Basic application of urllib 3 Library
Urllib 3 is a powerful and well-organized Python library for HTTP clients. Many native Python systems have started to use urllib 3. Urllib3 provides many important features that are not available in the python standard library:
- Thread safety
- Connection pool
- Client SSL/TSL authentication
- File segment code upload
- Assist in handling duplicate requests and HTTP redirects
- Support compression coding
- Support HTTP and SOCKS proxy
- 100% test coverage
The way of receiving data is in bytes, because if you access video or pictures, if you receive them in str, the data may be incomplete, and the form of bytes ensures the integrity of the data
For example, use GET to access a page and view the content:
import urllib3
if __name__ == '__main__':
http = urllib3.PoolManager() # Use a PoolManager instance to generate the request
baidu = http.request("GET","http://wwww.baidu.com ") # use the request method to create a request
print(baidu.status) # 200 normal 302 jump 403 unlimited 404 page without 500 server internal error (usually reliable, but can be changed)
print((baidu.data))
Submit content access page by POST:
import urllib3
if __name__ == '__main__':
http = urllib3.PoolManager()
# baidu = http.request("GET","http://wwww.baidu.com")
data = {"username": "admin", "password": "123456"}
baidu = http.request("POST", "http://www.baidu.com/admin.php", fields=data)
print(baidu.status) # 200 normal 302 jump 403 unlimited 404 page without 500 server internal error (usually reliable, but can be changed)
print((baidu.data).decode()) # decode() converts bytes to characters
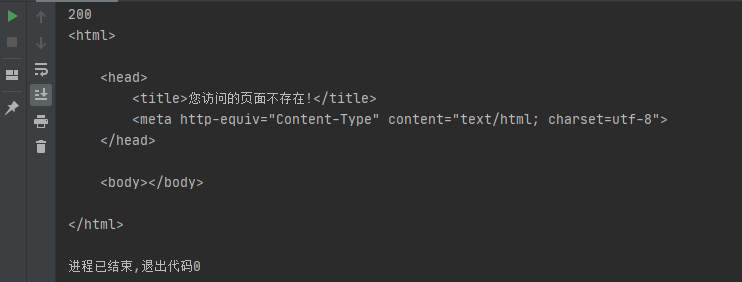
It can also be seen here that the page does not exist and returns 200
Exception handling optimization
- Redirect:
When a redirection problem with a status code beginning with 3 is encountered in the network request, the redirection is allowed by default in the Requests, that is, the access will continue in case of redirection. We Kenya reset redirect = flame - Retry:
The default number of retries is 3. You can also specify the number of retries=5 - Disable warning:
Urllib 3 will be warned when processing HTTPS requests, and urllib 3 needs to be referenced in advance disable_ Warnings() disable warnings
Basic application of Requests Library
Seven main methods of requests Library:
| method | explain |
|---|---|
| requsts.requst() | The most basic method of constructing a request is the support of the following methods |
| requsts.get() | GET the web page, corresponding to the GET method in HTTP |
| requsts.post() | Submit information to the web page, corresponding to the POST method in HTTP |
| requsts.head() | Get the header information of html web page, corresponding to the HEAD method in HTTP |
| requsts.put() | Submit the put method to html, corresponding to the put method in HTTP |
| requsts.patch() | Submit a local request modification request to an html web page, corresponding to the PATCH method in HTTP |
| requsts.delete() | Submit a DELETE request to html, corresponding to the DELETE method in HTTP |
- GET request and pass parameters:
request.get(url='http://www.test.com/', params={'test':'123'})
- POST request and transfer parameters
request.post(url='http://www.test.com/', data={'username':'admin','password':'pass'})
- Content of response body:
r.encoding Get current encoding r.encoding = 'utf-8' Set code r.text with encoding Parse the returned content. The response body in string mode is automatically decoded according to the character encoding of the response header. r.content Returns in bytes (binary). The response body in byte mode will be automatically decoded for you gzip and deflate Compression. r.headers The server response header is stored as a dictionary object, but this dictionary is special. The dictionary key is case insensitive. If the key does not exist, it will be returned None. . r.staus_code Response status code r.json() Requests Built in JSON Decoder to json Return in form, and ensure that the returned content is json Format, otherwise an exception will be thrown if there is an error in parsing. r.raise_for_staus() Exception thrown for Failed Request (not 200 response)
- Customize header / cookie content:
header = {'user-agent':'my-app/0.0.1'}
cookie = {'key':'value'}
r = requests.get/post('your url', headers=header, cookies=cookie)
- Set HTTP proxy:
proxies = {'http':'ip1','https':'ip2'}
requests.get('url',proxies=proxies)
- Basic authentication:
import requests
from requests.auth import HTTPBasicAuth
r = requests.get('https://test.com/', auth=('user', 'passwd'))
print(r.json())
- Exception handling:
import requests
from requests.exceptions import ReadTimeout, HTTPError, RequestException, ConnectionError
try:
response = requests.get('http://test.com', timeout=0.3)
print(response.status_code)
except ReadTimeout:
print('Timeout')
except HTTPError:
print('Http Error')
# except ConnectionError:
# print('Connection Error')
except RequestException:
print('Request Error ')
When we use python crawlers, it is more recommended to use the requests library, because requests is more convenient than urllib. Requests can directly construct get and post requests and initiate them, while urllib Request can only construct get and post requests before initiating.
Basic application of HackRequests Library
HackRequests is based on Python 3 X is an HTTP underlying network library for hackers. If you need a less bloated and elegant design like requests, and provide the underlying request package / response package to facilitate your next analysis, for a large number of HTTP requests, hack requests thread pool can also help you achieve fast response.
