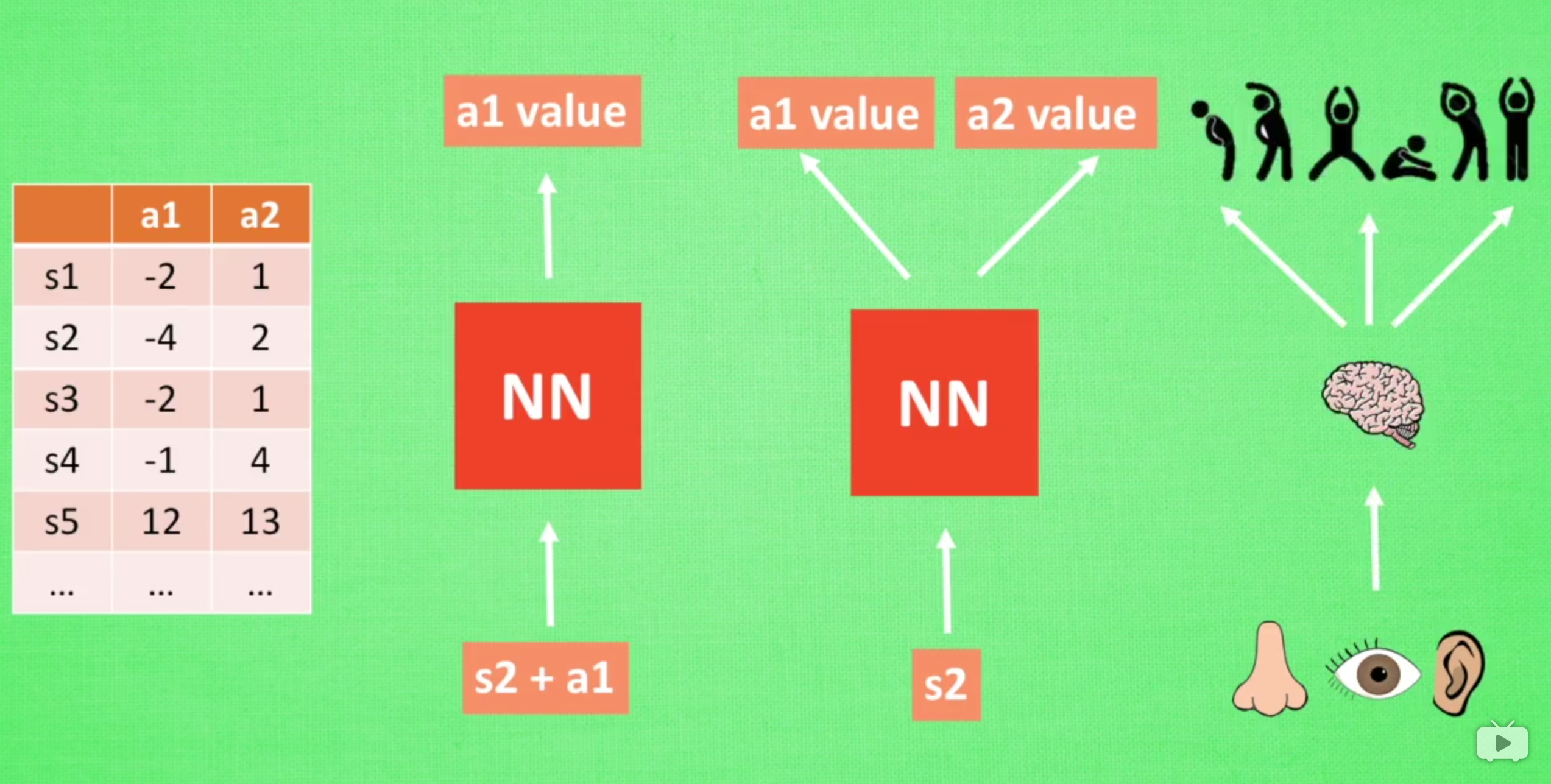
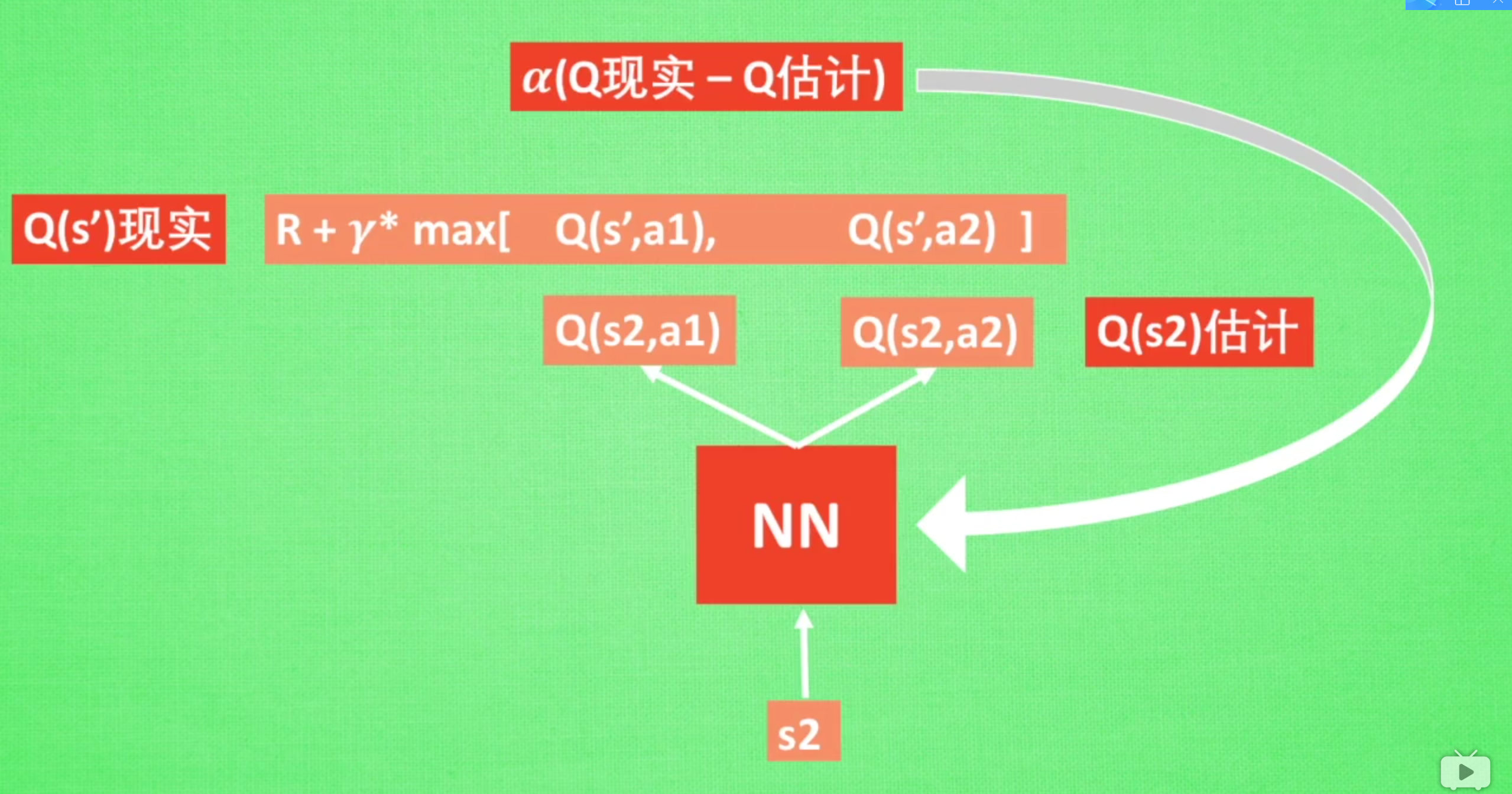
Using Q-learning algorithm to realize two-dimensional treasure hunt game
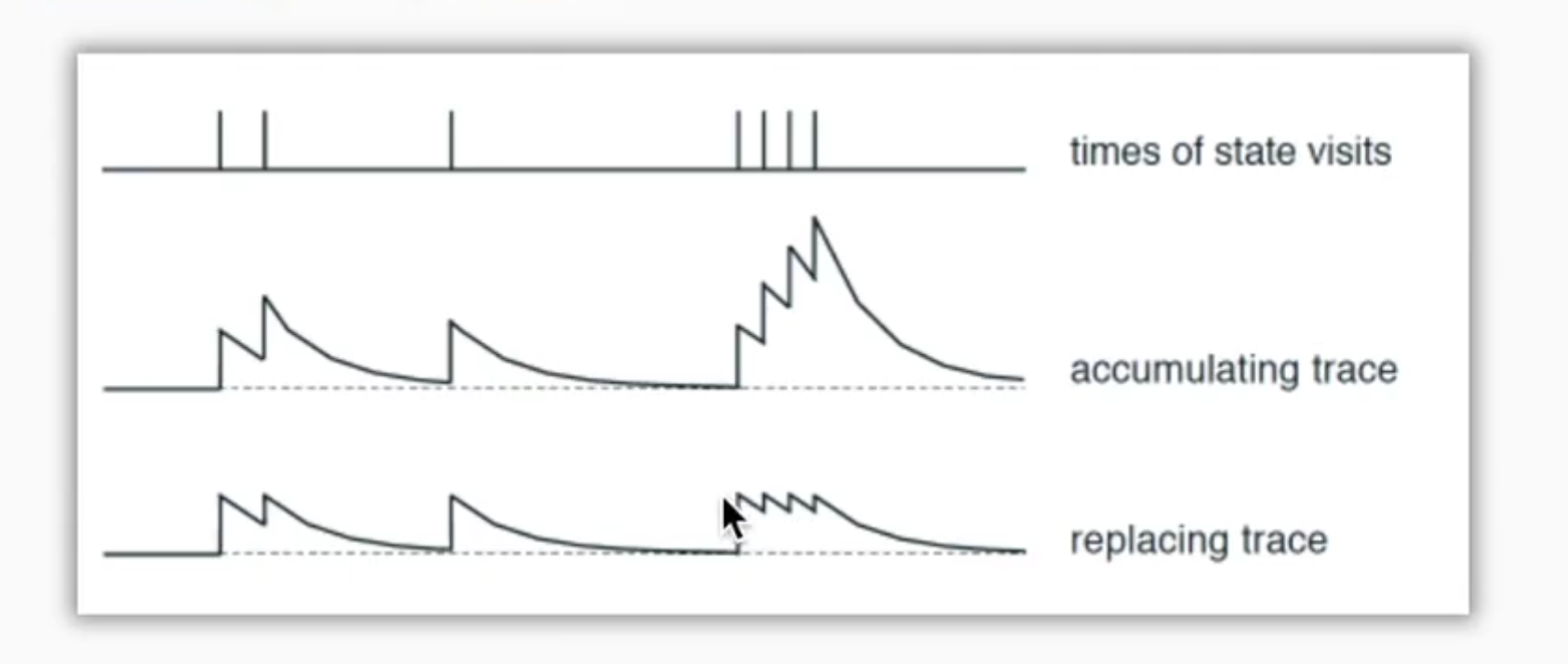
sarsa(lambda) algorithm in which lambda represents the importance of past experience
If lambda = 0, Sarsa lambda is Sarsa, only update the last step before getting reward
If lambda = 1, sarsa lambda updates to get all the steps before reward

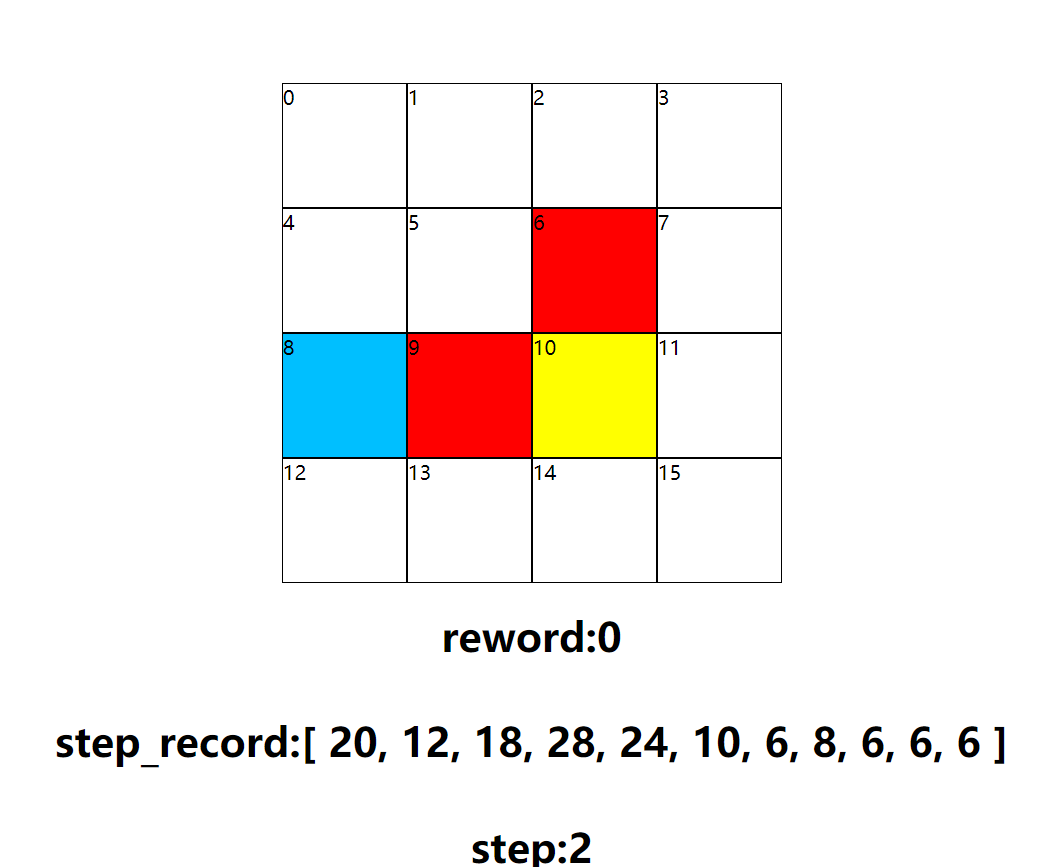
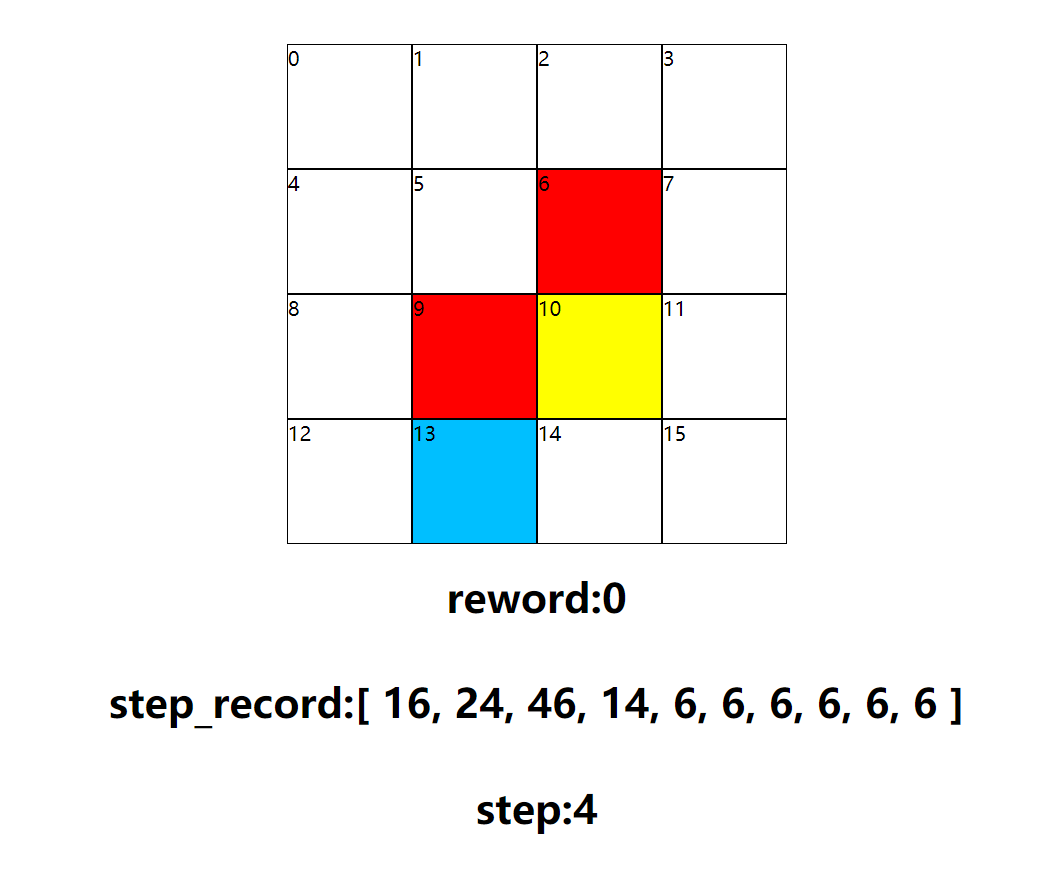
Game process

Several results show that the required path has been found effectively
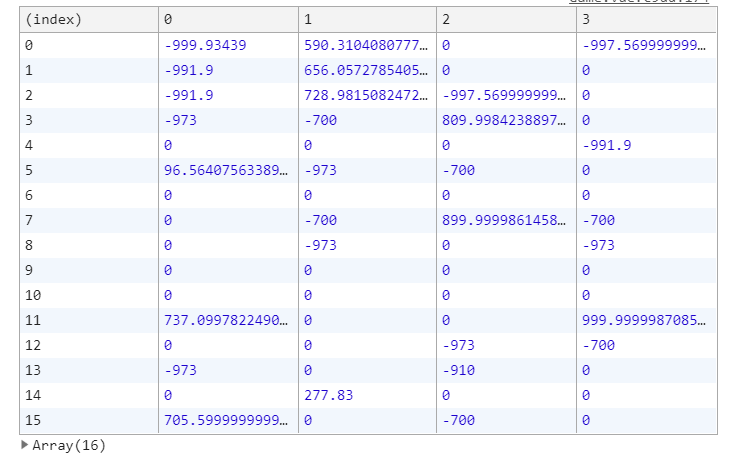
q table
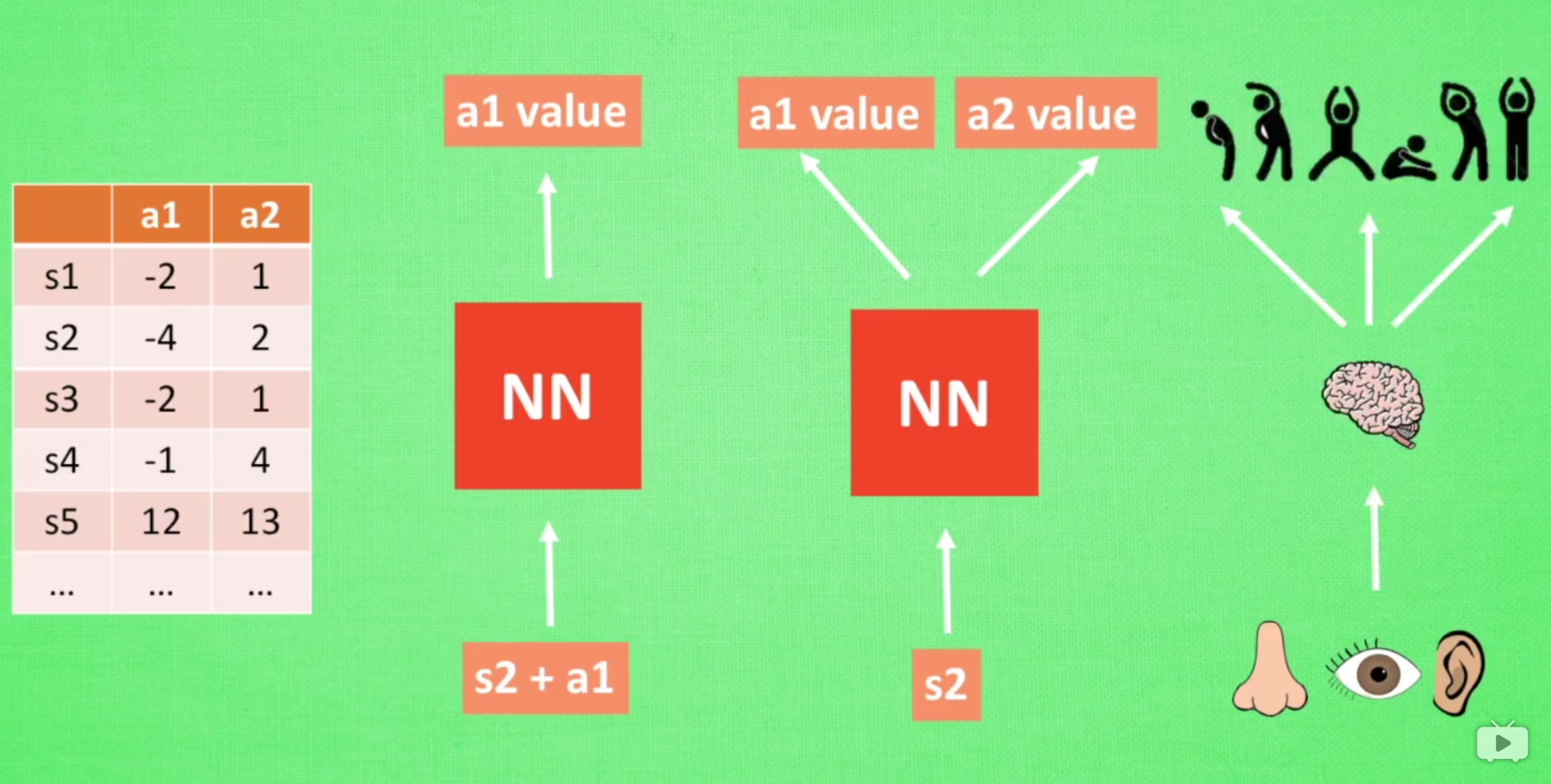
sarsa algorithm
This diagram shows the attenuation experienced. Generally, the third kind is chosen, which is not cumulative
Because there are many useless steps at the beginning, if they are accumulated, they will take up more
# Method 1: # self.eligibility_trace.loc[s, a] += 1 # Method 2: self.eligibility_trace.loc[s, :] *= 0 self.eligibility_trace.loc[s, a] = 1 # Q update self.q_table += self.lr * error * self.eligibility_trace # decay eligibility trace after update self.eligibility_trace *= self.gamma*self.lambda_
<template> <div class="main"> <div class="game"> <div v-for="row,index_row in mat"> <div v-for="cell,index_col in row" :class="getClass(cell)"> {{index_col*row.length+index_row}} </div> </div> </div> <h1>reword:{{reword}}</h1> <h1>step_record:{{step_record}}</h1> <h1>step:{{step}}</h1> </div> </template> <script> let classes = ['box', 'start', 'end', 'danger', 'reword'] // The corresponding value of different kinds of lattices let values = [0, 0, 1000, -1000, 500] // direction let dirs = [ [-1, 0], [0, 1], [1, 0], [0, -1], ] let width = 4 let height = 4 /** * 0 Common passable * 1 start * 2 End * 3 DANGER * 4 reward */ function getInitMat() { let init_mat = [ [1, 0, 0, 0], [0, 0, 3, 0], [0, 3, 4, 0], [0, 0, 0, 0], ] return init_mat } let alpha = .7 // Learning rate let gamma = .9 // Future reward attenuation value let epsilon = .1 // Proportion of random actions let train_time_inv = 100 // Action interval let qtable = Array.from(Array(width * height)).map(() => Array(width).fill(0)) function get_feedback(x, y, action, mat) { let s = x * width + height let nx = x + dirs[action][0] let ny = y + dirs[action][1] let reword = 0 if (nx < 0 || ny < 0 || nx >= height || ny >= width || mat[nx][ny] == 3 ) { // Cross border or dangerous reword = -1000 } else if (mat[nx][ny] == 4) { reword = 1000 } return [nx, ny, reword] } // Random return of values in an array function random_choice(arr) { let r = parseInt(arr.length * Math.random()) return arr[r] } function choice_action(x, y) { let all_actions = qtable[x * width + y] let d = 0 let maxv = 0 if (Math.random() < epsilon || all_actions.every(item => !item)) { d = parseInt(Math.random() * 4) } else { let maxv = Math.max(...all_actions) let arr = all_actions.reduce( (pre, cur, index) => { if (cur === maxv) { pre.push(index) } return pre }, [] ) // If more than one action has the same value, randomly select one action d = random_choice(arr) } return d } export default { data() { return { mat: getInitMat(), // current location x: 0, y: 0, // Accumulated reward value reword: 0, step: 0, // Control training inv: {}, testInv: {}, step_record: [] } }, name: "Game", methods: { getClass(n) { return 'box ' + classes[n] }, reset() { this.x = this.y = 0 this.mat = getInitMat() this.reword = 0 this.step = 0 }, // Start training start() { let d = choice_action(this.x, this.y) let [nx, ny, reword] = get_feedback(this.x, this.y, d, this.mat) console.log('x,y,d,nx,ny,reword ', this.x, this.y, d, nx, ny, reword) let s = this.x * width + this.y let ns = nx * width + ny let q_predict = qtable[s][d] let q_target if (nx >= 0 && ny >= 0 && nx < height && ny < width ) { q_target = reword + gamma * Math.max(...qtable[ns]) } else { // Out of bounds or error q_target = reword } qtable[s][d] += alpha * (q_target - q_predict) console.table(qtable) this.step++ if (nx < 0 || ny < 0 || nx >= height || ny >= width || this.mat[nx][ny] === 3 ) { this.reset() return } else if (this.mat[nx][ny] == 4) { this.step_record.push(this.step) this.reset() return } this.setMat(this.x, this.y, 0) this.setMat(nx, ny, 1) this.x = nx this.y = ny }, setMat(x, y, v) { this.$set(this.mat[x], y, v) }, train() { this.inv = setInterval( () => this.start(), train_time_inv, ) }, }, mounted() { this.train() } } </script> <style scoped> .main { width: 100%; height: 100%; display: flex; flex-direction: column; justify-content: center; align-items: center; } .box { box-sizing: border-box; border: 1px solid black; width: 100px; height: 100px; } .start { background: deepskyblue; } .end { background: blue; } .danger { background: red; } .reword { background: yellow; } .game { display: flex; /*flex-direction: column;*/ } .mat { display: flex; /*flex-direction: column;*/ } .qmat { display: flex; } </style>