Python module
Modules in Python are a collection of functions, which can be divided into three categories:
- Built in modules: Python comes with some built-in libraries, which can be used out of the box
- Third party module: the module downloaded through pip command does not need to be defined by itself. Python has a large number of third-party modules
- Custom module: one Py file is a module, so I wrote it myself Py files can also be used as modules. For example, a file named m.py is a custom module named M
Custom module
The user-defined module is a module written by yourself. The benefits are as follows:
- Classify codes of the same function
- Reduce code coupling and code redundancy
- Make the organization structure of the whole program clearer for later maintenance
Structural classification
Because of one py file is a module, so we can create 2 py file, one as the program entry file and the other as the function module file. The following is the structure diagram:
. ├── m1.py # Function module file └── run.py # Program entry file
First in M1 Py to write a basic function:
# m1.py
print("this is module m1")
def add(x, y):
return x + y
The second is in run Write a print statement in py:
# run.py
print("run ..")
import is easy to use
If run You want to use M1 in py What should I do with the add() function in py?
Just run Import m1 from py The add() function defined in py is sufficient. Note that you must also start with m1 when using:
# run.py
import m1 # ❶
print("run ..")
result = m1.add(1, 2) # ❷
print(result)
# this is module m1
# run ..
# 3
❶: when the interpreter finds import m1, it will find M1 Py file, and M1 Py, so this is module m1 will be printed below
❷: the add() function in m1 is used
For ❶, a question is raised. If you import this m1 file multiple times, will the code in it be executed multiple times?
The result is yes or no, that is, the code in the module will be executed only when the module is imported for the first time. Multiple imports will only be executed once. Refer to the Python module search section for the root cause.
# run.py
import m1
import m1
import m1
print("run ..")
result = m1.add(1, 2)
print(result)
# this is module m1 ❶
# run ..
# 3
Module namespace
Now we have 2 module files:
. ├── m1.py ├── m2.py └── run.py
And most of the codes in the two module files are similar:
# m1.py
print("this is module m1")
def add(x, y):
return x + y
# m2.py
print("this is module m2")
def add(x, y):
return x + y
What happens when two modules are imported into run and the add() function under them is used respectively?
# run.py
import m1
import m2
print("run ..")
resultM1 = m1.add(1, 2)
resultM2 = m2.add(1, 2)
print(resultM1)
print(resultM2)
# this is module m1
# this is module m2
# run ..
# 3
# 3
- run. When py is executed, M1 will be executed in the order of import Py and M2 Code in py file
- After m1 and m2 are executed, a module namespace will be generated
- run. Two identifiers will be generated in the global namespace of Py, pointing to M1 Py and M2 Module namespace for PY
The module namespace is as follows:
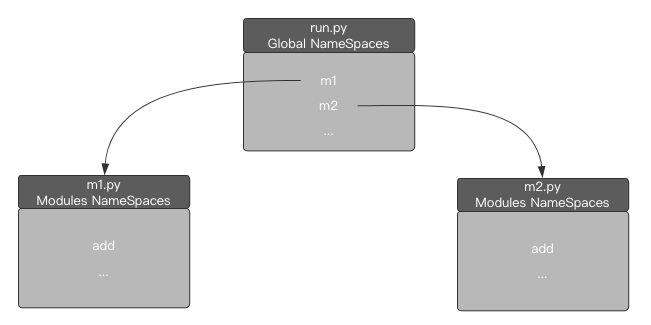
When you want to use m1 When add(), run Py finds the function identifier add in the namespace of the m1 module through the identifier m1 in the global namespace.
When using m2 When add(), run Py finds the function identifier add in the namespace of module M2 through the identifier m2 in the global namespace.
__ name__ And__ main__
When a module is written, it will be tested to ensure that the code is correct before it can be put into use.
As follows, write the test code of m1:
# m1.py
print("this is module m1")
def add(x, y):
return x + y
# test
print(add(1, 2))
After the test is OK, run Py:
# run.py
import m1
import m2
print("run ..")
resultM1 = m1.add(1, 2)
resultM2 = m2.add(1, 2)
print(resultM1)
print(resultM2)
# this is module m1
# 3 ❶
# this is module m2
# run ..
# 3
When running run After py, you will find that there are more than three printed in one place, because the test code is also executed when the m1 module is executed.
How to avoid this problem? We can do it in M1 Add a judgment statement to py:
# m1.py
print("this is module m1")
def add(x, y):
return x + y
# test
if __name__ == "__main__": # ❶
print(add(1, 2))
❶: __ name__: If so If the py file is executed as a script, the variable is__ main__, If so If the py file is executed as a module import, the variable is The name of the py file, such as m1 py is m1
Therefore, the purpose of adding this test statement is to py files can execute different codes when used in different ways:
- When the script is executed, the test code is run
- When a module is imported, the test code is not run
Module import
import ...
How to use the import statement:
- import module name
- The smallest unit to import is the module
Advantages and disadvantages of using import module:
- Advantage: it will not conflict with the current global namespace identifier
- Disadvantages: the identifier prefix on the right of import must be added when using the module function
As shown below, the same identifier function of 2 different modules does not conflict:
import time import datetime print(time.time()) print(datetime.time()) # 1621665686.779634 # 00:00:00
You can also import multiple modules in one line, separated by commas:
import time, datetime
from ... import ...
