I. application scenario
In x86 (Ubuntu 18.04) cpu, in pytorch1.0 10 framework, using the detectron2 model base model to train their own data sets, and carry out target detection reasoning.
II. Environment configuration
My environment is:
pytorch==1.10+cpu
torchvision==0.11.2+cpu
detectron2==0.6
opencv==4.5.5
1. Basic environment configuration
Here, you can use conda or Python 3-venv to create a virtual environment. I won't repeat it here, but only explain the construction of the basic environment.
$ sudo apt-get install python3-pip git cmake make gcc g++ $ python3 -m pip intall –upgrade pip
On the official website( https://pytorch.org/ )Install pytorch and torchvison according to your actual situation
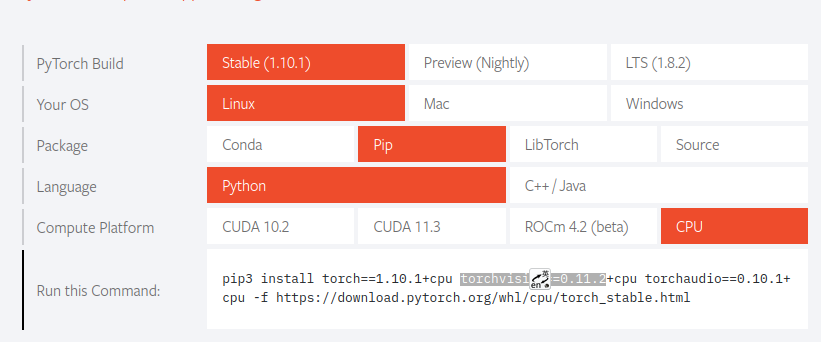
$ pip3 install torch==1.10.1+cpu torchvision==0.11.2+cpu torchaudio==0.10.1+cpu -f https://download.pytorch.org/whl/cpu/torch_stable.html $ pip3 install opencv-python $ pip3 install setuptools==58.2.0
2. Construction of detectron2
$ git clone https://github.com/facebookresearch/detectron2.git $ python3 -m pip install -e detectron2
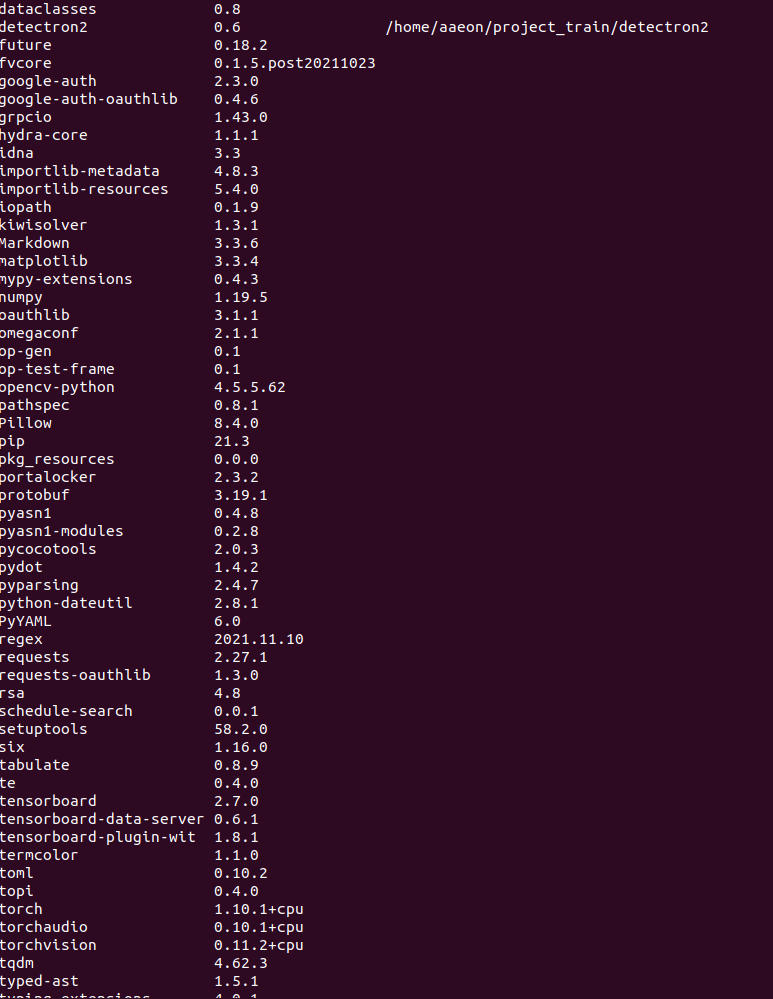
After installation, the main library versions are as follows:
3 demo run test
First, download the test image in the detectron2 / demo folder. Here I download it and name it dog jpg

