1. Neural network: build small actual combat and use Sequential
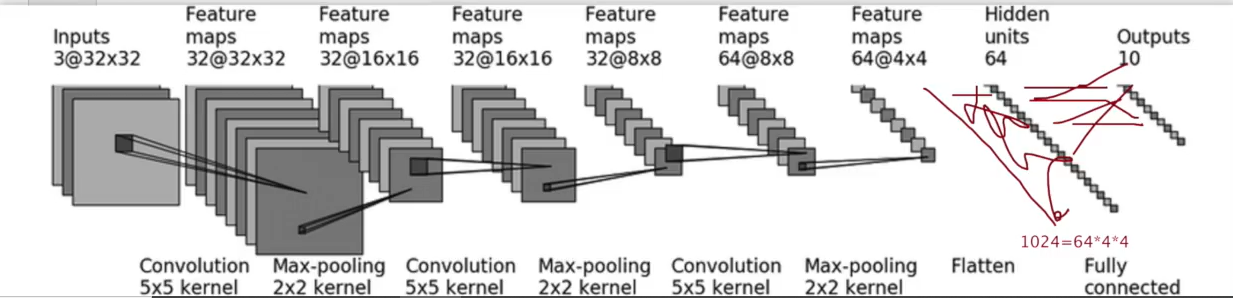
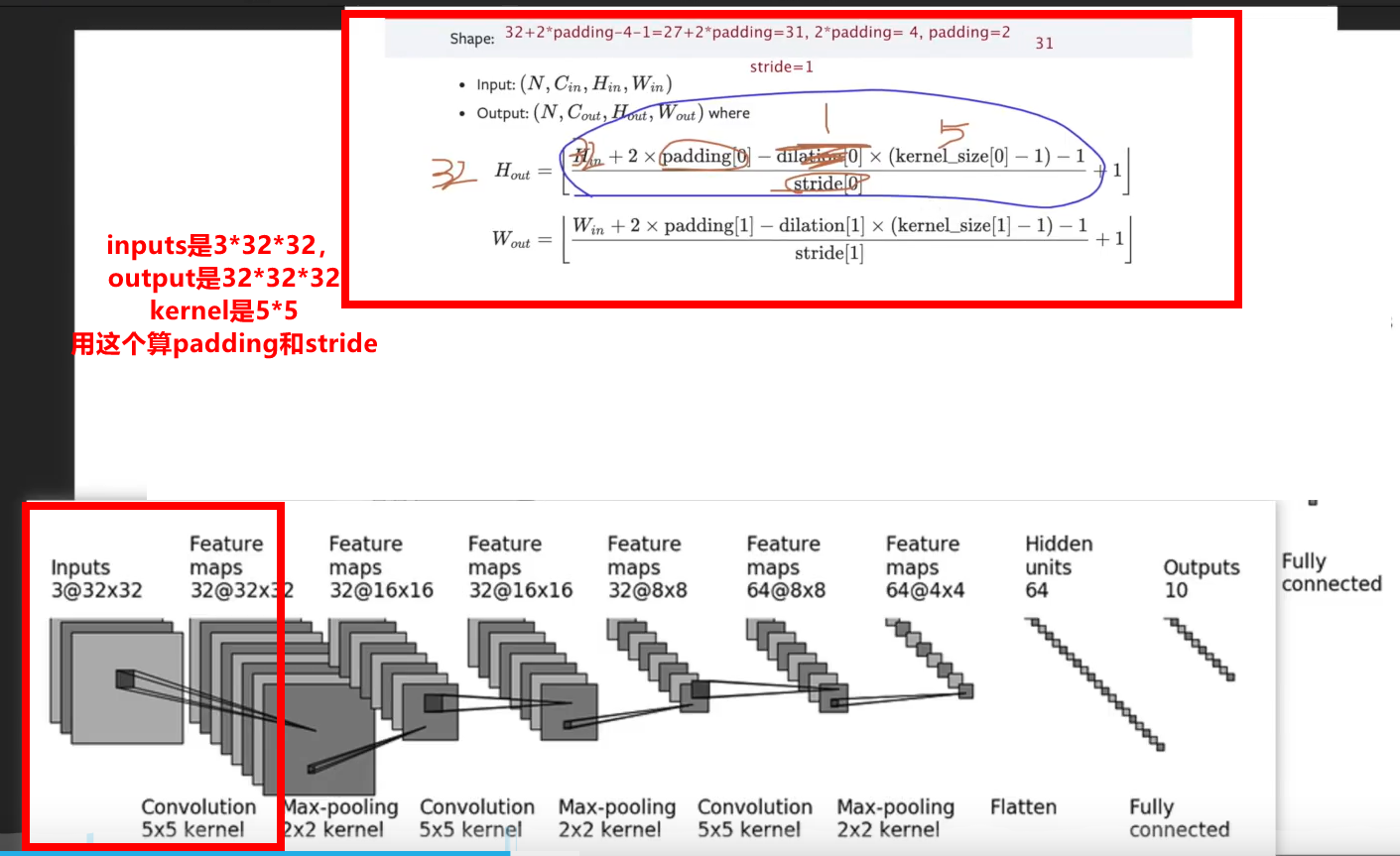
Take CIFAR10 model as an example
import torch
import torchvision
from tensorboardX import SummaryWriter
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten
from torch.utils.data import DataLoader
class test_cifar(nn.Module):
def __init__(self) -> None:
super(test_cifar, self).__init__()
self.conv1 = Conv2d(3, 32, 5, padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32, 32, 5, padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32, 64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(1024, 64)
self.linear2 = Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
test = test_cifar()
print(test)
input = torch.ones((64, 3, 32, 32)) # Generate a test data with all 1
output = test(input)
print(output.shape) # torch.Size([64, 10]) indicates that there should be no problem in network construction
If there is an error in the middle of the network, you can test through this part of the code
test = test_cifar() print(test) input = torch.ones((64, 3, 32, 32)) # Generate a test data with all 1 output = test(input) print(output.shape) # torch.Size([64, 10]) indicates that there should be no problem in network construction
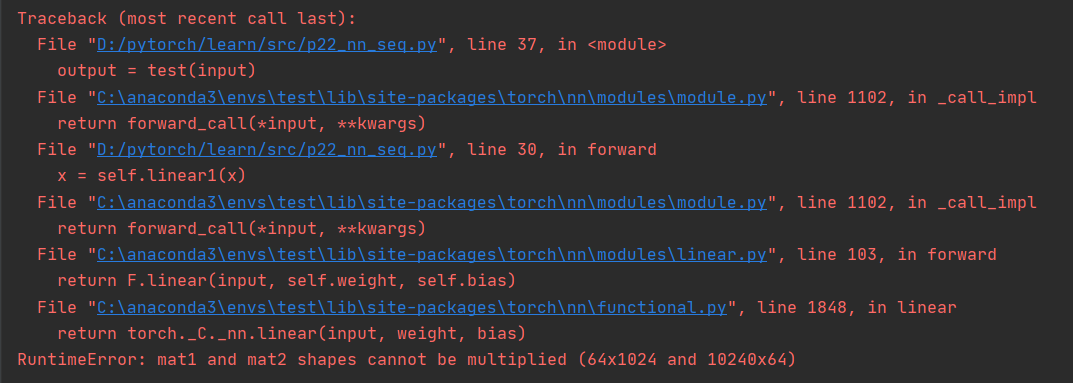
