In the previous article, the data set is divided into 37 points in order, which will lead to inaccurate results. Therefore, this paper uses the kfold method in sklearn to realize cross validation, so as to make the results more accurate
Last article ----- > Python post processing data format run model (pycruise) - verify data validity
1. Introduction to cross validation method
The section on cross validation in the official website of sklearn: 3.1. Cross-validation: evaluating estimator performance¶
Those who are not used to the English version of sklearn can see the official document of the Chinese version: Scikit learn (sklearn) official document Chinese version
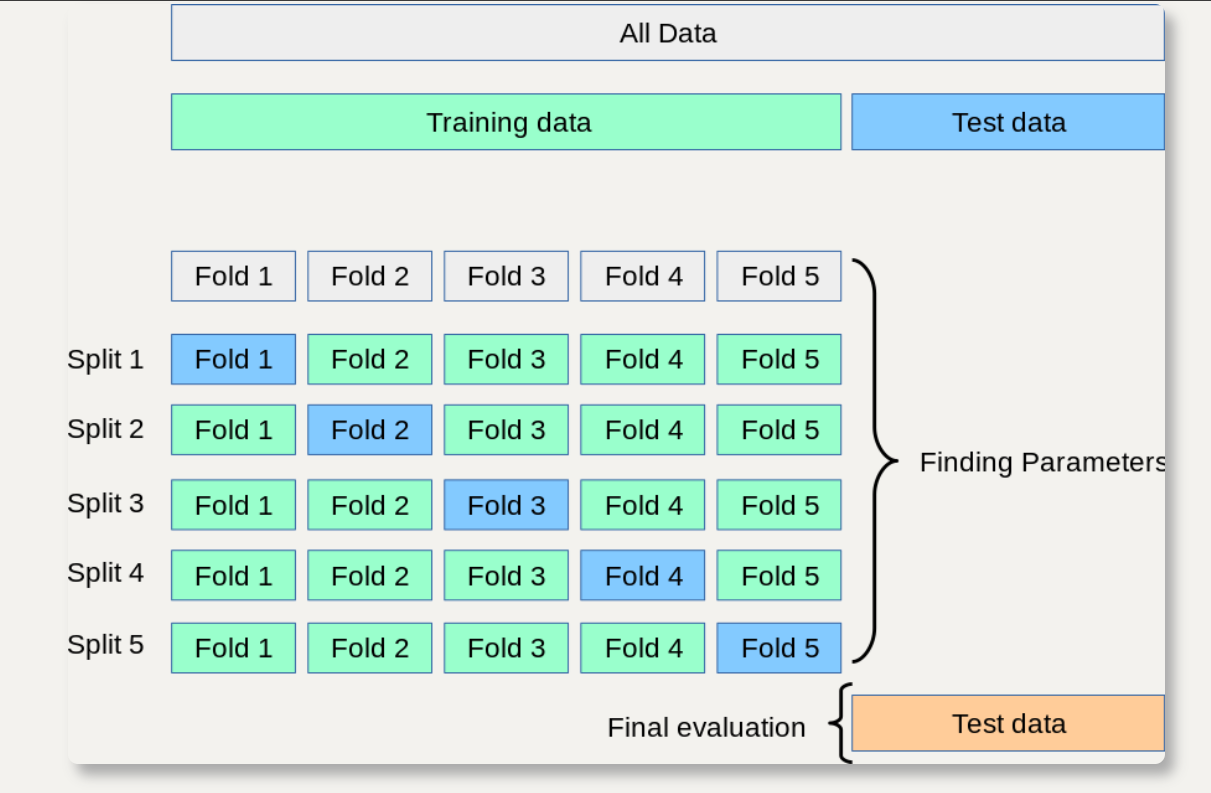
My understanding: Generally speaking, cross validation is to divide the data set into N parts in proportion (n-fold cross validation is divided into N parts), in which each part takes turns as the test set, the rest of the test set acts as the training set, runs the model in turn, and finally averages the scores to make the results more accurate
Reference blog: Cross validation in sklearn
[Python learning] - sklearn learning - data set segmentation method - random division and K-fold cross division and StratifiedKFold and stratifiedsufflesplit
2. Kfold method
For the introduction of kfold method, please refer to the blog: sklearn.KFold usage example
3. Processing process
The main codes to realize cross verification in this processing:
#The data set is divided into five parts, and the data set is randomly disrupted during allocation (shuffle is True),
# The way of each disturbance is the same (random_state = 1)
kf = KFold(5,shuffle = True,random_state = 1)
for a in kf.split(data_all):
train_sents = []#Training set per session
test_sents = []#Test set per test
a_train_index = a[0]
a_test_index = a[1]
for index in a_train_index:
train_sents.append(data_all[index])
for index in a_test_index:
test_sents.append(data_all[index])
# print(a_train_index)
# print(a_test_index)
# print(train_sents[1:50])
# print(test_sents[1:50])
# print(len(train_sents))#32584
# print(len(test_sents))#8146
Where data_ The format of all is as follows:
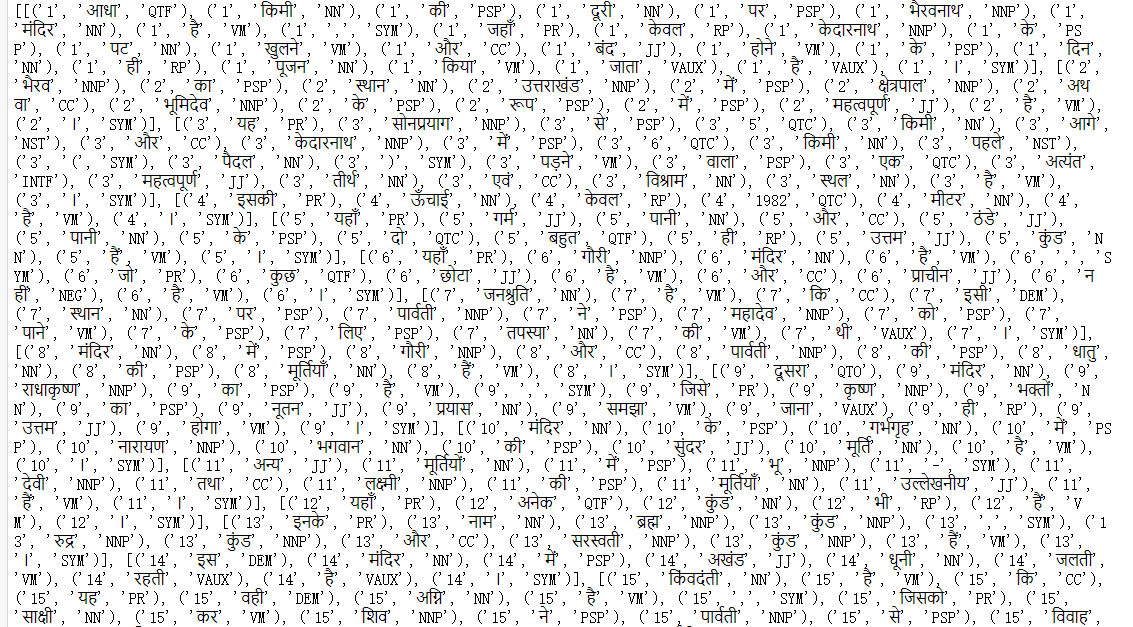
Several lists are embedded in a list (each list is a sentence), and there are several tuples in each list (each tuple represents a word, its number and label)
kf = KFold(5,shuffle = True,random_state = 1) for the parameters here, please refer to the blog: sklearn.KFold usage example
Or official documents: 3.1. Cross-validation: evaluating estimator
performance¶
One thing to note: what disrupts is the index of the subscript!!
Therefore, the above code uses two recycling data_all[index] restore the disturbed text content, and then append it into the list of training set and test set for running the model
Complete code:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn import svm
from array import array
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeRegressor
from sklearn import preprocessing
from sklearn.model_selection import KFold
from itertools import chain
