RabbitMQ video learning (basic)
Based on Alibaba cloud, this article refers to the videos of Shang Silicon Valley: Shangsilicon Valley 2021 new RabbitMQ tutorial | quickly master MQ message middleware
1. Related concepts of MQ
1.1. What is MQ?
MQ (Message Queue), literally speaking, is essentially a queue. FIFO is first in first out, but the content stored in the queue is message. It is also a cross process communication mechanism for upstream and downstream message delivery. In the Internet architecture, MQ is a very common upstream and downstream "logical decoupling + physical decoupling" message communication service. After using MQ, the upstream of message sending only needs to rely on MQ without relying on other services.
1.2 why use MQ?
1.2.1 flow peak elimination
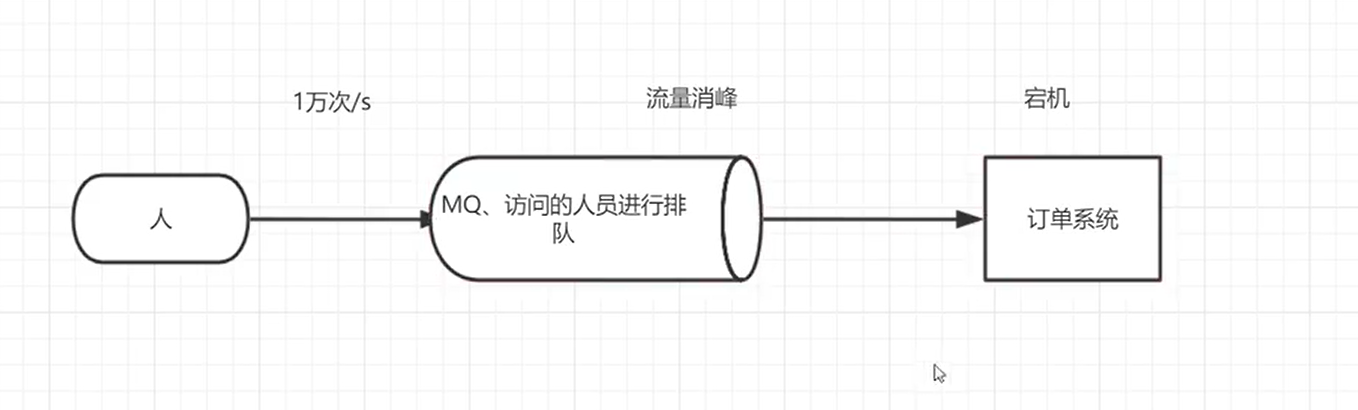
For example, if the order system can process 10000 orders at most, this processing capacity is more than enough to deal with the order in the normal period. In the normal period, we can return the results one second after we place the order. However, in the peak period, if 20000 orders are placed, the operating system can not handle them. Users can only be restricted from placing orders after more than 10000 orders. Using the message queue as a buffer, we can cancel this restriction and disperse the orders placed within one second into a period of time. At this time, some users may not receive the successful operation of placing an order until more than ten seconds after placing an order, but it cannot be better than the experience of placing an order.
