(I) analysis page
Download the sales data for this link below
https://item.jd.com/6733026.html#comment
1. When turning the page, the Network tab of Google F12 can see the following request.

It can be seen from the Preview tab that this request is to obtain comment information

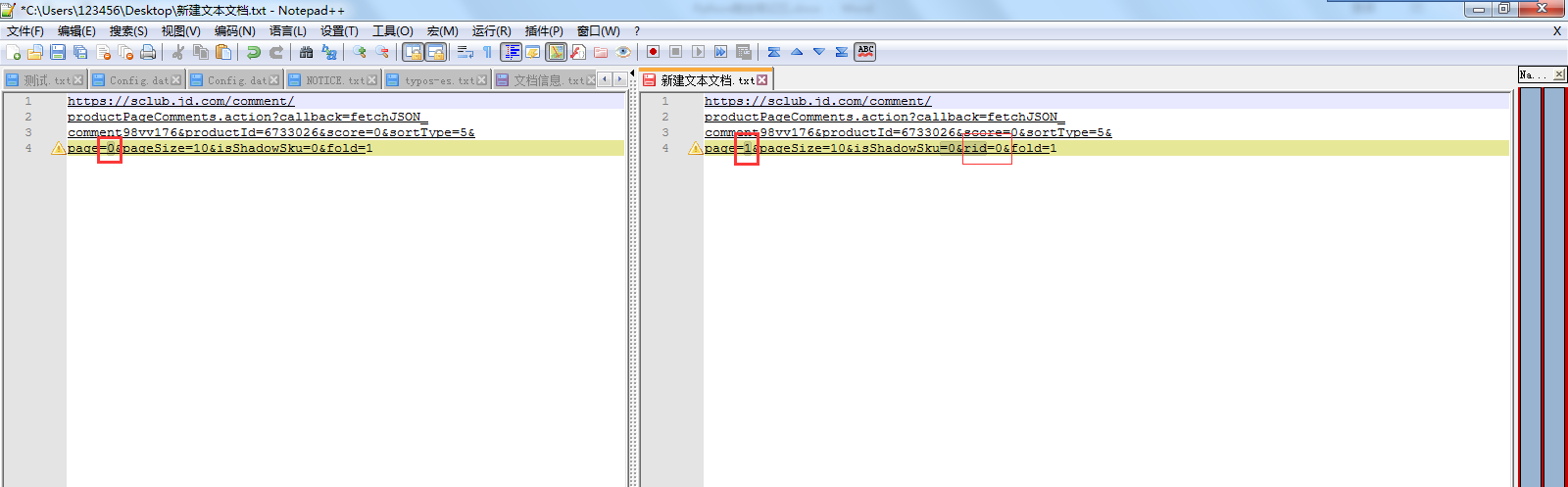
2. Compare the first page, the second page, the third page Differences in request URL s
It can be found that page=0, page=1, 0 and 1 refer to the number of pages.
request url on the first page: no rid = 0 &. Page two, three request url of: add this rid = 0&
Except for the above two places, the other contents are the same.
3. Input the copied request url directly in the browser, and you can see the comments, colors, versions, and memory information. The code will write regular expressions based on these information to match.

(2) Implementation code
The code of delayed.py is the same as that I posted earlier( Python web crawler notes (2) )Delete the code related to this module if there is no speed limit
1 import urllib.request as ure 2 import urllib.parse 3 import openpyxl 4 import re 5 import os 6 from delayed import WaitFor 7 def download(url,user_agent='FireDrich',num=2,proxy=None): 8 print('download:'+url) 9 #Set up user agent 10 headers = {'user_agent':user_agent} 11 request = ure.Request(url,headers=headers) 12 #Support agent 13 opener = ure.build_opener() 14 if proxy: 15 proxy_params = {urllib.parse.urlparse(url).scheme: proxy} 16 opener.add_handler(ure.ProxyHandler(proxy_params)) 17 try: 18 #Download webpage 19 # html = ure.urlopen(request).read() 20 html = opener.open(request).read() 21 except ure.URLError as e: 22 print('Download failed'+e.reason) 23 html=None 24 if num>0: 25 #Encounter 5 XX In case of an error, recursively call itself to retry the download, and repeat at most twice 26 if hasattr(e,'code') and 500<=e.code<600: 27 return download(url,num=num-1) 28 return html 29 def writeXls(sale_list): 30 #If Excel No, create Excel,Otherwise, open the existing document directly 31 if 'P20 Sales situation.xlsx' not in os.listdir(): 32 wb =openpyxl.Workbook() 33 else: 34 wb =openpyxl.load_workbook('P20 Sales situation.xlsx') 35 sheet = wb['Sheet'] 36 sheet['A1'] = 'colour' 37 sheet['B1'] = 'Edition' 38 sheet['C1'] = 'Memory' 39 sheet['D1'] = 'comment' 40 sheet['E1'] = 'Commentary time' 41 x = 2 42 #Iterate all sales information (list) 43 for s in sale_list: 44 #Get color and other information 45 content = s[0] 46 creationTime = s[1] 47 productColor = s[2] 48 productSize = s[3] 49 saleValue = s[4] 50 # Add information such as color to Excel 51 sheet['A' + str(x)] = productColor 52 sheet['B' + str(x)] = productSize 53 sheet['C' + str(x)] = saleValue 54 sheet['D' + str(x)] = content 55 sheet['E' + str(x)] = creationTime 56 x += 1 57 wb.save('P20 Sales situation.xlsx') 58 59 page = 0 60 allSale =[] 61 waitFor = WaitFor(2) 62 #Precompiled regular expressions matching color, version, memory and other information 63 regex = re.compile('"content":"(.*?)","creationTime":"(.*?)".*?"productColor":"(.*?)","productSize":"(.*?)".*?"saleValue":"(.*?)"') 64 #Only 20 pages of data can be downloaded here, which can be set to be larger (even if there is no comment information, some tag information can also be downloaded, so you can if If the rules don't match, the loop will end. Of course, we don't deal with this below.) 65 while page<20: 66 if page==0: 67 url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv176&productId=6733026&score=0&sortType=5&page=' + str(page) + '&pageSize=10&isShadowSku=0&fold=1' 68 else: 69 url = 'https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv176&productId=6733026&score=0&sortType=5&page=' + str(page) + '&pageSize=10&isShadowSku=0&rid=0&fold=1' 70 waitFor.wait(url) 71 html = download(url) 72 html = html.decode('GBK') 73 #Returns color, version, memory and other information in the form of a list 74 sale = regex.findall(html) 75 #Add color, version, memory and other information to allSale Medium (extension) allSale List) 76 allSale.extend(sale) 77 page += 1 78 79 writeXls(allSale)
(3) Data analysis
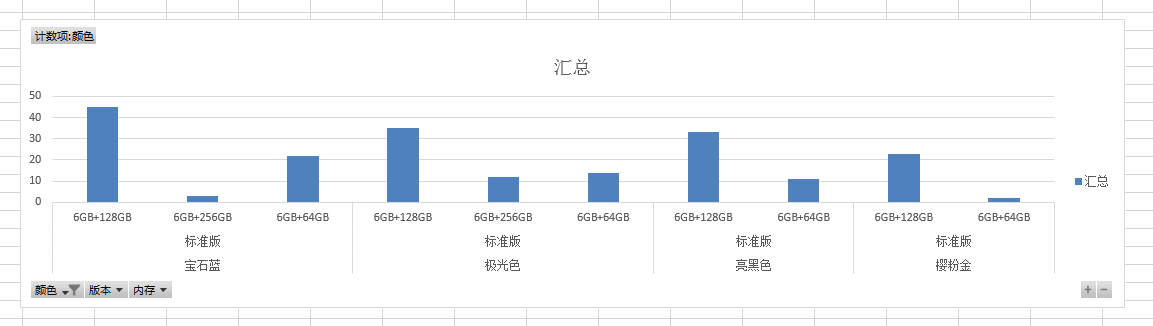
1. The downloaded data is shown in the figure below.

2. Generate a chart.