import nltk,pycrfsuite
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.preprocessing import LabelBinarizer
def word2features(sent, i):
word = sent[i][0]
postag = sent[i][1]
features = [
'bias',
'word.lower=' + word.lower(),
'word[-3:]=' + word[-3:],
'word[-2:]=' + word[-2:],
'word.isupper=%s' % word.isupper(),
'word.istitle=%s' % word.istitle(),
'word.isdigit=%s' % word.isdigit(),
'postag=' + postag,
'postag[:2]=' + postag[:2],
]
if i > 0:
word1 = sent[i - 1][0]
postag1 = sent[i - 1][1]
features.extend([
'-1:word.lower=%s' % word1.lower(),
'-1:word.istitle=%s' % word1.istitle(),
'-1:word.issupper=%s' % word1.isupper(),
'-1:postag=%s' % postag1,
'-1:postag[:2]=%s' % postag1[:2],
])
else:
features.append('BOS')
if i < len(sent) - 1:
word1 = sent[i + 1][0]
postag1 = sent[i + 1][1]
features.extend([
'+1:word.lower=%s' % word1.lower(),
'+1:word.istitle=%s' % word1.istitle(),
'+1:word.issupper=%s' % word1.isupper(),
'+1:postag=%s' % postag1,
'+1:postag[:2]=%s' % postag1[:2],
])
else:
features.append('EOS')
return features
# Test effect
# sent=train_sents[0]
# print(len(sent))
# for i in range (len(sent)):
# print(word2features(sent,i))
# print("======================================")
# Complete feature transformation
def sent2features(sent):
return [word2features(sent, i) for i in range(len(sent))]
# Gets the category, the label
def sent2labels(sent):
return [label for token, postag, label in sent]
# Get word
def sent2tokens(sent):
return [token for token, postag, label in sent]
# Start processing
with open("POS-data_all.txt", "r+", encoding="utf-8") as f1:
data_all = f1.readlines()
list_data = []
list_target = []
# all
list1 = []
list_each = []
for line in data_all:
if line == '\n':
list1.append(list_each)
list_each = []
else:
temp = line.replace('\n', '')
temp = temp.split('\t')
# print(temp)
# print(type(temp))
yuan = tuple(temp)
# print(yuan)
list_each.append(yuan)
# line = line.split('\t')
# list1.append(line)
# print(type(line))
# print(line)
# print(test_sents)
# print(list1)
data_all = list1
# print(len(test_sents))
# for lie in list1:
# for str_each in lie:
# temp = str_each.replace('\n','')
# temp = temp.split('\t')
# print(temp)
# # print(type(temp))
# yuan = tuple(temp)
# print(yuan)
print(type(data_all)) # list
# print(data_all[1:50])
# #Extracting Hindi words
# for list_sentences in data_all:
# for tuple_words in list_sentences:
# list_data.append(tuple_words[1])
# list_target.append(tuple_words[2])
# # print(tuple_words[1]+" "+tuple_words[2])
# # print("===============================")
# # print(list_data)
# # print(list_target)
# X = np.array(list_data)
# y = np.array(list_target)
# print(type(X))
# print(type(y))
# print(X.shape)
# print(y.shape)
# print(X)
# print(y)
# print(data_all[0])
# Cross partition data set
# The data set is divided into five parts, and the data set is randomly disrupted during allocation (shuffle is True),
# The way of each disturbance is the same (random_state = 1)
kf = KFold(5, shuffle=True, random_state=1)
for a in kf.split(data_all):
train_sents = [] # Training set per session
test_sents = [] # Test set per test
a_train_index = a[0]
a_test_index = a[1]
for index in a_train_index:
train_sents.append(data_all[index])
for index in a_test_index:
test_sents.append(data_all[index])
# print(a_train_index)
# print(a_test_index)
# print(train_sents[1:50])
# print(test_sents[1:50])
# print(len(train_sents))#32584
# print(len(test_sents))#8146
# Start each model training and output results
# After the feature conversion is completed, you can view the feature content of the next line
# print(sent2features(train_sents[0])[0])
# Construct feature training set and test set
X_train = [sent2features(s) for s in train_sents]
Y_train = [sent2labels(s) for s in train_sents]
# print(len(X_train))
# print(len(Y_train))
X_test = [sent2features(s) for s in test_sents]
Y_test = [sent2labels(s) for s in test_sents]
# print(len(X_test))
# print(X_train[0])
# print(Y_train[0])
print(len(Y_test))
print(type(Y_test))
# model training
# 1) Create pycryfsuite Trainer
trainer = pycrfsuite.Trainer(verbose=False)
# Load categories of training features and classifications (label)
for xseq, yseq in zip(X_train, Y_train):
trainer.append(xseq, yseq)
# 2) Set training parameters and select L-BFGS training algorithm (default) and Elastic Net regression model
trainer.set_params({
'c1': 1.0, # coefficient for L1 penalty
'c2': 1e-3, # coefficient for L2 penalty
'max_iterations': 50, # stop earlier
# include transitions that are possible, but not observed
'feature.possible_transitions': True
})
print(trainer.params())
# 3) Start training
# The meaning is that the trained model is called conll2002-esp.cruise
trainer.train('conll2002-esp.crfsuite')
# Using the trained model, create a annotator for testing.
tagger = pycrfsuite.Tagger()
tagger.open('conll2002-esp.crfsuite')
example_sent = test_sents[0]
# Check the content of this sentence
# print(type(sent2tokens(example_sent)))
# print(sent2tokens(example_sent))
# print(''.join(sent2tokens(example_sent)))
# print('\n\n')
# print("Predicted:", ' '.join(tagger.tag(sent2features(example_sent))))
# print("Predicted:", ' '.join(tagger.tag(X_test[0])))
# print("Correct: ", ' '.join(sent2labels(example_sent)))
# View the effect of the model on the training set
def bio_classification_report(y_true, y_pred):
lb = LabelBinarizer()
y_true_combined = lb.fit_transform(list(chain.from_iterable(y_true)))
y_pred_combined = lb.transform(list(chain.from_iterable(y_pred)))
tagset = set(lb.classes_) - {'O'}
tagset = sorted(tagset, key=lambda tag: tag.split('-', 1)[::-1])
class_indices = {cls: idx for idx, cls in enumerate(lb.classes_)}
return classification_report(
y_true_combined,
y_pred_combined,
labels=[class_indices[cls] for cls in tagset],
target_names=tagset,
)
# Mark all information
Y_pred = [tagger.tag(xseq) for xseq in X_test]
print(type(Y_pred))
print(type(Y_test))
# Print out the evaluation report
print(bio_classification_report(Y_test, Y_pred))
ps: POS_ data_ The format of all file is shown in the previous blog: Python post processing data format run model (pycruise) - verify data validity