1.2.2 application decoupling
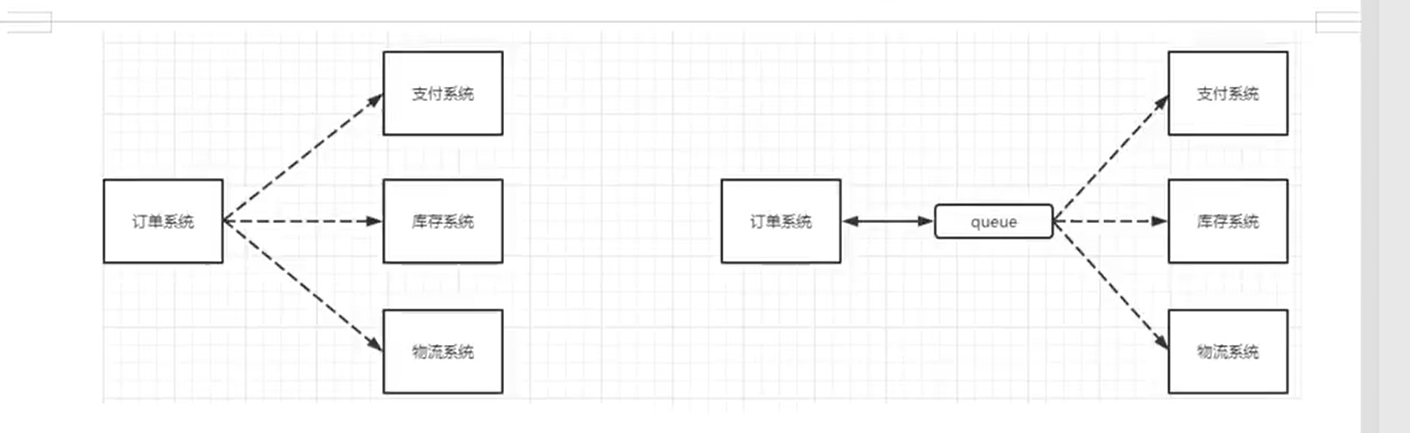
Taking e-commerce applications as an example, there are order system, inventory system, logistics system and payment system. After the user creates an order, if the inventory system, logistics system and payment system are coupled and invoked, any subsystem fails, which will cause abnormal ordering operation. When the method is changed to message queue based, the problem of inter system call will be reduced a lot. For example, the logistics system needs a few minutes to repair due to failure. In these minutes, the memory to be processed by the logistics system is cached in the message queue, and the user's order can be completed normally. After the logistics system is repaired, you can continue to process the order information. Intermediate order users can't feel the failure of the logistics system, so as to improve the availability of the system.
1.2.3 asynchronous processing
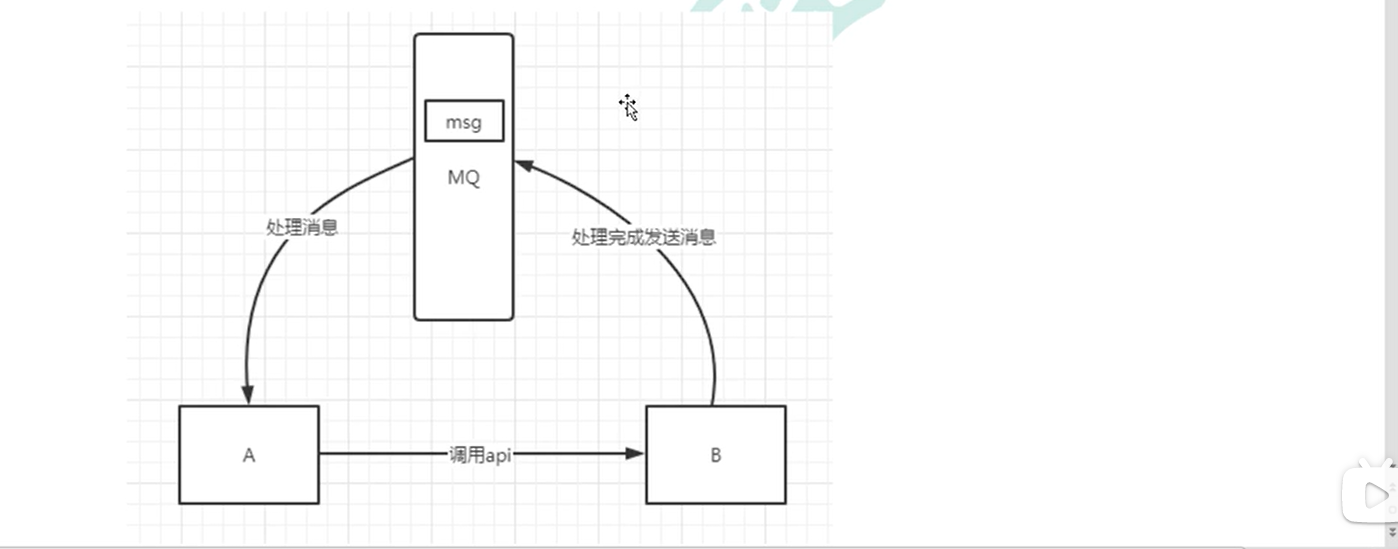
Some services are called asynchronously. For example, a calls B, which takes a long time to execute, but a needs to know when B can complete execution. In the past, there were generally two ways. The first way: a calls B's query api for a period of time. Or A provides a Callback api. After B is executed, api is called to notify the A service. Neither of these two methods is very elegant. Using the message bus can easily solve this problem. After a calls the B service, a only needs to listen to the message processed by B. when B processing is completed, it will send a message to MQ, which will forward the message to the a service. In this way, service a does not need to call B's query api or provide callback api. Similarly, service B does not need to do these operations. Service a can also get the message of successful asynchronous processing in time. Note: when using the message bus, service a can do other tasks before service B processes the request. In the previous two methods, service a is in a waiting state when service B processes the request.
