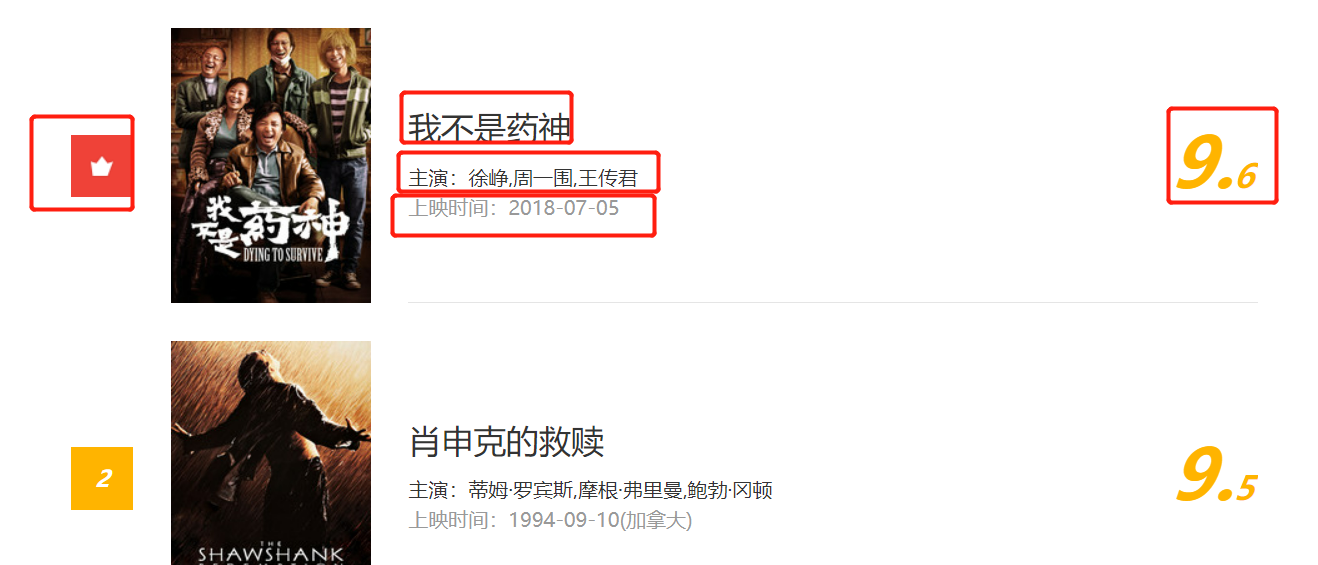
Page analysis
By analyzing the page structure, select the appropriate access point. selenium can directly check the page without analyzing whether the code appears in the source code.
The cursor is located at the first movie. Right click to check and locate the information of the first movie. We can fold the label and see that all the data of a movie is stored in the dd label, all the movies on this page are stored in all the dd labels, and all the dd labels are stored in the dl label. Then we only need to find the dl tag and then find the dd tag to get the movie data.
