catalogue
2.2 test page turning - Taking Beijing Xinfadi vegetable price as an example
2.3.3 case of food and Drug Administration
selenium is a browser based automation module that can specify a series of actions in code and then act on the browser.
selenium has the disadvantage of low efficiency
1 download browser driver
1.1 drive of edge
View browser version:
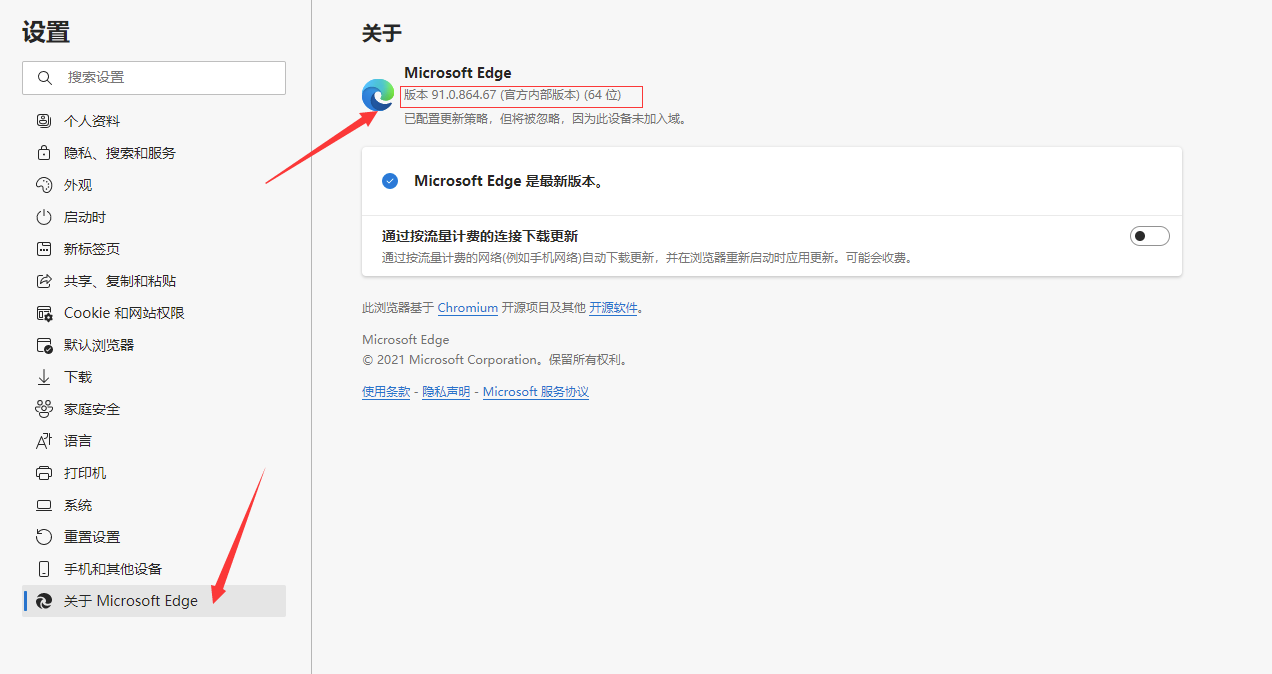
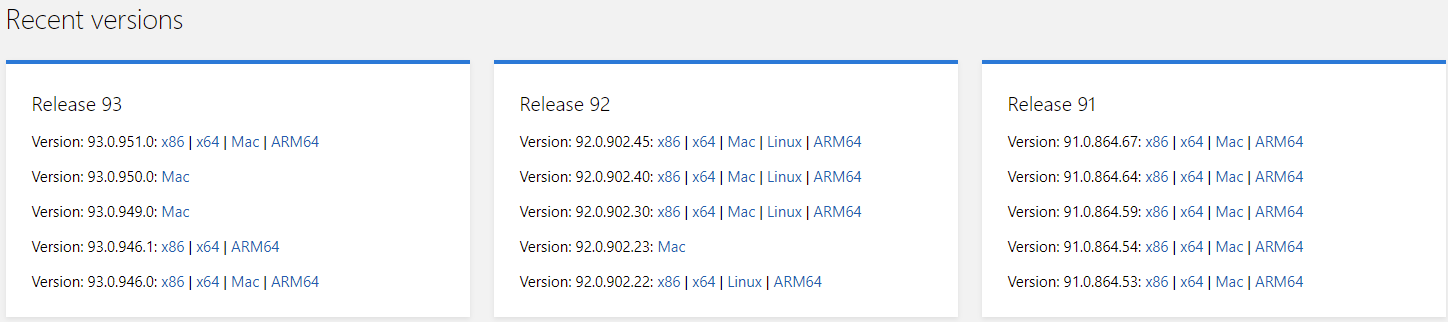
Download link:
Microsoft Edge Driver - Microsoft Edge Developer
https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
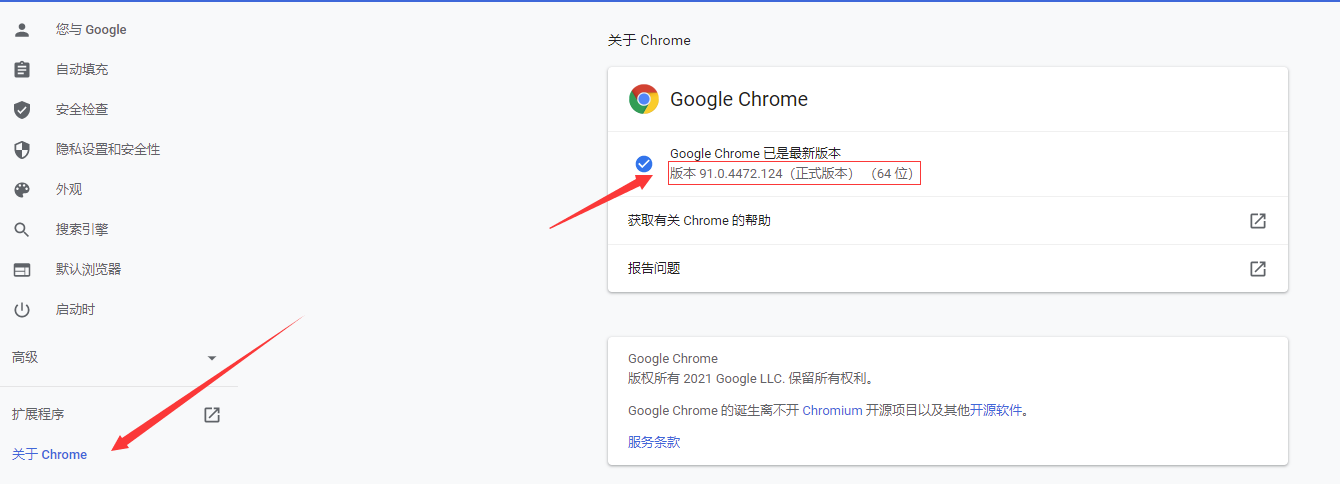
1.2 Google browser driver
Query browser version
Driver download address: http://npm.taobao.org/mirrors/chromedriver/
20210715 test driver supports up to version 89
selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 89
Current browser version is 91.0.4472.124 with binary path C:\Program Files\Google\Chrome\Application\chrome.exe
2. Simple test of selenium
2.1} function code fragment
First, the first step is to guide the package:
from selenium import webdriver
Set driver path: instantiate a browser object based on the browser driver
# The full path is recommended here edge_driver_path = r"...\msedgedriver.exe" browser = webdriver.Edge(executable_path=edge_driver_path)
Set url:
# Get the home page of Xinfadi vegetable price browser.get(url=r'http://www.xinfadi.com.cn/marketanalysis/0/list/1.shtml')
Drag to the bottom of the page and wait to ensure that the data loading is completed: [JS injection]
# Perform the operation at the lower end of the drop-down slider value browser
browser.execute_script('window.scrollTo(0, document.body.scrollHeight);')
# Wait a minute and let the page load
time.sleep(3)Get the web page source code: what you get here is the complete data of the page loaded with dynamic data
html = browser.page_source
Page turning function: find the next tab and click