Run demo
$python3 demo.py --config-file ../configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml \ --input dog.jpg –output dog_out.jpg \ --opts MODEL.DEVICE cpu MODEL.WEIGHTS detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl
Parameter interpretation:
--Config file is followed by configuration file, which can be found under detectron2/configs
--Input followed by input file
--The output is followed by the prediction to save the picture
--opt is a configuration option, which needs to be followed by the specific parameter model The device is followed by the device. Here is the cpu. The default cud is not added
MODEL.WEIGHTS is followed by the weight of the model
Prediction results of model operation:

The test is successful and the api installation is OK. Let's start the operation process.
III. data set preparation
The file operations involved here are complex. Please read them carefully. Here, labelimg data annotation tool is used to label the image as an xml file, and then convert it into coco2017 dataset format
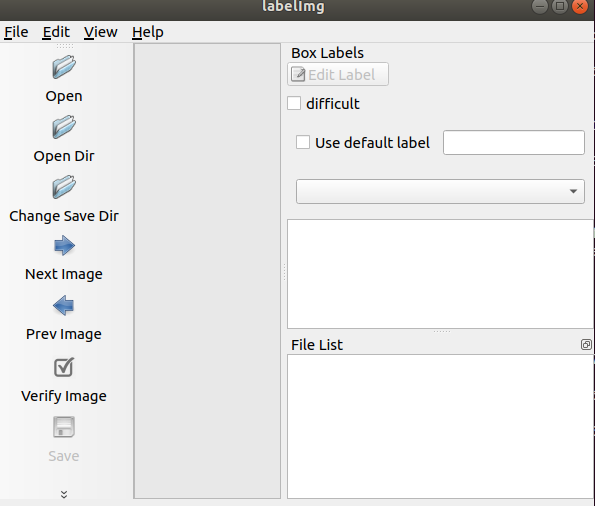
1 labelimg installation
$ pip3 install labelimg
Open labelimg:
2 voc data processing
Create a new folder in the detectron2/datasets folder and generate the following directory:
VOC2007
----Annotations # manual creation
----Create JPEGs # images manually
----ImageSets # manual creation
--------Main # manual creation
----split.py # script
----train_JPEGImages # self created
----val_JPEGImages # self created
----val_annotations # self created
----train_annotations # self created
mv.py # script
(1) Prepare for operation
Put the prepared original pictures on JPEGImages and name them uniformly, similar to letters + serial numbers.
Open labelimg and click open dir to enter JPEGImages pointing here
Click change save dir to point the generated xml file to the Annotations folder.
Ensure that the label format is pascal VOC format.
Then you can start normal labeling.
(2) Partition dataset
After labeling, divide the data set
1 generate index file
Run split first Py (detectron2 / datasets / voc207 /) code is as follows:
import os
import random
trainval_percent = 0.2
train_percent = 0.8
xmlfilepath = 'Annotations'
txtsavepath = r'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()Generate the next partition txt file of JPEGImages/Main
The split ratio can be modified at the corresponding position of the script.