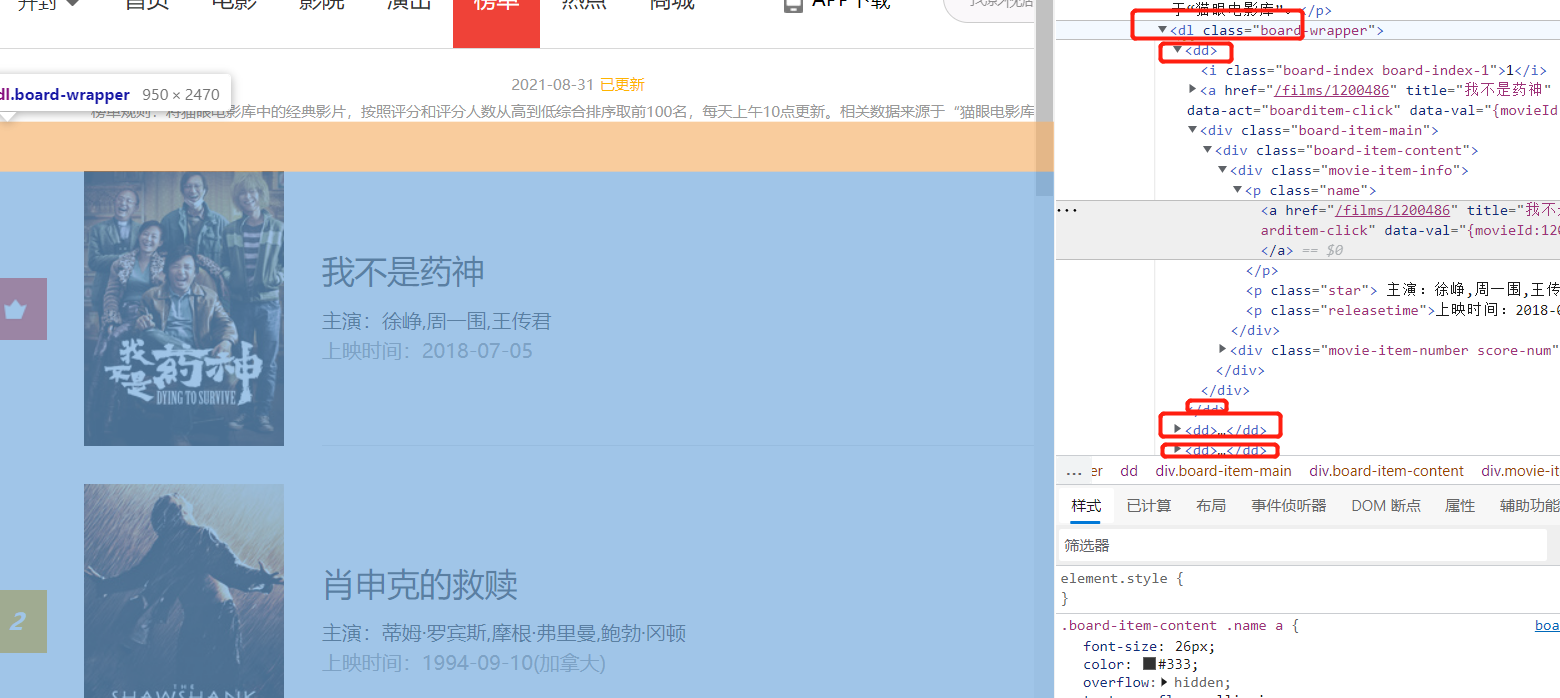
Sliding the web page, you can see that there are ten movies on the first page, which are just 10 dd tags in the code.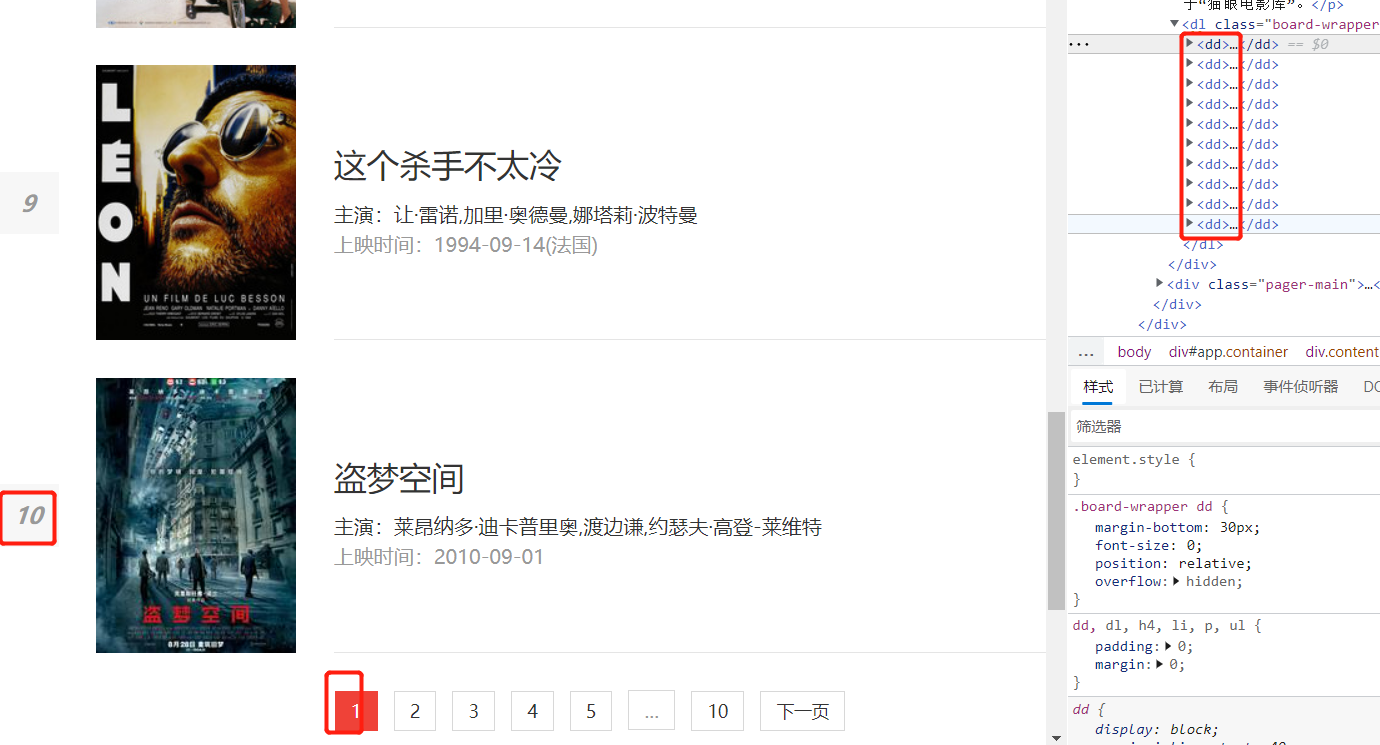
In summary, through analysis, a dd tag corresponds to a movie. All dd tags are stored in the dl tag. We need to find the dl tag of class = "board wrapper", then find the dd tag under the dl tag, and finally analyze the data in the dd tag.
For example: a function has multiple return values, and only the method that takes the required return value
import csv
def test():
return [{'t': 2, 'm': '3'}],['t','m']
a, b = test()
a, _ = test()
_, b = test()
with open('a.c.csv', 'a',encoding='utf-8',newline="") as f:
w = csv.DictWriter(f,b)
w.writeheader()
w.writerows(a)
print(a) [{'t': 2, 'm': '3'}]
print(b) ['t', 'm']
code implementation
from selenium import webdriver
import csv
import time
driver = webdriver.Edge()
driver.get('https://maoyan.com/board/4?offset=0')
time.sleep(1)
# Find dl tag
# driver.find_element_by_xpath('//*[@id="app"]/div/div/div[1]/dl')
# Find all dd tags under the dl tag, because not one is obtained, and use elements for all
# Parsing a page's function
def get_data():
