Starting with Hudi version 0.10.0, we are pleased to introduce the support of advanced data layout optimization technology called Z-Order and Hilbert space filling curve in the database field.
1. Background
Amazon EMR team recently published a very good article [1] showing how clustering data [2] can improve query performance. In order to better understand what happened and its relationship with space filling curve, let's study the setting of this article carefully.
This article compares two Apache Hudi tables (both from Amazon Reviews dataset [3]):
• non clustered amazon_reviews table (i.e. the data has not been reordered by any specific key) • amazon_reviews_clustered clustered table. When the data is clustered, the data is arranged in dictionary order (here we call this sort linear sort), and the sort column is star_rating,total_votes two columns (see figure below)

To demonstrate the improvement in query performance, perform the following queries on these two tables:


An important consideration to note here is that the query specifies two columns for sorting (star_rating and total_votes). Unfortunately, this is a key limitation of linear / dictionary sorting, and the value of sorting will be reduced if more columns are added.
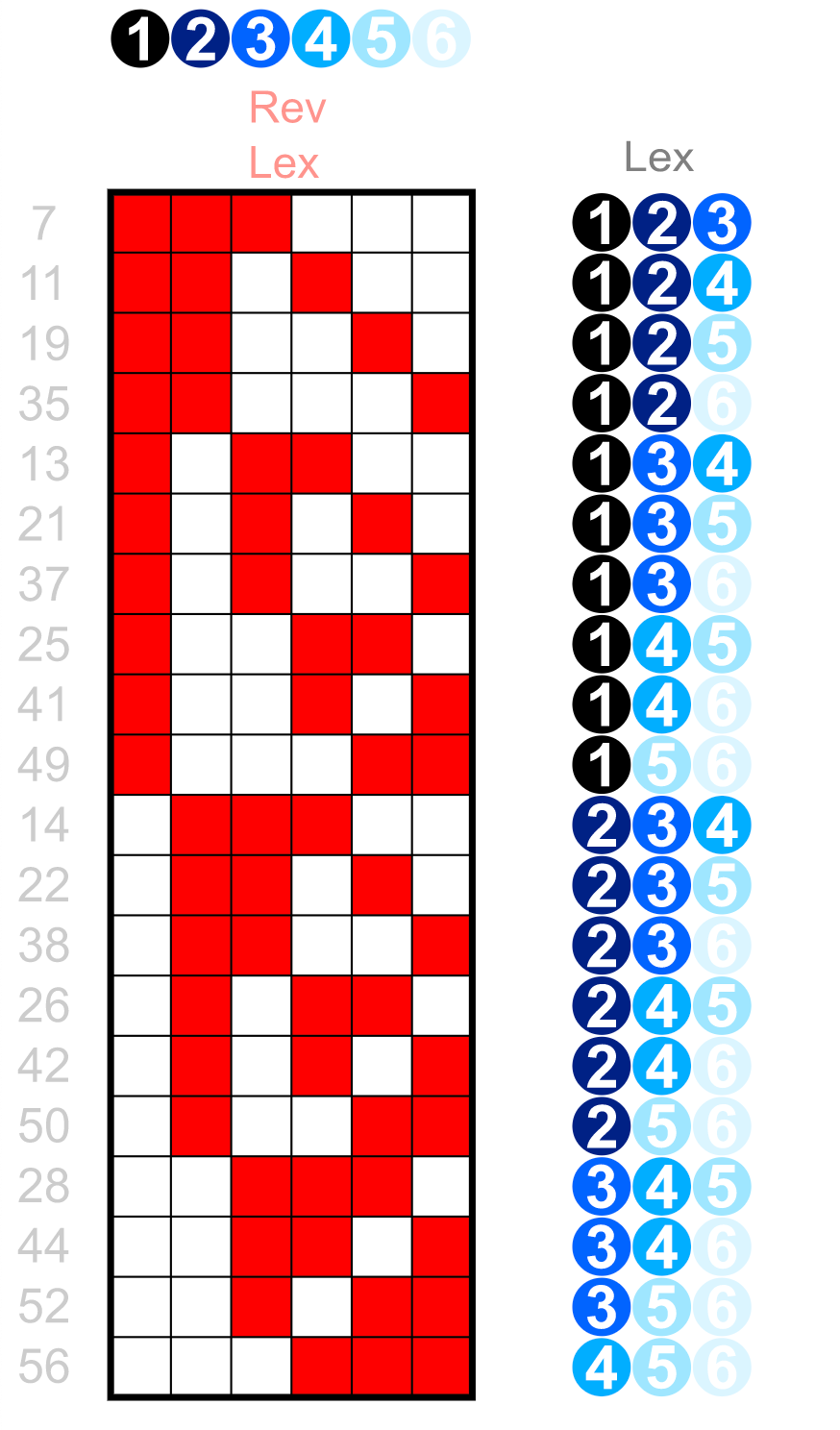
As can be seen from the above figure, for 3-tuple integers arranged in dictionary order, Only the first column can have key locality attributes for all records with the same value: for example, all records have values "1", "2" and "3" (in the first column), which are well clustered together. However, if you try to find all values "5" in the third column "You will find that these values are scattered everywhere, there is no locality at all, and the filtering effect is very poor.
The key factor to improve query performance is Locality: it can significantly reduce the search space and the number of files to be scanned and parsed.
But does this mean that if we filter anything other than the first (or more accurately, the prefix) of the column sorted by the table, our query is destined to be fully scanned? Not exactly. Locality is also an attribute enabled by space filling curves when enumerating multidimensional spaces (records in our table can be represented as points in N-dimensional space, where N is the number of columns in our table)
So how does it work? Let's take the Z curve as an example: the z-order curve fitting the two-dimensional plane is as follows:

You can see that by path, instead of simply sorting by one coordinate ("x") and then another coordinate, it is actually sorting them, as if the bits of these coordinates have been interleaved into a single value:
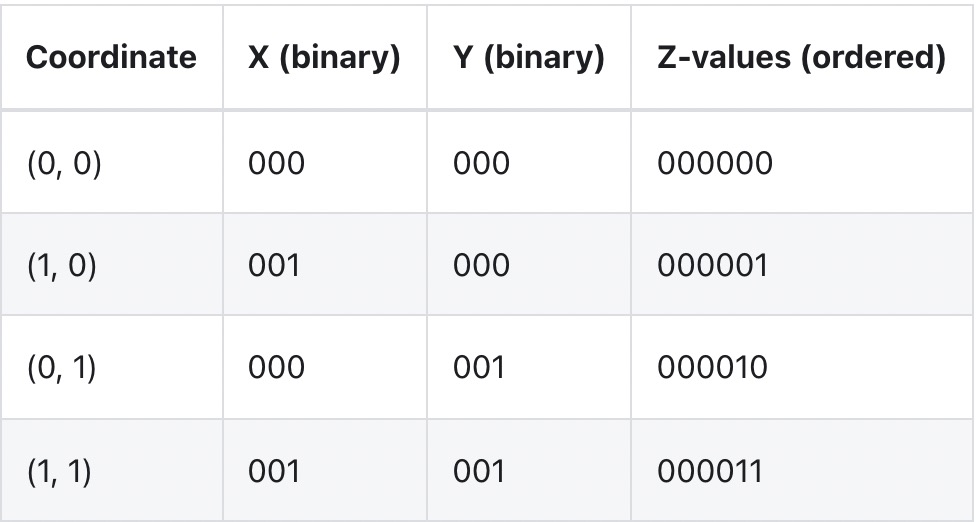
In the case of linear sorting, locality only uses the first column. Compared with the first column, the locality of this method uses all columns.
In a similar way, Hilbert curve allows mapping points in N-dimensional space (rows in our table) to one-dimensional curves, basically sorting them, while still retaining the key attribute of locality. Read more details about Hilbert curve here [4]. Our experiments so far show that, Sorting data using Hilbert curve will have better clustering and performance results.
Now let's see its actual effect!
2. Setting
We will use the Amazon Reviews dataset again [5], but this time we will use Hudi by product_id,customer_ The ID column tuples are sorted by Z-Order instead of clustering or linear sorting.
The dataset does not need special preparation. It can be directly downloaded from S3 in Parquet format and directly used as Spark to ingest it into Hudi table.
Start spark shell
./bin/spark-shell --master 'local[4]' --driver-memory 8G --executor-memory 8G \ --jars ../../packaging/hudi-spark-bundle/target/hudi-spark3-bundle_2.12-0.10.0.jar \ --packages org.apache.spark:spark-avro_2.12:2.4.4 \ --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
Import Hudi table
import org.apache.hadoop.fs.{FileStatus, Path}
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.{DataSourceReadOptions, DataSourceWriteOptions}
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.common.fs.FSUtils
import org.apache.hudi.common.table.HoodieTableMetaClient
import org.apache.hudi.common.util.ClusteringUtils
import org.apache.hudi.config.HoodieClusteringConfig
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.spark.sql.DataFrame
import java.util.stream.Collectors
val layoutOptStrategy = "z-order"; // OR "hilbert"
val inputPath = s"file:///${System.getProperty("user.home")}/datasets/amazon_reviews_parquet"
val tableName = s"amazon_reviews_${layoutOptStrategy}"
val outputPath = s"file:///tmp/hudi/$tableName"
def safeTableName(s: String) = s.replace('-', '_')
val commonOpts =
Map(
"hoodie.compact.inline" -> "false",
"hoodie.bulk_insert.shuffle.parallelism" -> "10"
)
////////////////////////////////////////////////////////////////
// Writing to Hudi
////////////////////////////////////////////////////////////////
val df = spark.read.parquet(inputPath)
df.write.format("hudi")
.option(DataSourceWriteOptions.TABLE_TYPE.key(), COW_TABLE_TYPE_OPT_VAL)
.option("hoodie.table.name", tableName)
.option(PRECOMBINE_FIELD.key(), "review_id")
.option(RECORDKEY_FIELD.key(), "review_id")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD.key(), "product_category")
.option("hoodie.clustering.inline", "true")
.option("hoodie.clustering.inline.max.commits", "1")
// NOTE: Small file limit is intentionally kept _ABOVE_ target file-size max threshold for Clustering,
// to force re-clustering
.option("hoodie.clustering.plan.strategy.small.file.limit", String.valueOf(1024 * 1024 * 1024)) // 1Gb
.option("hoodie.clustering.plan.strategy.target.file.max.bytes", String.valueOf(128 * 1024 * 1024)) // 128Mb
// NOTE: We're increasing cap on number of file-groups produced as part of the Clustering run to be able to accommodate for the
// whole dataset (~33Gb)
.option("hoodie.clustering.plan.strategy.max.num.groups", String.valueOf(4096))
.option(HoodieClusteringConfig.LAYOUT_OPTIMIZE_ENABLE.key, "true")
.option(HoodieClusteringConfig.LAYOUT_OPTIMIZE_STRATEGY.key, layoutOptStrategy)
.option(HoodieClusteringConfig.PLAN_STRATEGY_SORT_COLUMNS.key, "product_id,customer_id")
.option(DataSourceWriteOptions.OPERATION.key(), DataSourceWriteOptions.BULK_INSERT_OPERATION_OPT_VAL)
.option(BULK_INSERT_SORT_MODE.key(), "NONE")
.options(commonOpts)
.mode(ErrorIfExists)3. Test
Each individual test should be run in a separate spark shell to avoid caching affecting the test results.
////////////////////////////////////////////////////////////////
// Reading
///////////////////////////////////////////////////////////////
// Temp Table w/ Data Skipping DISABLED
val readDf: DataFrame =
spark.read.option(DataSourceReadOptions.ENABLE_DATA_SKIPPING.key(), "false").format("hudi").load(outputPath)
val rawSnapshotTableName = safeTableName(s"${tableName}_sql_snapshot")
readDf.createOrReplaceTempView(rawSnapshotTableName)
// Temp Table w/ Data Skipping ENABLED
val readDfSkip: DataFrame =
spark.read.option(DataSourceReadOptions.ENABLE_DATA_SKIPPING.key(), "true").format("hudi").load(outputPath)
val dataSkippingSnapshotTableName = safeTableName(s"${tableName}_sql_snapshot_skipping")
readDfSkip.createOrReplaceTempView(dataSkippingSnapshotTableName)
// Query 1: Total votes by product_category, for 6 months
def runQuery1(tableName: String) = {
// Query 1: Total votes by product_category, for 6 months
spark.sql(s"SELECT sum(total_votes), product_category FROM $tableName WHERE review_date > '2013-12-15' AND review_date < '2014-06-01' GROUP BY product_category").show()
}
// Query 2: Average star rating by product_id, for some product
def runQuery2(tableName: String) = {
spark.sql(s"SELECT avg(star_rating), product_id FROM $tableName WHERE product_id in ('B0184XC75U') GROUP BY product_id").show()
}
// Query 3: Count number of reviews by customer_id for some 5 customers
def runQuery3(tableName: String) = {
spark.sql(s"SELECT count(*) as num_reviews, customer_id FROM $tableName WHERE customer_id in ('53096570','10046284','53096576','10000196','21700145') GROUP BY customer_id").show()
}
//
// Query 1: Is a "wide" query and hence it's expected to touch a lot of files
//
scala> runQuery1(rawSnapshotTableName)
+----------------+--------------------+
|sum(total_votes)| product_category|
+----------------+--------------------+
| 1050944| PC|
| 867794| Kitchen|
| 1167489| Home|
| 927531| Wireless|
| 6861| Video|
| 39602| Digital_Video_Games|
| 954924|Digital_Video_Dow...|
| 81876| Luggage|
| 320536| Video_Games|
| 817679| Sports|
| 11451| Mobile_Electronics|
| 228739| Home_Entertainment|
| 3769269|Digital_Ebook_Pur...|
| 252273| Baby|
| 735042| Apparel|
| 49101| Major_Appliances|
| 484732| Grocery|
| 285682| Tools|
| 459980| Electronics|
| 454258| Outdoors|
+----------------+--------------------+
only showing top 20 rows
scala> runQuery1(dataSkippingSnapshotTableName)
+----------------+--------------------+
|sum(total_votes)| product_category|
+----------------+--------------------+
| 1050944| PC|
| 867794| Kitchen|
| 1167489| Home|
| 927531| Wireless|
| 6861| Video|
| 39602| Digital_Video_Games|
| 954924|Digital_Video_Dow...|
| 81876| Luggage|
| 320536| Video_Games|
| 817679| Sports|
| 11451| Mobile_Electronics|
| 228739| Home_Entertainment|
| 3769269|Digital_Ebook_Pur...|
| 252273| Baby|
| 735042| Apparel|
| 49101| Major_Appliances|
| 484732| Grocery|
| 285682| Tools|
| 459980| Electronics|
| 454258| Outdoors|
+----------------+--------------------+
only showing top 20 rows
//
// Query 2: Is a "pointwise" query and hence it's expected that data-skipping should substantially reduce number
// of files scanned (as compared to Baseline)
//
// NOTE: That Linear Ordering (as compared to Space-curve based on) will have similar effect on performance reducing
// total # of Parquet files scanned, since we're querying on the prefix of the ordering key
//
scala> runQuery2(rawSnapshotTableName)
+----------------+----------+
|avg(star_rating)|product_id|
+----------------+----------+
| 1.0|B0184XC75U|
+----------------+----------+
scala> runQuery2(dataSkippingSnapshotTableName)
+----------------+----------+
|avg(star_rating)|product_id|
+----------------+----------+
| 1.0|B0184XC75U|
+----------------+----------+
//
// Query 3: Similar to Q2, is a "pointwise" query, but querying other part of the ordering-key (product_id, customer_id)
// and hence it's expected that data-skipping should substantially reduce number of files scanned (as compared to Baseline, Linear Ordering).
//
// NOTE: That Linear Ordering (as compared to Space-curve based on) will _NOT_ have similar effect on performance reducing
// total # of Parquet files scanned, since we're NOT querying on the prefix of the ordering key
//
scala> runQuery3(rawSnapshotTableName)
+-----------+-----------+
|num_reviews|customer_id|
+-----------+-----------+
| 50| 53096570|
| 3| 53096576|
| 25| 10046284|
| 1| 10000196|
| 14| 21700145|
+-----------+-----------+
scala> runQuery3(dataSkippingSnapshotTableName)
+-----------+-----------+
|num_reviews|customer_id|
+-----------+-----------+
| 50| 53096570|
| 3| 53096576|
| 25| 10046284|
| 1| 10000196|
| 14| 21700145|
+-----------+-----------+4. Results
We summarize the following test results

It can be seen that multi column linear sorting is not very effective for queries filtered by columns other than columns (Q2 and Q3), which is in obvious contrast to spatial filling curves (Z-order and Hilbert), which speeds up the query time by up to three times. It is worth noting that the performance improvement largely depends on the basic data and query. In our internal data benchmark, we can achieve more than 11 times the query performance improvement!
5. Summary
Apache Hudi v0.10 brings new layout optimization functions Z-order and Hilbert to open source. Using these industry-leading layout optimization technologies can bring significant performance improvement and cost savings for user queries!
Reference link
[1] Article: https://aws.amazon.com/blogs/big-data/new-features-from-apache-hudi-0-7-0-and-0-8-0-available-on-amazon-emr/ [2] Clustering: https://hudi.apache.org/docs/clustering [3] Amazon Reviews dataset: https://s3.amazonaws.com/amazon-reviews-pds/tsv/index.txt [4] Here: https://drum.lib.umd.edu/handle/1903/804 [5] Amazon Reviews dataset: https://s3.amazonaws.com/amazon-reviews-pds/readme.html