
t o r c n . n n \qquad torcn.nn torcn.nn is a modular interface specially designed for neural networks, including convolution, pooling, R N N RNN RNN and other calculations, such as L o s s Loss Loss calculation, you can put t o r c h . n n torch.nn The classes in torch.nn package are imagined as a layer of neural network.
t o r c n . n n \qquad torcn.nn Most classes in torcn.nn inherit the parent class t o r c h . n n . M o d u l e s torch.nn.Modules torch.nn.Modules, i.e. essentially all t o r c h . n n torch.nn The layers (such as convolution and pooling) in torch.nn are t o r c h . n n . M o d u l e s torch.nn.Modules torch.nn.Modules.
1, class torch.nn.Parameter
-
c
l
a
s
s
t
o
r
c
h
.
n
n
.
P
a
r
a
m
e
t
e
r
(
d
a
t
a
,
r
e
q
u
i
r
e
s
_
g
r
a
d
)
class\ \ torch.nn.Parameter(data, requires\_grad)
class torch.nn.Parameter(data,requires_grad):
Example: torch.nn.Parameter(torch.tensor(20211012.1139))- data: tensor of parameter.
- requires_grad: whether to calculate gradient. The default value is True.
\qquad torch.nn.Parameter is a subclass inherited from torch.Tensor. It is mainly used as a trainable parameter in torch.nn.Module. The difference between torch.Tensor and torch.nn.Parameter is that torch.nn.Parameter is automatically considered as a trainable parameter of module, that is, it is added to the iterator parameter(); Ordinary tensors in torch.nn.Module that are not torch.nn.Parameter are not in the iterator parameter ().
notes \qquad note Note: the torch.nn.Parameter object requires_ The default value of the grad property is True, that is, it can be trained, which is opposite to the default value of the torth.Tensor object.
2, class torch.nn.Module
\qquad Torch.nn.Module is the base class of all neural networks. There are up to 48 functions in this class. Any model we create should inherit this class. Generally, there is no layer concept in pytorch, and the layer is also treated as a model. Therefore, the Module can also contain other modules, that is, sub models. A torch.nn.Module (e.g. LeNet) can contain many sub modules (e.g. convolution layer, pooling layer, etc.), and the sub modules can be assigned to the model attributes.
2.1 building models
\qquad When defining our own neural network, we need to inherit the torch.nn.Module class and re implement it__ init__ Constructor and forward method. Generally, we put the layers with learnable parameters (such as full connection layer, convolution layer, etc.) in the neural network__ init__ Constructor; Layers without learnable parameters (such as ReLU, dropout, batchspecification layer, etc.) can be placed in__ init__ In the constructor, you can also choose not to put it in the constructor__ init__ In, torch.nn.functional can be used instead in the forward method.
\qquad After we put the layer with learnable parameters in the constructor, we can make the learnable parameters exist in the torch.nn.Module in the form of parameters through the torch.nn.Parameter function, and can use the parameters() function or named_ The parameters () function returns learnable parameters as iterators. All placed in constructor__ init__ The layers inside are the "inherent properties" of the model. Next, we inherit torch.nn.Module class to build a simple neural network model.
import torch.nn as nn
import torch.nn.functional as F # The function class will be described in detail later
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
# Two convolution sub models are established
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
# Build forward calculation process
x = F.relu(self.conv1(x))
y = F.relu(self.conv2(x))
return y
model = Model()
print(model)
Output:

\qquad
The above code constructs a neural network Model, which contains two sub modules: conv1 and conv2. The sub models assigned in the above way will be registered. When. cuda() is called, the parameters of the sub Model will also be converted to cuda Tensor.