dd_tags = driver.find_elements_by_xpath('//*[@id="app"]/div/div/div[1]/dl/dd')
lis = []
for dd_tag in dd_tags:
# Textis used to obtain all text of nodes (including child nodes and all descendant nodes),
# print(type(dd_tag.text), dd_tag.text) # character string
# The printed content is separated by newline. The obtained content can be converted into a list by string segmentation
lis_dd = dd_tag.text.split('\n')
item = {}
# Define titles and continue to use them as headers when saving functions
titles = ['rank', 'name', 'star', 'time', 'score']
# In LIS_ Fetching data by index in DD
suoyins = range(5)
for title, suoyin in zip(titles, suoyins):
# title as the key value and suoyin as the value value are saved in the dictionary item
item[title] = lis_dd[suoyin]
# Store each saved dictionary in the list
lis.append(item)
return lis, titles
# The return list lis is used to write data, and the header of tieles is used to write
def save_data(lis_data, titles):
with open('data3.csv', 'a', encoding='utf-8',newline="") as f:
writ = csv.DictWriter(f, titles)
writ.writerows(lis_data)
if __name__ == '__main__':
# To solve the problem of duplicate header, write the header and only write data in subsequent cycles
# Only the title part is taken from the two return values
_, titles = get_data()
with open('data3.csv', 'a', encoding='utf-8', newline="") as f:
writ = csv.DictWriter(f, titles)
writ.writeheader()
while True:
# Extract the data part from the two return values
lis, _ = get_data()
# Pass the two return values into save_data function
save_data(lis, titles)
time.sleep(3)
try:
# The a tag in the front end usually represents the link and the text of the hyperlink on the next page
driver.find_element_by_link_text('next page').click()
# If you can find the "next page", click it. If you can't find it, enter except
except:
# Exit the drive and terminate the cycle
driver.quit()
break
As mentioned earlier, the headless browser (phantom JS) has no interface and is loaded in memory. If the cat's eye is not loaded just now, the crawling speed will be slightly faster (opening the page will occupy a certain amount of memory). If the headless browser is set for selenium, the loading speed will be faster. The best way to use the no interface mode is to crawl the data through the program, otherwise you may not know where the problem is. Here, we only try to use Google browser. Edge has not found the corresponding function. If the following code is used to crawl the above case, we need to install the driver of Google browser.