How to use the from statement:
- from module name import identifier
- The smallest cell imported is the specific function
Advantages and disadvantages of using the from statement to import modules:
- Advantages: when using module functions, the identifier prefix on the right of import must be added. If a specific function is directly imported, the prefix is not needed
- Disadvantages: it is easy to conflict with the current global namespace identifier
In the following example, since the datetime module is imported after, its time function identifier replaces the time function identifier of the time module:
from time import time from datetime import time print(time()) print(time()) # 00:00:00 # 00:00:00
The first mock exam can also import multiple functions under the same module in one line, and divide them by commas.
from time import time, sleep, ctime
Use of aliases
Use the as statement to alias the conflicting identifier:
from time import time as ttime from datetime import time as dtime print(ttime()) print(dtime()) # 1621665953.605452 # 00:00:00
*And__ all__
All identifiers under the module can be imported by using the from module name import *.
If you are the developer of this module, you can__ all__ Property specifies which identifiers are allowed to be imported by this import method.
- In__ all__ The identifier in can be imported in the form of from module name import *
- Not in__ all__ The identifier in will not be imported in the form of from module name import *
- If not defined__ all__ Property, all identifiers will be imported in the form of from module name import *
As follows, in M1 In the PY module file, an interface exposure function of getMax() is defined. In addition, there is an internal processing function computmax() and the module description variable desc:
# m1.py
def getMax(iterable):
currentMax = None
for index, item in enumerate(iterable):
if index == 0:
currentMax = computeMax(item, iterable[index + 1])
elif currentMax != item:
currentMax = computeMax(currentMax, item)
return currentMax
def computeMax(x, y):
return x if x > y else y
desc = "this is module m1"
__all__ = ("getMax", "desc") # ❶
❶: __ all__ The format of must be Tuple(str, str)
Now run If from m1 import * is used in py, the__ all__ All identifiers in are imported. In the following example, due to the use of__ all__ If the identifier defined in, an exception of NameError is thrown:
# run.py from m1 import * print(getMax) print(desc) print(computeMax) # <function getMax at 0x102bff6a8> # this is module m1 # NameError: name 'computeMax' is not defined
Circular import problem
Module b is imported into module a, and module a is imported into module b, and the import statements are in the first line. At this time, the problem of circular import will be caused.
Examples are as follows:
# run.py import m1 print(m1.desc)
# m1.py import m2 desc = "this is module m1" print(m2.desc)
# m2.py import m1 desc = "this is module m2" print(m1.desc)
Run Py, the results are as follows:
AttributeError: module 'm2' has no attribute 'desc'
The reason for the exception is:
run. The first line of Py imports m1, the first line of m1 imports m2, and the first line of M2 imports m1, resulting in m1 Desc failed to declare the object successfully, so an exception was thrown.
Execution steps:
- run.py: import m1 (load m1 into memory)
- m1.py: import m2 (load m2 into memory)
- m2.py: import m1 (m1 has been executed and will not be repeated)
- m2.py: desc = "this is module m2"
- m2.py: print(m1.desc)) (m1.desc does not declare an object and throws an exception)
terms of settlement:
- Put the statement from m1 to m2 at the end of the line
- Put the statement from m1 to m2 into the function and execute the function at the end of the line
Method 1:
# m1.py desc = "this is module m1" import m2 print(m2.desc)
Option 2:
desc = "this is module m1"
def importFunction():
import m2
print(m2.desc)
importFunction()
Module lookup
Find priority
Whether it is a from... Import... Statement or an import statement, module location lookup will be involved when importing a module.
Module search priority is as follows:
- Look for memory first
- Find hard disk after
When a module is imported once, it will be loaded into memory. Repeated import can directly get the module from memory, and the module code existing in memory will not be executed.
sys.modules
sys.modules is used to view modules that exist in memory. If the module to be imported exists here, it will be imported directly without executing the code:
>>> import sys >>> sys.modules ...
When a module existing on the hard disk is imported, the module will be loaded into memory. As long as it is a module existing in memory, the code will not be executed during repeated import.
In the following example, after the m1 module existing on the hard disk is imported for the first time, it is loaded into memory:
>>> tuple(sys.modules.items())[-1]
('rlcompleter', <module 'rlcompleter' from '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/rlcompleter.py'>)
>>> import m1
>>> tuple(sys.modules.items())[-1]
(('m1', <module 'm1' from '/Users/yunya/PycharmProjects/Python Basics/m1.py'>))
Ps: in fact, when the Python interpreter starts, it will automatically run all built-in modules and load them into memory, because these built-in modules are also stored on disk. You can find them in the lib directory of the Python interpreter installation root directory.
sys.path
When there is no module path in memory, it will follow sys The path order of path is found in the disk in turn.
If sys. Is printed under PyCharm Path, which will be optimized to find more paths than the native REPL environment. The following is marked with # numbers:
[ # '/Users/yunya/PycharmProjects/Project', # '/Users/yunya/PycharmProjects/Project', # '/Applications/PyCharm.app/Contents/plugins/python/helpers/pycharm_display', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python36.zip', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/lib-dynload', '/Users/yunya/Library/Python/3.6/lib/python/site-packages', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages', # '/Applications/PyCharm.app/Contents/plugins/python/helpers/pycharm_matplotlib_backend' ]
Print in native REPL environment:
>>> import sys >>> sys.path [ '', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python36.zip', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/lib-dynload', '/Users/yunya/Library/Python/3.6/lib/python/site-packages', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages' ] >>>
Module import specification
Some specifications to follow when importing modules:
-
Import order: the built-in module is at the top, the third-party module is in the middle, and the custom module is below
-
Custom module name style: snake naming
Ps: some modules in Python 2 are named hump, but in Python 3, they are named snake, such as pymysql, which is renamed pymysql
In addition, the module is also a first-class citizen, whose operation is assigned, passed parameters and so on.
Module writing specification
If you want to write a custom module, you also need to follow some specifications:
- Add a module document description on the first line to let others know what your module is
- Reduce the use of global variables, which will speed up the import when importing the module for the first time
- The classes and functions in the module need to be annotated
- Use if__ name__ == “__main__”: Write the test case