1.3 classification of MQ
1.3.1,ActiveMQ
- Advantages: single machine throughput of 10000 class, timeliness of ms class, high availability, high availability based on master-slave architecture, low message reliability and low probability of data loss
- Disadvantages: the official community now maintains less and less Active MQ 5.x, and uses less in high throughput scenarios.
1.3.2,KafKa
Kafka is the killer mace of big data. When it comes to message transmission in the field of big data, Kafka cannot be bypassed. This message middleware born for big data is famous for its throughput of one million TPS. It has quickly become a favorite in the field of big data and plays an important role in the process of data collection, transmission and storage. It has been adopted by LinkedIn, Uber, Twitter, Netflix and other large companies.
- Advantages: excellent performance. The single write TPS is about one million pieces / s. The biggest advantage is high throughput. Timeliness: ms level availability is very high. kafka is distributed. One data has multiple copies, and a few machines go down, which will not lose data and cause unavailability. Consumers use Pull to obtain messages. Messages are orderly. Through control, all messages can be consumed and only consumed once; Excellent third-party Kafka Web management interface Kafka - Manager; It is mature in the log field and is used by many companies and open source projects; Function support: the function is relatively simple. It mainly supports simple MQ functions. Real time computing and log collection in the field of big data are used on a large scale
- Disadvantages: the Kafka single machine has more than 64 queues / partitions, and the load will soar obviously. The more queues, the higher the load, and the longer the response time of sending messages. Using short polling mode, the real-time performance depends on the polling interval, and retry is not supported for consumption failure (in short, message loss will occur); The message sequence is supported, but when an agent goes down, the message sequence will be out of order and the community update will be slow.
1.3.3,RocketMQ
RocketMQ is an open-source product from Alibaba and is implemented in JAVA. It refers to Kafka and makes some improvements. It is widely used by Alibaba in order, transaction, recharge, stream computing, message push, log stream processing, binlog distribution and other scenarios.
- Advantages: the single machine throughput is 100000 levels, the availability is very high, the distributed architecture, the message can achieve 0 loss, the MQ function is relatively perfect, it is still distributed, and the scalability is good. It supports the accumulation of 1 billion levels of messages, and the performance will not decline due to the accumulation. The source code is java. We can read the source code ourselves and customize our company's MQ.
- Disadvantages: there are not many supported client languages. At present, JAVA and C + +, of which C + + is immature; The community is generally active and does not implement JMS and other interfaces in the MQ core. Some system migrations need to modify a lot of code.
1.3.4,RabbitMQ
Released in 2007, it is a reusable enterprise message system based on AMQP (Advanced message queuing protocol). It is one of the most mainstream message middleware at present.