# Create a chrome settings object
options = webdriver.ChromeOptions()
# Set no interface function
# ---headless browser has no interface
options.add_argument('---headless')
# Pass options to the drive as a parameter
driver = webdriver.Chrome(options=options)
2. Climb Jingdong books
demand
Enter the search data (input) of any keyword into the JD interface, enter the crawler book for retrieval, and save the results of the price, title, number of evaluators and store name of each book.
Page analysis
Right click the first book and check. The cursor is positioned at the picture position of the book, and then fold the label level by level. You will find that each book is placed in a li label, and all li labels are placed in a ul label, which stores all books on this page.
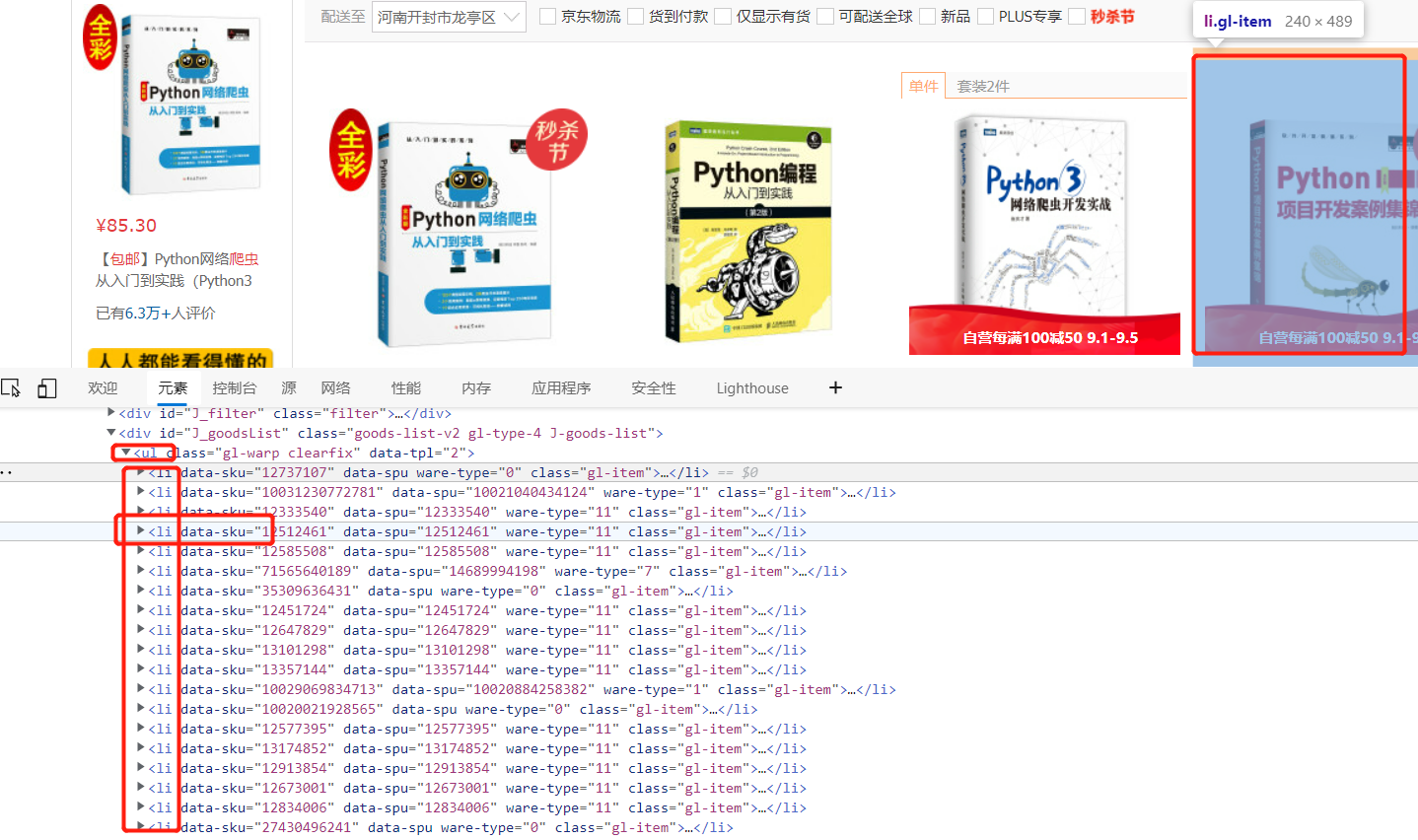
If you continue to scroll down the web page interface, the li tag of the newly loaded book will appear below the code, which is lazy loading. The data will be loaded only when the interface arrives. The