# Page code. When using this code page, you must be able to see the label on the next page, or you will be prompted error: Message: element click intercepted
next_page = browser.find_element_by_xpath("//div/a[text() = 'next page'] ")
next_page.click()Close browser after running:
# Exit the current page and close the browser browser.close() browser.quit()
2.2 test page turning - Taking Beijing Xinfadi vegetable price as an example
Take the vegetable price of Xinfadi farmers' market in Beijing as an example to test the page turning function
from selenium import webdriver
from lxml import etree
import time
edge_driver_path = r"...\msedgedriver.exe"
browser = webdriver.Edge(executable_path=edge_driver_path)
# Get the official tmall store of jd.com
browser.get(url=r'http://www.xinfadi.com.cn/marketanalysis/0/list/1.shtml')
# Perform the operation at the lower end of the drop-down slider value browser
browser.execute_script('window.scrollTo(0, document.body.scrollHeight);')
# Wait a minute and let the page load
time.sleep(3)
# Get web page text
html = browser.page_source
el = etree.HTML(html)
page_count = 10
for page in range(1, page_count):
print('Start flipping')
# Page code. When using this code page, you must be able to see the label on the next page, or you will be prompted error: Message: element click intercepted
next_page = browser.find_element_by_xpath("//div/a[text() = 'next page'] ")
next_page.click()
# Perform the operation at the lower end of the drop-down slider value browser
browser.execute_script('window.scrollTo(0, document.body.scrollHeight);')
# Wait 3 seconds until the web page is loaded
time.sleep(3)
# Exit the current page and close the browser
browser.close()
browser.quit()2.3 other cases
2.3.1. JD's case
Automatically open JD, type the iPhone x keyword in the search box, complete the search, slide to the bottom of the page, and then close the browser