- Advantages: due to the high concurrency of erlang language, the performance is good; The throughput reaches 10000, MQ functions are relatively complete, robust, stable, easy to use, cross platform, support multiple languages, such as Python, Ruby,. NET, JAVA, JMS, C, PHP, ActionScript, STOMP, etc., and support AJAX documents; The management interface provided by open source is very good, very easy to use, and the community is highly active; The update frequency is very high
- Disadvantages: the commercial version needs to be charged, and the learning cost is high.
1.4 selection of MQ
1.4.1,Kafka
Kafka is mainly characterized by processing message consumption based on Pull mode and pursuing high throughput. Its initial purpose is to collect and transmit logs, which is suitable for the data collection business of Internet services that generate a large amount of data. Large companies suggest that Kafka can be selected. If there is log collection function, Kafka must be the first choice.
1.4.2,RocketMQ
Born in the field of financial Internet, scenes with high reliability requirements, especially order deduction and business peak elimination in e-commerce, may not be handled in time at the back end when a large number of transactions pour in. RocketMQ may be more reliable in stability. These business scenarios have been tested many times in Alibaba double 11. If your business has the above concurrent scenarios, it is recommended to choose RocketMQ.
1.4.3,RabbitMQ
Combined with the concurrency advantages of erlang language itself, it has good performance, subtle timeliness, high community activity and convenient management interface. If your data volume is not so large, small and medium-sized companies give priority to RabbitMQ with relatively complete functions.
2. The beginning of RabbitMQ
2.1 concept of RabbitMQ
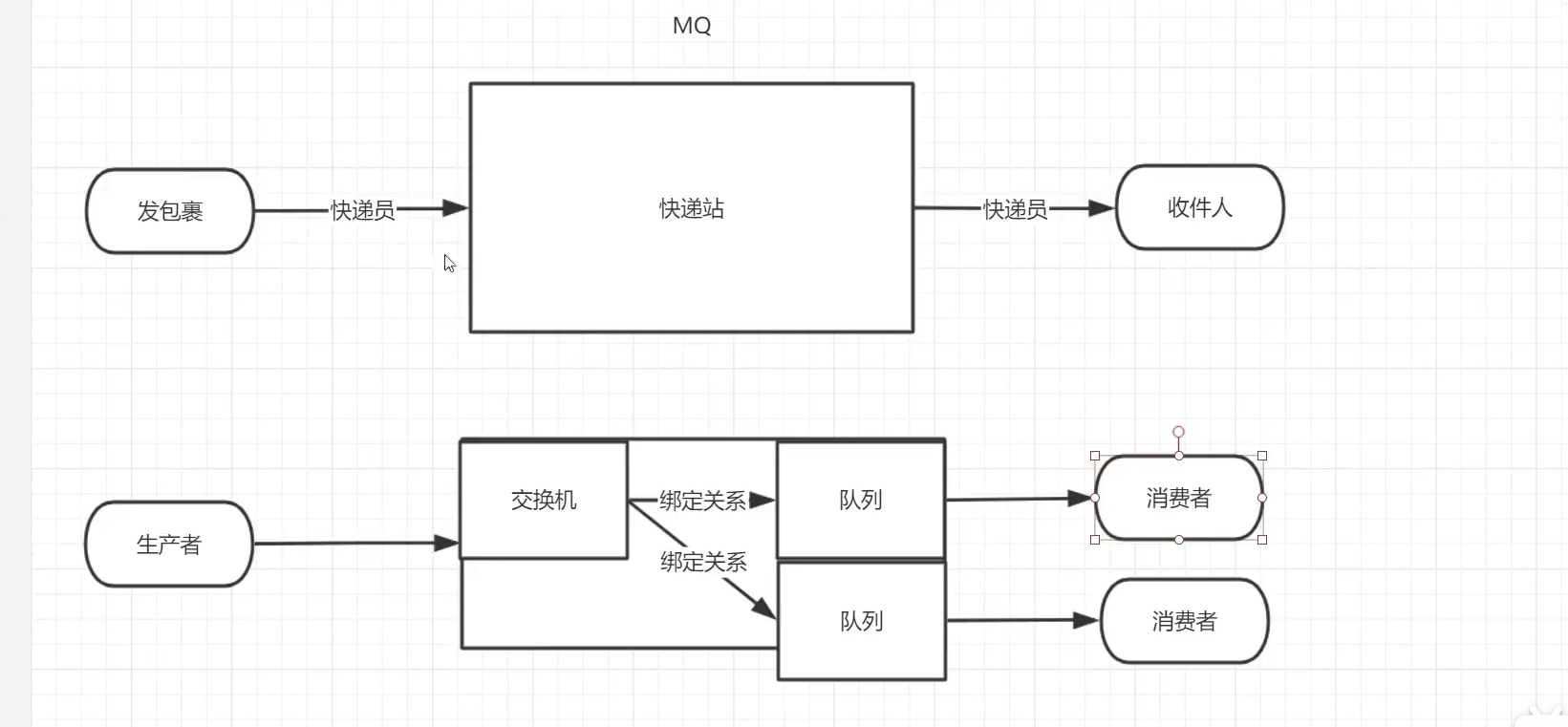
RabbitMQ is a message oriented middleware: it accepts and forwards messages. You can take it as an express site. When you want to send a package, you put your package in the express station, and the courier will eventually send your express to the recipient. According to this logic, RabbitMQ is an express station, and a courier will deliver the express for you. The main difference between RabbitMQ and express station is that it does not process express mail, but receives, stores and forwards message data.
2.2. Four core concepts
-
producer
- The program that generates the data sending message is the producer
-
Switch
- Switch is a very important part of RabbitMQ. On the one hand, it receives messages from producers, on the other hand, it pushes messages to queues. The switch must know exactly how to handle the messages it receives, whether to push them to a specific queue or to multiple queues. Or discard the message, which depends on the type of switch.
-
queue
- Queue is a data structure used internally by RabbitMQ. Although messages flow through RabbitMQ and applications, they can only be stored in the queue. The queue is only constrained by the memory and disk limitations of the host. It is essentially a large message buffer. Many producers can send messages to a queue, and many consumers can try to receive data from a queue. This is how we use queues.
-
consumer
- Consumption and reception have similar meanings. Most of the time, consumers are a program waiting to receive messages. Note that producers, consumers, and message middleware are often not on the same machine. The same application can be both a producer and a consumer.
2.3. The core part of RabbitMQ (six modes)
2.3.1 introduction to terms
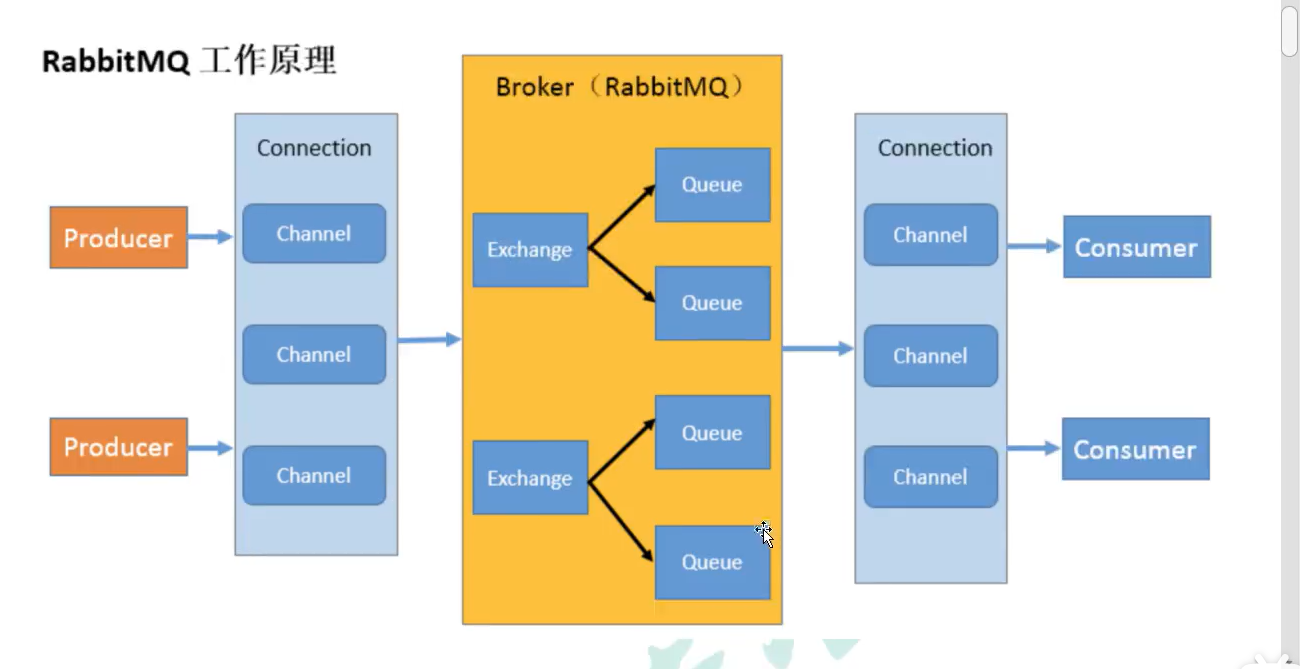
- Broker: an application that receives and distributes messages. RabbitMQ Server is the Message Broker
- Virtual host: designed for multi tenancy and security factors, the basic components of AMQP are divided into a virtual group, which is similar to the concept of namespace in the network. When multiple different users use the services provided by the same RabbitMQ Server, multiple vhosts can be divided, and each user creates exchange / queue in its own vhost.
- Connection: TCP connection between publisher / consumer and broker.
- Channel: if a Connection is established every time RabbitMQ is accessed, the overhead of establishing a TCP Connection when the message volume is large will be huge and the efficiency will be low. A channel is a logical Connection established within a Connection. If the application supports multithreading, a separate channel is usually created for each thread to communicate. The AMQP method contains a channel id to help the client and the message broker identify the channel, so the channels are completely isolated. As a lightweight Connection, channel greatly reduces the overhead of establishing TCP Connection by the operating system.