\qquad
2.2 add sub model for model: add_module(name, module)
\qquad Add a submodule to the current model module. Submodules can be accessed through the given name attribute. For example:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
# Via add_ Adding a submodel to a module is equivalent to adding a module in 2.1, which is self.conv1 = nn.Conv2d(1, 20, 5)
self.add_module("conv1", nn.Conv2d(1, 20, 5))
model = Model()
print(model)
Output:

By the given name attribute
c
o
n
v
1
conv1
Conv1 accesses Submodules: model.conv1

2.3 acquire sub model: children()
\qquad Returns the iterator of the current model sub model. Duplicate models are returned only once. For example:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv1", nn.Conv2d(10, 20, 4))
self.add_module("conv2", nn.Conv2d(20 ,10, 4))
model = Model()
print(model.children()) # Generator iterator type < generator object module. Children at 0x7f55e005cb30 >
# Iterator for loop submodel
for sub_module in model.children():
print(sub_module)
Output:

2.4 get the name of the sub model of the model and the sub model itself: named_children()
\qquad Returns the name of the current model sub model and the iterator of the sub model itself. Duplicate models are returned only once. Unlike the children() method, named_ The children() method also returns the name corresponding to the child model. For example:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv1", nn.Conv2d(10, 20, 4))
self.add_module("conv2", nn.Conv2d(20 ,10, 4))
model = Model()
print(model.named_children()) # Generator iterator type < generator object module.named_ children at 0x7f56d3056820>
# The for loop iterates the submodel name and the submodel itself
for name, sub_module in model.named_children():
print("name:{}, sub_module:{}".format(name,sub_module))
Output:

2.5 get iterators of all models: modules()
\qquad Returns iterators for all models of the current model. Duplicate models are returned only once. Unlike the children() method, the modules() method also returns the current model module. For example:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv1", nn.Conv2d(10, 20, 4))
self.add_module("conv2", nn.Conv2d(20 ,10, 4))
model = Model()
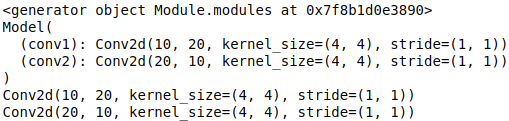
print(model.modules()) # Generator iterator type < generator object module. Modules at 0x7f8b1d0e3890 >
for module in model.modules():
print(module)
Output:
2.6 get the names of all models and the iterator of the model itself: named_modules()
\qquad Returns iterators for all models of the current model. Duplicate models are returned only once. And named_ The children () method is different, named_ The modules () method also returns the name of the current model module and the model itself. For example:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv1", nn.Conv2d(10, 20, 4))
self.add_module("conv2", nn.Conv2d(20 ,10, 4))
model = Model()
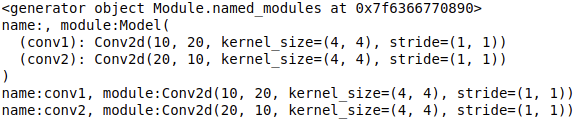
print(model.named_modules()) # Generator iterator type < generator object module. Modules at 0x7f6366770890 >
for name, module in model.named_modules():
print("name:{}, module:{}".format(name,module))
Output:
2.7 iterator for obtaining model parameters: parameters(recurse=True)
\qquad If rescue is True, an iterator containing all parameters of the current module and its sub modules is returned; If rescue is False, only an iterator containing all the parameters of the current module is returned. For example:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv1", nn.Conv2d(10, 20, 4))
self.add_module("conv2", nn.Conv2d(20 ,10, 4))
model = Model()
print(model.parameters()) # Generator iterator type < generator object module.modules at 0x7f4f279487b0 >
for param in model.parameters():
print(type(param), param.size())
Output:

2.8 iterator for obtaining model parameter name and parameter itself: named_parameters(prefix=’’, recurse=True)
\qquad If rescue is True, an iterator containing all parameter names and parameters of the current module and its sub modules is returned; If rescue is False, only an iterator containing all the parameter names of the current module and the parameter itself is returned. Prefix indicates the prefix added to the front of all parameter names. For example:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv1", nn.Conv2d(10, 20, 4))
self.add_module("conv2", nn.Conv2d(20 ,10, 4))
model = Model()
