The whole crawler is based on selenium and Python, running the packages needed
1 mysql,matplotlib,selenium
Need to install selenium Firefox browser driver, Baidu search.
The whole crawler is modular. Functions and classes with different functions are placed in different files. Finally, constants that need to be configured are placed in constant.py.
Project address: GitHub (click through)
The main thread of the whole crawler is the Main.py file. After setting constant.py, it can run Main.py directly.
Analysis from the Main Line
Main.py
1 # /bin/python 2 # author:leozhao 3 # author@email: dhzzy88@163.com 4 5 """ 6 This is the main program of the whole crawler system. 7 """ 8 import numpy as np 9 10 import dataFactory 11 import plotpy 12 import sqlDeal 13 import zhilian 14 from Constant import JOB_KEY 15 16 # 17 # Start the crawler program 18 zhilian.spidefmain(JOB_KEY) 19 20 """ 21 Visualization of data after crawling 22 """ 23 # Reading crawled data from a database 24 # First you get the tuple name,salray, demand,welfare. 25 26 value = sqlDeal.sqlselect() 27 # Wage cap, floor, average 28 updata = np.array([], dtype=np.int) 29 downdata = np.array([], dtype=np.int) 30 average = np.array([], dtype=np.int) 31 for item in value: 32 salray = dataFactory.SarayToInt(item[1]) 33 salray.slove() 34 updata = np.append(updata, salray.up) 35 downdata = np.append(downdata, salray.down) 36 average = np.append(average, (salray.up + salray.down) / 2) 37 38 # Upper and lower wage limits 39 average.sort() 40 41 # Matching city information is not yet realized 42 43 # statistical information 44 # Both graphics are loaded for easy viewing 45 plotpy.plotl(average) 46 plotpy.plots(average) 47 48 print(average, average.sum()) 49 print("average wage:", average.sum() / len(average)) 50 print("Highest:", average.max()) 51 print("minimum", average.min()) 52 print("Number of Posts", len(average)) 53 54 # Drawing
Basically, it is organized by the whole execution process of the crawler.
Import zhilian.py from the function file
1 # /bin/python 2 # author:leo 3 # author@email : dhzzy88@163.com 4 from selenium import webdriver 5 from selenium.webdriver.common.by import By 6 from selenium.webdriver.common.keys import Keys 7 from selenium.webdriver.support import expected_conditions as EC 8 from selenium.webdriver.support.ui import WebDriverWait 9 10 import sqlDeal 11 from Constant import PAGE_NUMBER 12 13 14 def init(key="JAVA"): 15 # The home page of Zhaolian Recruitment Search keywords, initialize to the collection page 16 url = "https://www.zhaopin.com/" 17 opt = webdriver.FirefoxOptions() 18 opt.set_headless() #Setting Headless Browser Mode 19 driver = webdriver.Firefox(options=opt) 20 driver.get(url) 21 driver.find_element_by_class_name("zp-search-input").send_keys(key) 22 # driver.find_element_by_class_name(".zp-search-btn zp-blue-button").click() 23 driver.find_element_by_class_name("zp-search-input").send_keys(Keys.ENTER) 24 import time 25 time.sleep(2) 26 all = driver.window_handles 27 driver.switch_to_window(all[1]) 28 url = driver.current_url 29 return url 30 31 32 class ZhiLian: 33 34 def __init__(self, key='JAVA'): 35 # default key:JAVA 36 indexurl = init(key) 37 self.url = indexurl 38 self.opt = webdriver.FirefoxOptions() 39 self.opt.set_headless() 40 self.driver = webdriver.Firefox(options=self.opt) 41 self.driver.get(self.url) 42 43 def job_info(self): 44 45 # Extracting Work Information You can load the details page 46 job_names = self.driver.find_elements_by_class_name("job_title") 47 job_sarays = self.driver.find_elements_by_class_name("job_saray") 48 job_demands = self.driver.find_elements_by_class_name("job_demand") 49 job_welfares = self.driver.find_elements_by_class_name("job_welfare") 50 for job_name, job_saray, job_demand, job_welfare in zip(job_names, job_sarays, job_demands, job_welfares): 51 sqlDeal.sqldeal(str(job_name.text), str(job_saray.text), str(job_demand.text), str(job_welfare.text)) 52 53 # Waiting for Page Loading 54 print("Waiting for Page Loading") 55 WebDriverWait(self.driver, 10, ).until( 56 EC.presence_of_element_located((By.CLASS_NAME, "job_title")) 57 ) 58 59 def page_next(self): 60 try: 61 self.driver.find_elements_by_class_name("btn btn-pager").click() 62 except: 63 return None 64 self.url = self.driver.current_url 65 return self.driver.current_url 66 67 68 def spidefmain(key="JAVA"): 69 ZHi = ZhiLian(key) 70 ZHi.job_info() 71 # Set a number of pages to crawl 72 page_count = 0 73 while True: 74 ZHi.job_info() 75 ZHi.job_info() 76 page_count += 1 77 if page_count == PAGE_NUMBER: 78 break 79 # Remove objects after collection 80 del ZHi 81 82 83 if __name__ == '__main__': 84 spidefmain("python")
This is a program that calls selenium to simulate the browser loading dynamic pages. The core of the whole crawler is around this file.