JD interface is loaded twice. Only part of it is loaded for the first time, and the remaining data will be loaded only when you scroll down to a certain interface. At this time, the data obtained by taking the url is incomplete.
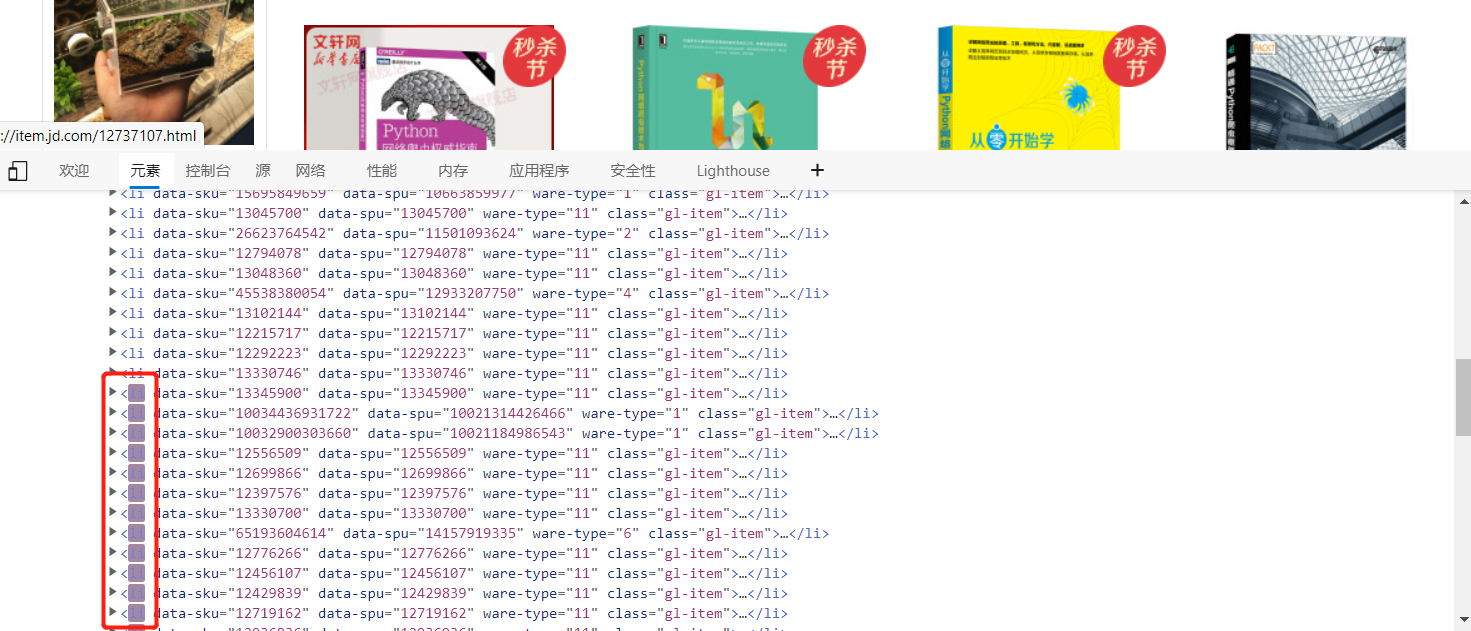
Part of the data is loaded when opening the page. The data obtained by selenium is incomplete. We can directly drag the page to the bottom (automatic drag) and wait for all the contents to be loaded before obtaining the data. Facing the problem of incomplete data caused by lazy loading, our solution is to locate the page and directly drag the scroll bar on the right to the bottom of the page to leave some loading time for the page. After the page elements are loaded, we can obtain the data. You can use the mouse behavior chain to drag the scroll bar to the bottom, or you can use js code to implement it.
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
Here through execute_ Script to execute js code, 0 is the starting position, document.body.scrollHeight is the height of the whole window, and the function of the code is to turn the scroll bar to the bottom of the page.