print(model.named_parameters()) # Generator iterator type < generator object module. Modules at 0x7f407c0257b0 >
for name, param in model.named_parameters(prefix='dong'):
print("name:{}, | {}, | {}".format(name, type(param), param.size()))
Output:

2.9 iterator for obtaining model buffer: buffers(recurse=True)
\qquad If rescue is True, an iterator containing all buffers of the current module and its sub modules is returned; If rescue is False, only an iterator containing all buffers of the current module is returned. For example:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.register_buffer("buffer1", torch.randn([2,3])) # register_ The buffer method will be described in detail later
self.register_buffer("buffer2", torch.randn([2,3]))
model = Model()
print(model.buffers()) # Generator iterator type < generator object module. Modules at 0x7f2591cea970 >
for buf in model.buffers():
print(type(buf), buf.size())
Output:

2.10 get the name of the model buffer and the iterator of the buffer itself: named_buffers(prefix=’’, recurse=True)
\qquad If rescue is True, an iterator containing all the buffer names of the current module and its sub modules and the buffer itself is returned; If rescue is False, only an iterator containing all the buffer names of the current module and the buffer itself is returned. Prefix indicates the prefix added to the front of all parameter names. For example:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.register_buffer("buffer1", torch.randn([2,3])) # register_ The buffer method will be described in detail later
self.register_buffer("buffer2", torch.randn([2,3]))
model = Model()
print(model.named_buffers()) # Generator iterator type < generator object module. Modules at 0x7f2591cea6d0 >
for name, buf in model.named_buffers(prefix='dong'):
print("name:{}, | {}, | {}".format(name, type(buf), buf.size()))
Output:

2.11 mobile model parameters and buffer
2.11.1 cpu()
\qquad Moving all model parameters and buffers to the CPU is an in place operation, that is, the original values are directly modified without copying.
2.11.2 xpu(device=None)
\qquad Moving all model parameters and buffers to XPU is an in place operation, that is, the original values are directly modified without copying. If device is specified, all model parameters will be moved to the specified device.
2.11.3 cuda(device=None)
\qquad Moving all model parameters and buffers to the GPU is an in place operation, that is, the original values are directly modified without copying. If device is specified, all model parameters will be moved to the specified device. Here are some other GPU related methods:
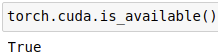
- torch.cuda.is_available(): determines whether the GPU can be used.
- torch.cuda.device_count(): returns the number of GPU s available.
- torch.cuda.current_device(): returns the id of the currently selected device.
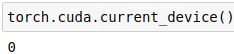
- torch.device('cuda', 0)/torch.device('cuda:0'): Specifies GPU acceleration.
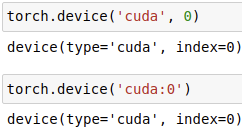
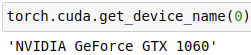
- torch.cuda.get_device_name(0): get the GPU name with id 0.
2.12 converting data types
2.12.1 double()
\qquad Convert all floating-point parameters and buffers in the module model to double data type.
2.12.2 float()
\qquad Convert all parameters and buffers with floating-point data type in the module model to float data type.
2.12.3 half()
\qquad Convert all parameters and buffers with floating-point data type in module model to half data type.
2.12.4 bfloat16()
\qquad
Convert all floating-point parameters and buffers in the module model to bfloat16 data types.
\qquad
2.13 adjust model mode
\qquad When building the neural network model, the module must first train, so it is always in the training state. However, if you download the model module already trained by others without training yourself, the neural network model should become the evaluation evaluation mode. For some models with BatchNorm, Dropout and other layers, the forward used in training and verification is different in calculation. It is necessary to specify whether the current model is training or verification in the process of forward.
2.13.1 eval()
\qquad Adjust the model module to the evaluation evaluation mode. Equivalent to self.train(False).
2.13.2 train(mode=True)
\qquad
Set the module to train training mode. Default: True.
