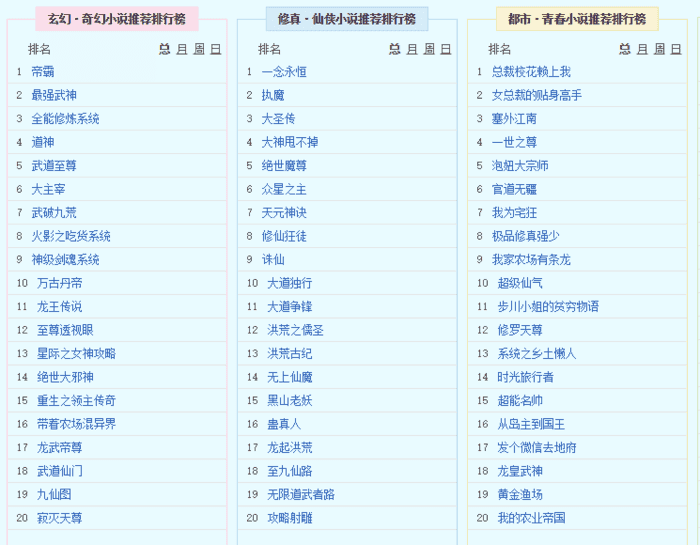
As you all know, there are always some novel that is refreshing, whether it is fairy-man or fantasy. The first dozen chapters successfully circled a large wave of fans, successfully climbed the soaring list, hot list and other lists, throwing a few chestnuts out:
As a developer, it is particularly important to have a learning atmosphere and a communication circle. This is my python communication group: 831524055. Whether you are Xiaobai or Daniel, welcome to stay, discuss technology, and share learning and growth together.
New Bi Fun Pavilion is the most worth collecting online novel reading network for the majority of book friends. The website contains the current... I won't advertise any more (other websites that meet the following criteria are OK. I've already done some precedents for simply crawling chapters before, but the effect is not ideal. There are many unnecessary ingredients left behind to link: http://www.bxquge.com/ . In this article, we have crawled thousands of novels on this website. The focus is to share with you some ideas of reptiles and some pits that we often encounter.
The context of this paper is as follows:
1. First, construct a simple crawler to practice.
2. Briefly share some error-prone problems when installing MongoBD database.
3. Use Scrapy framework to crawl the ranking of New Bi-Yi Pavilion.
All the code can be obtained by replying to the "novel" in the background of the public number.
I. Climbing a Single Novel
It's relatively easy to crawl the website. Open the editor (recommend PyCharm, powerful), first introduce the module urllib. request (Python 2.x can be introduced into urllib and urllib2, later I will write out the 2.x for you to see), give the website URL, write down the request, and add the request header (although this site is not a header, but the author suggests that we should cultivate each. The habit of writing request heads every time, in case you meet a website like bean flaps that day, you will be blocked if you don't pay attention to it.) Say no more, go directly to the code:
#coding:utf-8import urllib.requesturl = "http://www.bxquge.com/3_3619/10826.html"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \ (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063'}request = urllib.request.Request(url,headers=headers)Then the request is sent out, the variable response is defined, and the read () method is used to observe it. Attention is paid to decoding the symbol into utf-8, which saves scrambling code.
#coding:utf-8import urllib.requesturl = "http://www.bxquge.com/3_3619/10826.html"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \ (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063'}request = urllib.request.Request(url,headers=headers)response = urllib.request.urlopen(request)html = response.read()html = html.decode("utf-8")print(html)Print out the results.

See such a large bar, then compare the source code of the web page, found that it is consistent.

This observation is very important, because it means that the site does not use AJAX asynchronous loading, otherwise we will start to grab the work of the package, which we will leave to analyze the dynamic website. It is recommended that you use it when there is no better way. I remember that there is a direct judgment method before, but I forgot it carelessly. If you know something, please send it to me.