Next, search the price, title, number of evaluators and store name of each book. By traversing the li tag under ul, you can see that the second book has two more single pieces / sets and coupons than the first book.
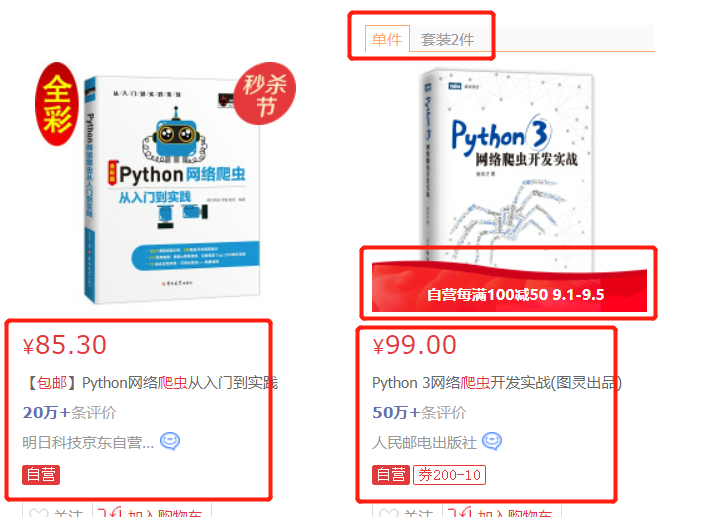
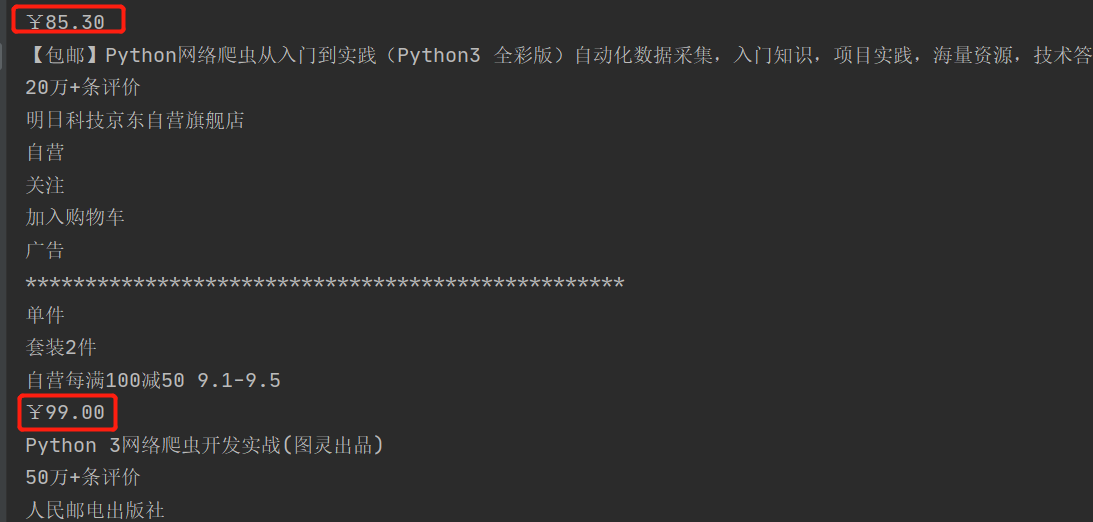
If the index value is obtained directly by traversing the text method of the element, the data will be inconsistent. The result of code printing can see that the price of the first book is in the first content and the price of the second book is in the fourth content. At this time, the content to be found will be taken one by one.
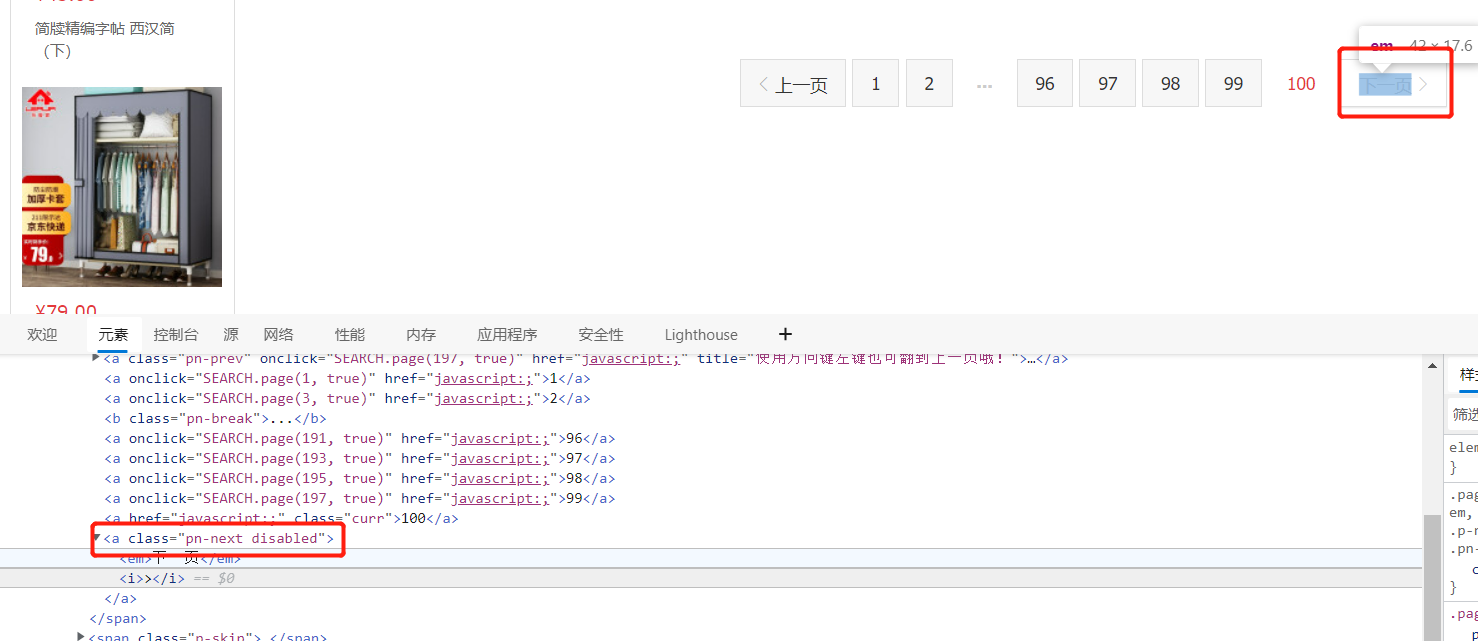
The following page turning operation is realized. Through observation, you can see that the search content is 100 pages in total, and each page has a next page button. You can click the next page button to enter the next page,
On page 100, the button on the next page is gray and cannot be clicked. Observe that the class = "PN next disabled" label appears in the code. You can click the next page until the class = "PN next disabled" tab appears, and then stop clicking to turn the page with driver.page_source.find(class = "PN next disabled").