\qquad
2.14 forward propagation function (* input)
\qquad
The forward method defines the forward propagation calculation to be performed every time the neural network is called. All subclasses must override this method.
\qquad
2.15 gradient return function zero_grad(set_to_none=False)
\qquad
Set the gradient of all model parameters to zero. set_to_none=True will let the memory allocator handle gradients instead of actively setting them to 0, which will accelerate moderately.
\qquad
2.16 creation and acquisition of parameter and buffer
\qquad There are two parameters that need to be saved in the neural network model: one is back propagation, which needs to be updated by the optimizer, called parameter; The other is called buffer, which does not need to be updated by the optimizer. Generally, pytorch saves the parameters in the network as OrderedDict Formal.
2.16.1 parameter
1. Create parameter
- Create from member variables
\qquad We can directly create the member variable self. * * * * * of the model through nn.Parameter(), which will be automatically registered in parameters, and the parameters created in this way will be automatically saved in OrderedDict.self.my_param = nn.Parameter(torch.randn(5, 5)) # Member variables of the model
- register_parameter(name, param)
\qquad We can create an ordinary parameter object through nn.Parameter(), which is not a member variable of the model, and then use register_ The parameter function registers the parameter object, and the registered parameters will also be automatically saved to OrderedDict. The parameter can be accessed by the specified name.param = nn.Parameter(torch.randn(5, 5)) # Normal Parameter object module.register_parameter("my_param", param)
2. Get parameter
- get_parameter(target)
\qquad Get the specified parameter according to the given target. If it exists, return the parameter corresponding to the target. Otherwise, an error is thrown.
2.16.2 buffer
1. Create buffer
- register_buffer(name, tensor, persistent=True)
\qquad Pass the tensor to register_buffer is registered. If this buffer needs to be added to OrderedDict, persistent needs to be set to True. After registration, the buffer will be automatically saved to OrderedDict, and the buffer can be accessed through the specified name.
2. Get buffer
- get_buffer(target)
\qquad Get the specified buffer according to the given target. If it exists, the buffer corresponding to the target will be returned. Otherwise, an error will be thrown.
2.16.3 get_submodule(target)
\qquad Obtain the specified sub model according to the given target. If it exists, return the sub model corresponding to the target. Otherwise, an error is thrown.
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv1", nn.Conv2d(10, 20, 4))
self.register_buffer("buffer1", torch.randn([2,3])) # register_ The buffer method will be described in detail later
model = Model()
print(model.get_buffer("buffer1"))
print(model.get_parameter("conv1.weight").shape)
print(model.get_submodule("conv1"))
Output:

2.17 hook related methods
\qquad Hook programming, also known as "hook", is a computer programming term. It refers to various technologies that modify or expand the behavior of operating system, application program or other software components by intercepting function calls, message passing and event passing between software modules. The code that handles intercepted function calls, events, and messages is called a hook.
\qquad In order to save video memory (memory), pytorch does not save intermediate variables in the calculation process, including the characteristic graph of the middle layer and the gradient of non leaf tensor. However, it is precisely because of the mechanism of pytorch to calculate the dynamic graph that there is a hook function. If we need to view or modify these intermediate variables when analyzing the neural network, we need to register hook to export the required intermediate variables. Using it, we can easily obtain and change the value and gradient of variables in the middle layer of the network without changing the structure of network input and output. There are four hook related methods:
- torch.Tensor.register_hook()
- torch.nn.Module.register_forward_hook()
- torch.nn.Module.register_backward_hook()
- torch.nn.Module.register_forward_pre_hook()
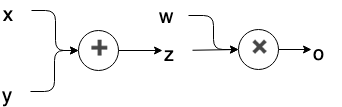
\qquad In the calculation graph of PyTorch, only the variables of leaf nodes will retain the gradient. The gradients of all intermediate variables are only used for back propagation. Once the back propagation is completed, the gradients of intermediate variables will be released automatically, so as to save memory. Now use the following code and calculation diagram for demonstration. As shown in the calculation diagram below, x, y and w are leaf nodes and z is intermediate variables.