Now we get the response of the website, and then we want to get the data to parse and extract, but so on. Considering that we want to crawl a large number of novels, it is really a failure not to do a database storage, the author recommends MongoDB database, which belongs to NOSQL type database, mainly document storage. It is very suitable to crawl novels here. But it needs a certain program to install it. If you want to try it, you can refer to the download and installation tutorials for reference. http://blog.csdn.net/u011262253/article/details/74858211 In order to start easily after installation, you can add environment variables, but there is a pit here. You need to open mongod first (pay attention to mongodb, don't open Mongo first). Then you need to add dbpath path path accurately. Otherwise, opening will easily fail.
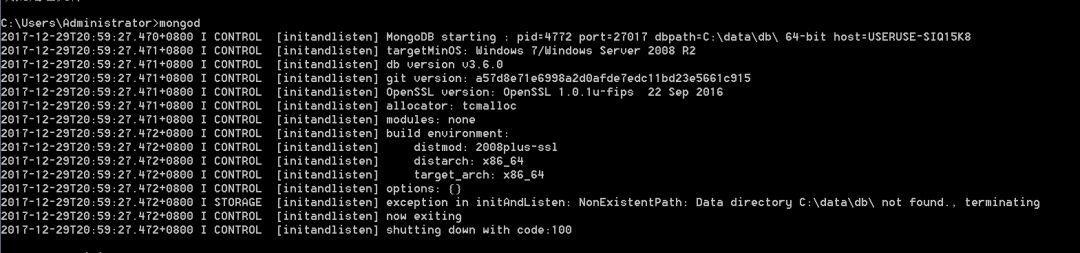
Failure state
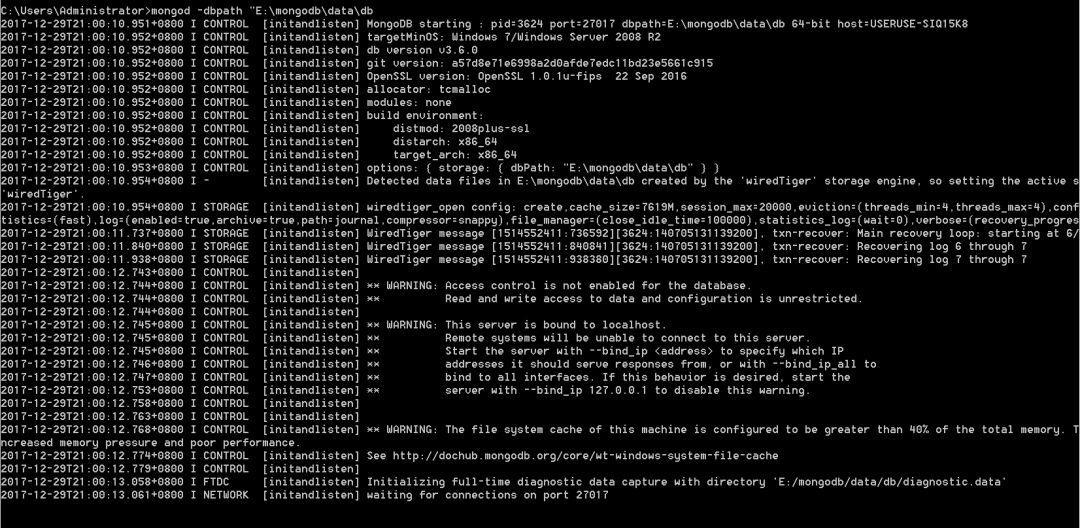
Successful state
After adding the path, the connection is successful, waiting for connections on port 27017, which means that the database connection is successful, and then don't turn off the terminal. Only by keeping the database connected, can you run the MongoDB database (otherwise you don't know how you died if you make a mistake)
Well, after connecting the database, we will link the database and the editor interactively. The location is very secret. Add the component Mongo Plugin under File > Settings > Plugins, and download one without:
Steal a map
We write code in the editor, introduce Python module pymongo which is used to interact with MongoDB, and then link the port of MongoDB database at the top, default is 27017. We first create a database called reading, and then create a new table called sheet_words in reading, the code is as follows:
#coding:utf-8import pymongoimport urllib.requestclient = pymongo.MongoClient('localhost',27017)reading = client['reading']sheet_words = reading['sheet_words']Let's find a novel called "Xiu Luo Wu Shen" to practise. Personally, I hate flipping pages and sometimes jumping out of advertisements. At this time, I have to go back and flip pages again. As a lazy lazy person, I think it would be better if I put the whole novel in a document and read it again, but if I copy and paste chapter by chapter, I want to return it. Forget it, then you will know how convenient the crawler is. Okay, now what we need to do is to crawl down the novel "Xiu Luo Wu Shen" and back it up in the database. When we get the response, we should choose a method to parse the web page. The general method is re,xpath,selector(css). We recommend that novice use XPath instead of re. One reason is that re is not good enough to cause errors. When you decide to solve problems with regular expressions, you have two problems. Comparing with xpath, XPath is a clear and stable step. Secondly, it can copy XPath path directly in Firefox, Chrome and other browsers, which greatly reduces our workload. Fig.
