First, why use Flume
In the previous experimental environment of HAWQ data warehouse, I used Sqoop to extract incremental data from MySQL database to HDFS, and then accessed it with the external table of HAWQ. This method only needs a small amount of configuration to complete the task of data extraction, but the drawback is also obvious, that is, real-time. Sqoop uses MapReduce to read and write data, and MapReduce is designed for batch scenarios with the goal of high throughput and little concern for low latency. As the experiment has done, the data are extracted incrementally and regularly once a day.Flume is a massive log collection, aggregation and transmission system that supports customizing various data senders in the log system for data collection. At the same time, Flume provides the ability to process data simply and write to various data recipients. Flume processes data in a streaming manner and can continue to run as an agent. When new data is available, Flume can get the data immediately and output it to the target, which can solve the real-time problem to a large extent.
Flume was originally just a log collector, but with the emergence of the flume-ng-sql-source plug-in, it became possible for Flume to collect data from relational databases. Following is a brief introduction to Flume and a detailed description of how to configure Flume to extract MySQL table data into HDFS in quasi-real time.
Introduction to Flume
1. The concept of Flume
Flume is a distributed log collection system, which collects data from various servers and sends it to designated places, such as HDFS. Simply speaking, flume collects logs. Its architecture is shown in Figure 1.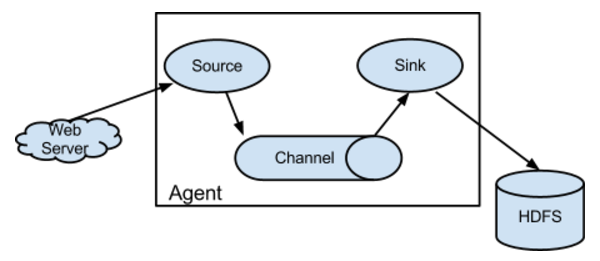
2. The concept of Event
It is necessary to introduce the concept of event in Flume first: the core of Flume is to collect data from data source s and send the collected data to the designated destination (sink). In order to ensure the success of the transport process, before sending to the destination (sink), the data will be cached (channel), and after the data really reaches the destination (sink), Flume will delete the cached data.In the whole process of data transmission, the flow is event, that is, transaction assurance is carried out at event level. So what is event? Event encapsulates the transmitted data, which is the basic unit of Flume data transmission. If it is a text file, it is usually a row of records. Event is also the basic unit of transactions. Event is a byte array from source to channel to sink, and can carry headers information. Event represents the smallest complete unit of data, coming from an external data source to an external destination.
3. Introduction to Flume Architecture
Flume is so amazing because of its own design, which is agent. Agent itself is a Java process running on the log collection node, which is called the server node. Agent contains three core components: source, channel and sink, similar to the structure of producer, warehouse and consumer.- Source: Source component is specially designed to collect data and can handle various types and formats of log data, including avro, thrift, exec, jms, spooling directory, netcat, sequence generator, syslog, http, legacy, customization.
- Channel: After the source component collects the data, it is temporarily stored in the channel, that is, the channel component is used to store the temporary data in the agent - simply cache the collected data, which can be stored in memory, jdbc, file and so on.
- Sink: sink component is a component used to send data to a destination, including hdfs, logger, avro, thrift, ipc, file, null, Hbase, solr, custom.