import torch
x = torch.Tensor([0, 1, 2, 3]).requires_grad_()
y = torch.Tensor([4, 5, 6, 7]).requires_grad_()
w = torch.Tensor([1, 2, 3, 4]).requires_grad_()
z = x + y
# z.retain_grad()
o = w.matmul(z)
# o.retain_grad()
o.backward()
print('x.requires_grad:', x.requires_grad)
print('y.requires_grad:', y.requires_grad)
print('z.requires_grad:', z.requires_grad)
print('w.requires_grad:', w.requires_grad)
print('o.requires_grad:', o.requires_grad)
print()
print('x.grad:', x.grad)
print('y.grad:', y.grad)
print('w.grad:', w.grad)
print('z.grad:', z.grad)
print('o.grad:', o.grad)
Calculation diagram:
Output:
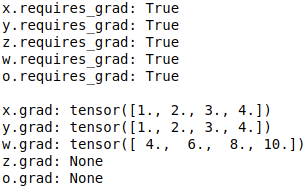
\qquad
Since z and o are intermediate variables (variables that do not directly specify values, but are calculated from other variables), they are required_ Grad's parameters are True, but after back propagation, their gradients are not saved, but directly deleted, so they are None.
\qquad
If you want to preserve their gradients after back propagation, you need to specify that z.retain in the above code_ Grad () and o.retain_ Remove the comments of grad to get their corresponding gradients. The operation results are as follows:
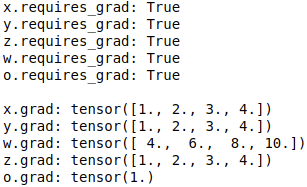
\qquad
However, this plus retain_grad() scheme will increase the memory occupation, which is not a good method. An alternative to this is to save the gradient of intermediate variables with hook (Note: the gradient in this way is not directly saved, and the gradient can only be operated in hook method, such as printing and modification).
2.17.1 torch.Tensor.register_hook(hook_fn)
\qquad Register a backpropagation hook function_ fn,register_ The hook function receives an input parameter hook_fn, is the name of the custom function. Hook is called before each call to the backward function_ FN function. hook_ The FN function also receives an input parameter, which is the gradient of the torch.Tensor tensor. The use method is as follows:
import torch
# x. Y is the leaf node, that is, PyTorch will only retain the gradient value of this node during calculation
x = torch.tensor([3.], requires_grad=True)
y = torch.tensor([5.], requires_grad=True)
# a. B and C are intermediate variables, which will be released when calculating the gradient
a = x + y
b = x * y
c = a * b
# Create a new list to store the intermediate gradient values saved by the hook function
a_grad = []
def hook_grad(grad):
a_grad.append(grad)
# register_ The hook parameter is a function
handle = a.register_hook(hook_grad)
c.backward()
# Only leaf nodes have gradient values
print('gradient:', x.grad, y.grad, a.grad, b.grad, c.grad)
# The hook function retains the gradient value of the intermediate variable a
print('hook Function preserves intermediate variables a Gradient value of:', a_grad[0])
# Remove hook function
handle.remove()
2.17.2 torch.nn.Module.register_forward_hook(hook_fn)
\qquad Function: used to export the input-output tensor of the specified sub model. You can only modify the output value, not the input value (modifying the input value is also invalid). You need to use return to return the modified output value to make the operation effective, register_ forward_ The return value of hook function is assigned to output by default, which is often used to export or modify convolution characteristic graph.