Since there are a lot of crawling data, some individual data will have problems. You can try to get the attribute data.
Implementation steps
from selenium import webdriver
import time
import csv
class jd_Data():
def __init__(self):
self.driver = webdriver.Edge()
self.driver.get('https://www.jd.com/')
time.sleep(1)
self.driver.find_element_by_id('key').send_keys('Reptile book')
# Note that there are many iconfont s in the code. It is better not to use class_name get
# Simply put, try to use xpath for those without id
# self.driver.find_element_by_class_name('iconfont').click()
self.driver.find_element_by_xpath('//*[@id="search"]/div/div[2]/button').click()
time.sleep(1)
# Complete data crawling and parsing
def parse_data(self):
# JD is lazy loading. You need to draw the page down to the bottom to display all data
# Through execute_script to execute js code, 0 is the starting position, and document.body.scrollHeight is the height of the whole window
self.driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(3)
li_list = self.driver.find_elements_by_xpath('//*[@id="J_goodsList"]/ul/li')
self.lis_data = []
for li in li_list:
# print(li.text)
# print('*'*50)
# It is found that the data distribution is uneven. The price of the first book is in the first text, there are single pieces and suits in front of the second book, preferential information, and the fourth text is the price
# Therefore, data cannot be obtained with the li.text split index
item = {}
# item['price'] = li.find_element_by_xpath('//*[@id="J_goodsList"]/ul/li[1]/div/div[2]/strong')
# Right click to copy xpath directly above
# You can also go directly to xpath. The price is in the strong tag under div (class="p-price")
# Find li using driver_ After list, the following data is found in li, and there is no need to use self.driver to find the data
try:
item['price'] = li.find_element_by_xpath('.//div[@class="p-price"]/strong').text.strip()
item['name'] = li.find_element_by_xpath('.//div[@class="p-name"]/a/em').text.strip()
item['commit'] = li.find_element_by_xpath('.//div[@class="p-commit"]/strong').text.strip()
item['shopnum'] = li.find_element_by_xpath('.//div[@class="p-shopnum"]/a').text.strip()
print(item)
self.lis_data.append(item)
except Exception as e:
print(e)
def save_data(self):
with open('jd_data.csv', 'a', encoding='utf-8', newline="") as f:
writ = csv.DictWriter(f, self.header)
writ.writerows(self.lis_data)
def main(self):
self.header = ['price', 'name', 'commit', 'shopnum']
with open('jd_data.csv', 'a', encoding='utf-8', newline="") as f:
writ = csv.DictWriter(f, self.header)
writ.writeheader()
while True:
self.parse_data()
self.save_data()
# Find the data in the web page source code - 1 means that the content is not found, which means that it is not the last page
# page_source.find finds elements in the code
if self.driver.page_source.find("pn-next disabled") == -1:
self.driver.find_element_by_xpath('//*[@id="J_bottomPage"]/span[1]/a[9]').click()
time.sleep(3)
else:
self.driver.quit()
break
if __name__ == '__main__':
jd = jd_Data()
jd.main()