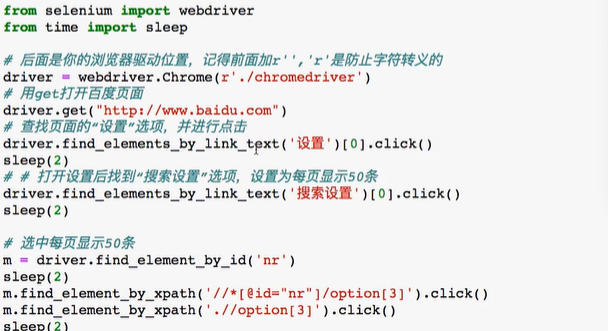
2.3.2 Baidu search case
Baidu sets preferences, searches with beauty keywords, and opens the first picture

2.3.3 case of food and Drug Administration
Data query page: State Drug Administration -- data query (nmpa.gov.cn)
Cosmetics production filing enterprise: Cosmetics production license information management system service platform (nmpa.gov.cn)
This case only obtains the name data of the production enterprise and captures the dynamically loaded data

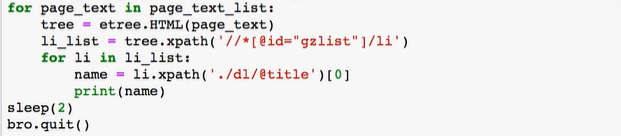
3. Action chains
Action chain refers to a series of continuous actions
Guide Package:

Test:

Note: switch_to, the iframe id is filled in
4. Avoid detection
Some websites will detect whether the request is initiated by selenium. If so, it will be judged as failure; The solution is to use browser hosting.
- The directory where the browser driver is installed on the computer must be found and added to the environment variable
- Open cmd and enter the following command:
chromedriver.exe --remote-debugging-port=9222 --user-data-dir="Any empty directory"
- Write the following python code to take over the real browser opened in step 2
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress","127.0.0.1:9222")
hrome_driver = "Your driver address"
driver = webdriver.chrome(chrome_driver, chrome_options=chrome_options)
print(driver.title)5 headless browser
That is, there is no visual browser interface during operation; The commonly used headless browser is Google browser
5.1 EDGE version
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
#Create browser objects
edge_driver_path = r"...\msedgedriver.exe"
EDGE = {
"browserName": "MicrosoftEdge",
"version": "",
"platform": "WINDOWS",
# The key is the following
"ms:edgeOptions": {
'extensions': [],
'args': [
'--headless',
'--disable-gpu',
'--remote-debugging-port=9222',
'window-size=1920x1080'
]}
}
browser = webdriver.Edge(executable_path=edge_driver_path,capabilities=EDGE)
#surf the internet
url ='https://www.baidu.com/'
browser.get (url)
time.sleep(3)
#screenshot
browser.save_screenshot("baidu.png")
print(browser.page_source)
browser.quit()5.2 Chrome version
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
#Create a parameter object to control chrome to open in no interface mode
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(executable_path='Google driver path',chrome_options=chrome_options)
#surf the internet
url ='https://www.baidu.com/'
browser.get (url)
time.sleep(3)
#screenshot
browser.save_screenshot("baidu.png")
print(browser.page_source)
browser.quit()
Summary of common parameters:
chrome_options.add_argument('--headless') #The browser does not provide visual pages That is, it is specified as headless mode. If the system does not support visualization under linux, it will fail to start
chrome_options.add_argument('--disable-gpu') #Google Docs mentioned the need to add this attribute to avoid bug s
chrome_options.add_argument('--no-sandbox')#Resolve the error message that the devtoolsactivport file does not exist
chrome_options.add_argument('window-size=1920x1080') #Specify browser resolution
chrome_options.add_argument("--proxy-server=http://119.117.24.185:8943 ") # agent
chrome_options.add_argument('--hide-scrollbars') #Hide the scroll bar to deal with some special pages
chrome_options.add_argument('blink-settings=imagesEnabled=false') #Don't load pictures, increase speed
chrome_options.add_argument('–start-maximized') #Browser maximization
chrome_options.add_argument('–user-agent=""') # Set the user agent of the request header
chrome_options.add_argument('–disable-infobars') # Disable the prompt that the browser is being controlled by an automation program
chrome_options.add_argument('–incognito') # Stealth mode (traceless mode)
chrome_options.add_argument('–disable-javascript') # Disable javascript
chrome_options.add_argument('–ignore-certificate-errors') # Disable extensions and maximize windows
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])# Simulate a real browser
More exciting, welcome to focus on the official account of logistics optimization and geographic information.
Python crawler uses xpath('string(.) ') Extract nested text at once