If you decide to use xpath, we need to introduce etree module from lxml, then we can parse the web page with HTML() method in etree, copy the path of the data we need from the page > inspection element (F12). I choose the title and content of each chapter of the novel, the above picture, the above picture:
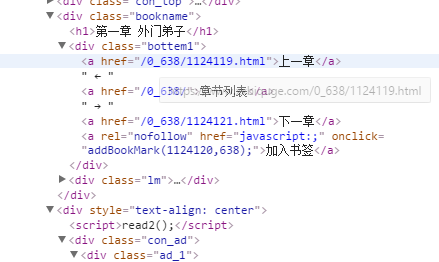
Path //div[@class="readAreaBox content"]/h1/text()
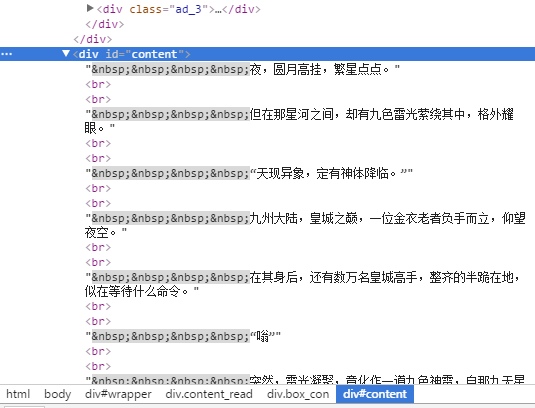
Path / html/body/div[4]/div[2]/div[2]/div[1]/div[2]/text()
Note that there's another pit. When you copy xpath, you get this one:
//div[@class="readAreaBox content"]/h1
And this East;
/html/body/div[4]/div[2]/div[2]/div[1]/div[2]
But what you need is the text in this path, so we need to add another specific text: / text(), and then just like above. Up the code, check the data:
url = 'http://www.17k.com/list/493239.html'response = urllib.request.urlopen(url)html = response.read().decode("utf-8")tree = etree.HTML(html)dom = tree.xpath('//a[@target="_blank"][@title]/@href')for i in dom: data = { 'words':"http://www.17k.com" + i } sheet_words.insert_one(data)# $lt/$lte/$gt/$gte/$ne,Equivalent in turn to</<=/>/>=/!=. (l Express less g Express greater e Express equal n Express not )try: os.mkdir("Xiu Luo's Wushen Novels")except FileExistsError: passos.chdir("Xiu Luo's Wushen Novels")for item in sheet_words.find(): filename = "The God of God" with open( filename,"a+") as f: contents = urllib.request.urlopen(item["words"]) responses = contents.read().decode("utf-8") trees = etree.HTML(responses) title = trees.xpath('//div[@class="readAreaBox content"]/h1/text()') word = trees.xpath("/html/body/div[4]/div[2]/div[2]/div[1]/div[2]/text()") a = ''.join(title) b = ''.join(word) f.write(a) f.write(b) #print(''.join(title))The novel is a little big, totaling 3500 chapters. Wait for about 4-7 minutes. Open the folder "Xiu Luo Wu Shen Novels" and you can see the whole novel that we downloaded without turning over the page. The links of each chapter are backed up in the database. It automatically starts from zero. That is to say, if you want to read Chapter 30, you have to open the links with serial number 29. This adjusts the order of downloads. Well, the author is lazy, and the reader who wants to try can change it by himself.

