Mainly refer to the Wz video of up thunderbolt bar at station b. thank you for your extremely detailed and friendly sharing with Xiaobai.
GoogLeNet knowledge point video
Code implementation video
The code comes from the open source project of Github warehouse of up master, and the infringement is deleted.
1. Network analysis
1.1 network highlights

1.2 Inception structure
This is the improved concept module, which introduces 1 compared with that before the improvement × 1 convolution kernel to reduce the dimension, so as to reduce the parameters of the network.
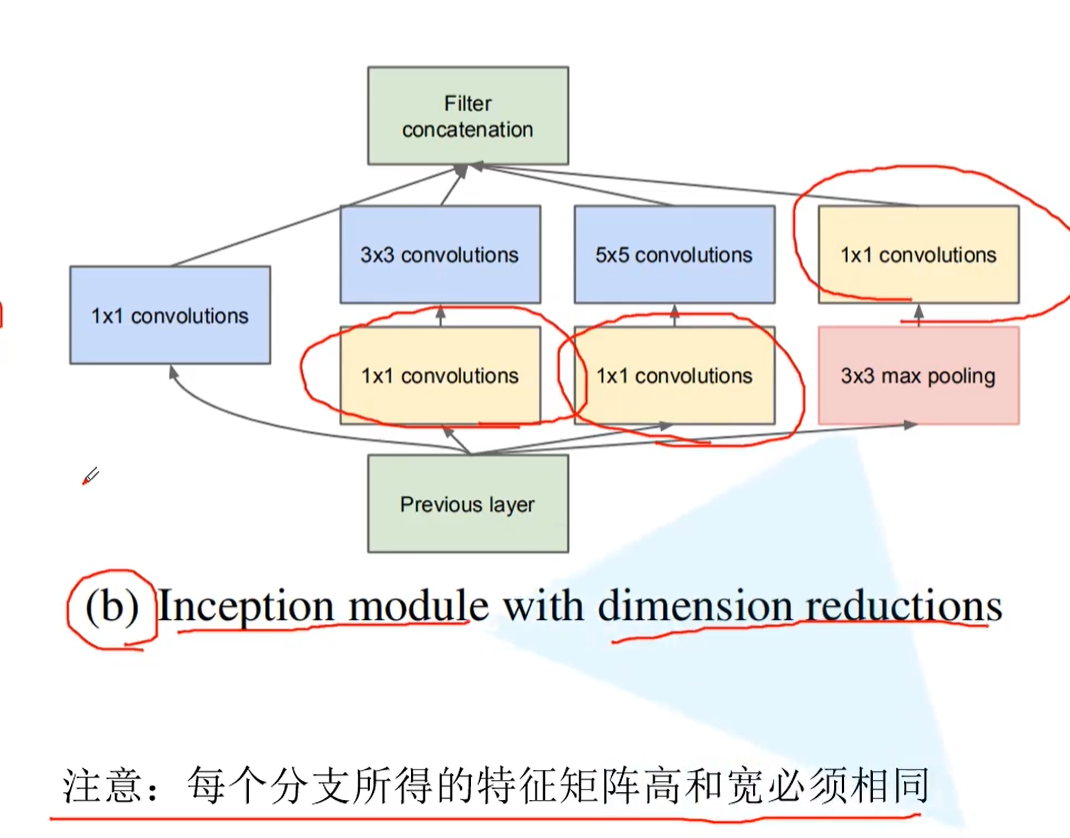
After the feature map is input, it passes through 4 branches.
Branch 1: direct 1 × 1) convolution dimensionality reduction;
Branch 2: first line 1 × 1 convolution dimensionality reduction, and then through 3 × 3 convolution extraction feature map;
Branch 3: first line 1 × 1 convolution dimensionality reduction, and then through 5 × 5. Convolution feature extraction;
Branch 4: pass through 3 first × 3. Maximize the pool layer, and then 1 × 1 convolution dimensionality reduction.
When four branches are output, they are spliced in the channels dimension to improve the channels of the output feature map and enrich the features. This requires that the length and width of the output feature map are the same, which needs to be filled by padding.
About introduction 1 × 1. Convolution dimension reduction:

1.3 auxiliary classifier
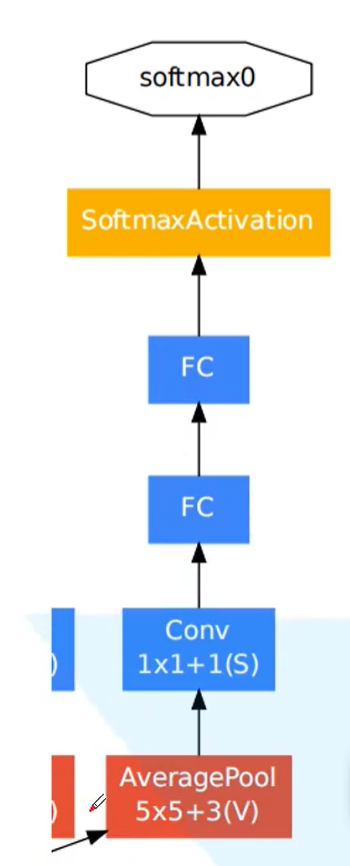
Considering that the gradient may disappear with the deepening of the network, and the low-dimensional features extracted by the low-dimensional network also have certain value, the low-dimensional features are introduced and output through an auxiliary classifier. When training the network, the loss function of the auxiliary classifier is weighted and summed with the final network loss function.
However, it should be noted that the auxiliary classifier is only used in training and will be discarded when using the trained network.
2. Network construction
2.1 convolution module
Because the convolution layer is always followed by the activation layer, the two are integrated.
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
2.2 Inception module
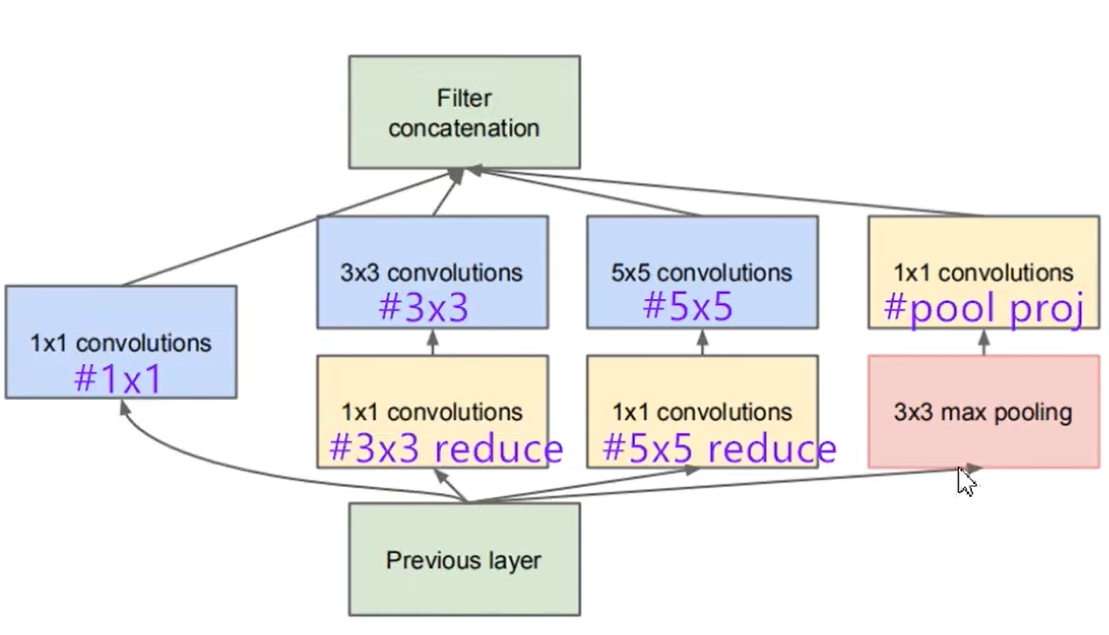
The parameters to be determined by the Inception module are:
1. Channels of input image (in_channels);
2. Branch 1 × 1 the number of convolution kernels (ch1x1), which determines the channels of branch one output
3. Branch II 1 × 1 the number of convolution kernels (ch3x3red), which determines the channels output after branch 2 dimensionality reduction, 3 × The number of convolution kernels (ch3x3), which determines the final output channels of branch 2
4. Branch III 1 × 1 the number of convolution kernels (ch5x5red), which determines the channels output after dimension reduction of branch 3, 5 × The number of convolution kernels (ch5x5), which determines the final output channels of branch 2
5. Branch IV 1 × 1 the number of convolution kernels (pool_proj), which determines the final output channels after dimension reduction of branch four
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # Ensure that the output size is equal to the input size
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # Ensure that the output size is equal to the input size
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
torch.cat is to splice two tensor s together. cat means concatenate, that is, splicing and connecting together.
Use torch Cat ((a, b), dim), except that the splicing dimension dim value can be different, the other dimension values must be the same before alignment. dim = 1 is channels, whose 0 dimension (batch), 2 and 3 dimensions (image size) are equal.
2.3 auxiliary classifier module
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output[batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = self.averagePool(x)
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
x = F.dropout(x, 0.5, training=self.training)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x

2.4 whole network module
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits: # eval model lose this layer
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits: # eval model lose this layer
return x, aux2, aux1
return x
nn. Adaptive avgpool2d can adaptively adjust the size and step size of the pool by setting the output size.
nn. Adaptive avgpool2d ((1, 1)) indicates that the output image size becomes 1 × 1.
3. Network training
import os
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import torch.optim as optim
from tqdm import tqdm
from model import GoogLeNet
def main():
#device = "cpu"
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "dataSet", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 16
nw = 0
#nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
net = GoogLeNet(num_classes=5, aux_logits=True, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0003)
epochs = 30
best_acc = 0.0
save_path = './googleNet.pth'
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
logits, aux_logits2, aux_logits1 = net(images.to(device))
loss0 = loss_function(logits, labels.to(device))
loss1 = loss_function(aux_logits1, labels.to(device))
loss2 = loss_function(aux_logits2, labels.to(device))
loss = loss0 + loss1 * 0.3 + loss2 * 0.3
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device)) # eval model only have last output layer
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
Notes:
1. The setting of loss function during training is the weighted sum of the loss of network output and the loss of auxiliary classifier;
logits, aux_logits2, aux_logits1 = net(images.to(device)) loss0 = loss_function(logits, labels.to(device)) loss1 = loss_function(aux_logits1, labels.to(device)) loss2 = loss_function(aux_logits2, labels.to(device)) loss = loss0 + loss1 * 0.3 + loss2 * 0.3
2. When calculating the accuracy, because net is used Eval () so the network only outputs the results at the end of the network for classification.
4. Test documents
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import GoogLeNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img_path = "2.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# create model
model = GoogLeNet(num_classes=5, aux_logits=False).to(device)
# load model weights
weights_path = "./googleNet.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
missing_keys, unexpected_keys = model.load_state_dict(torch.load(weights_path, map_location=device),
strict=False)
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
print(print_res)
plt.show()
if __name__ == '__main__':
main()
Notes:
1. When loading the trained model parameters, the parameter strict=False indicates a non strict match, because the trained model also has parameters of the auxiliary classification layer, which are not required by the model we use to classify. By unexpected_keys can know the lost parameters.
missing_keys, unexpected_keys = model.load_state_dict( torch.load(weights_path, map_location=device),strict=False)
Loss parameters in pychar:

Except for the contents of supplementary instructions, there is no difference between the training documents and test documents and the previous network.