I'm sure we often have stories we want to read, but they can't be downloaded, so we can't watch them without the Internet.Here's how to crawl online fiction with python3.
This article is mainly for learning, I hope you can support genuine.
First we need two packages, requests and beautifulsoup4
We just need to run the cmd command separately
pip install requests
pip install beautifulsoup4
It's ready to install. After installing, we'll go to the novel website to find the url. I'm looking for the pride of potatoes. The website is as follows: https://www.hehuamei.com//1/1138/975876.html
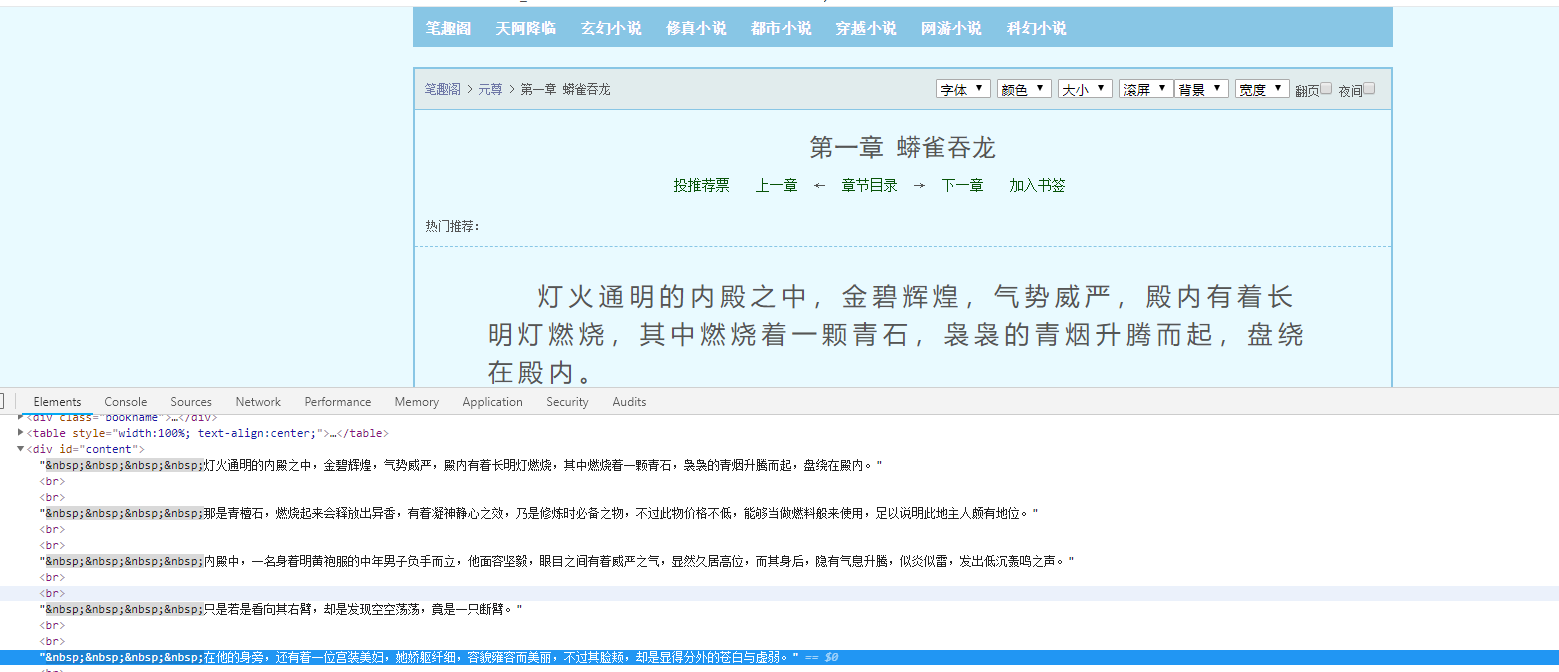
When we open element review in the web address and hover the mouse over the corresponding html element, it will automatically locate the corresponding location. We find the element location of the body:
Next we can write the code:
First we need to get the html code for the whole page, and then we can parse what we want from it:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'https://www.hehuamei.com//1/1138/975876.html'
req = requests.get(url=target)
print(req.text)
The results are as follows: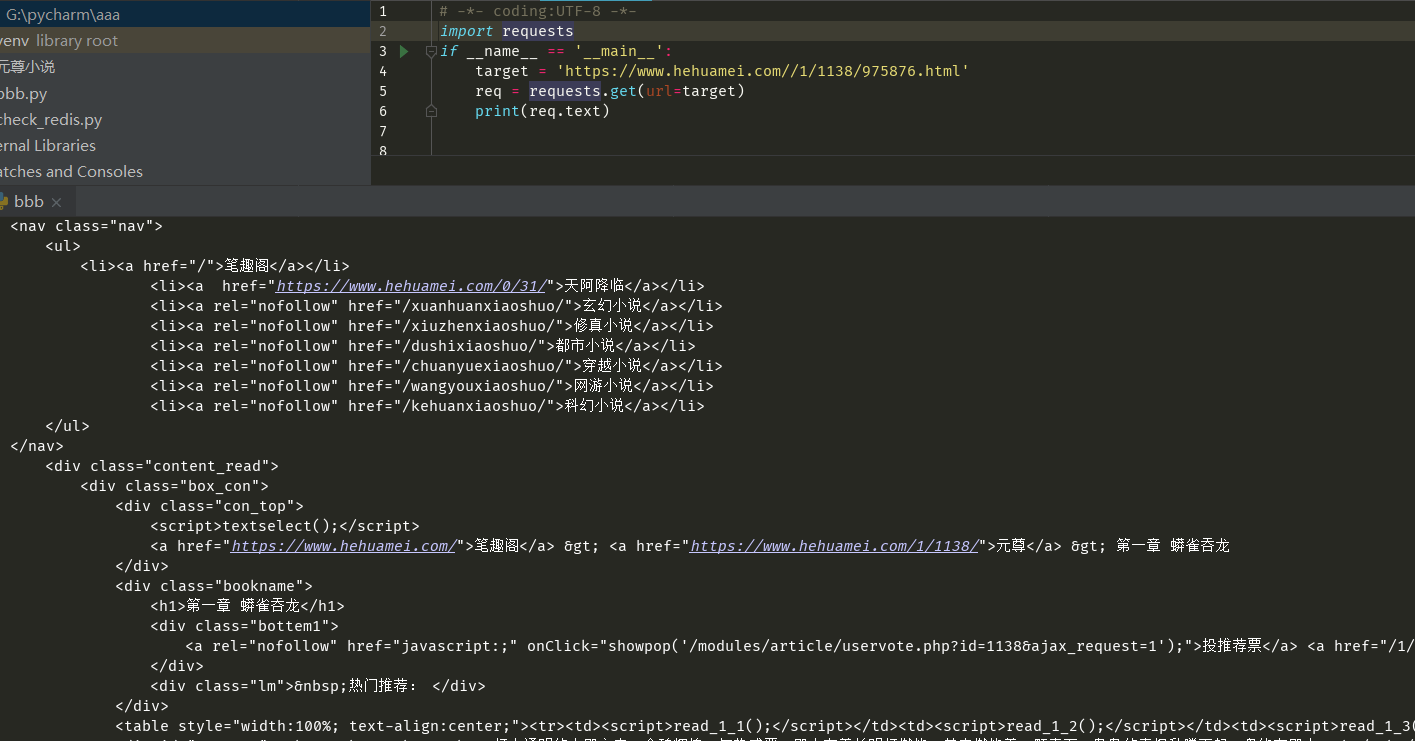
Next we'll parse what we get, we can find the html elements of the corresponding body, you can see that the red circle is the body we want:
So let's modify the original code so that "\xa0" in the code represents spaces. As you can see from the figure above, there are many places in the body, so we change the four-time spaces to new lines:
# -*- coding:UTF-8 -*-
import requests
from bs4 import BeautifulSoup
if __name__ == '__main__':
target = 'https://www.hehuamei.com/1/1138/'
req = requests.get(url=target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', id='content') #Used to parse the resulting html, leaving only the part with id content
print(texts[0].text.replace('\xa0' * 4, '\n\n')) #We only got one long line of article, so we changed the space to newline
Run as follows: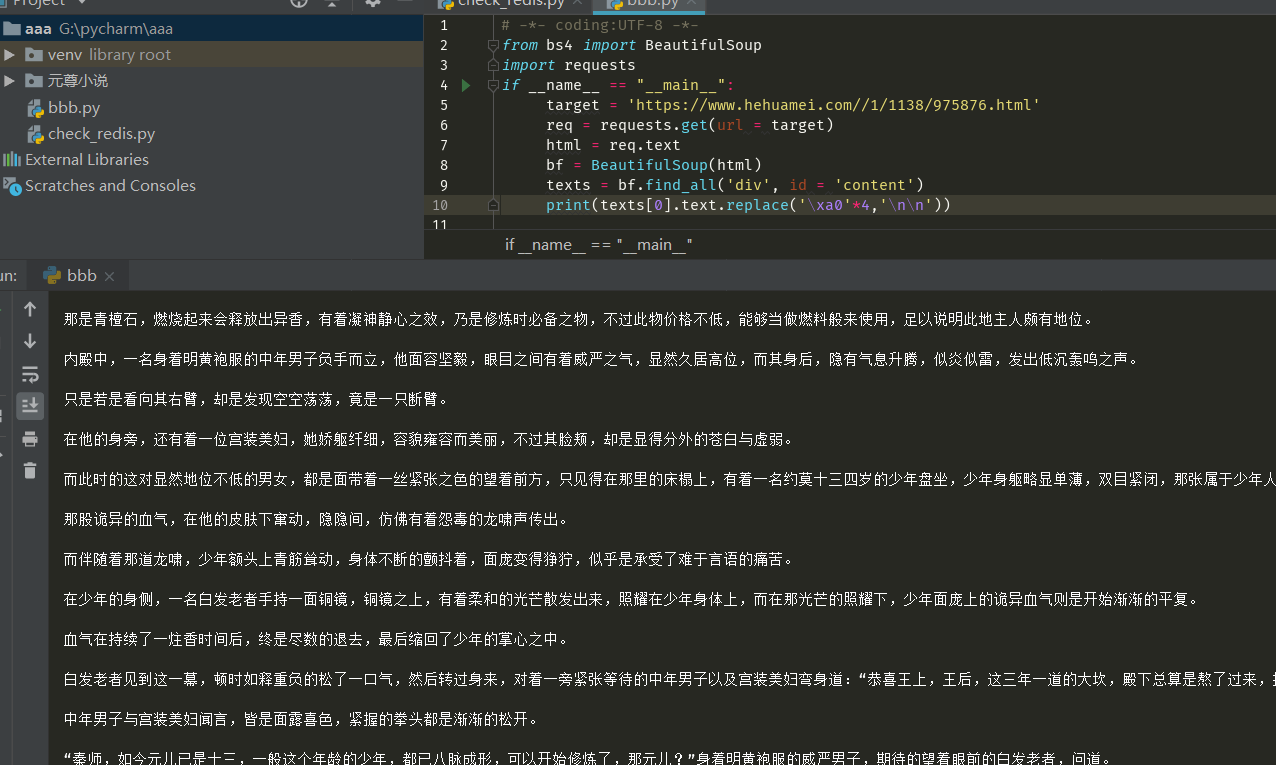
When we get one chapter, we get all the chapters. All we need to do is get the URL of each chapter, because the URLs of these chapters are the same before each other, so we can write them out easily, with server + index.get('href') as the address of the chapter and index.string as the chapter name;
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
server = 'https://www.hehuamei.com/'#Web site for Fiction
target = 'https://www.hehuamei.com/1/1138/'#Web address for the meta-esteem novel catalogue
req = requests.get(url=target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div', id='list') #Parse the directory to get all the elements in the directory with the id list
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a') #The html you get is a hyperlink label, so remove'a'
for each in a:
print(each.string, server + each.get('href'))
Code performance: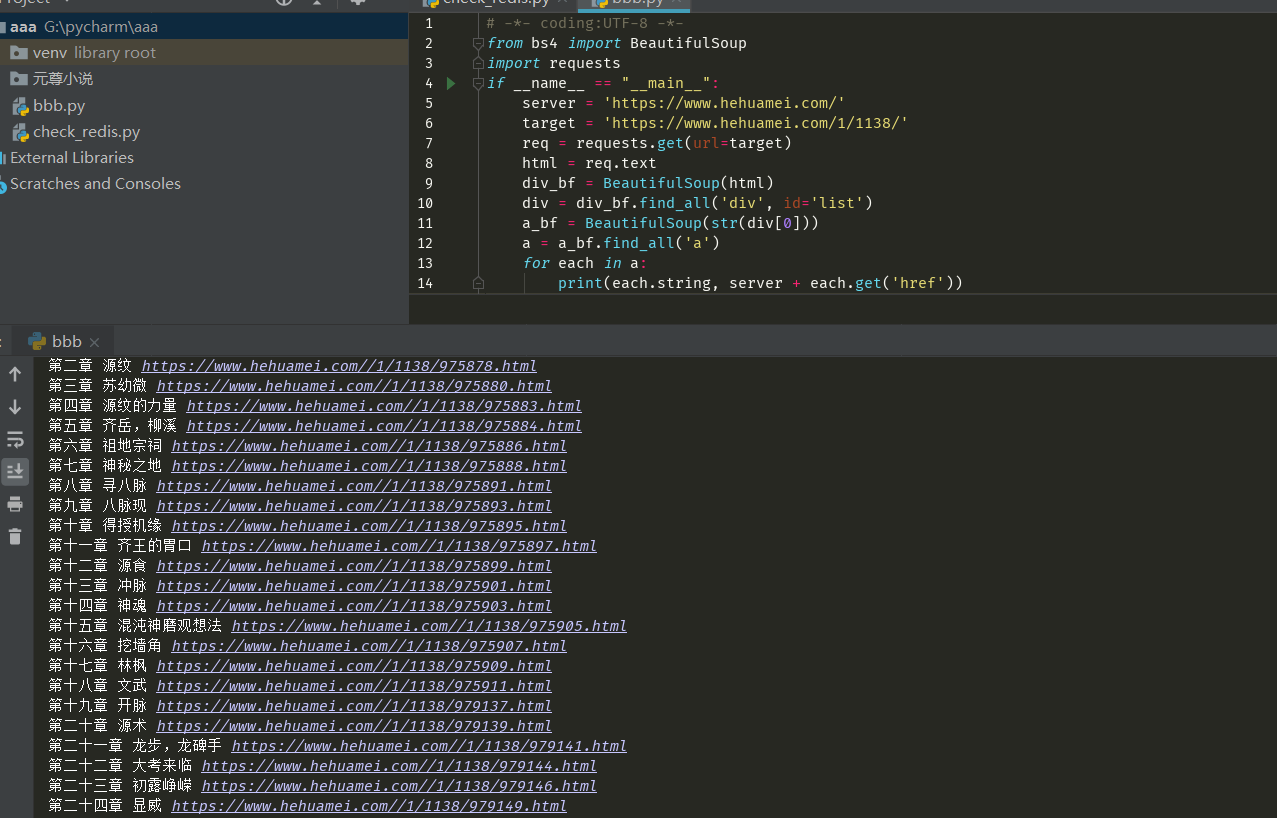
Next, we'll just send the above two codes into two functions.
The main function creates a folder and calls the code to get the chapter and chapter websites (that is, the third code above)
When the code to get the chapter enters the loop, call the code to get the body and pass the chapter and the address of the corresponding chapter to him
Combine the code;
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
import os ,sys
def one(a,b):
target = a
req = requests.get(url=target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', id='content')
os.getcwd()
os.chdir(r'G:\pycharm\aaa\Novels of Yuan Zun')
fobj = open(b+".txt", 'a',encoding='utf-8')
text=texts[0].text.replace('\xa0' * 4, '\n\n')
fobj.write(text)
def two():
server = 'https://www.hehuamei.com/'
target = 'https://www.hehuamei.com/1/1138/'
req = requests.get(url=target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div', id='list')
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a')
for each in a:
#print(each.string, server + each.get('href'))
one(server + each.get('href'),each.string)
if __name__ == "__main__":
path="Novels of Yuan Zun"
os.mkdir(path)
print("Directory created")
two()
Especially simple, if we run, we can find the corresponding files in the project directory, a little more, so the running time will be a little longer: