1. What is MQ
MQ(message queue), literally speaking, message queuing is essentially a queue. FIFO is first in first out, but the content stored in the queue is message. MQ is also a cross process communication mechanism for upstream and downstream message delivery. In the Internet architecture, MQ is a very common upstream and downstream "logical decoupling + physical decoupling" message communication service. After using MQ, the upstream of message sending only needs to rely on MQ without relying on other services
2. Why use MQ
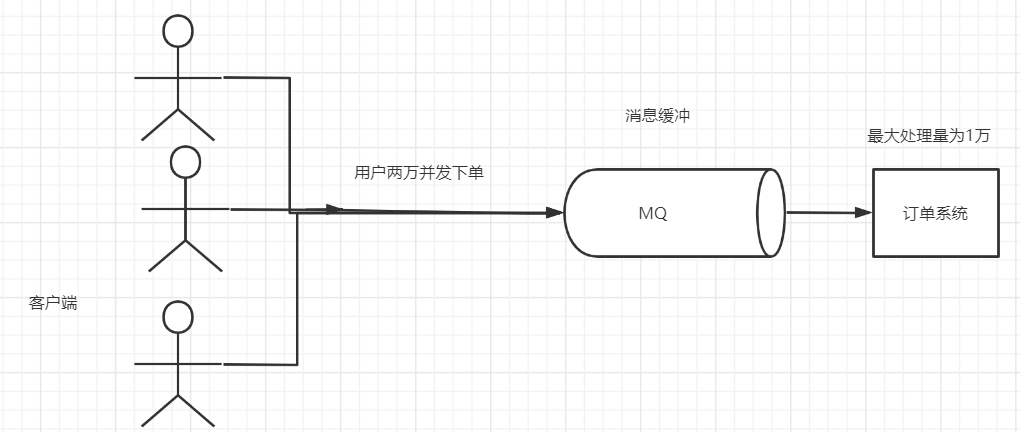
1. Flow peak elimination
If the order system can process 10000 orders at most, this processing capacity is more than enough to deal with the order in the normal period. In the normal period, we can return the results one second after we place the order. However, in the peak period, if there are 20000 orders, the system can't handle them. It can only limit orders to more than 10000, and users are not allowed to place orders. Using the message queue as a buffer, we can cancel this restriction and disperse the orders placed in one second into a period of time. At this time, some users may not receive the successful operation of placing an order until more than ten seconds after placing an order, but it is better than the experience of not placing an order.
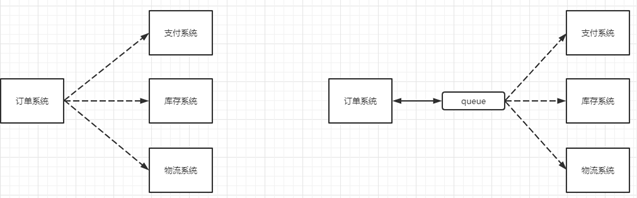
2. Application decoupling
Taking e-commerce applications as an example, there are order system, inventory system, logistics system and payment system. After the user creates an order, if the inventory system, logistics system and payment system are coupled and invoked, any subsystem fails, which will cause abnormal ordering operation. When the method is changed to message queue based, the problem of inter system call will be reduced a lot. For example, the logistics system needs a few minutes to repair due to failure. In these minutes, the memory to be processed by the logistics system is cached in the message queue, and the user's order can be completed normally. After the logistics system is restored, you can continue to process the order information. Medium order users can't feel the failure of the logistics system and improve the availability of the system.
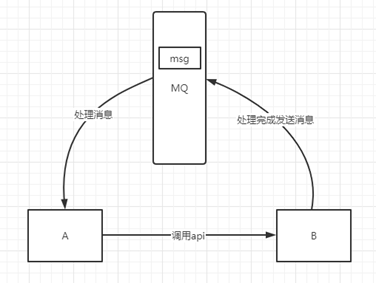
3. Asynchronous processing
Some inter service calls are asynchronous. For example, a calls B, and B takes a long time to execute, but a needs to know when B can complete execution. In the past, there were generally two ways. A calls B's query api for a period of time. Or A provides a callback api. After B is executed, api is called to notify the A service. Neither of these two methods is very elegant. Using the message bus can easily solve this problem. After a calls the B service, a only needs to listen to the message processed by B. when B processing is completed, it will send a message to MQ, which will forward the message to the a service. In this way, service a does not need to call B's query api or provide callback api. Similarly, service B does not need to do these operations. Service a can also get the message of successful asynchronous processing in time.
3. Classification of MQ
1,ActiveMQ
**Advantages: * * single machine throughput of 10000 class, timeliness of ms class, high availability, high availability based on master-slave architecture, message reliability and low probability of data loss
**Disadvantages: * * the official community now supports ActiveMQ 5 X maintenance is less and less, and high throughput scenarios are less used.
2,Kafka
Kafka is the killer of big data. When it comes to message transmission in the field of big data, Kafka cannot be bypassed. This message middleware born for big data is famous for its throughput of million level TPS * * (Transactions Per Second system throughput) * *. It has quickly become a favorite in the field of big data and plays an important role in the process of data collection, transmission and storage. It has been adopted by LinkedIn, Uber, Twitter, Netflix and other large companies.
Advantages: excellent performance, single machine write TPS is about one million pieces / s, and the biggest advantage is high throughput. Timeliness: ms level availability is very high. kafka is distributed. One data has multiple copies, and a few machines go down, which will not lose data and cause unavailability. Consumers use Pull to obtain messages. Messages are orderly. Through control, all messages can be consumed only once; Excellent third-party Kafka Web management interface kafka manager; It is mature in the log field and is used by many companies and open source projects; Function support: the function is relatively simple. It mainly supports simple MQ functions. Real time computing and log collection in the field of big data are used on a large scale
**Disadvantages: * * Kafka has more than 64 queues / partitions, and the load will soar obviously. The more queues, the higher the load, and the longer the response time for sending messages. Short polling mode is used, and the real-time performance depends on the polling interval. Retry is not supported in case of consumption failure; Support message order, but when an agent goes down, it will cause message disorder and slow community update;
3,RocketMQ
RocketMQ is an open-source product from Alibaba and is implemented in Java language. Kafka is referred to in the design and some improvements have been made. It is widely used by Alibaba in order, transaction, recharge, stream computing, message push, log stream processing, binglog distribution and other scenarios.
**Advantages: the single machine throughput is 100000, the availability is very high, the distributed architecture, * * messages can be lost, the * * MQ function is relatively perfect, or distributed, and the scalability is good, * * supports 1 billion level message accumulation, which will not lead to performance degradation. The source code is java. We can read the source code ourselves and customize our own MQ
**Disadvantages: * * there are not many supported client languages. At present, java and c + +, of which c + + is immature; Community activity is average, not in MQ
To implement JMS and other interfaces in the core, some systems need to modify a lot of code to migrate
4,RabbitMQ
Released in 2007, it is a reusable enterprise message system based on AMQP (Advanced message queuing protocol). It is one of the most mainstream message middleware at present.
Advantages: due to the high concurrency of erlang language, the performance is good; With a throughput of 10000, MQ functions are relatively complete, robust, stable, easy to use, cross platform, and support multiple languages, such as Python, Ruby NET, Java, JMS, C, PHP, ActionScript, XMPP, STOMP, etc., supporting AJAX and complete documents; The management interface provided by open source is very good, easy to use, and the community is highly active; The update frequency is quite high
https://www.rabbitmq.com/news.html
Disadvantages: the commercial version needs to be charged, and the learning cost is high
4. MQ selection
1,Kafka
kafka is mainly characterized by processing message consumption based on Pull mode and pursuing high throughput. Its initial purpose is to collect and transmit logs, which is suitable for the data collection business of Internet services that generate a large amount of data. It is suggested that large companies can choose it. If there is log collection function, it must be the first choice kafka.
2,RocketMQ
Born in the field of financial Internet and demanding high reliability, especially in the case of order deduction and business peak cutting in e-commerce, when a large number of transactions pour in, the back end may not be able to handle them in time. RocketMQ may be more reliable in stability. These business scenarios have been tested many times in Alibaba double 11. If your business has the above concurrent scenarios, it is recommended to choose RocketMQ.
3,RabbitMQ
Combined with the concurrency advantages of erlang language itself, it has good performance, timeliness, microsecond level, high community activity, and convenient management interface. If your data volume is not so large, small and medium-sized companies give priority to RabbitMQ with relatively complete functions.
5. RabbitMQ installation
1. Installing using docker
docker run -it --rm --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:3-management # -it interaction is entering the container # run runs the container through an image # --Name specifies the container name # -p specifies the port mapping for linux hosts and containers # rabbitmq: 3-management image
2. Install using rpm
# rabbitMq requires erlang environment and socat environment rpm -ivh erlang-21.3-1.el7.x86_64.rpm yum install socat -y rpm -ivh rabbitmq-server-3.8.8-1.el7.noarch.rpm # -i installation # v details # h print information
3. Common commands
# Rabbitmq server starts automatically systemctl enable rabbitmq-server.service # Start rabbitmq systemctl start rabbitmq-server # View service status systemctl status rabbitmq-server # Open rabbitmq web management plug-in rabbitmq-plugins enable rabbitmq_management
4. Open port
# 1. rabbitmq management port 15672 # 2. rabbitmq service port 5672 # For ECS, you need to open the security group and then open the server port firewall-cmd --zone=public --add-port=15672/tcp --permanent firewall-cmd --zone=public --add-port=5672/tcp --permanent firewall-cmd --reload systemctl restart firewalld
5. Accessing rabbitmq_management
# Local access rabbitmq_management uses the default account guest password guest # You need to create an account for remote access # Create account rabbitmqctl add_user admin 123456 # Set user roles rabbitmqctl set_user_tags admin administrator # Set user permissions (user admin has read, write and configurable permissions for all resources under the "/" path) # set_permissions [-p <vhostpath>] <user> <conf> <write> <read> rabbitmqctl set_permissions -p "/" admin ".*" ".*" ".*" # Current users and roles rabbitmqctl list_users
5. Command help
[root@VM-8-9-centos ~]# rabbitmqctl --help Usage rabbitmqctl [--node <node>] [--timeout <timeout>] [--longnames] [--quiet] <command> [<command options>] Available commands: Help: autocomplete Provides command name autocomplete variants help Displays usage information for a command version Displays CLI tools version Nodes: await_startup Waits for the RabbitMQ application to start on the target node reset Instructs a RabbitMQ node to leave the cluster and return to its virgin state rotate_logs Instructs the RabbitMQ node to perform internal log rotation shutdown Stops RabbitMQ and its runtime (Erlang VM). Monitors progress for local nodes. Does not require a PID file path. start_app Starts the RabbitMQ application but leaves the runtime (Erlang VM) running stop Stops RabbitMQ and its runtime (Erlang VM). Requires a local node pid file path to monitor progress. stop_app Stops the RabbitMQ application, leaving the runtime (Erlang VM) running wait Waits for RabbitMQ node startup by monitoring a local PID file. See also 'rabbitmqctl await_online_nodes' Cluster: await_online_nodes Waits for <count> nodes to join the cluster change_cluster_node_type Changes the type of the cluster node cluster_status Displays all the nodes in the cluster grouped by node type, together with the currently running nodes force_boot Forces node to start even if it cannot contact or rejoin any of its previously known peers force_reset Forcefully returns a RabbitMQ node to its virgin state forget_cluster_node Removes a node from the cluster join_cluster Instructs the node to become a member of the cluster that the specified node is in rename_cluster_node Renames cluster nodes in the local database update_cluster_nodes Instructs a cluster member node to sync the list of known cluster members from <seed_node> Replication: cancel_sync_queue Instructs a synchronising mirrored queue to stop synchronising itself sync_queue Instructs a mirrored queue with unsynchronised mirrors (follower replicas) to synchronise them Users: add_user Creates a new user in the internal database authenticate_user Attempts to authenticate a user. Exits with a non-zero code if authentication fails. change_password Changes the user password clear_password Clears (resets) password and disables password login for a user delete_user Removes a user from the internal database. Has no effect on users provided by external backends such as LDAP list_users List user names and tags set_user_tags Sets user tags Access Control: clear_permissions Revokes user permissions for a vhost clear_topic_permissions Clears user topic permissions for a vhost or exchange list_permissions Lists user permissions in a virtual host list_topic_permissions Lists topic permissions in a virtual host list_user_permissions Lists permissions of a user across all virtual hosts list_user_topic_permissions Lists user topic permissions list_vhosts Lists virtual hosts set_permissions Sets user permissions for a vhost set_topic_permissions Sets user topic permissions for an exchange Monitoring, observability and health checks: list_bindings Lists all bindings on a vhost list_channels Lists all channels in the node list_ciphers Lists cipher suites supported by encoding commands list_connections Lists AMQP 0.9.1 connections for the node list_consumers Lists all consumers for a vhost list_exchanges Lists exchanges list_hashes Lists hash functions supported by encoding commands list_queues Lists queues and their properties list_unresponsive_queues Tests queues to respond within timeout. Lists those which did not respond ping Checks that the node OS process is up, registered with EPMD and CLI tools can authenticate with it report Generate a server status report containing a concatenation of all server status information for support purposes schema_info Lists schema database tables and their properties status Displays status of a node Parameters: clear_global_parameter Clears a global runtime parameter clear_parameter Clears a runtime parameter. list_global_parameters Lists global runtime parameters list_parameters Lists runtime parameters for a virtual host set_global_parameter Sets a runtime parameter. set_parameter Sets a runtime parameter. Policies: clear_operator_policy Clears an operator policy clear_policy Clears (removes) a policy list_operator_policies Lists operator policy overrides for a virtual host list_policies Lists all policies in a virtual host set_operator_policy Sets an operator policy that overrides a subset of arguments in user policies set_policy Sets or updates a policy Virtual hosts: add_vhost Creates a virtual host clear_vhost_limits Clears virtual host limits delete_vhost Deletes a virtual host list_vhost_limits Displays configured virtual host limits restart_vhost Restarts a failed vhost data stores and queues set_vhost_limits Sets virtual host limits trace_off trace_on Configuration and Environment: decode Decrypts an encrypted configuration value encode Encrypts a sensitive configuration value environment Displays the name and value of each variable in the application environment for each running application set_cluster_name Sets the cluster name set_disk_free_limit Sets the disk_free_limit setting set_log_level Sets log level in the running node set_vm_memory_high_watermark Sets the vm_memory_high_watermark setting Definitions: export_definitions Exports definitions in JSON or compressed Erlang Term Format. import_definitions Imports definitions in JSON or compressed Erlang Term Format. Feature flags: enable_feature_flag Enables a feature flag on target node list_feature_flags Lists feature flags Operations: close_all_connections Instructs the broker to close all connections for the specified vhost or entire RabbitMQ node close_connection Instructs the broker to close the connection associated with the Erlang process id eval Evaluates a snippet of Erlang code on the target node eval_file Evaluates a file that contains a snippet of Erlang code on the target node exec Evaluates a snippet of Elixir code on the CLI node force_gc Makes all Erlang processes on the target node perform/schedule a full sweep garbage collection resume_listeners Resumes client connection listeners making them accept client connections again suspend_listeners Suspends client connection listeners so that no new client connections are accepted Queues: delete_queue Deletes a queue purge_queue Purges a queue (removes all messages in it) Deprecated: hipe_compile DEPRECATED. This command is a no-op. HiPE is no longer supported by modern Erlang versions node_health_check DEPRECATED. Performs intrusive, opinionated health checks on a fully booted node. See https://www.rabbitmq.com/monitoring.html#health-checks instead Use 'rabbitmqctl help <command>' to learn more about a specific command
6,RabbitMQ
RabbitMQ is a message oriented middleware: it accepts and forwards messages. You can regard it as an express site. When you want to send a package, you put your package in the express station, and the courier will eventually send your express to the recipient. According to this logic, RabbitMQ is an express station, and a courier will deliver the express for you. The main difference between RabbitMQ and express station is that it does not process express mail, but receives, stores and forwards message data.
1. Four core concepts
Producer: the program that generates data and sends messages is the producer switch
Switch: RabbitMQ is a very important component. On the one hand, it receives messages from producers, on the other hand, it pushes messages to queues. The switch must know exactly how to handle the messages it receives, whether to push these messages to a specific queue or multiple queues, or discard the messages, which depends on the switch type
queue
Queue is a data structure used internally by RabbitMQ. Although messages flow through RabbitMQ and applications, they can only be stored in the queue. The queue is only constrained by the memory and disk limitations of the host. It is essentially a large message buffer. Many producers can send messages to a queue, and many consumers can try to receive data from a queue. This is how we use queues
consumer
Consumption and reception have similar meanings. Most of the time, consumers are a program waiting to receive messages. Note that producers, consumers, and message middleware are often not on the same machine. The same application can be both a producer and a consumer.
2. How RabbitMQ works
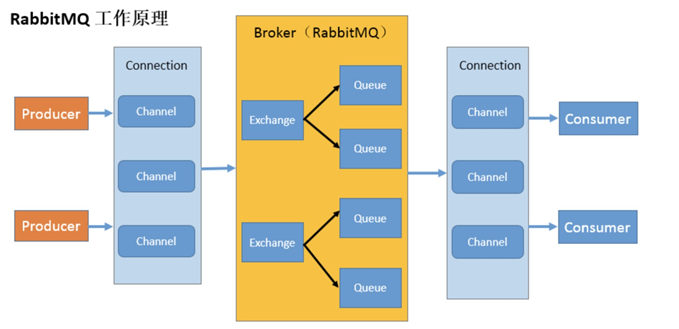
Broker: an application that receives and distributes messages. RabbitMQ Server is the Message Broker (Message Broker)
Virtual host: designed for multi tenancy and security factors, the basic components of AMQP are divided into a virtual group, which is similar to the concept of namespace in the network. When multiple different users use the services provided by the same RabbitMQ server, they can be divided into multiple vhosts. Each user creates an exchange / queue in its own vhost
Connection: TCP connection between publisher / consumer and broker
Channel: if a Connection is established every time RabbitMQ is accessed, the overhead of establishing a TCP Connection when the message volume is large will be huge and the efficiency will be low. A channel is a logical Connection established within a Connection. If the application supports multithreading, each thread usually creates a separate channel for communication. The AMQP method contains a channel id to help the client and message broker identify the channel, so the channels are completely separated. As a lightweight Connection, channel greatly reduces the overhead of establishing TCP Connection by the operating system
Exchange: message arrives at the first stop of the broker, matches the routing key in the query table according to the distribution rules, and distributes the message to the queue. Common types are: direct (point-to-point), topic (publish subscribe) and fan out (multicast)
Queue: the message is finally sent here to wait for the consumer to pick it up
Binding: the virtual connection between exchange and queue. The binding can contain routing key s. The binding information is saved in the query table in exchange for the distribution basis of message s
7. Hello World (single production and consumption)
1. Single producer consumer relationship diagram

2. Introduce dependency
<dependencies> <!--rabbitmq Dependent client--> <dependency> <groupId>com.rabbitmq</groupId> <artifactId>amqp-client</artifactId> <version>5.8.0</version> </dependency> <!--A dependency on the operation file stream--> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.6</version> </dependency> </dependencies>
3. Write test
/**
* consumer
*/
public class Producer {
public static void main(String[] args) {
// Create a factory connected to rabbitmq
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("119.29.41.38");
factory.setUsername("admin");
factory.setPassword("123");
Connection connection = null;
Channel channel = null;
try{
// Connect factory to establish connection
connection = factory.newConnection();
// Create a channel inside the connection
channel = connection.createChannel();
/**
* Consumer declares a queue
* 1,Queue name
* 2,Whether to persist queue messages
* 3,Whether the queue is only for one consumer. true means only for one consumer
* 4,Is the queue automatically deleted after the last consumer disconnects
*/
channel.queueDeclare("hello", false, false, true,null);
String message = "hello world";
/**
* Consumers publish messages (messages will be placed in the queue, so you need to specify the queue)
* 1,Which switch will the message be sent to
* 2,Declare the routing key
* 3,Other configurations for this message
* 4,Messages sent
*/
channel.basicPublish("","hello",null,message.getBytes("UTF-8"));
System.out.println("Message sent");
}catch (Exception e){
System.out.println("fail in send");
e.printStackTrace();
}finally {
try{
if(channel != null){
channel.close();
}
if(connection != null){
connection.close();
}
}catch (Exception e){
e.printStackTrace();
}
}
}
}
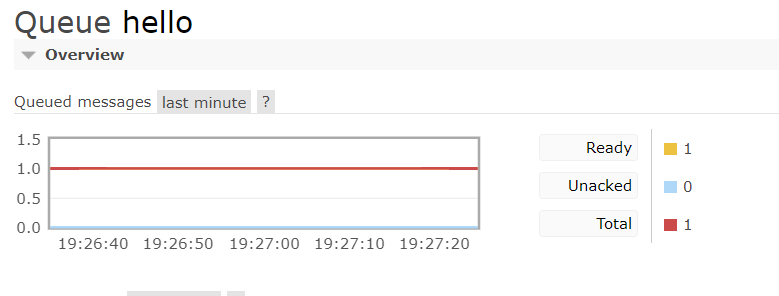
After running, you can see that there is a message waiting for consumption in the message queue
/**
* consumer
*/
public class Consumer {
public static void main(String[] args) throws Exception{
ConnectionFactory connectionFactory = new ConnectionFactory();
connectionFactory.setHost("119.29.41.38");
connectionFactory.setUsername("admin");
connectionFactory.setPassword("123");
Connection connection = connectionFactory.newConnection();
Channel channel = connection.createChannel();
System.out.println("Waiting to receive messages...");
// Interface callback for consumption of pushed messages
DeliverCallback deliverCallback = (consumerTag, message) -> {
System.out.println(new String(message.getBody()));
};
// Cancel interface callback of consumption
CancelCallback cancelCallback = (consumerTag) ->{
System.out.println("Message consumption interrupted");
};
/**
* Consumer News
* 1,Which queue to consume
* 2,Do you want to answer automatically after successful consumption? false: answer manually
* 3,The consumer received a callback for the message
* 4,Consumer cancels the callback of consumption
*/
channel.basicConsume("hello",true,deliverCallback,cancelCallback);
}
}