If I put
self. Linear1 = 1024 in linear (1024, 64) is changed to 10240
Then an error will be reported
Change to Sequential code and it will become very concise
import torch
import torchvision
from tensorboardX import SummaryWriter
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten, Sequential
from torch.utils.data import DataLoader
class test_cifar(nn.Module):
def __init__(self) -> None:
super(test_cifar, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
test = test_cifar()
print(test)
input = torch.ones((64, 3, 32, 32)) # Generate a test data with all 1
output = test(input)
print(output.shape) # torch.Size([64, 10]) indicates that there should be no problem in network construction
Display with tensorboardX
(here I report an error!!!!! I don't know why!!!!! Look video (the effect is awesome, solve it)
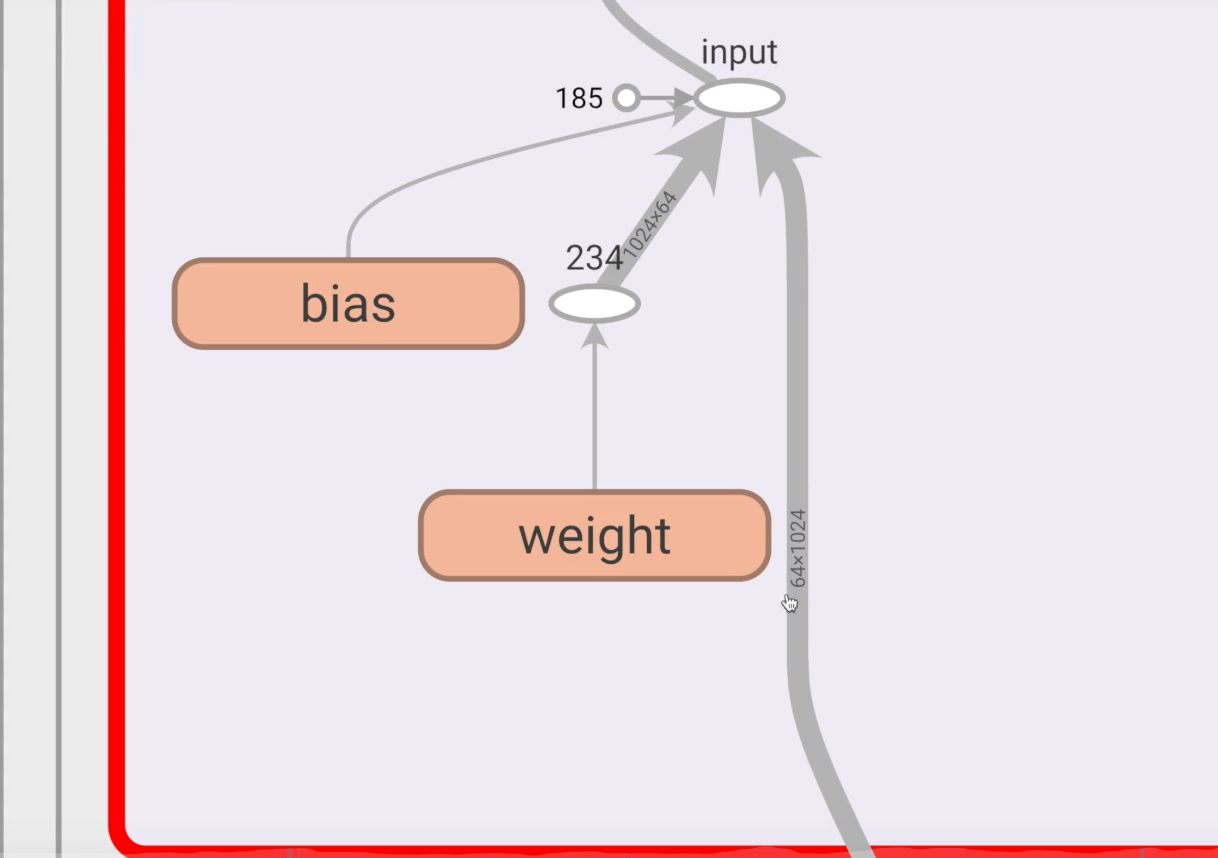
# This code reported an error and did not find the problem
import torch
import torchvision
from tensorboardX import SummaryWriter
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten, Sequential
from torch.utils.data import DataLoader
class test_cifar(nn.Module):
def __init__(self) -> None:
super(test_cifar, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
return x
test_model = test_cifar()
print(test_model)
input = torch.ones((64, 3, 32, 32)) # Generate a test data with all 1