Novel text
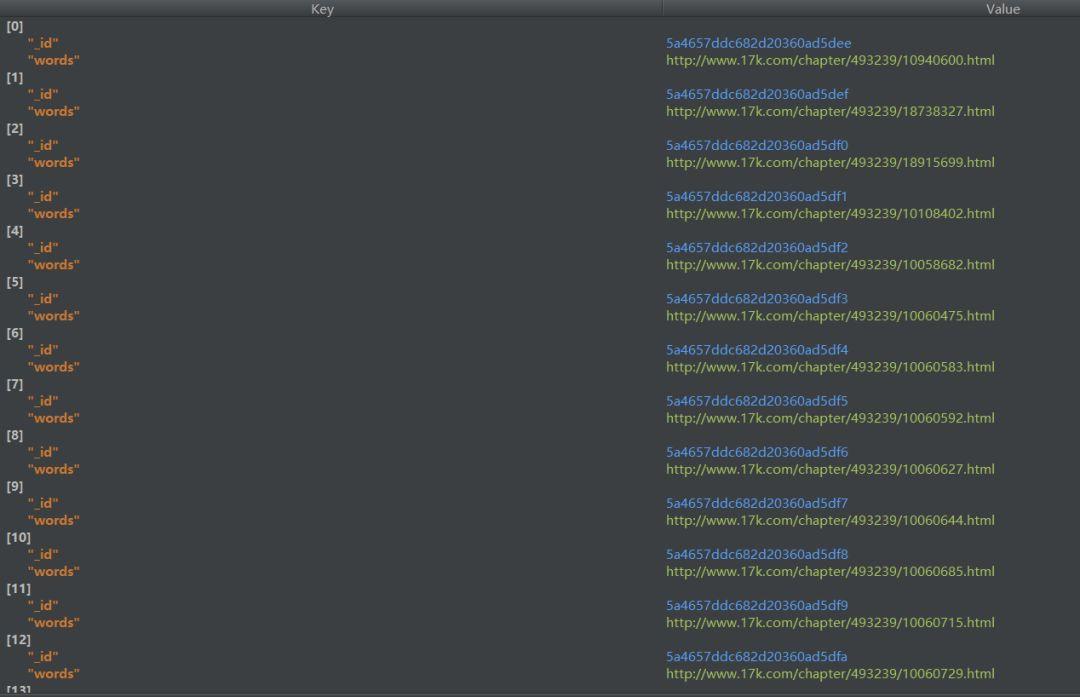
Database Connection
Look, it feels good. Good examples are finished. Next we are going to get to the point.
We want to crawl the whole website like the example above. Of course, it's no longer recommended to use an ordinary editor to execute it. Smart readers have found that a novel has crawled for 4 minutes, so thousands of books can crawl well for a while. This shows the role of Scripy Framework. It's excellent to write engineering reptiles with a special Scripy Framework. For fast and labor-saving, it is a necessary medicine for writing insects at home.
2. Climbing All Novels on the Novels List
Firstly, install all components of Scrapy. It is recommended that all components except pywin32 be installed with pip. No, Du Niang. It is very simple. pywin32 needs to download the same installation file as the Python version you use.