$ python3 split.py
After running successfully, txt files will be generated under several subfolders of Main.
2 picture mark segmentation
Divide and copy the pictures and xml files according to the index file generated in 1
Separate the training set first.
Yes, MV Py (under the detectron2/datasets path):
import os
import shutil
class CopyXml():
def __init__(self):
# The path of your annotation in xml format
self.xmlpath = r'VOC2007/Annotations'
self.jpgpath = r'VOC2007/JPEGImages'
# The storage path of your training set / test set xml and jpg
self.newxmlpath = r'VOC2007/train_annotations'
self.newjpgpath = r'VOC2007/train_JPEGImages'
def startcopy(self):
filelist = os.listdir(self.path) # file list in this directory
# print(len(filelist))
test_list = loadFileList()
# print(len(test_list))
for f in filelist:
xmldir = os.path.join(self.xmlpath, f)
jpgdir = os.path.join(self.jpgpath, f)
(shotname, extension) = os.path.splitext(f)
if str(shotname) in test_list:
#print('success')
shutil.copyfile(str(xmldir),os.path.join(self.newxmlpath,f))
shutil.copyfile(str(jpgdir),os.path.join(self.newjpgpath,f))
# load the list of train/test file list
def loadFileList():
filelist = []
f = open("VOC2007/ImageSets/Main/train.txt", "r")
# f = open("VOC2007/ImageSets/Main/train.txt", "r")
lines = f.readlines()
for line in lines:
# Remove the characters at the end of each line of the file
line = line.strip('\r\n') # to remove the '\n' for test.txt, '\r\n' for tainval.txt
line = str(line)
filelist.append(line)
f.close()
# print(filelist)
return filelist
if __name__ == '__main__':
demo = CopyXml()
demo.startcopy()Make modifications


Post run:
$ python 3 mv.py
No problem running. You'll see the train_ annotations train_ There are xml files and jpg files with the same name under the jpegimages folder.
Then separate the test set
Yes, MV Py (under the path of detectron2/datasets)