- Exchange: message arrives at the first stop of the broker, matches the routing key in the query table according to the distribution rules, and distributes the message to the queue. Common types are: direct (point-to-point), topic (publish subscribable) and fan out (multicast).
- Queue: the message is finally sent here to wait for the consumer to pick it up
- Binding: the virtual connection between exchange and queue. The binding can contain routing key s. The binding information is saved in the query table in exchange for the distribution basis of message s.
3. Using RabbitMQ
Query rabbitMQ. If it is not specified, it defaults to the latest version:

Pull image:
docker pull rabbitmq:management
To view the docker image list:

Docker container operation: after the above command is executed, the image has been pulled to the local warehouse. Then, you can operate the container and start RabbitMQ
# Set the account password and run RabbitMQ # -d background operation # -p map open port host port: container port # --Name specifies the name of the rabbitMQ container # -E configure environment variable - e RABBITMQ_DEFAULT_USER specifies the user account # -e RABBITMQ_DEFAULT_PASS specifies the account password # --hostname host name (an important note of RabbitMQ is that it stores data according to the so-called node name, which is the host name by default) docker run -d -p 15672:15672 -p 5672:5672 -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=admin --name rabbitmq --hostname=rabbitmqhostone rabbitmq:management # Run RabbitMQ without setting the account name and password docker run -d -p 5672:5672 --name rabbitmq rabbitmq:management
Note that the default account password of rabbitMQ is guest/guest
Enter the running RabbitMQ container:

# Add a new user root@rabbitmqhostone:/# rabbitmqctl add_user username and password # Set user roles root@rabbitmqhostone:/# rabbitmqctl set_user_tags username tags/administrator # Set up users and roles set_permission [-p <vhostpath>] <user> <conf> <write> <read> rabbitmqctl set_permission -p "/" admin ".*" ".*" ".*" # View current users and roles root@rabbitmqhostone:/# rabbitmqctl list_users Listing users ... user tags admin [administrator]
RabbitMQ main interface after successful login:
4. Using rabbit MQ in JAVA language
Write two programs in JAVA, the producer who sends a single message and the consumer who receives and prints the message.