4. Operation mechanism of Flume
The core of Flume is an agent. This agent has two places to interact with the outside world. One is the source that receives data input, the other is the sink that outputs data. The sink is responsible for sending data to the designated destination outside. After the source receives the data, it sends the data to the channel. chanel as a data buffer temporarily stores the data. Then sink sends the data from the channel to a designated place, such as HDFS. Note: Channel will delete temporary data only after sink successfully sends out the data in channel. This mechanism guarantees the reliability and security of data transmission.Installation of Hadoop and Flume
My experiment was carried out on HDP 2.5.0. Flume was included in the HDP installation as long as the Flume service was configured. Installation steps of HDP“ HAWQ Technology Analysis (2) - Installation and Deployment"IV. Configuration and Testing
1. Establishing MySQL database tables
Establish test tables and add data.use test; create table wlslog (id int not null, time_stamp varchar(40), category varchar(40), type varchar(40), servername varchar(40), code varchar(40), msg varchar(40), primary key ( id ) ); insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(1,'apr-8-2014-7:06:16-pm-pdt','notice','weblogicserver','adminserver','bea-000365','server state changed to standby'); insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(2,'apr-8-2014-7:06:17-pm-pdt','notice','weblogicserver','adminserver','bea-000365','server state changed to starting'); insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(3,'apr-8-2014-7:06:18-pm-pdt','notice','weblogicserver','adminserver','bea-000365','server state changed to admin'); insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(4,'apr-8-2014-7:06:19-pm-pdt','notice','weblogicserver','adminserver','bea-000365','server state changed to resuming'); insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(5,'apr-8-2014-7:06:20-pm-pdt','notice','weblogicserver','adminserver','bea-000361','started weblogic adminserver'); insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(6,'apr-8-2014-7:06:21-pm-pdt','notice','weblogicserver','adminserver','bea-000365','server state changed to running'); insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(7,'apr-8-2014-7:06:22-pm-pdt','notice','weblogicserver','adminserver','bea-000360','server started in running mode'); commit;
2. Establishing relevant directories and files
(1) Create a local status filemkdir -p /var/lib/flume cd /var/lib/flume touch sql-source.status chmod -R 777 /var/lib/flume
(2) Establishing HDFS Target Directory
hdfs dfs -mkdir -p /flume/mysql hdfs dfs -chmod -R 777 /flume/mysql
3. Preparing JAR packages
From http://book2s.com/java/jar/f/flume-ng-sql-source/download-flume-ng-sql-source-1.3.7.html Download the flume-ng-sql-source-1.3.7.jar file and copy it to the Flume library directory.Copy the MySQL JDBC driver JAR package to the Flume library directory as well.cp flume-ng-sql-source-1.3.7.jar /usr/hdp/current/flume-server/lib/
cp mysql-connector-java-5.1.17.jar /usr/hdp/current/flume-server/lib/mysql-connector-java.jar
4. Establishing HAWQ External Table
create external table ext_wlslog
(id int,
time_stamp varchar(40),
category varchar(40),
type varchar(40),
servername varchar(40),
code varchar(40),
msg varchar(40)
) location ('pxf://mycluster/flume/mysql?profile=hdfstextmulti') format 'csv' (quote=e'"'); 5. Configure Flume
Configure the following properties in Ambari-> Flume-> Configs-> flume.conf:Flume specifies Source, Channel and Link-related configurations in the flume.conf file, and the attributes are described in Table 1.agent.channels.ch1.type = memory agent.sources.sql-source.channels = ch1 agent.channels = ch1 agent.sinks = HDFS agent.sources = sql-source agent.sources.sql-source.type = org.keedio.flume.source.SQLSource agent.sources.sql-source.connection.url = jdbc:mysql://172.16.1.127:3306/test agent.sources.sql-source.user = root agent.sources.sql-source.password = 123456 agent.sources.sql-source.table = wlslog agent.sources.sql-source.columns.to.select = * agent.sources.sql-source.incremental.column.name = id agent.sources.sql-source.incremental.value = 0 agent.sources.sql-source.run.query.delay=5000 agent.sources.sql-source.status.file.path = /var/lib/flume agent.sources.sql-source.status.file.name = sql-source.status agent.sinks.HDFS.channel = ch1 agent.sinks.HDFS.type = hdfs agent.sinks.HDFS.hdfs.path = hdfs://mycluster/flume/mysql agent.sinks.HDFS.hdfs.fileType = DataStream agent.sinks.HDFS.hdfs.writeFormat = Text agent.sinks.HDFS.hdfs.rollSize = 268435456 agent.sinks.HDFS.hdfs.rollInterval = 0 agent.sinks.HDFS.hdfs.rollCount = 0
attribute | describe |
agent.channels.ch1.type | channel Type of Agent |
agent.sources.sql-source.channels | channel name corresponding to Source |
agent.channels | Channel name |
agent.sinks | Sink name |
agent.sources | Source name |
agent.sources.sql-source.type | Source type |
agent.sources.sql-source.connection.url | Database URL |
agent.sources.sql-source.user | Database username |
agent.sources.sql-source.password | Database password |
agent.sources.sql-source.table | Database table name |
agent.sources.sql-source.columns.to.select | Query columns |
agent.sources.sql-source.incremental.column.name | Incremental Listing |
agent.sources.sql-source.incremental.value | Incremental Initial Value |
agent.sources.sql-source.run.query.delay | The interval between queries initiated in milliseconds |
agent.sources.sql-source.status.file.path | Status file path |
agent.sources.sql-source.status.file.name | Status file name |
agent.sinks.HDFS.channel | channel name corresponding to Sink |
agent.sinks.HDFS.type | Sink type |
agent.sinks.HDFS.hdfs.path | Sink Path |
agent.sinks.HDFS.hdfs.fileType | File type of stream data |
agent.sinks.HDFS.hdfs.writeFormat | Data Writing Format |
agent.sinks.HDFS.hdfs.rollSize | Target file rotation size in bytes |
agent.sinks.HDFS.hdfs.rollInterval | How long does the HDFS sink interval scroll the temporary file into the final target file in seconds; if set to 0, it means that the file is not scrolled according to the time |
agent.sinks.HDFS.hdfs.rollCount | When the events data reaches that number, scroll the temporary file into the target file; if set to 0, it means that the files are not scrolled according to the events data. |
Table 1
6. Running Flume Agent
Save the previous settings and restart the Flume service, as shown in Figure 2.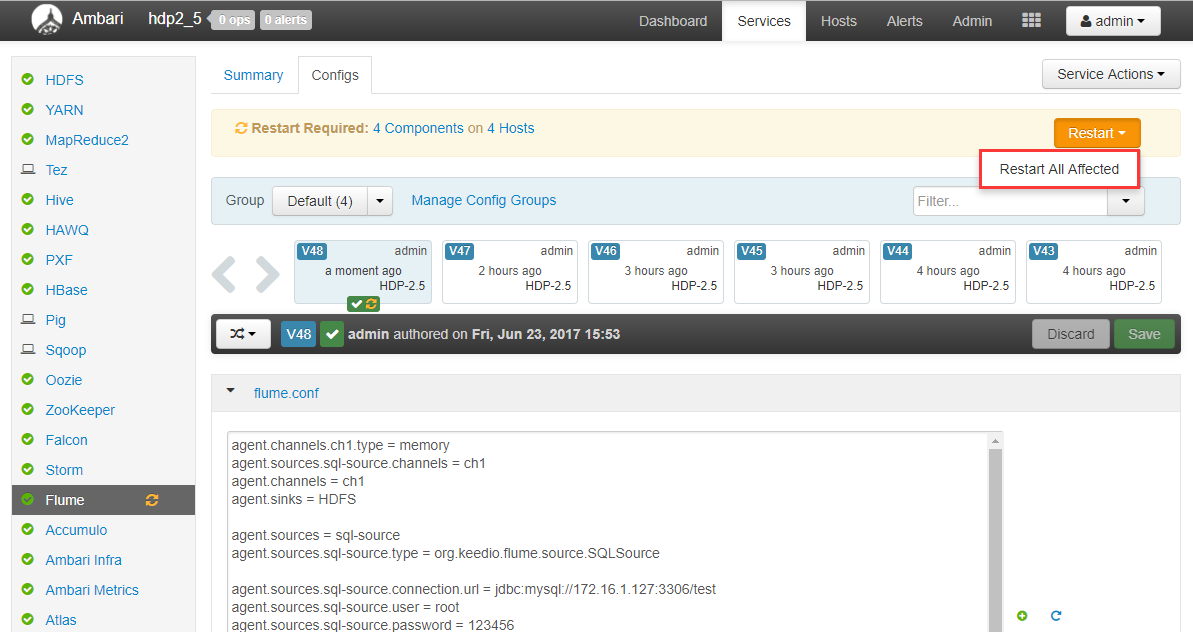
After restart, the status file has recorded the latest id value of 7, as shown in Figure 3.

Look at the target path and generate a temporary file with seven records, as shown in Figure 4.

Query the HAWQ external table, and the result also has seven pieces of data, as shown in Figure 5.
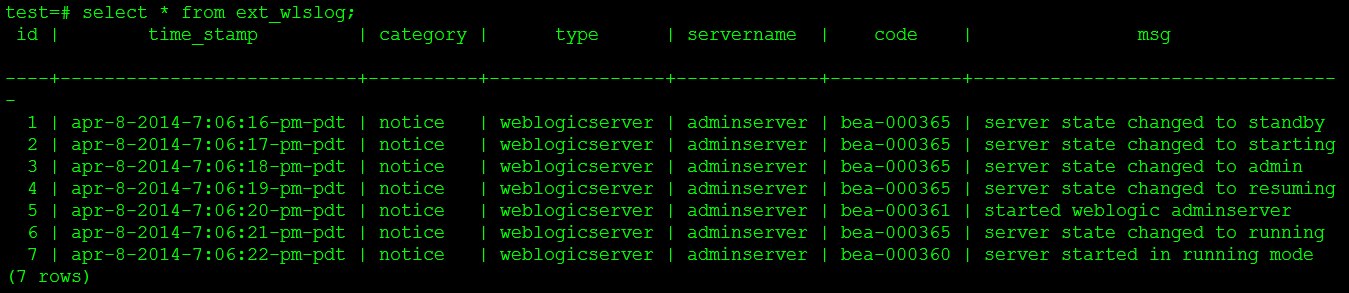
At this point, the initial data extraction has been completed.
7. Test quasi-real-time incremental extraction
3 records with id of 8, 9 and 10 were added to the source table.5 seconds later, the HAWQ external table is queried. As can be seen from Figure 6, all 10 data have been queried, and the quasi-real-time incremental extraction is successful.use test; insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(8,'apr-8-2014-7:06:22-pm-pdt','notice','weblogicserver','adminserver','bea-000360','server started in running mode'); insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(9,'apr-8-2014-7:06:22-pm-pdt','notice','weblogicserver','adminserver','bea-000360','server started in running mode'); insert into wlslog(id,time_stamp,category,type,servername,code,msg) values(10,'apr-8-2014-7:06:22-pm-pdt','notice','weblogicserver','adminserver','bea-000360','server started in running mode'); commit;
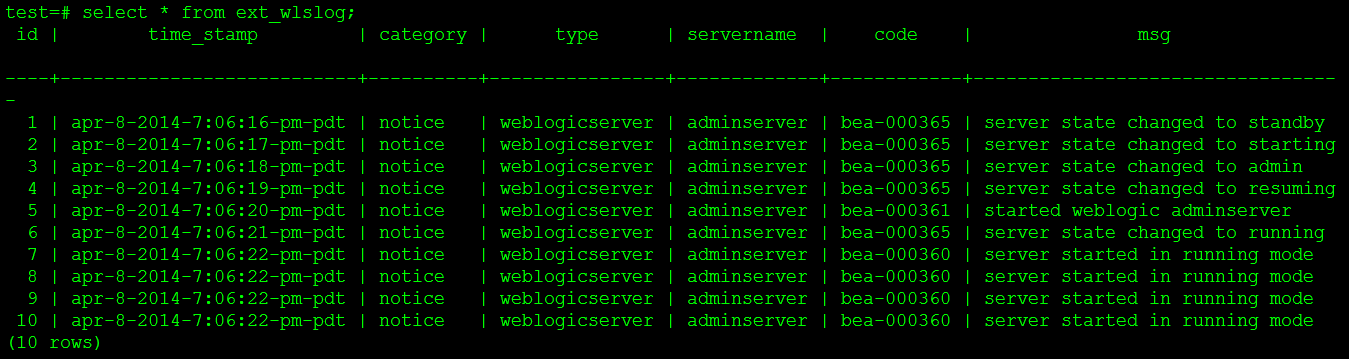
5. Advantages and disadvantages of the scheme
The biggest advantage of using Flume to collect relational database table data is simple configuration and no programming. Compared with the complexity of tungsten-replicator, Flume has no difficulty in configuring the relevant attributes of source, channel and sink in the flume.conf file. Compared with the popular canal, it is not flexible enough, but after all, one line of code does not need to be written.The shortcomings of this scheme are as prominent as its advantages, mainly reflected in the following aspects.
- Queries are executed on the source library, which is intrusive.
- Incremental polling can only achieve quasi-real-time, and the shorter polling interval, the greater the impact on source and repository.
- Only new data can be identified, and deletion and update can not be detected.
- The source library is required to have fields that represent increments.
Reference resources:
Flume Architecture and Application IntroductionStreaming MySQL Database Table Data to HDFS with Flume
how to read data from oracle using FLUME to kafka broker
https://github.com/keedio/flume-ng-sql-source