\qquad Usage: register a forward on the neural network model module_ Hook function hook_fn,register_ forward_ The hook function receives an input parameter hook_fn, is the name of the custom function. Note: when calling hook_ The hook will not be executed until the model (layer) of FN function propagates forward and calculates the result_ FN function, so modifying the output value will only affect subsequent operations. hook_fn function receives three input parameters: module, input and output, where module is the current network layer, input is the input data of the current network layer, and output is the output data of the current network layer. The function performed by the following code is 3 × 3 3 \times 3 three × Convolution sum of 3 2 × 2 2 \times 2 two × 2 pool. We use register_ forward_ The hook function records the feature map of the input and output of the intermediate convolution layer.
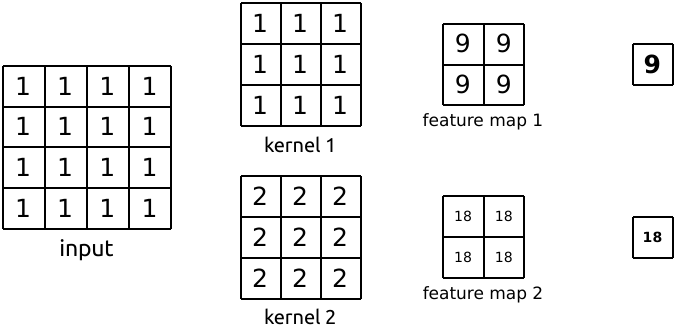
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 2, 3)
self.pool1 = nn.MaxPool2d(2, 2)
def forward(self, x):
print("-------------implement forward function-------------")
print("Convolution layer input:",x)
x = self.conv1(x)
print("Convolution layer output:",x)
x = self.pool1(x)
print("Pool layer output:",x)
print("-------------end forward function-------------")
return x
# The module is net.conv1
# data_input is the input of net.conv1 layer
# data_output is the output of net.conv1 layer
def forward_hook(module, data_input, data_output):
print("-------------implement forward_hook function-------------")
input_block.append(data_input)
fmap_block.append(data_output)
#print("convolution layer output before modification: {}". format(data_output))
#data_output = torch.rand((1, 1, 4, 4))
#print("modified convolution layer output: {}". format(data_output))
print("-------------end forward_hook function-------------")
#return data_output
# Initialize network
net = Net()
net.conv1.weight[0].detach().fill_(1)
net.conv1.weight[1].detach().fill_(2)
net.conv1.bias.data.detach().zero_()
# Register hook
fmap_block = list()
input_block = list()
handle = net.conv1.register_forward_hook(forward_hook)
# inference
fake_img = torch.ones((1, 1, 4, 4)) # batch size * channel * H * W
output = net(fake_img)
handle.remove()
# observation
print("Neural network model output:\noutput shape: {}\noutput value: {}\n".format(output.shape, output))
Output:
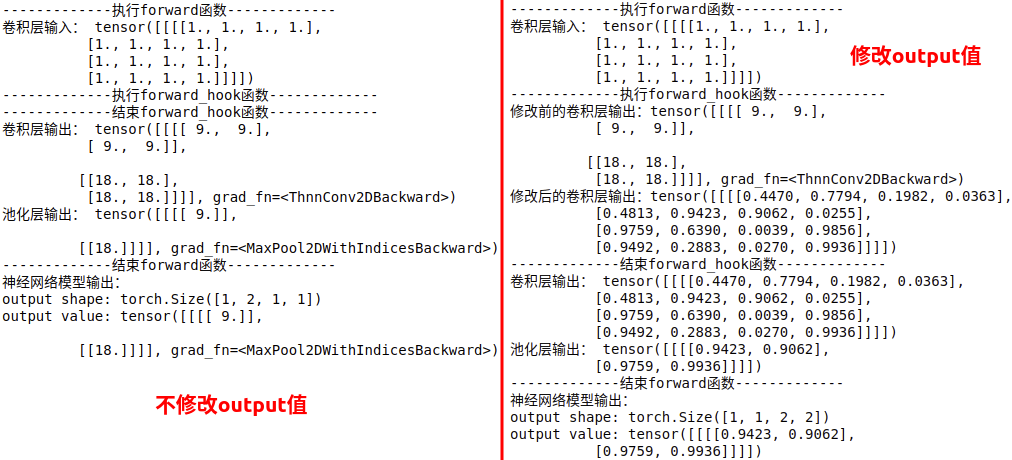
2.17.3 torch.nn.Module.register_forward_pre_hook(hook_fn)
\qquad Function: used to export or modify the input tensor of the specified sub model. Return is required to return the modified output value to make the operation effective.