output = test_model(input)
print(output.shape) # torch.Size([64, 10]) indicates that there should be no problem in network construction
writer = SummaryWriter("../logs_seq")
writer.add_graph(test_model, input)
writer.close()
2. Loss function
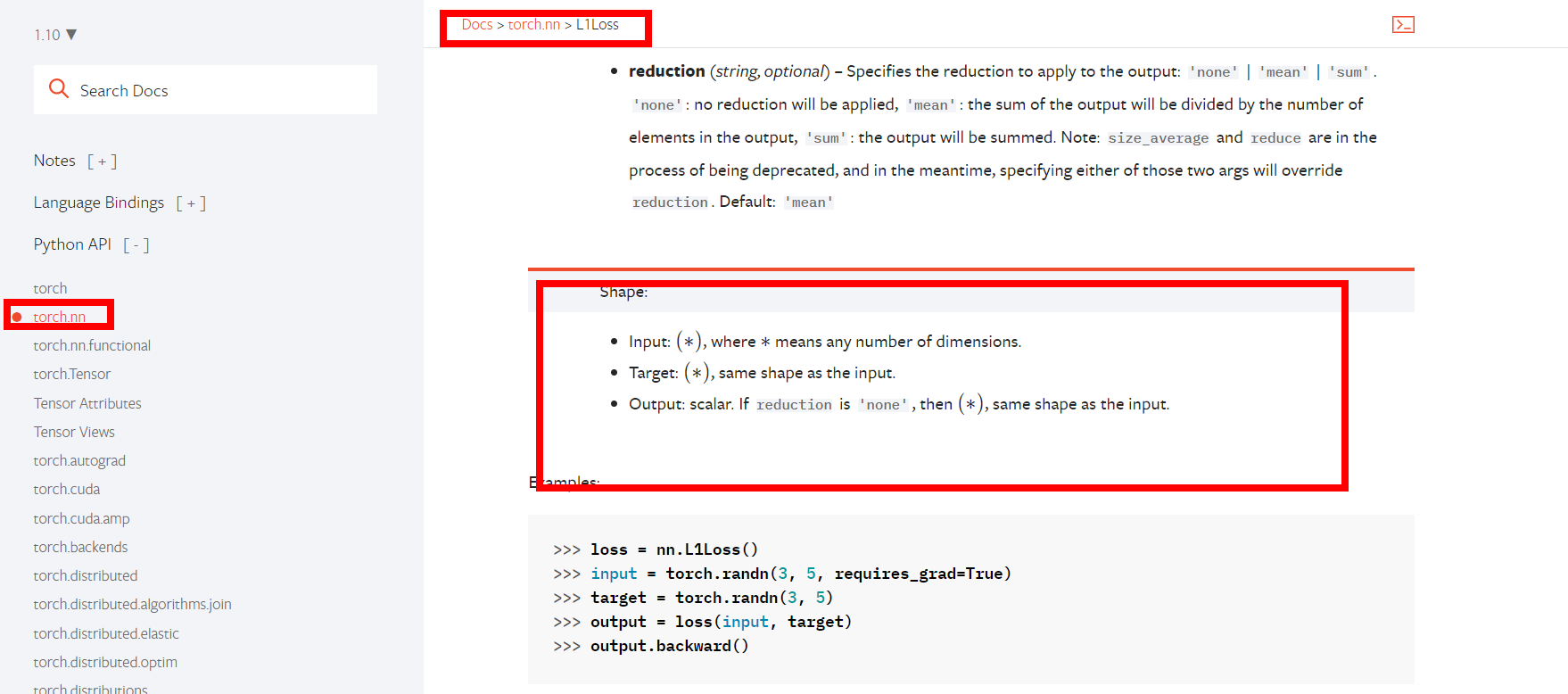
Take L1loss as an example
import torch from torch.nn import L1Loss inputs = torch.tensor([1, 2, 3], dtype=torch.float32) targets = torch.tensor([1, 2, 5], dtype=torch.float32) inputs = torch.reshape(inputs, (1, 1, 1, 3)) targets = torch.reshape(targets, (1, 1, 1, 3)) loss = L1Loss() result = loss(inputs, targets) # tensor(0.6667)
Cross entropy
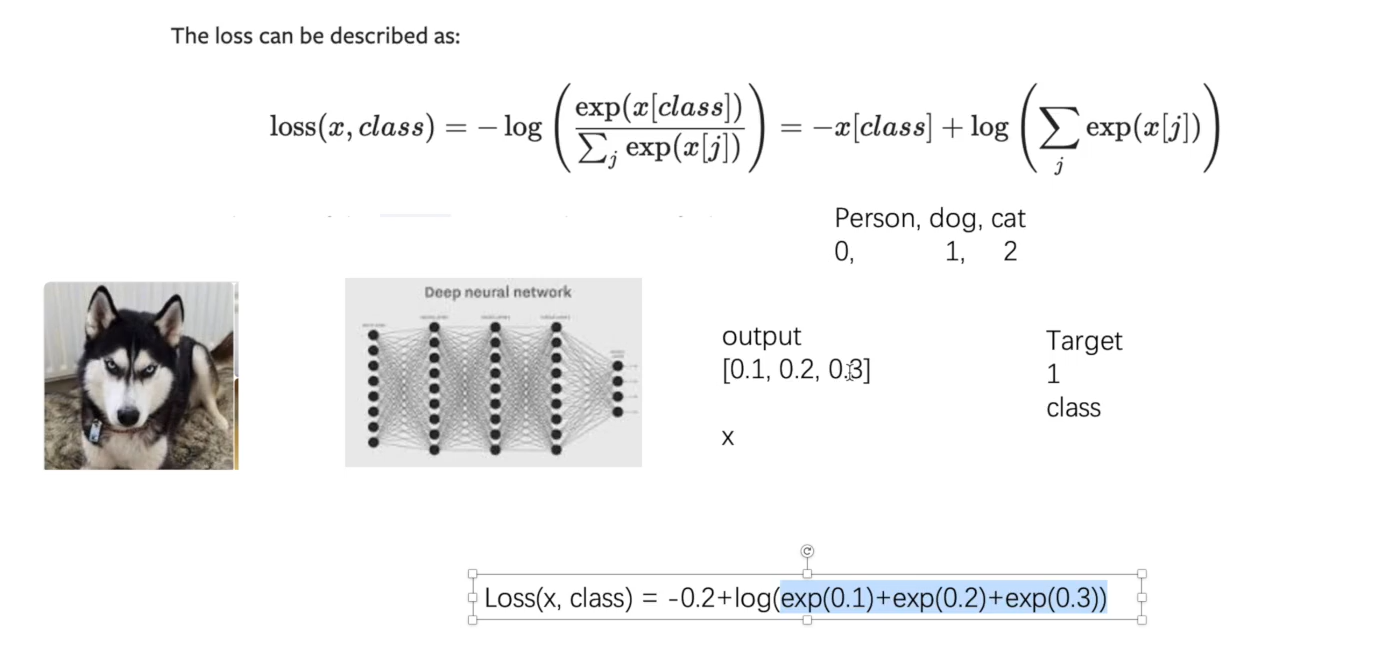
import torch from torch.nn import L1Loss from torch import nn inputs = torch.tensor([1, 2, 3], dtype=torch.float32) targets = torch.tensor([1, 2, 5], dtype=torch.float32) inputs = torch.reshape(inputs, (1, 1, 1, 3)) targets = torch.reshape(targets, (1, 1, 1, 3)) # L1Loss loss = L1Loss() result = loss(inputs, targets) # tensor(0.6667) # MSELoss loss_mse = nn.MSELoss() result_mse = loss_mse(inputs, targets) # tensor(1.3333) # CrossEntropyLoss x = torch.tensor([0.1, 0.2, 0.3]) y = torch.tensor([1]) x = torch.reshape(x, (1, 3)) loss_cross = nn.CrossEntropyLoss() result_cross = loss_cross(x, y) print(result_cross) # tensor(1.1019)
3. Back propagation
Using cifar10 network to test loss and back propagation
import torch
import torchvision
from tensorboardX import SummaryWriter
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten, Sequential
from torch.utils.data import DataLoader
class test_cifar(nn.Module):
def __init__(self) -> None:
super(test_cifar, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
dataset = torchvision.datasets.CIFAR10("../datasets", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
test_model = test_cifar()
loss_cross = nn.CrossEntropyLoss()
for data in dataloader:
imgs, targets = data
outputs = test_model(imgs)
# See what outputs and targets look like, and what loss functions need to be selected
print(outputs) # tensor([[-0.0997, -0.1220, -0.1413, 0.0602, -0.1044, 0.1636, -0.0469, -0.1157, 0.0060, -0.1186]], grad_fn=<AddmmBackward0>)
print(targets) # tensor([3])
result_loss = loss_cross(outputs, targets) # tensor(2.3130, grad_fn=<NllLossBackward0>)
result_loss.backward()
print("ok")
Break point, enter the network
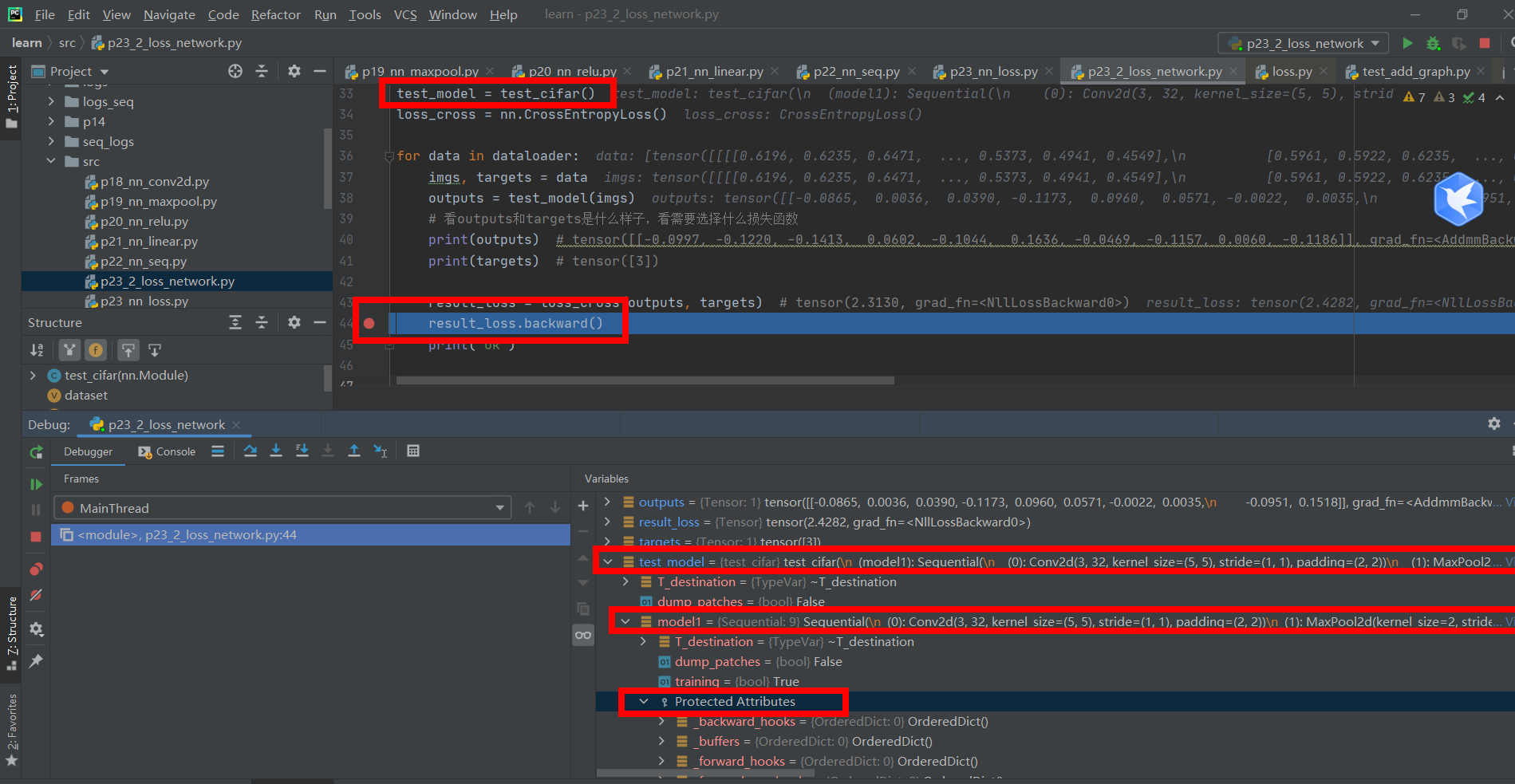
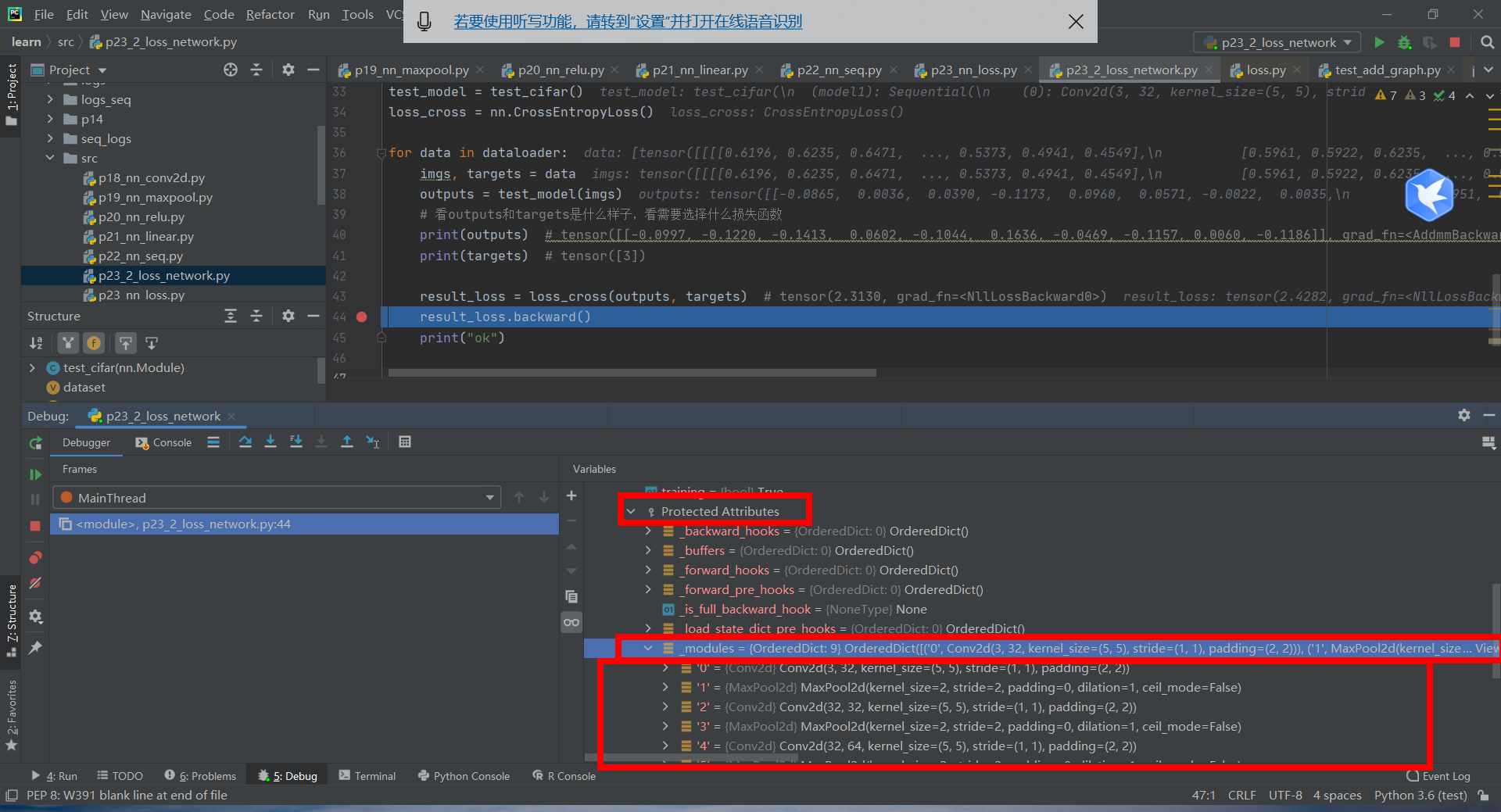
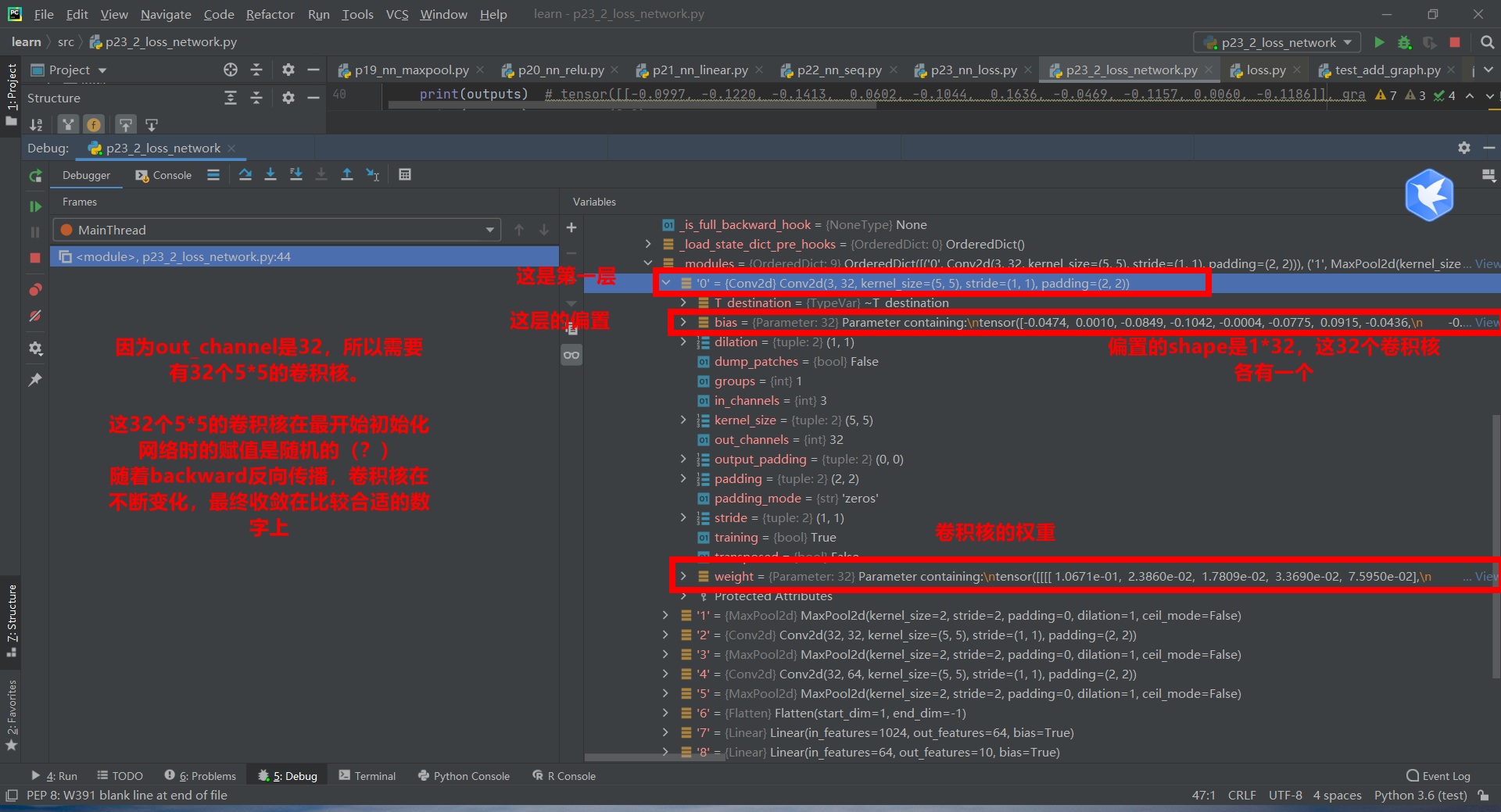
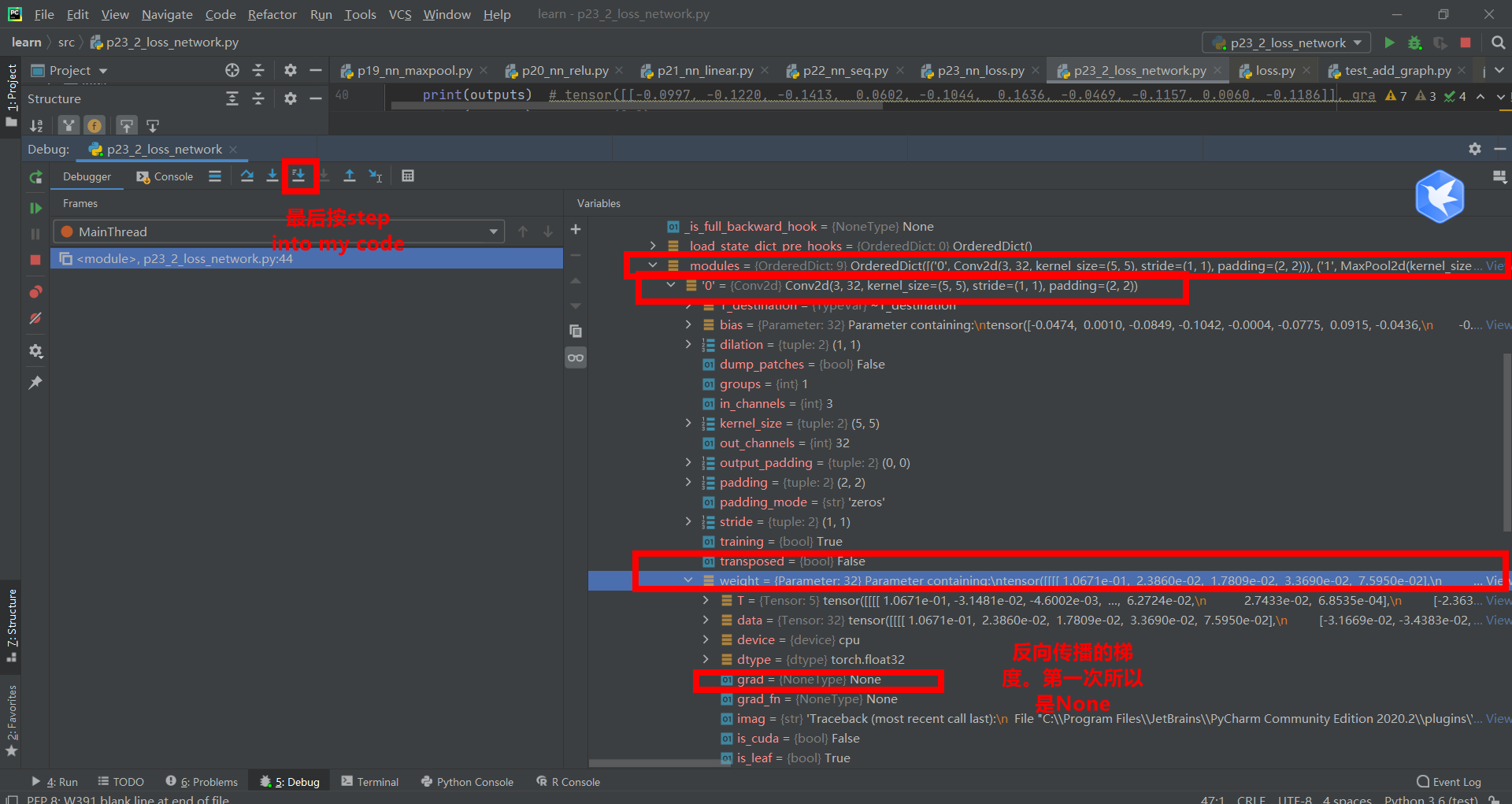
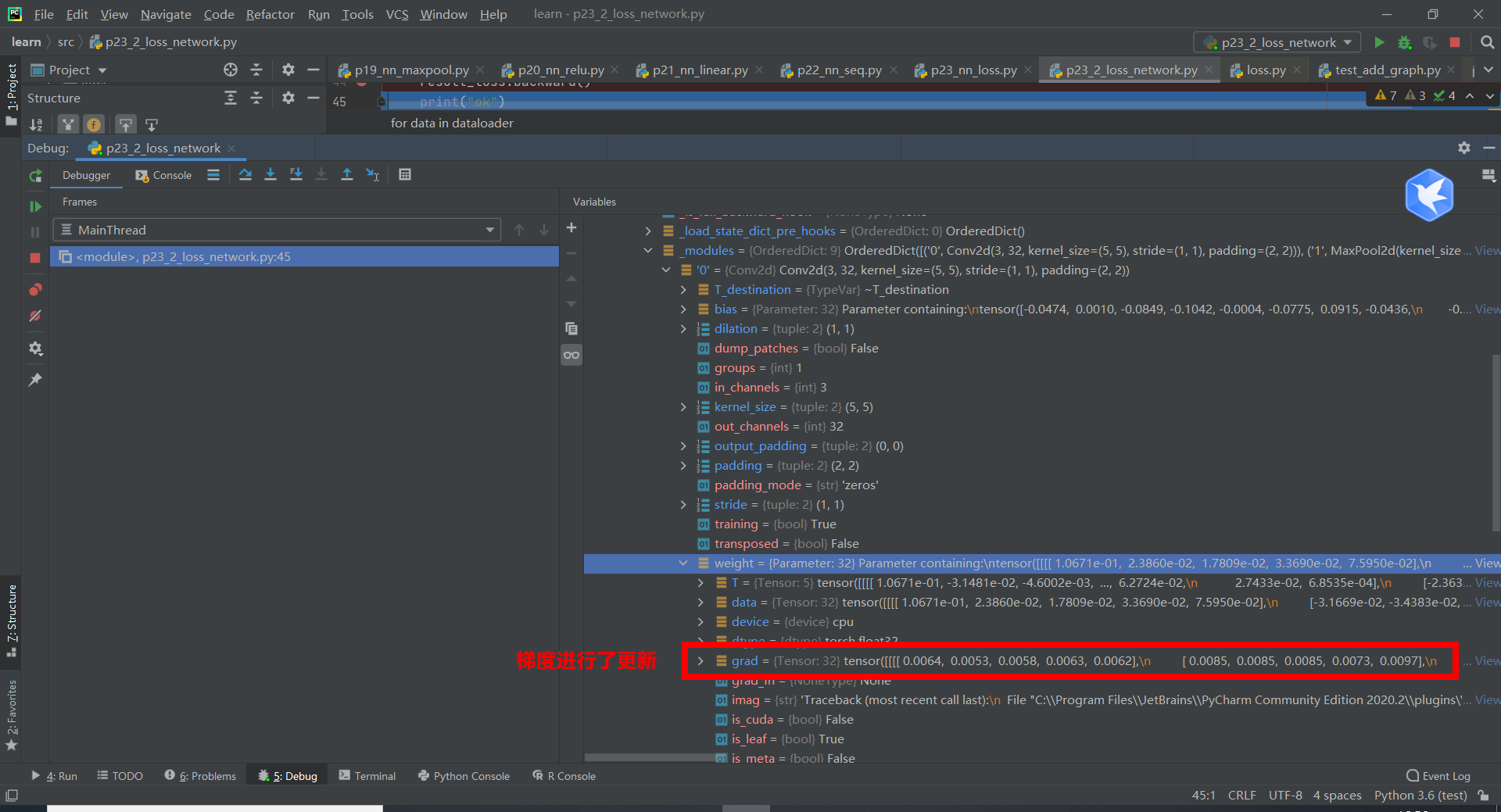
Note that if there is no result_ loss. With the statement backward (), the gradient will not be updated.
4. Optimizer
The optimizer adjusts the gradient
import torch
import torchvision
from tensorboardX import SummaryWriter
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten, Sequential
from torch.utils.data import DataLoader
class test_cifar(nn.Module):
def __init__(self) -> None:
super(test_cifar, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
dataset = torchvision.datasets.CIFAR10("../datasets", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
test_model = test_cifar()
loss_cross = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(test_model.parameters(), lr=0.01) # lr: learning rate
for data in dataloader:
imgs, targets = data
outputs = test_model(imgs)
result_loss = loss_cross(outputs, targets) # tensor(2.3130, grad_fn=<NllLossBackward0>)
optimizer.zero_grad() # The optimizer adjusts the gradient to 0
result_loss.backward()
optimizer.step() # Tune each parameter
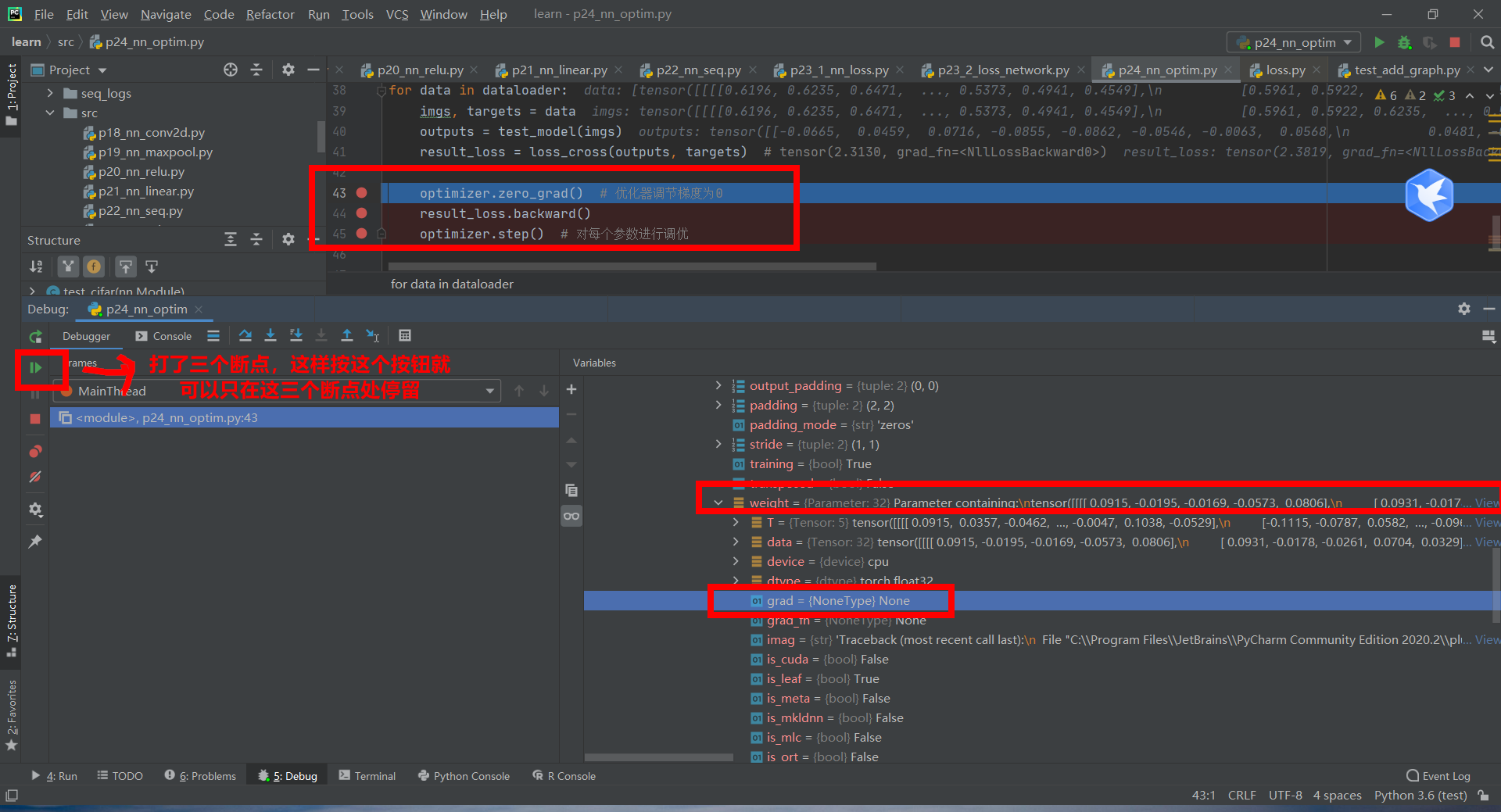
Press the green button to go to the next step, that is, run optimizer zero_ Grad() # optimizer adjusts gradient to 0, and grad=None
Press the green button again to run result_loss.backward() for back propagation. The gradient is updated.
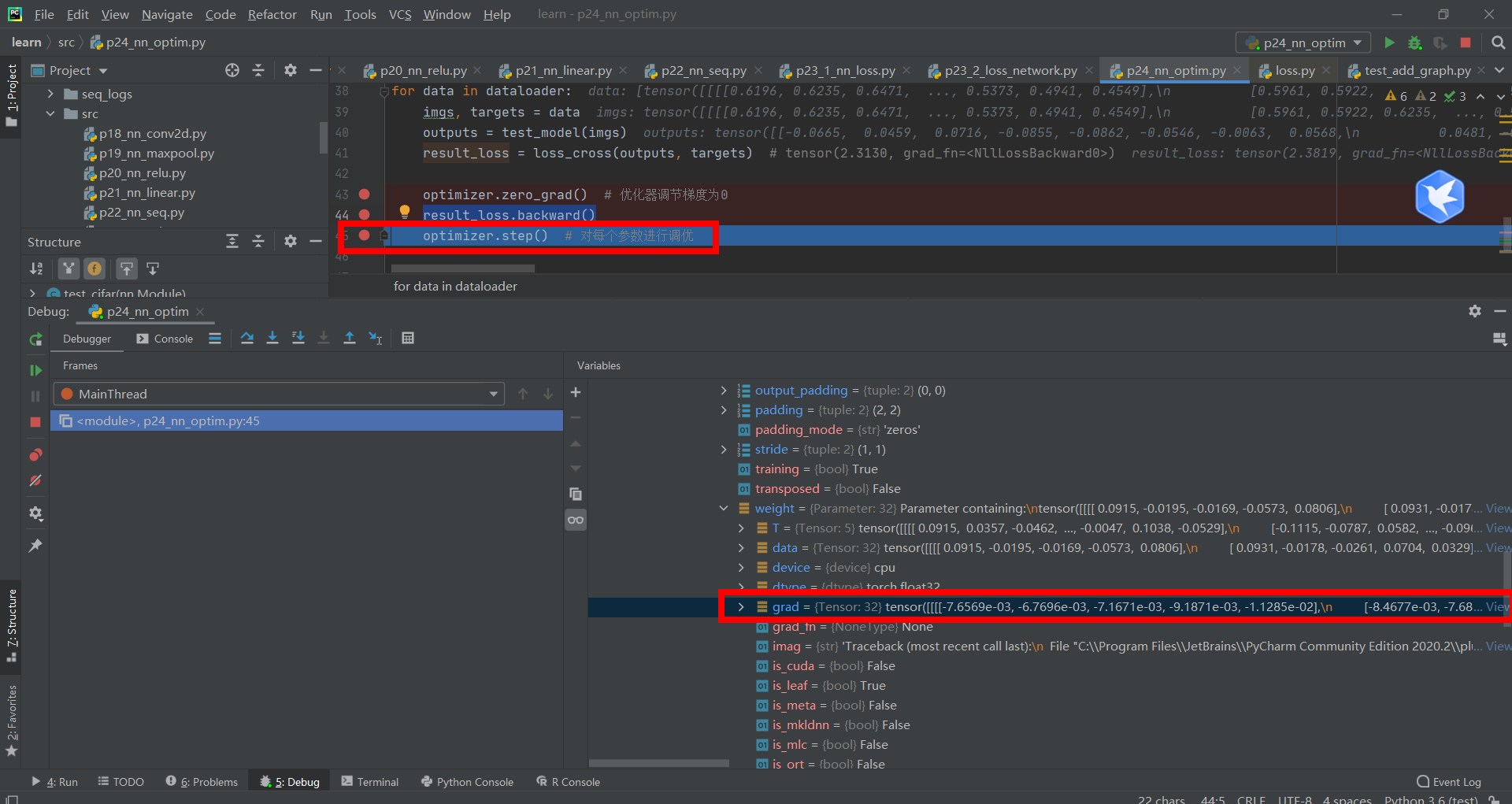
Press the green button again and run optimizer Step() # optimizes each parameter, and the optimizer updates the data with grad gradient.
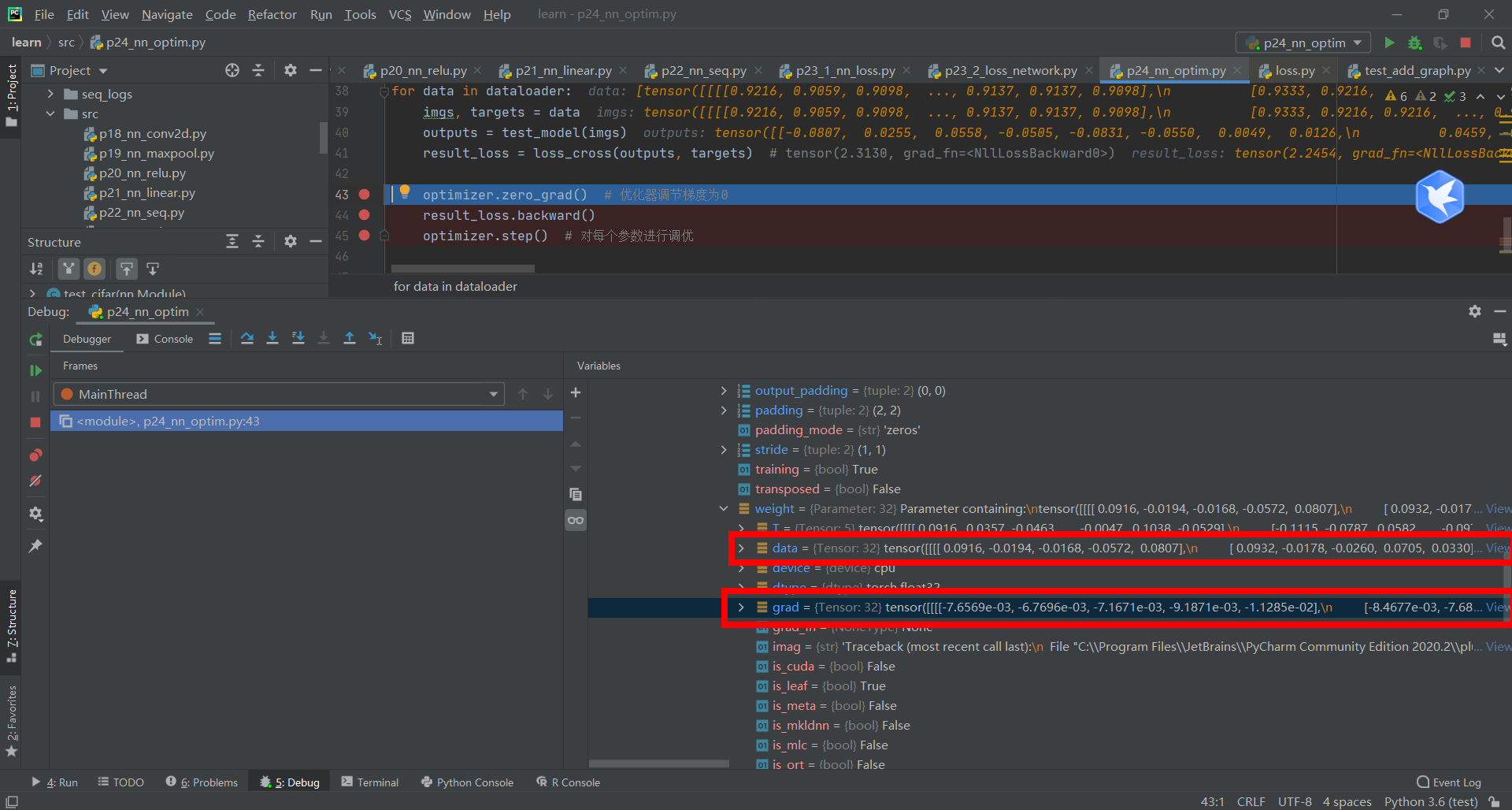
Plus the number of rounds
import torch
import torchvision
from tensorboardX import SummaryWriter
from torch import nn
from torch.nn import ReLU, Sigmoid, Linear, Conv2d, MaxPool2d, Flatten, Sequential
from torch.utils.data import DataLoader
class test_cifar(nn.Module):
def __init__(self) -> None:
super(test_cifar, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
dataset = torchvision.datasets.CIFAR10("../datasets", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
test_model = test_cifar()
loss_cross = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(test_model.parameters(), lr=0.01) # lr: learning rate
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = test_model(imgs)
result_loss = loss_cross(outputs, targets) # tensor(2.3130, grad_fn=<NllLossBackward0>)
optimizer.zero_grad() # The optimizer adjusts the gradient to 0
result_loss.backward()
optimizer.step() # Tune each parameter
running_loss = result_loss + result_loss
print(running_loss)
5. Use and modification of existing network model
Use vgg as an example
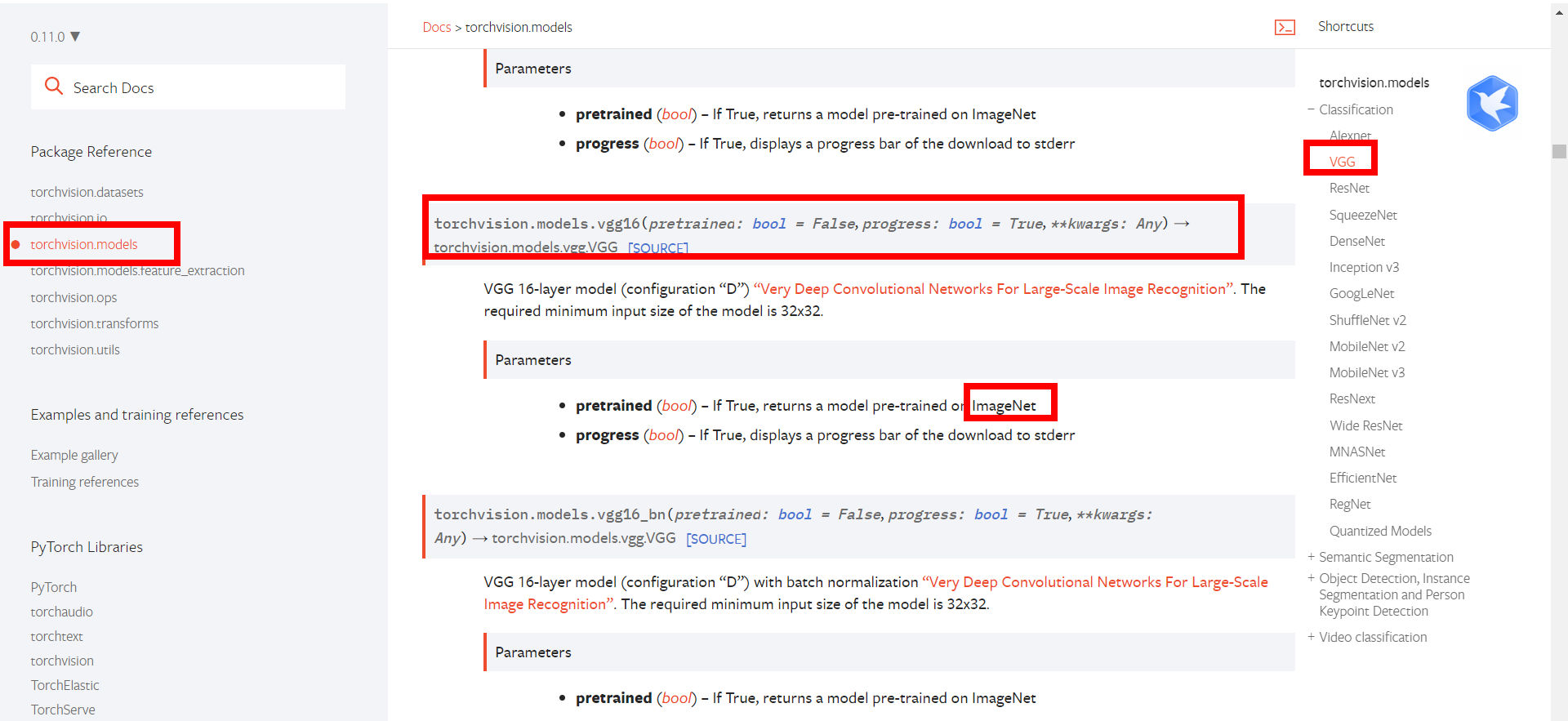
ImageNet dataset required
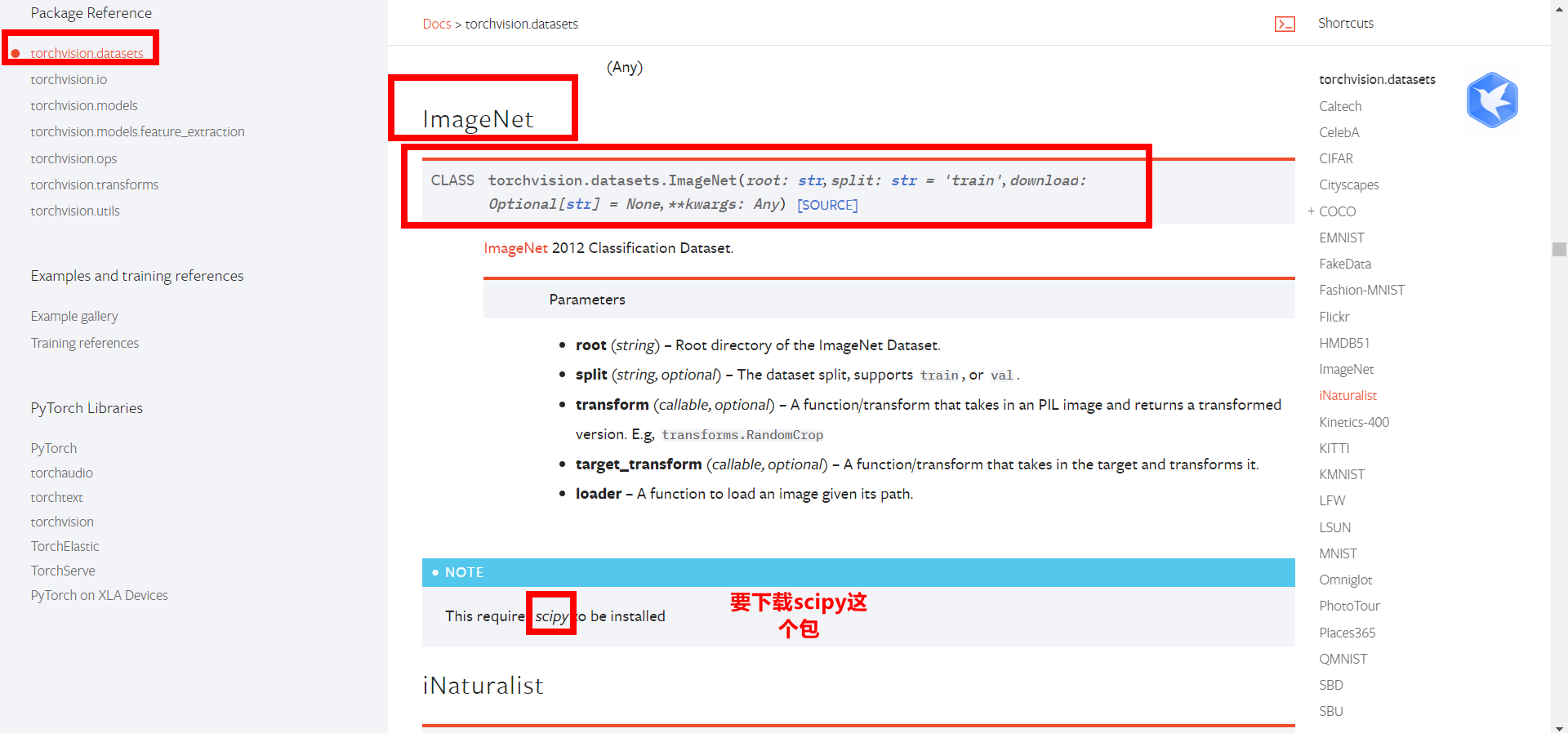
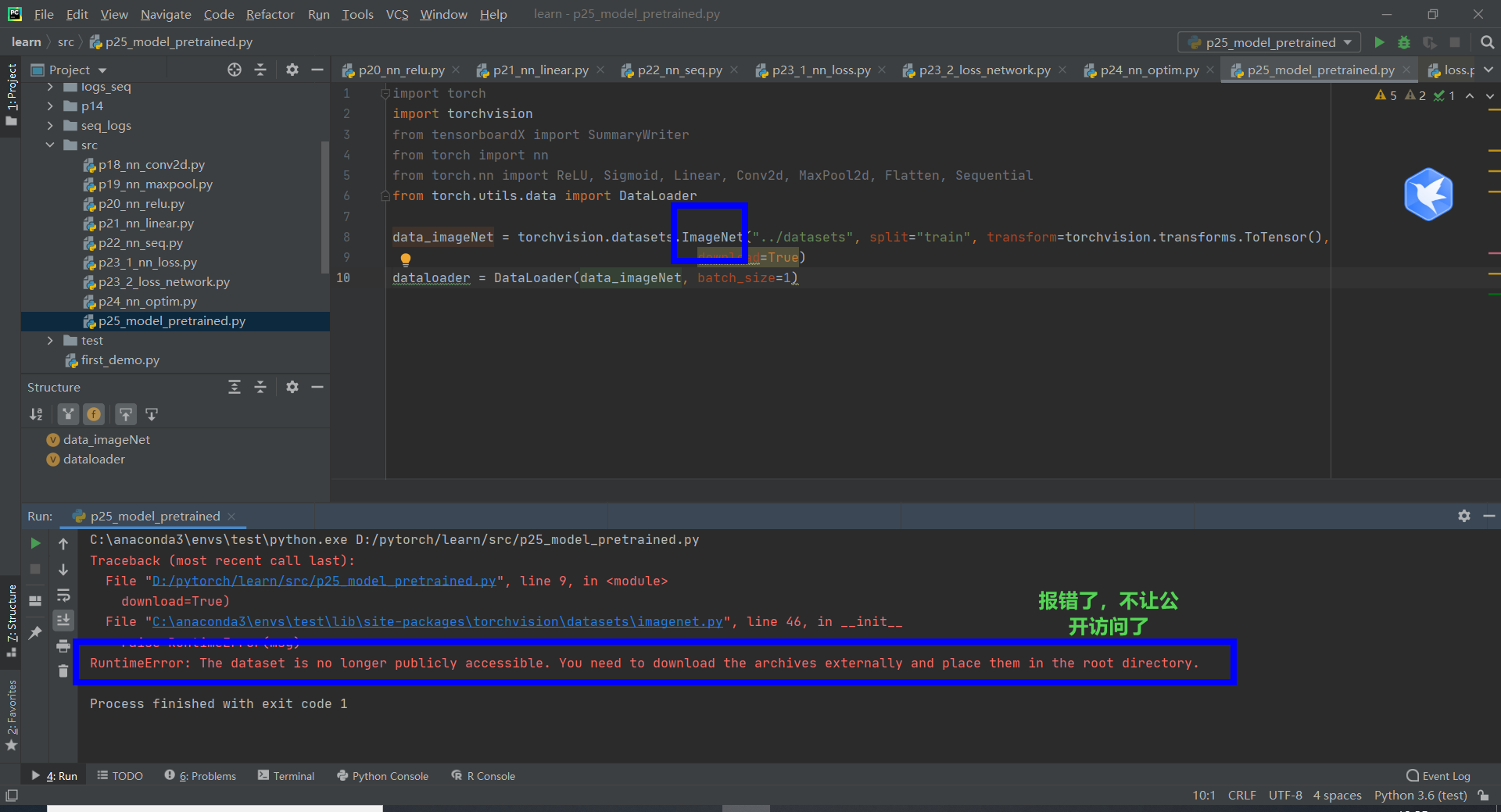
Wrong report. Forget it
--------
vgg model, where pre trained is whether to pre train
import torchvision vgg16_false = torchvision.models.vgg16(pretrained=False) # Network model, no parameter pre trained: pre trained or not vgg16_true = torchvision.models.vgg16(pretrained=True) # Trained network model print(vgg16_true)
Print out:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
As can be seen from the last linear layer, the output is out_features=1000, 1000 categories. We want vgg to be able to classify 10 and use them on cifar10.
Add a layer at the back
import torchvision
from torch import nn
vgg16_false = torchvision.models.vgg16(pretrained=False) # Network model, no parameter pre trained: pre trained or not
vgg16_true = torchvision.models.vgg16(pretrained=True) # Trained network model
print(vgg16_true)
vgg16_true.add_module("add_linear", nn.Linear(1000, 10))
print(vgg16_true)
Output:
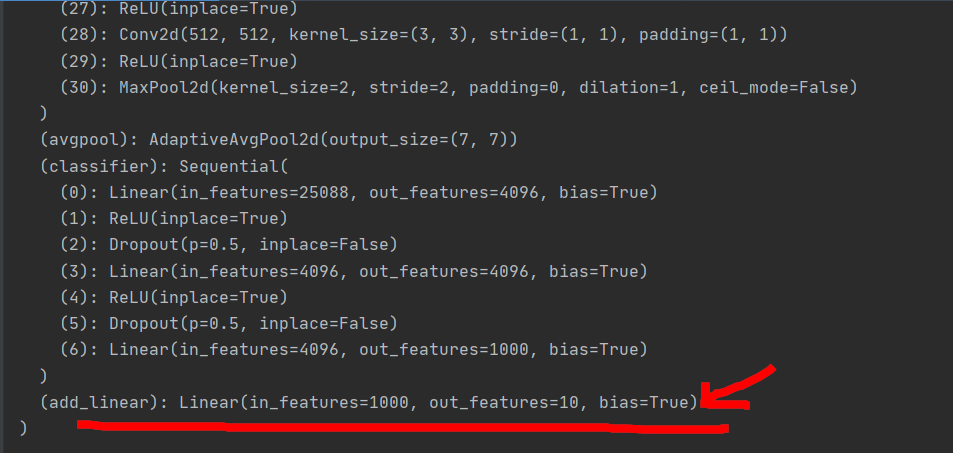
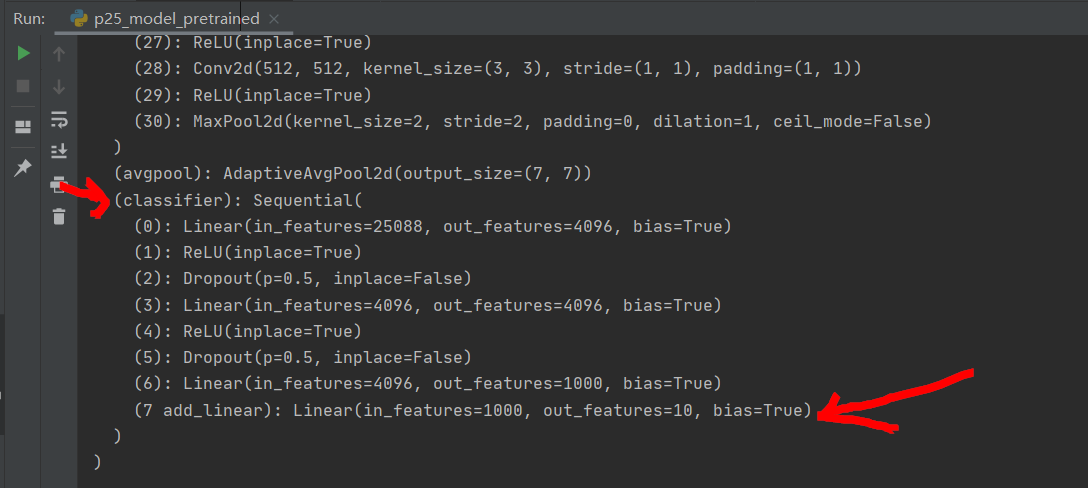
If a layer is added after the classifier, the statement is:
vgg16_true.classifier.add_module("7 add_linear", nn.Linear(1000, 10))
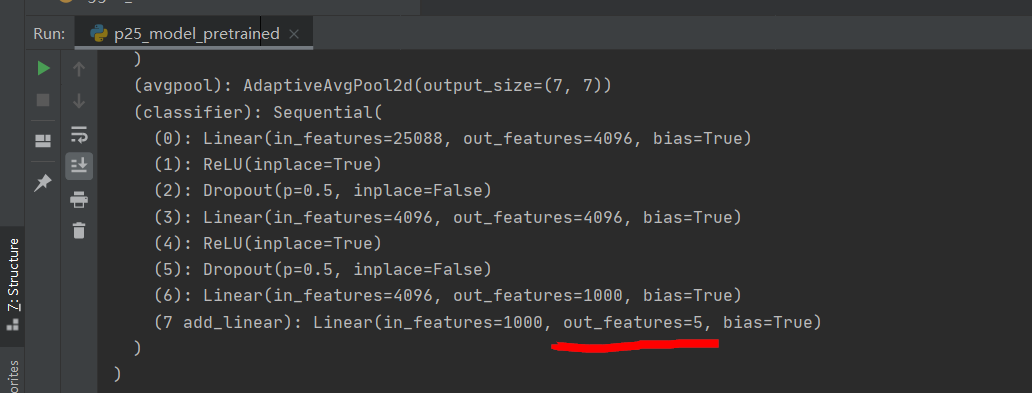
If you want to modify a layer, for example, add 7_ Modify linear to output 5
vgg16_true.classifier[7] = nn.Linear(1000, 5) # 7 is the subscript, and the subscript starts from 0
Then output
6. Model saving and loading
Model saving
Method 1: save the structure and parameters of the model
Method 2: save the state in vgg16 as a dictionary
The two methods are shown in the following code
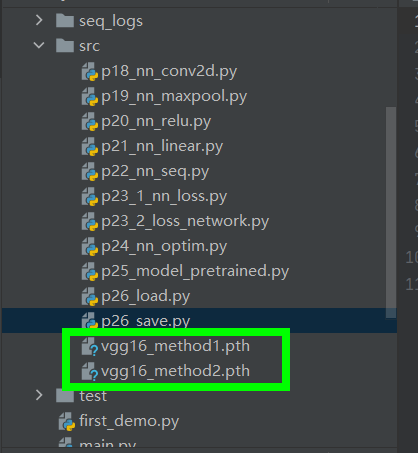
import torchvision from torch import nn import torch vgg16 = torchvision.models.vgg16(pretrained=False) # Save method 1: model structure + model parameters torch.save(vgg16, "vgg16_method1.pth") # Save the structure and parameters of the model # Save mode 2: the model parameters (officially recommended) are relatively small torch.save(vgg16.state_dict(), "vgg16_method2.pth") # Save the state in vgg16 as a dictionary
Generate a file and save the structure and parameters of the model
Model loading
The two methods correspond to different loading methods
import torchvision
from torch import nn
import torch
# Save method 1 - > Load
model1 = torch.load("vgg16_method1.pth")
print(model1)
# Save method 2 - > Load
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
print(vgg16)
In pychart: right click open in Terminal in the folder where pth is located
Then enter dir in Terminal to view the information of all files in the folder
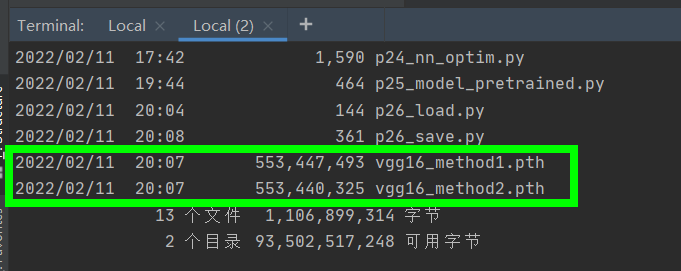
Trap:
When saving:
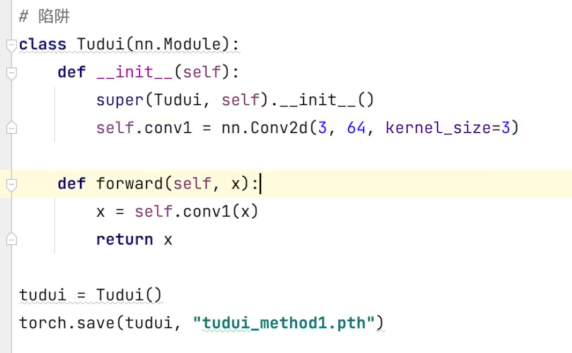
When loading directly, an error will be reported: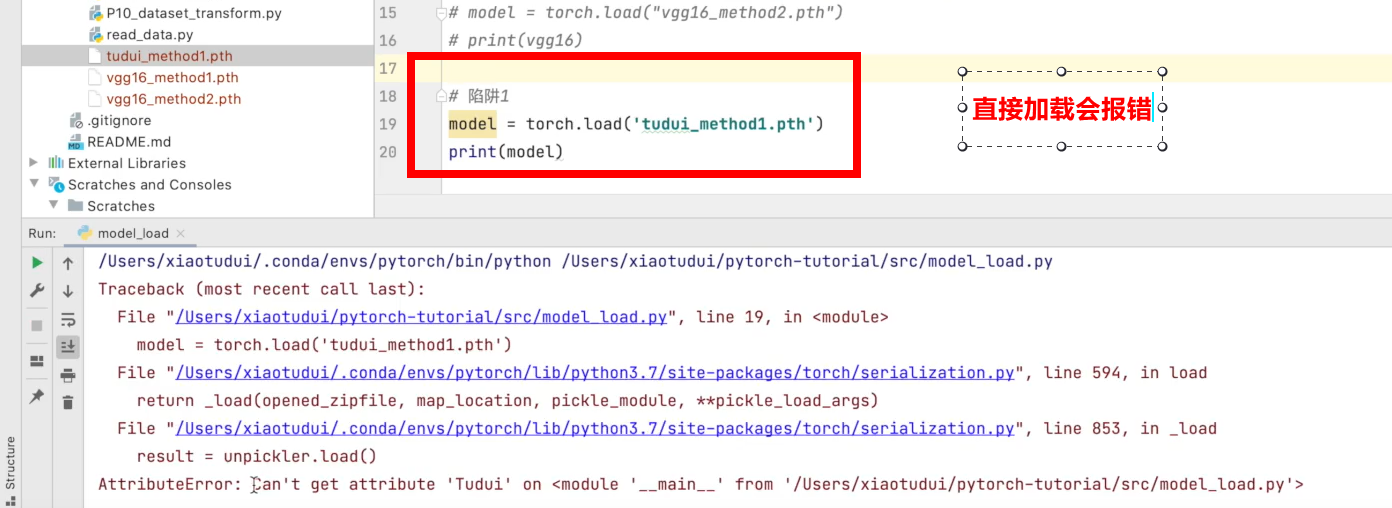
The network structure should be defined before it can work normally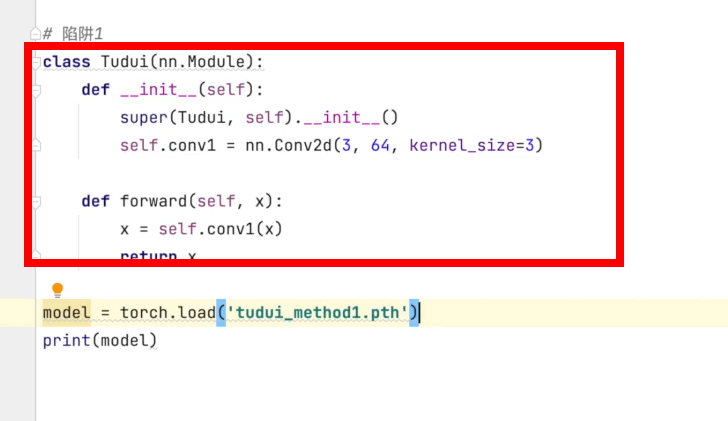
You can also import directly from the py file