To connect: https://sourceforge.net/projects/pywin32/
Scrapy plug-in installed successfully
Then it's the old rule that if you don't want to find the path bit by bit every time the terminal runs, add the root directory to the environment variable and open the terminal. Let's test whether the installation is successful:
Successful installation of Scrapy
OK, after installation, open the terminal and build a new Scrapy project. Here you can choose to use various functions of Scrapy according to the index. It is not explained in detail here. The Scrapy project folder we have built has already appeared in the D disk:
Open the folder and we will see that the Scrapy framework has automatically placed all the raw materials we need in the reading folder:

Open the internal reading folder and add the crawler py code file to the spiders folder:
In addition to the spider files we write, we also define the content set we want to crawl in items.py. It's a bit like a dictionary. The name can be freely picked up, but the existing inheritance class scrapy.Item can't be changed. This is a self-defined class within Scrapy, which can't be found. Spider uses us to grab a single book and add a for loop to OK. It's very simple. If you don't say a word, you can get the picture above.
# -*- coding: utf-8 -*-import scrapyimport urllib2from lxml import etreeimport osfrom reading.items import ReadingSpiderItemimport sysreload(sys)sys.setdefaultencoding('utf-8')class ReadingspiderSpider(scrapy.Spider): name = 'bigreadingSpider'#Reptile name allowed_domains = ['http://www.xinbiquge.com/']#Total domain start_urls = ['http://www.bxquge.com/paihangbang/']#home page def parse(self, response): sel = scrapy.selector.Selector(response)#Analytic domain for i in range(2,10): path = '//*[@id="main"]/table[' +str(i)+ ']/tbody/tr[1]/td[2]/span'#Ranking Path sites = sel.xpath(path) items = [] for site in sites:#Press9Crawl through the rankings item = ReadingSpiderItem() path_list_name = '//*[@id="main"]/table[' +str(i)+ ']/tbody/tr[1]/td[2]/span/text()' item['list_name'] = site.xpath(path_list_name).extract()#List Name try: os.mkdir(item['list_name'][0]) except IOError: pass os.chdir(item['list_name'][0]) for li in range(1,21): title = '//*[@id="tb' + str(i-1) + '-1"]/ul/li['+str(li)+']/a/text()' item['name'] = site.xpath(title).extract()#Title url = 'http://www.bxquge.com/' path_link = '//*[@id="tb'+ str(i-1) +'-1"]/ul/li[' + str(li) + ']/a/@href'#Bibliographic links item['link'] = site.xpath(path_link).extract() full_url = url + item['link'][0] headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \ (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063'} #request = urllib2.Request(''.join(item['link']),headers=headers) request = urllib2.Request(full_url,headers=headers) try: os.mkdir(item['name'][0]) except IOError: pass os.chdir(item['name'][0]) response = urllib2.urlopen(request).read().decode('utf-8') tree = etree.HTML(response) for j in range(1,11): path_title = '//*[@id="list"]/dl/dd['+ str(j) +']/a/text()' item['title'] = tree.xpath(path_title)#Chapter name path_words_page = '//*[@id="list"]/dl/dd['+ str(j) +']/a/@href' word_page = tree.xpath(path_words_page) try: url_words = full_url + word_page[0] request_words = urllib2.Request(url_words,headers=headers) response_words = urllib2.urlopen(request_words).read().decode('utf-8') tree_words = etree.HTML(response_words) path_words = '//*[@id="content"]/text()' item['words'] = tree_words.xpath(path_words)#Front20Chapter content except urllib2.HTTPError: pass items.append(item) try: filename = r''.join(item['title'][0]) + '.json' with open(filename,"a+") as f: a = ''.join(item['title']) b = ''.join(item['words']) f.write(a) f.write(b) except IOError: pass path_now = os.getcwd() path_last = os.path.dirname(path_now) os.chdir(path_last) path_now = os.getcwd() path_last = os.path.dirname(path_now) os.chdir(path_last)Python is indeed an exciting and powerful language. The right combination of Python's performance and features makes programming with Python interesting and simple.
Well, don't talk nonsense, now share my Python learning materials to you!
Write a deficiency, you can contact Wenping's QQ. Please give your advice!!!