- Design as easy to use as requests;
- Provide an interface to obtain the underlying request package and return the original package for further analysis;
- It supports sending HTTP original messages and replaying from Burp Suite and other packet capturing software;
- Hack requests is a single file module, which can be easily transplanted to other projects.
HackRequests library call method:
hack.http() parameter options:
| Parameter name | Parameter function | Parameter type |
|---|---|---|
| URL (required) | Used to pass an address | str |
| post | The post parameter is used to pass the post submission. When this parameter is selected, the method will automatically change to post. The type of the post parameter can be str or dict | str/dict |
| method | Access magic currently supports three types: HEAD, GET and POST. The default is GET | str |
| location | When the status codes are 301 and 302, it will jump automatically. The default is True | str |
| proxy | Proxy, a tuple needs to be passed in, similar to ('127.0.0.1 ',' 8080 ') | Tuple |
| headers | Customize the HTTP header, which can be passed into the dictionary or the original request header | str/dict |
| cookie | Custom cookie, which can be passed in dictionary or original cookie string | str/dict |
| referer | Impersonate user Referer | str |
| user_agent | User request header. If it is empty, a normal request header will be simulated | str |
| real_host | Used to fill in the injection statement in the header host field in the host header injection, and fill in the real address here | str |
hack.http() return value:
| Interface parameters | function | return type |
|---|---|---|
| status_code | Get return status code | int |
| content() | Get return bytes | bytes |
| text() | Get the returned text (automatically transcoded) | str |
| header | Return original response header | str |
| headers | Returns the dictionary form of the original response header | dict |
| charset | Get encoding type | str |
| log | Get the request packet / return packet sent by the bottom layer | dict |
| url | Return the url. If there is a jump, it is the url after the jump | str |
| cookie | Return the requested Cookie | str |
| cookies | Returns the dictionary form of the Cookie after the request | dict |
httpraw() parameter options:
| Parameter name | Parameter type | Parameter function |
|---|---|---|
| Raw (required) | str | Original message |
| ssl | bool | Whether the website is https or not. The default is False |
| proxy | tuple | Agent address |
| location | bool | Auto jump, default to true |
| real_host | str | Used to fill in the injection statement in the header host field in the host header injection |
Return value of httpraw():
| Interface parameters | function | return type |
|---|---|---|
| status_code | Get return status code | int |
| content() | Get return bytes | bytes |
| text() | Get the returned text (automatically transcoded) | str |
| header | Return original response header | str |
| headers | Returns the dictionary form of the original response header | dict |
| charset | Get encoding type | str |
| log | Get the request packet / return packet sent by the bottom layer | dict |
| url | Return the url. If there is a jump, it is the url after the jump | str |
| cooke | Return the requested Cookie | str |
| cookies | Returns the dictionary form of the Cookie after the request | dict |
Write a directory traversal script
The dictionary here is the dictionary of Yujian, which traverses the DVWA shooting range:
import HackRequests
def Hackreq(url):
hack = HackRequests.hackRequests()
headers = {
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0"
}
try:
target = hack.http(url, headers=headers)
if target.status_code == 200:
print("%s is success" % url)
return url
elif target.status_code != 404:
print("%s is %d" % (url, target.status_code))
except:
pass
if __name__ == '__main__':
with open("E:\Codepy\PyCharm\DIR.txt", "r") as file:
lines = file.readlines()
urls = []
for lin in lines:
url = "http://127.0.0.1/i/DVWA-master%s" % lin
urls.append(url[:-1])
success_url = []
for url in urls:
res = Hackreq(url)
if res is not None:
success_url.append(res)
else:
continue
# print(success_url)
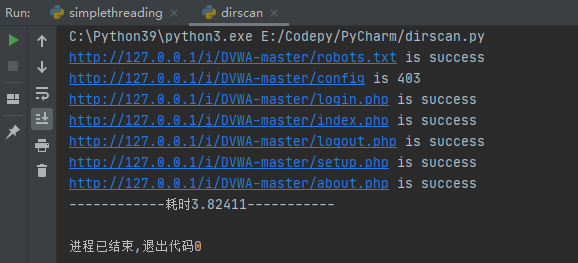
The output results are as follows:
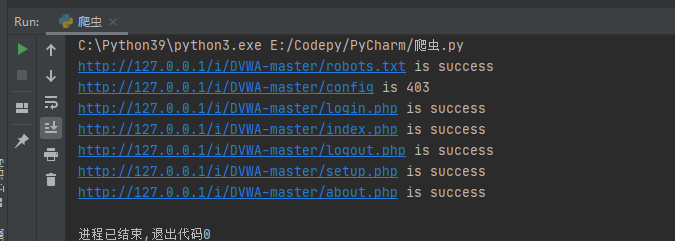
Multithreading optimization
The optimized code is as follows:
import HackRequests
import threading
import time
threads = []
thread_max = threading.BoundedSemaphore(500)
headers = {
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0"
}
def Hackreq(url):
hack = HackRequests.hackRequests()
try:
target = hack.http(url, headers=headers)
if target.status_code == 200:
print("%s is success" % url)
elif target.status_code != 404:
print("%s is %d" % (url, target.status_code))
except:
pass
thread_max.release()
def scan(file, url):
for i in file:
newurl = url + i
newurl = newurl.strip()
thread_max.acquire()
t = threading.Thread(target=Hackreq, args=(newurl,))
threads.append(t)
t.start()
for t in threads:
t.join()
if __name__ == '__main__':
start = time.time()
url = "http://127.0.0.1/i/DVWA-master"
director = "E:\Codepy\PyCharm\DIR.txt"
file = open(director)
scan(file, url)
end = time.time()
totaltime = end - start
print("------------time consuming{0:.5f}-----------".format(totaltime))
It can be seen that the time consumption is greatly reduced: