1, Data preprocessing transforms module mechanism
torchvision. The transforms module contains many image preprocessing methods:
- Data centralization
- Data standardization
- zoom
- Cutting
- rotate
- Flip
- fill
- Noise addition
- Gray transformation
- linear transformation
- affine transformation
- Brightness, saturation and contrast transformation
This module can perform data enhancement and data preprocessing to enhance the generalization ability of the model. In the process of data reading, data preprocessing transforms finally generates batch data after data preprocessing.
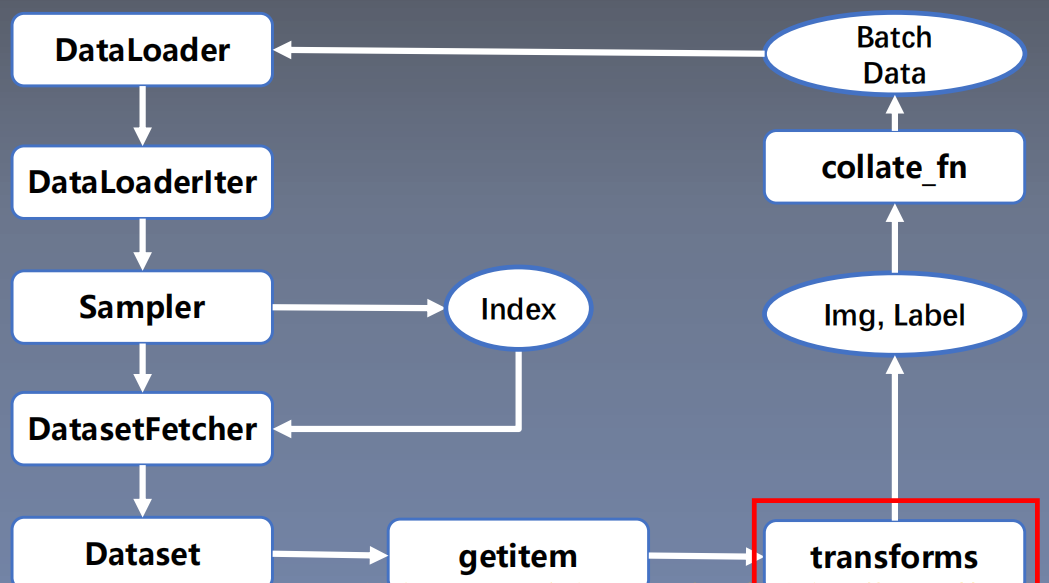
class RMBDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
rmb Denomination classification task Dataset
:param data_dir: str, Path of dataset
:param transform: torch.transform,Data preprocessing
"""
self.label_name = {"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info stores all picture paths and labels, and reads samples through index in DataLoader
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
# The transform is called at the node where the data is read, and multiple tansform methods are used iteratively
if self.transform is not None:
img = self.transform(img) # Do transform here, turn it into tensor, etc
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# Traversal category
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# Traversal picture
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
2, Twenty two data preprocessing methods for transforms
2. Cutting
transforms.CenterCrop
Function: crop picture from image center
- Size: the size of the picture to be cropped
transforms.RandomCrop
transforms.RandomCrop(size, padding=None, pad_if_needed=False,fill=6, padding_mode= 'constant ' )
Function: randomly cut out the picture with size from the picture
- Size: the size of the picture to be cropped
- Padding: set padding size
When it is a, a pixel is filled up, down, left and right
When (a, b), fill B pixels up and down and a pixels left and right
When it is (a, b, c, d), the left, upper, right and lower are filled with a, b, c and D respectively - pad_if_need: if the image is smaller than the set size, it will be filled
- padding_mode: filling mode. There are four modes
1. constant: the pixel value is set by filI
2. Edge: the pixel value is determined by the image edge pixels
3. reflect: Mirror filling, the last pixel is not mirrored, eg:[1,2,3.4] → [3,2,1,2,3,4,3,2]
4. symmetric: Mirror filling, the last pixel is mirrored, eg:[1,2,3,4] → [2,1,1,2,3,4,3] - fill: constant, sets the pixel value of the fill
transforms.RandomResizedCrop
RandomResizedCrop(size, scale=(0.08,1.0), ratio=(3/4,4/3),interpolation)
Function: crop pictures with random size and aspect ratio
- Size: the size of the picture to be cropped
- Scale: random clipping area scale, default (0.08, 1)
- Ratio: random aspect ratio, default (3 / 4, 4 / 3)
- Interpolation: interpolation method
PIL.lmage.NEAREST
PIL.lmage.BILINEAR
PIL.lmage.BICUBIC
transforms.FiveCrop
transforms .FiveCrop(size)
Function: cut out 5 pictures of size in the top, bottom, left, right and center of the image
# Convert tuple format to Tensor format transforms.FiveCrop(112), transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops]))
transforms.TenCrop
Function: tenprop horizontally or vertically mirrors these 5 pictures to obtain 10 pictures
- Size: the size of the picture to be cropped
- vertical_flip: flip vertically
transforms.TenCrop(112, vertical_flip=False), transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops]))
3. Turnover and rotation
transforms.RandomHorizontalFlip
transforms.RandomHorizontalFlip(p=0.5)
Function: flip pictures according to probability level (left and right)
- p: Turnover probability
transforms.RandomVerticalFlip
transforms.RandomVerticalFlip(p=0.5)
Function: flip pictures vertically (up and down) according to probability
- p: Turnover probability
transforms.RandomRotation
RandomRotation(degrees, resample=False,expand=False, center=None)
Function: randomly rotate pictures
- degrees: rotation angle
When it is a, select the rotation angle between (- A, a)
When (a,b), select the rotation angle between (a,b) - Resample: resample method
- Expand: whether to expand the picture to keep the original information
4. Image transformation
transforms.Pad
transforms.Pad(padding, fill=0, padding_mode= ' constant ' )
Function: fill the edge of the picture
- Padding: set padding size
When it is a, a pixel is filled up, down, left and right
When (a, b), fill B pixels up and down and a pixels left and right
When it is (a, b, c, d), the left, upper, right and lower are filled with a, b, c and D respectively - padding_mode: filling mode. There are four modes,
constant, edge, reflect, and symmetric - When fill:constant, set the filled pixel value, (R, G,B)or(Gray)
transforms.colorjitter
transforms.colorJitter(brightness=0, contrast=0, saturation=0, hue=0)
Function: adjust brightness, contrast, saturation and hue
- Brightness: brightness adjustment factor
When it is a, select randomly from [max(0, 1-a), 1+a]
When (a, b), select randomly from [a, b] - Contrast: contrast parameter, the same as brightness
- Saturation: saturation parameter, the same as brightness
- Hue: hue parameter,
When it is a, select the parameter from [- A, a],
Note: 0 < = a < = 0.5
When (a, b): select parameters from [a, b]
Note: - 0.5 < = a < = B < = 0.5
transforms.Grayscale
Grayscale(num_output_channels)
Function: convert pictures to grayscale images
- num_ouput_channels: the number of output channels can only be set to 1 or 3
transforms.RandomGrayscale
Function: convert the picture into gray image according to probability
- num_ouput_channels: the number of output channels can only be set to 1 or 3
- p: probability value, the probability that the image is converted into a gray image
transforms.RandomAffine
transforms.RandomAffine(degrees, translate=None,scale=None, shear=None ,resample=False,fillcolor=)
Function: perform affine transformation on the image. Affine transformation is a two-dimensional linear transformation, which is composed of five basic atomic transformations: rotation, translation, scaling, staggered cutting and flipping
- degrees: rotation angle setting
- translate: translation interval setting
For example (a, b), a sets the width, B sets the height, and the translation interval of the image in the wide dimension is
-img_width * a < dx < img_width * a - scale: scale (in area)
- fill_color: fill color settings
- shear: setting of stagger angle, including horizontal stagger and vertical stagger
If it is a, only the x-axis is staggered, and the staggered angle is between (- a, a)
If (a, b), a sets the angle of x axis and B sets the angle of y
If (a, b,c,d), a and B set the x-axis angle, and c and D set the y-axis angle - resample: resampling methods, including NEAREST, BILINEAR and BICUBIC
transforms.RandomErasing
transforms.RandomErasing(p=0.5, scale=(0.02,0.33), ratio=(0.3,3.3),value=0, inplace=False)
Function: random occlusion of images
- p: Probability value, the probability of performing the operation
- scale: area of occluded area
- Ratio: aspect ratio of occluded area
- Value: sets the pixel value of the occlusion area, (R, G, B) or (Gray)
transforms.Lambda(lambd)
Function: user defined lambda method
- Lambd: lambda anonymous function
lambda [arg1 [,arg2, ... , argn]] : expression
eg:
transforms. Lambda(lambda crops: torch.stack([transforms. Totensor()(crop) for crop in crops]))
5. Selection of transforms method
transforms.RandomChoice
Function: randomly select one from a series of transforms methods
transforms. RandomChoice([transforms1,transforms2,transforms3])
transforms.RandomApply
Function: perform a set of transforms operations according to probability
transforms.RandomApply([transforms1,transforms2,transforms3], p=0.5)
transforms.RandomOrder
Function: disorganize a group of transforms operations
transforms. Randomorder([transforms1,transforms2,transforms3])
transforms.Resize
Function: adjust the size of the picture
transforms.Totensor
Function: convert the previous data structure into tensor
transforms.Normalize
transforms.Normalize(mean, std, inplace=False)
Function: standardize the image channel by channel (the transformed data mean is 0 and the standard deviation is 1). The advantage of standardization is to speed up the convergence of the model.
o
u
t
p
u
t
=
(
i
n
p
u
t
−
m
e
a
n
)
/
s
t
d
output = (input - mean) / std
output=(input−mean)/std
- Mean: mean value of each channel
- std: standard deviation of each channel
- inplace: whether to operate in place
The source code is as follows:
def normalize(tensor, mean, std, inplace=False):
"""Normalize a tensor image with mean and standard deviation.
.. note::
This transform acts out of place by default, i.e., it does not mutates the input tensor.
See :class:`~torchvision.transforms.Normalize` for more details.
Args:
tensor (Tensor): Tensor image of size (C, H, W) to be normalized.
mean (sequence): Sequence of means for each channel.
std (sequence): Sequence of standard deviations for each channel.
inplace(bool,optional): Bool to make this operation inplace.
Returns:
Tensor: Normalized Tensor image.
"""
# Legitimacy judgment of input - whether it is Tensor
if not _is_tensor_image(tensor):
raise TypeError('tensor is not a torch image.')
# Whether to operate in situ. If not, clone a tensor
if not inplace:
tensor = tensor.clone()
dtype = tensor.dtype
# The mean and variance are transformed into tensors
mean = torch.as_tensor(mean, dtype=dtype, device=tensor.device)
std = torch.as_tensor(std, dtype=dtype, device=tensor.device)
# sub_: Underline indicates in-situ operation; (input - mean) / std
tensor.sub_(mean[:, None, None]).div_(std[:, None, None])
# Returns the transformed tensor
return tensor
6. Customize transfroms method
the transforms method is passed in the Compose class__ call__ Method called.
class Compose(object):
"""Composes several transforms together.
Args:
transforms (list of ``Transform`` objects): list of transforms to compose.
Example:
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.ToTensor(),
>>> ])
"""
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, img):
# Loop executes the transforms method
for t in self.transforms:
img = t(img)
return img
def __repr__(self):
format_string = self.__class__.__name__ + '('
for t in self.transforms:
format_string += '\n'
format_string += ' {0}'.format(t)
format_string += '\n)'
return format_string
We can find the following characteristics when calling transforms:
- Only one parameter is received and one parameter is returned
- Pay attention to the upstream and downstream outputs and inputs
let's customize transforms. Its basic structure is:
class YourTransforms(object) : def __init_(self, ...): ... def __cal1__(self, img): ... return img
salt and pepper noise, also known as impulse noise, is a random white point or black point. The white point is called salt noise and the black is pepper noise. Signal noise rate (SNR) is a measure of the proportion of noise, which is the proportion of image pixels in the image. We take salt and pepper noise as an example to customize the transforms method.
class AddPepperNoise(object):
"""Increase salt and pepper noise
Args:
snr (float): Signal Noise Rate
p (float): Probability value, which performs the operation according to probability
"""
def __init__(self, snr, p=0.9):
assert isinstance(snr, float) and (isinstance(p, float)) # 2020 07 26 or --> and
# Signal percentage
self.snr = snr
# probability
self.p = p
def __call__(self, img):
"""
Args:
img (PIL Image): PIL Image
Returns:
PIL Image: PIL image.
"""
# Judgment of probability
if random.uniform(0, 1) < self.p:
# Convert data format to ndarray
img_ = np.array(img).copy()
# Height, width, number of channels
h, w, c = img_.shape
# Get signal percentage
signal_pct = self.snr
# Noise percentage
noise_pct = (1 - self.snr)
# Select 3 mask s according to probability
mask = np.random.choice((0, 1, 2), size=(h, w, 1), p=[signal_pct, noise_pct/2., noise_pct/2.])
mask = np.repeat(mask, c, axis=2)
img_[mask == 1] = 255 # Salt noise
img_[mask == 2] = 0 # Pepper noise
return Image.fromarray(img_.astype('uint8')).convert('RGB')
else:
return img
If it is helpful to you, please praise and pay attention, which is really important to me!!! If you need to communicate with each other, please comment or send a private letter!