\qquad Usage: register a forward on the neural network model module_ pre_ Hook function hook_fn,register_ forward_ pre_ The hook function receives an input parameter hook_fn, is the name of the custom function. Note: when calling hook_ The hook will be executed before the forward propagation operation of the model (layer) of FN function_ FN function, so modifying the input value will affect the operation of this layer, and the operation results of this layer will continue to be passed forward. hook_fn function receives two input parameters: module and input, where module is the current network layer and input is the input data of the current network layer. The function performed by the following code is 3 × 3 3 \times 3 three × Convolution sum of 3 2 × 2 2 \times 2 two × 2 pool. We use register_ forward_ pre_ The hook function modifies the tensor of the intermediate convolution input.
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 2, 3)
self.pool1 = nn.MaxPool2d(2, 2)
def forward(self, x):
print("-------------implement forward function-------------")
print("Convolution layer input:",x)
x = self.conv1(x)
print("Convolution layer output:",x)
x = self.pool1(x)
print("Pool layer output:",x)
print("-------------end forward function-------------")
return x
# The module is net.conv1
# data_input is the input of net.conv1 layer
def forward_pre_hook(module, data_input):
print("-------------implement forward_pre_hook function-------------")
input_block.append(data_input)
#print("convolution layer input before modification: {}". format(data_input))
#data_input = torch.rand((1, 1, 4, 4))
#print("modified convolution layer input: {}". format(data_input))
print("-------------end forward_pre_hook function-------------")
#return data_input
# Initialize network
net = Net()
net.conv1.weight[0].detach().fill_(1)
net.conv1.weight[1].detach().fill_(2)
net.conv1.bias.data.detach().zero_()
# Register hook
input_block = list()
handle = net.conv1.register_forward_pre_hook(forward_pre_hook)
# inference
fake_img = torch.ones((1, 1, 4, 4)) # batch size * channel * H * W
output = net(fake_img)
handle.remove()
# observation
print("Neural network model output:\noutput shape: {}\noutput value: {}\n".format(output.shape, output))
Output:

2.17.4 torch.nn.Module.register_backward_hook(hook)
\qquad During network back propagation, you can use register_backward_hook to obtain the gradient input and output of the middle layer, which is often used to extract the gradient of the feature map. Example: unfinished to be continued
3, class torch.nn.Sequential(* args)
\qquad torch.nn.Sequential is a container inherited from the Module class. The Sequential container implements the forward function. The Sequential container will add the neural network modules in the constructor to the calculation diagram for execution in order of being passed, and name each layer with 0,1,2,3. In addition, the Sequential container can also receive an ordered dictionary OrderedDict.
3.1 implementation of sequential class
3.1.1 constructor
\qquad Sequential is a sequential container that adds specific neural network modules to the calculation diagram in the order of passing in constructors. Examples are as follows:
import torch.nn as nn
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
print(model)
print(model[2]) # Get the specified layer using the index
Output:

3.1.2 ordered dictionary
\qquad The specific neural network module is passed into the Sequential class in the form of ordered dictionary parameters. In this way, each layer can be given a name, and the specified layer can be obtained directly through the name. Examples are as follows:
import torch.nn as nn
from collections import OrderedDict
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
print(model)
# Get the specified layer using the index
print(model[0])
print(model[2])
# Gets the specified layer by name
print(model.conv1)
print(model.conv2)
Output:

3.1.3 add layer_ module
\qquad add_module is a method of the Sequential class inherited from the parent class module, which can add sub models to a neural network model.