Post run:
$ python 3 mv.py
Run no problem, you will see val_ annotations val_ There are xml files and jpg files with the same name under the jpegimages folder
3. Production of coco data set
Create a new folder in the detectron2/datasets folder and generate the following directory:
coco
----train2017 ##### manual creation
----val2017 ###### manual creation
----annotations ###### manual creation
--------instances_train2017.json ###### script generation
--------instances_val2017.json ###### script generation
xml_json.py ###### script
Connect voc207 / train_ Jpegimages and voc2007 / Val_ The pictures in jpegimages are respectively placed in coco/train2017 and coco/val2017 folders
Mr. Cheng training set instances_train2017.json file
For xml_json.py (under datasets path):
"""
Created on Tue Jun 12 10:24:36 2018
take voc Format conversion json Format for caffe2 of detectron Training of
stay detectron in voc_2007_train.json and voc_2007_val.json in categories The order of must be consistent
Therefore, it is best to determine in advance category The order of writing in category_set in
@author: yantianwang
"""
import xml.etree.ElementTree as ET
import os
import json
import collections
coco = dict()
coco['images'] = []
coco['type'] = 'instances'
coco['annotations'] = []
coco['categories'] = []
#category_set = dict()
image_set = set()
image_id = 2017000001 #train:2018xxx; val:2019xxx; test:2020xxx
category_item_id = 0
annotation_id = 0
#category_set = ['open','close',"mopen","mclose"]
category_set = ['mushroom']
'''
def addCatItem(name):
global category_item_id
category_item = dict()
category_item['supercategory'] = 'none'
category_item_id += 1
category_item['id'] = category_item_id
category_item['name'] = name
coco['categories'].append(category_item)
category_set[name] = category_item_id
return category_item_id
'''
def addCatItem(name):
'''
increase json In format categories part
'''
global category_item_id
category_item = collections.OrderedDict()
category_item['supercategory'] = 'none'
category_item['id'] = category_item_id
category_item['name'] = name
coco['categories'].append(category_item)
category_item_id += 1
def addImgItem(file_name, size):
global image_id
if file_name is None:
raise Exception('Could not find filename tag in xml file.')
if size['width'] is None:
raise Exception('Could not find width tag in xml file.')
if size['height'] is None:
raise Exception('Could not find height tag in xml file.')
#image_item = dict() #In a certain order, collections OrderedDict()
image_item = collections.OrderedDict()
print(file_name,"*******")
# jpg_name = os.path.splitext(file_name)[0]+'.png'
jpg_name = file_name
image_item['file_name'] = jpg_name
image_item['width'] = size['width']
image_item['height'] = size['height']
image_item['id'] = image_id
coco['images'].append(image_item)
image_set.add(jpg_name)
image_id = image_id+1
return image_id
def addAnnoItem(object_name, image_id, category_id, bbox):
global annotation_id
#annotation_item = dict()
annotation_item = collections.OrderedDict()
annotation_item['segmentation'] = []
seg = []
# bbox[] is x,y,w,h
# left_top
seg.append(bbox[0])
seg.append(bbox[1])
# left_bottom
seg.append(bbox[0])
seg.append(bbox[1] + bbox[3])
# right_bottom
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1] + bbox[3])
# right_top
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1])
annotation_item['segmentation'].append(seg)
annotation_item['area'] = bbox[2] * bbox[3]
annotation_item['iscrowd'] = 0
annotation_item['image_id'] = image_id
annotation_item['bbox'] = bbox
annotation_item['category_id'] = category_id
annotation_item['id'] = annotation_id
annotation_item['ignore'] = 0
annotation_id += 1
coco['annotations'].append(annotation_item)
def parseXmlFiles(xml_path):
xmllist = os.listdir(xml_path)
xmllist.sort()
for f in xmllist:
if not f.endswith('.xml'):
continue
bndbox = dict()
size = dict()
current_image_id = None
current_category_id = None
file_name = None
size['width'] = None
size['height'] = None
size['depth'] = None
xml_file = os.path.join(xml_path, f)
print(xml_file)
tree = ET.parse(xml_file)
root = tree.getroot() #Grab root node element
if root.tag != 'annotation': #Root node label
raise Exception('pascal voc xml root element should be annotation, rather than {}'.format(root.tag))
# elem is <folder>, <filename>, <size>, <object>
for elem in root:
current_parent = elem.tag
current_sub = None
object_name = None
#elem.tag, elem.attrib,elem.text
if elem.tag == 'folder':
continue
if elem.tag == 'filename':
file_name = elem.text
if file_name in category_set:
raise Exception('file_name duplicated')
# add img item only after parse <size> tag
elif current_image_id is None and file_name is not None and size['width'] is not None:
if file_name not in image_set:
current_image_id = addImgItem(file_name, size)#Picture information
print('add image with {} and {}'.format(file_name, size))
else:
raise Exception('duplicated image: {}'.format(file_name))
# subelem is <width>, <height>, <depth>, <name>, <bndbox>
for subelem in elem:
bndbox['xmin'] = None
bndbox['xmax'] = None
bndbox['ymin'] = None
bndbox['ymax'] = None
current_sub = subelem.tag
if current_parent == 'object' and subelem.tag == 'name':
object_name = subelem.text
#if object_name not in category_set:
# current_category_id = addCatItem(object_name)
#else:
#current_category_id = category_set[object_name]
current_category_id = category_set.index(object_name) #index starts from 0 by default, but json files start from 1, so + 1
elif current_parent == 'size':
if size[subelem.tag] is not None:
raise Exception('xml structure broken at size tag.')
size[subelem.tag] = int(subelem.text)
# option is <xmin>, <ymin>, <xmax>, <ymax>, when subelem is <bndbox>
for option in subelem:
if current_sub == 'bndbox':
if bndbox[option.tag] is not None:
raise Exception('xml structure corrupted at bndbox tag.')
bndbox[option.tag] = int(option.text)
# only after parse the <object> tag
if bndbox['xmin'] is not None:
if object_name is None:
raise Exception('xml structure broken at bndbox tag')
if current_image_id is None:
raise Exception('xml structure broken at bndbox tag')
if current_category_id is None:
raise Exception('xml structure broken at bndbox tag')
bbox = []
# x
bbox.append(bndbox['xmin'])
# y
bbox.append(bndbox['ymin'])
# w
bbox.append(bndbox['xmax'] - bndbox['xmin'])
# h
bbox.append(bndbox['ymax'] - bndbox['ymin'])
print(
'add annotation with {},{},{},{}'.format(object_name, current_image_id-1, current_category_id, bbox))
addAnnoItem(object_name, current_image_id-1, current_category_id, bbox)
#categories section
for categoryname in category_set:
addCatItem(categoryname)
if __name__ == '__main__':
xml_path = 'VOC2007/val_annotations'
json_file = './coco/annotations/instances_val2017.json'
parseXmlFiles(xml_path)
json.dump(coco, open(json_file, 'w'))Make modifications
The first is the dataset category. I only have mushroom here

Then there are the xml file and the output json file path

Start running $python3 XML after_ json. py
After running successfully in coco/
annotations generate instances_train2017.json
Mr. Cheng training set instances_val2017.json file
For xml_json.py (under the datasets path)
The first is the dataset category. I only have mushroom here

Then there are the xml file and the output json file path

Start running $python3 XML after_ json. py
After running successfully in coco/
annotations generate instances_val2017.json.
So far, the coco data set has been made.
4 data set test
Because data sets are critical, let's test the data sets we have made
I wrote a script dataset_test.py is placed in the detectron2 folder:
import os
import cv2
import logging
from collections import OrderedDict
import detectron2.utils.comm as comm
from detectron2.utils.visualizer import Visualizer
from detectron2.checkpoint import DetectionCheckpointer
from detectron2.config import get_cfg
from detectron2.data import DatasetCatalog, MetadataCatalog
from detectron2.data.datasets.coco import load_coco_json
from detectron2.engine import DefaultTrainer, default_argument_parser, default_setup, launch
from detectron2.evaluation import COCOEvaluator, verify_results
from detectron2.modeling import GeneralizedRCNNWithTTA
# Dataset path
DATASET_ROOT = './datasets/coco'
ANN_ROOT = os.path.join(DATASET_ROOT, 'annotations')
TRAIN_PATH = os.path.join(DATASET_ROOT, 'train2017')
VAL_PATH = os.path.join(DATASET_ROOT, 'val2017')
TRAIN_JSON = os.path.join(ANN_ROOT, 'instances_train2017.json')
#VAL_JSON = os.path.join(ANN_ROOT, 'val.json')
VAL_JSON = os.path.join(ANN_ROOT, 'instances_val2017.json')
CLASS_NAMES =['mushroom']
# Dataset category metadata
DATASET_CATEGORIES = [
# {"name": "background", "id": 0, "isthing": 1, "color": [220, 20, 60]},
{"name": "mushroom", "id": 0, "isthing": 1, "color": [219, 142, 185]},
]
# Subset of dataset
PREDEFINED_SPLITS_DATASET = {
"train_2019": (TRAIN_PATH, TRAIN_JSON),
"val_2019": (VAL_PATH, VAL_JSON),
}
def register_dataset():
"""
purpose: register all splits of dataset with PREDEFINED_SPLITS_DATASET
"""
for key, (image_root, json_file) in PREDEFINED_SPLITS_DATASET.items():
register_dataset_instances(name=key,
metadate=get_dataset_instances_meta(),
json_file=json_file,
image_root=image_root)
def get_dataset_instances_meta():
"""
purpose: get metadata of dataset from DATASET_CATEGORIES
return: dict[metadata]
"""
thing_ids = [k["id"] for k in DATASET_CATEGORIES if k["isthing"] == 1]
thing_colors = [k["color"] for k in DATASET_CATEGORIES if k["isthing"] == 1]
# assert len(thing_ids) == 2, len(thing_ids)
thing_dataset_id_to_contiguous_id = {k: i for i, k in enumerate(thing_ids)}
thing_classes = [k["name"] for k in DATASET_CATEGORIES if k["isthing"] == 1]
ret = {
"thing_dataset_id_to_contiguous_id": thing_dataset_id_to_contiguous_id,
"thing_classes": thing_classes,
"thing_colors": thing_colors,
}
return ret
def register_dataset_instances(name, metadate, json_file, image_root):
"""
purpose: register dataset to DatasetCatalog,
register metadata to MetadataCatalog and set attribute
"""
DatasetCatalog.register(name, lambda: load_coco_json(json_file, image_root, name))
MetadataCatalog.get(name).set(json_file=json_file,
image_root=image_root,
evaluator_type="coco",
**metadate)
# Register datasets and metadata
def plain_register_dataset():
DatasetCatalog.register("train_2019", lambda: load_coco_json(TRAIN_JSON, TRAIN_PATH, "train_2019"))
MetadataCatalog.get("train_2019").set(thing_classes=CLASS_NAMES,
json_file=TRAIN_JSON,
image_root=TRAIN_PATH)
DatasetCatalog.register("val_2019", lambda: load_coco_json(VAL_JSON, VAL_PATH, "val_2019"))
MetadataCatalog.get("val_2019").set(thing_classes=CLASS_NAMES,
json_file=VAL_JSON,
image_root=VAL_PATH)
# Viewing dataset annotations
def checkout_dataset_annotation(name="train_2019"):
dataset_dicts = load_coco_json(TRAIN_JSON, TRAIN_PATH, name)
for d in dataset_dicts:
img = cv2.imread(d["file_name"])
visualizer = Visualizer(img[:, :, ::-1], metadata=MetadataCatalog.get(name), scale=1.5)
vis = visualizer.draw_dataset_dict(d)
cv2.imshow('show', vis.get_image()[:, :, ::-1])
cv2.waitKey(0)
register_dataset()
checkout_dataset_annotation()If your previous operation completely follows me, you only need to modify the dataset_test.py the following parts are sufficient.
1 label classification
Fill in according to your own classification, which should be consistent with the above XML_ json. The order of Py is always maintained

2 id and color mapping
Keep the same order as above

Start running test script
$ python3 dataset_test.py

If the operation is successful, you can sample and check the data set

Check and make sure the data set is complete.
Four model training
Because pytorch trains its own data sets, which involves the registration of data sets, the registration and loading of metadata sets. The process is cumbersome. Here, I wrote a script trainsample with reference to the official sample Py placed in model_ Under the train folder.
import os
import cv2
import logging
from collections import OrderedDict
import detectron2.utils.comm as comm
from detectron2.utils.visualizer import Visualizer
from detectron2.checkpoint import DetectionCheckpointer
from detectron2.config import get_cfg
from detectron2.data import DatasetCatalog, MetadataCatalog
from detectron2.data.datasets.coco import load_coco_json
from detectron2.engine import DefaultTrainer, default_argument_parser, default_setup, launch
from detectron2.evaluation import COCOEvaluator, verify_results
from detectron2.modeling import GeneralizedRCNNWithTTA
# Dataset path
DATASET_ROOT = '../datasets/coco'
ANN_ROOT = os.path.join(DATASET_ROOT, 'annotations')
TRAIN_PATH = os.path.join(DATASET_ROOT, 'train2017')
VAL_PATH = os.path.join(DATASET_ROOT, 'val2017')
TRAIN_JSON = os.path.join(ANN_ROOT, 'instances_train2017.json')
#VAL_JSON = os.path.join(ANN_ROOT, 'val.json')
VAL_JSON = os.path.join(ANN_ROOT, 'instances_val2017.json')
CLASS_NAMES =['mushroom']
# Dataset category metadata
DATASET_CATEGORIES = [
# {"name": "background", "id": 0, "isthing": 1, "color": [220, 20, 60]},
{"name": "mushroom", "id": 0, "isthing": 1, "color": [219, 142, 185]},
]
# Subset of dataset
PREDEFINED_SPLITS_DATASET = {
"train_2019": (TRAIN_PATH, TRAIN_JSON),
"val_2019": (VAL_PATH, VAL_JSON),
}
def register_dataset():
"""
purpose: register all splits of dataset with PREDEFINED_SPLITS_DATASET
"""
for key, (image_root, json_file) in PREDEFINED_SPLITS_DATASET.items():
register_dataset_instances(name=key,
metadate=get_dataset_instances_meta(),
json_file=json_file,
image_root=image_root)
def get_dataset_instances_meta():
"""
purpose: get metadata of dataset from DATASET_CATEGORIES
return: dict[metadata]
"""
thing_ids = [k["id"] for k in DATASET_CATEGORIES if k["isthing"] == 1]
thing_colors = [k["color"] for k in DATASET_CATEGORIES if k["isthing"] == 1]
# assert len(thing_ids) == 2, len(thing_ids)
thing_dataset_id_to_contiguous_id = {k: i for i, k in enumerate(thing_ids)}
thing_classes = [k["name"] for k in DATASET_CATEGORIES if k["isthing"] == 1]
ret = {
"thing_dataset_id_to_contiguous_id": thing_dataset_id_to_contiguous_id,
"thing_classes": thing_classes,
"thing_colors": thing_colors,
}
return ret
def register_dataset_instances(name, metadate, json_file, image_root):
"""
purpose: register dataset to DatasetCatalog,
register metadata to MetadataCatalog and set attribute
"""
DatasetCatalog.register(name, lambda: load_coco_json(json_file, image_root, name))
MetadataCatalog.get(name).set(json_file=json_file,
image_root=image_root,
evaluator_type="coco",
**metadate)
# Register datasets and metadata
def plain_register_dataset():
DatasetCatalog.register("train_2019", lambda: load_coco_json(TRAIN_JSON, TRAIN_PATH, "train_2019"))
MetadataCatalog.get("train_2019").set(thing_classes=CLASS_NAMES,
json_file=TRAIN_JSON,
image_root=TRAIN_PATH)
DatasetCatalog.register("val_2019", lambda: load_coco_json(VAL_JSON, VAL_PATH, "val_2019"))
MetadataCatalog.get("val_2019").set(thing_classes=CLASS_NAMES,
json_file=VAL_JSON,
image_root=VAL_PATH)
class Trainer(DefaultTrainer):
@classmethod
def build_evaluator(cls, cfg, dataset_name, output_folder=None):
if output_folder is None:
output_folder = os.path.join(cfg.OUTPUT_DIR, "inference")
return COCOEvaluator(dataset_name, cfg, distributed=False, output_dir=output_folder)
@classmethod
def test_with_TTA(cls, cfg, model):
logger = logging.getLogger("detectron2.trainer")
# In the end of training, run an evaluation with TTA
# Only support some R-CNN models.
logger.info("Running inference with test-time augmentation ...")
model = GeneralizedRCNNWithTTA(cfg, model)
evaluators = [
cls.build_evaluator(
cfg, name, output_folder=os.path.join(cfg.OUTPUT_DIR, "inference_TTA")
)
for name in cfg.DATASETS.TEST
]
res = cls.test(cfg, model, evaluators)
res = OrderedDict({k + "_TTA": v for k, v in res.items()})
return res
def setup(args):
"""
Create configs and perform basic setups.
"""
cfg = get_cfg() # Copy default config copy
args.config_file = "./config.yaml"
cfg.merge_from_file(args.config_file) # Overwrite configuration from config file
cfg.merge_from_list(args.opts) # Override configuration from CLI parameters
# Change configuration parameters
cfg.DATASETS.TRAIN = ("train_2019",)
cfg.DATASETS.TEST = ("val_2019",)
cfg.DATALOADER.NUM_WORKERS = 2 # Single thread
# cfg.INPUT.MAX_SIZE_TRAIN = 400
# cfg.INPUT.MAX_SIZE_TEST = 400
# cfg.INPUT.MIN_SIZE_TRAIN = (160,)
# cfg.INPUT.MIN_SIZE_TEST = 160
cfg.MODEL.DEVICE = 'cpu'
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1# Number of categories
cfg.MODEL.WEIGHTS = "./model_final.pth" # Pre training model weight
cfg.SOLVER.IMS_PER_BATCH = 6 # batch_size=2; iters_in_one_epoch = dataset_imgs/batch_size
ITERS_IN_ONE_EPOCH = int(118/ cfg.SOLVER.IMS_PER_BATCH)
# (ITERS_IN_ONE_EPOCH * ) - 1 # 12 epochs
cfg.SOLVER.MAX_ITER = 640
cfg.SOLVER.BASE_LR = 0.002
cfg.SOLVER.MOMENTUM = 0.9
cfg.SOLVER.WEIGHT_DECAY = 0.0001
cfg.SOLVER.WEIGHT_DECAY_NORM = 0.0
cfg.SOLVER.GAMMA = 0.1
cfg.SOLVER.STEPS = (500,)
cfg.SOLVER.WARMUP_FACTOR = 1.0 / 1000
cfg.SOLVER.WARMUP_ITERS = 300
cfg.SOLVER.WARMUP_METHOD = "linear"
cfg.SOLVER.CHECKPOINT_PERIOD = ITERS_IN_ONE_EPOCH - 1
cfg.OUTPUT_DIR = "./output_trainsample/"
cfg.freeze()
default_setup(cfg, args)
return cfg
def main(args):
cfg = setup(args)
print(cfg)
# Register dataset
register_dataset()
if args.eval_only:
model = Trainer.build_model(cfg)
DetectionCheckpointer(model, save_dir=cfg.OUTPUT_DIR).resume_or_load(
cfg.MODEL.WEIGHTS, resume=args.resume
)
res = Trainer.test(cfg, model)
if comm.is_main_process():
verify_results(cfg, res)
return res
trainer = Trainer(cfg)
trainer.resume_or_load(resume=args.resume)
return trainer.train()
if __name__ == "__main__":
args = default_argument_parser().parse_args()
print("Command Line Args:", args)
launch(
main,
args.num_gpus,
num_machines=args.num_machines,
machine_rank=args.machine_rank,
dist_url=args.dist_url,
args=(args,),
)
1. Modification of training documents
If your data set making process is consistent with mine, you only need to make trainsample Py modify the following:
1 label classification
Fill in according to your own classification, which should be consistent with the above XML_ json. The order of Py is always maintained

2 id and color mapping
Keep the same order as above

3 configuration file

args.config_file = followed by the path of the configuration file. In detectron2, the configuration file is placed in detectron2 / configurations

What I want to achieve here is target detection, using the configuration file in the coco detection folder

I use my own configuration file because I have trained many times here
4 relevant parameters

The first item is the device. Here is the cpu. cpu is not specified. cuda is the default
The second item is the number of categories, which can be modified according to the total number of your label categories
The third item is the pre training weight. You can comment out the first training, use the default weight of the configuration file, and modify it to your own weight after repeated training.

cfg.SOLVER.IMS_PER_BATCH is the batchsize set according to the performance of your computer
ITERS_ IN_ ONE_ 118 in epoch = int (118 / CFG. Solver. Ims_per_batch) is the total number of test sets, so ITERS_IN_ONE_EPOCH represents the number of iterations required for one epoch
cfg.SOLVER.MAX_ITER represents the maximum number of iterations. You can set the number directly, but in order to make the epoch number an integer, it can be equal to (ITERS_IN_ONE_EPOCH * epoch number) – 1

cfg.SOLVER.STEPS is the number of running steps, which is no more than the maximum number of iterations

cfg.OUTPUT_DIR: model output path
Other parameters can be modified according to individual needs
This completes the training file configuration.
2 model training
Execute under the detectron2 path
$ python3 model_train/trainsample.py

During the training, the output_trainsample / generate multiple intermediate weights
Generate too many weights, you can know by yourself.
During training, you can open tensorboard to view training loss and related data.
$ tensorboard --logdir output_trainsample/
Five objective reasoning
After the training, it will be generated in the output folder (detectron2/output_trainsample folder here)
config.yaml and model_final.pth, which is the configuration file and weight file we finally get.

1 reasoning example
We use the previous demo file and the generated model for prediction.
Enter the detectron2/demo folder to run
$ python demo.py --config-file ../output_trainsample/config.yaml --input mushroom2.jpg --output mushroom2_out.jpg
--opts MODEL.DEVICE cpu MODEL.WEIGHTS ../output_trainsample/model_final.pth
--Config file configuration file
--Input input file. If folder / * is adopted, all pictures in the current folder can be input
--Output output file path, if not, will be displayed on the window
MODEL.DEVICE equipment: select the equipment according to the actual demand
MODEL.WEIGHTS of weights model
Prediction results:

2. Display and summary of prediction results



Conclusion: the trained model has good reasoning effect in the case of large difference between single target detection and multi-target background. In multi-target detection and high similarity of target background, it is prone to duplicate detection frames, waiting for subsequent optimization and modification.