After each page of information is crawled, the parsed data is stored in the database, and the definition of the database processing function is placed in another file, where only the logic of loading and extracting information is handled.
Store data in local mysql database
1 # /bin/python 2 # author:leozhao 3 # author@email :dhzzy88@163.com 4 5 import mysql.connector 6 7 from Constant import SELECT 8 from Constant import SQL_USER 9 from Constant import database 10 from Constant import password 11 12 13 def sqldeal(job_name, job_salray, job_demand, job_welfare): 14 conn = mysql.connector.connect(user=SQL_USER, password=password, database=database, use_unicode=True) 15 cursor = conn.cursor() 16 infostring = "insert into zhilian value('%s','%s','%s','%s')" % ( 17 job_name, job_salray, job_demand, job_welfare) + ";" 18 cursor.execute(infostring) 19 conn.commit() 20 conn.close() 21 22 23 def sqlselect(): 24 conn = mysql.connector.connect(user=SQL_USER, password=password, database=database, use_unicode=True) 25 print("Connect database to read information") 26 cursor = conn.cursor() 27 28 cursor.execute(SELECT) 29 values = cursor.fetchall() 30 conn.commit() 31 conn.close() 32 return values
Two functions
The first one is responsible for storing data.
The second is responsible for reading data.
Processing the data in another class after reading the data
Information like 10K-20K, for example, prepares for visualization
# /bin/python # author:leozhao # author@email : dhzzy88@163.com import matplotlib.pyplot as plt import numpy as np from Constant import JOB_KEY # Line Graph def plotl(dta): dta.sort() print("dta", [dta]) num = len(dta) x = np.linspace(0, num - 1, num) print([int(da) for da in dta]) print(len(dta)) plt.figure() line = plt.plot(x, [sum(dta) / num for i in range(num)], dta) # plt.xlim(0, 250) plt.title(JOB_KEY + 'Job_Info') plt.xlabel(JOB_KEY + 'Job_Salray') plt.ylabel('JobNumbers') plt.show() # Bar chart def plots(dta): fig = plt.figure() ax = fig.add_subplot(111) ax.hist(dta, bins=15) plt.title(JOB_KEY + 'Job_Info') plt.xlabel(JOB_KEY + 'Job_Salray') plt.ylabel('JobNumbers') plt.show()
Finally, the data is put into the drawing program to draw.
Finally, the relevant data are calculated.
In the crawling process, the data is stored in the database in time to reduce the proportion of virtual machine memory.
Put the data results below.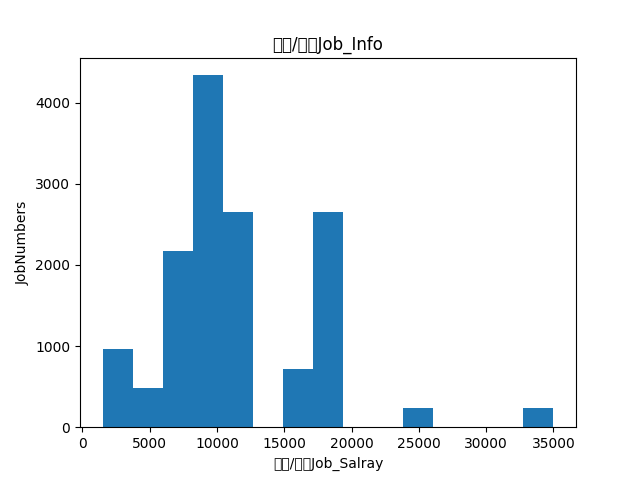
Here's the salary survey for financial jobs.
Here's the salary survey for Materials Science
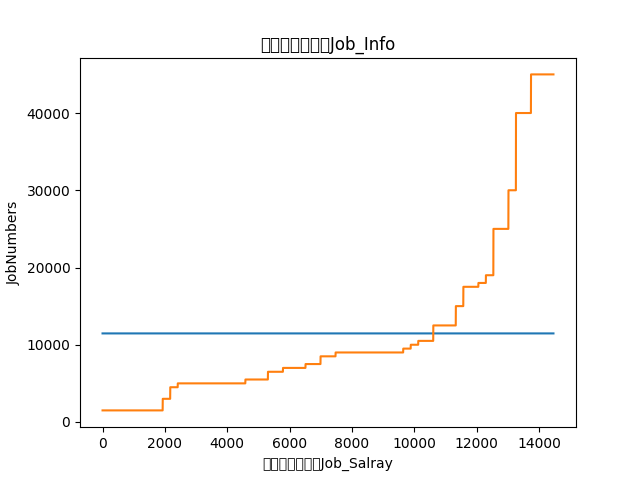
Blue is the average wage.
Attention should be paid to the requirement of doctoral degree and master's degree above the average.
Specific data processing has no time to do, there is time to do.