import torch.nn as nn
from collections import OrderedDict
model = nn.Sequential()
model.add_module("conv1",nn.Conv2d(1,20,5))
model.add_module('relu1', nn.ReLU())
model.add_module('conv2', nn.Conv2d(20,64,5))
model.add_module('relu2', nn.ReLU())
print(model)
print(model[2]) # Get the specified layer using the index
Output:

4, class torch.nn.ModuleList(modules=None)
\qquad ModuleList is a subclass of module. It is a container that stores different modules and automatically adds the parameters of each module to the network. When ModuleList is added as a member of the module object (that is, when we add modules to our network), the parameters of all modules inside ModuleList are also added as parameters of our network.
4.1 create ModuleList
import torch.nn as nn
class net_modlist(nn.Module):
def __init__(self):
super(net_modlist, self).__init__()
# Create ModuleList
self.modlist = nn.ModuleList([
nn.Conv2d(1, 20, 5),
nn.ReLU(),
nn.Conv2d(20, 64, 5),
nn.ReLU()
])
def forward(self, x):
for m in self.modlist:
x = m(x)
return x
net_modlist = net_modlist()
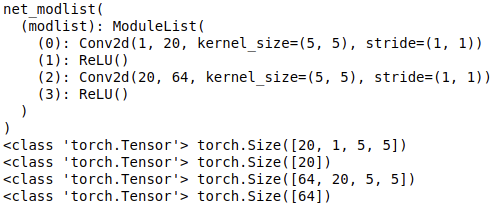
print(net_modlist)
for param in net_modlist.parameters():
print(type(param.data), param.size())
Output:
4.2 extend and append methods
\qquad After creating a ModuleList object, the object has the extend and append methods. The usage is the same as in python. Extend is to append multiple values of another ModuleList at one time at the end of the ModuleList object, and append is to add another module at the end of the ModuleList object.
import torch.nn as nn
class net_modlist(nn.Module):
def __init__(self):
super(net_modlist, self).__init__()
self.modlist = nn.ModuleList([
nn.Conv2d(1, 20, 5),
nn.ReLU(),
nn.Conv2d(20, 64, 5),
nn.ReLU()
])
def forward(self, x):
for m in self.modlist:
x = m(x)
return x
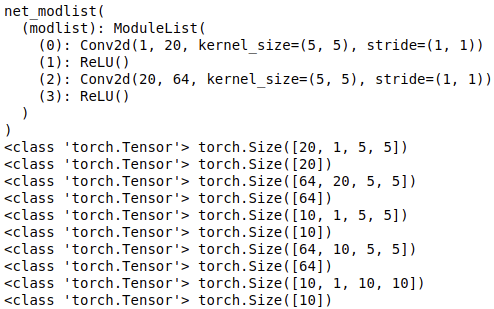
net_modlist = net_modlist()
print(net_modlist)
net_modlist.modlist.extend([nn.Conv2d(1, 10, 5),nn.ReLU(),nn.Conv2d(10, 64, 5),nn.ReLU()])
net_modlist.modlist.append(nn.Conv2d(1, 10, 10))
for param in net_modlist.parameters():
print(type(param.data), param.size())
Output:
4.3 differences between sequential and ModuleList
4.3.1 whether the forward function is implemented or not
\qquad Sequential implements the forward function internally, so you don't have to rewrite the forward function. ModuleList does not implement the internal forward function, so the forward function needs to be rewritten.
4.3.2 give network layer name
\qquad Sequential can use OrderedDict to name each layer, while ModuleList can only use the default name.
4.3.3 hierarchical relationship
\qquad The modules in Sequential are arranged in order, and the execution order is also arranged in order. Therefore, it must be ensured that the output size of the previous module is consistent with the input size of the next module. The ModuleList does not define a network, it just stores different modules together. The modules in the ModuleList cannot run directly in forward, and there is no order between these modules. The execution order of modules is determined according to the forward function.