P is our producer, C is our consumer, and the red box in the middle is a queue = = "representing the message buffer reserved by the user.

For example, create a Maven project and import the following dependencies:
<dependencies>
<!-- https://mvnrepository.com/artifact/com.rabbitmq/amqp-client -->
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.13.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.11.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- appoint jdk Compiled version -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
Producer code build:
public class Proceducer {
//Queue name
public static final String QUEUE_NAME="hello";
public static void main(String[] args) throws IOException, TimeoutException {
//Send a message
//Create a connection factory
ConnectionFactory factory=new ConnectionFactory();
//Factory IP, queue connecting RabbitMQ
factory.setHost("39.107.103.173");
//user name
factory.setUsername("admin");
//password
factory.setPassword("admin");
//Set the port number. Note that 15672 is RabbitMQ and the port number of the background management interface. Port 5672 should be set
factory.setPort(5672);
//Create connection
Connection connection = factory.newConnection();
//Get channel
Channel channel = connection.createChannel();
//Create a queue
/**
* queueDeclare(String var1, boolean var2, boolean var3, boolean var4, Map<String, Object> var5)
* var1:Queue name
* var2:Whether the messages in the queue are persisted. By default, the messages are stored in memory, and persistence is stored in disk
* var3:Whether the queue supports consumption by multiple consumers and message sharing. If true, multiple consumers can consume (i.e. Message Sharing)
* false It means that only one consumer can consume (i.e. no message sharing)
* var4:Whether to delete the queue automatically after the last consumer is disconnected
* var5: Other parameters, such as delay message, etc
*/
channel.queueDeclare(QUEUE_NAME,false,false,false,null);
//Send a message
String message="hello rabbitMQ";
/**
* Send a message:
* 1.To which switch
* 2.The key value of the route is the name of the queue this time. Distribute messages to the queue according to the routing key
* 3.Other parameter information
* 4.The body of the message sent
*/
channel.basicPublish("",QUEUE_NAME,null,message.getBytes());
System.out.println("Message sent!");
}
}
Consumer queue building:
/**
* @author wcc
* @date 2021/11/3 11:07
* Consumers, who accept the message
*/
public class Consumer {
//The name of the queue to accept messages from this queue
public static final String QUEUE_NAME = "hello";
public static void main(String[] args) throws IOException, TimeoutException {
//receive messages
//Create a connection factory that connects RabbitMQ
ConnectionFactory factory=new ConnectionFactory();
factory.setHost("39.107.103.173");
factory.setUsername("admin");
factory.setPassword("admin");
factory.setPort(5672);
Connection connection=factory.newConnection();
Channel channel=connection.createChannel();
//Successful consumption callback
DeliverCallback deliverCallback = (consumeTag,message)->{
System.out.println(new String(message.getBody()));
};
//Callback when canceling a message
CancelCallback cancelCallback= (consumerTag)->{
System.out.println("Consumption message interrupted");
};
//Consumer receives message
/**
* Consumer News
* 1.Which queue to consume
* 2.Whether to respond automatically after successful consumption. true means automatic response, and false means manual response
* 3.Callback of successful consumption by consumers
* 4.Consumer cancels consumption callback
*/
channel.basicConsume(QUEUE_NAME,true,deliverCallback,cancelCallback);
}
}
5. Work Queues
**The main idea of work queue (also known as task queue) * * is to avoid executing a resource intensive task immediately and having to wait for it to complete. Instead, we arranged for the task to be carried out later. We encapsulate the task as a message and send it to the queue. The worker process running in the background will pop up the task and finally execute the job. When there are multiple worker threads, these worker threads will handle these tasks together.
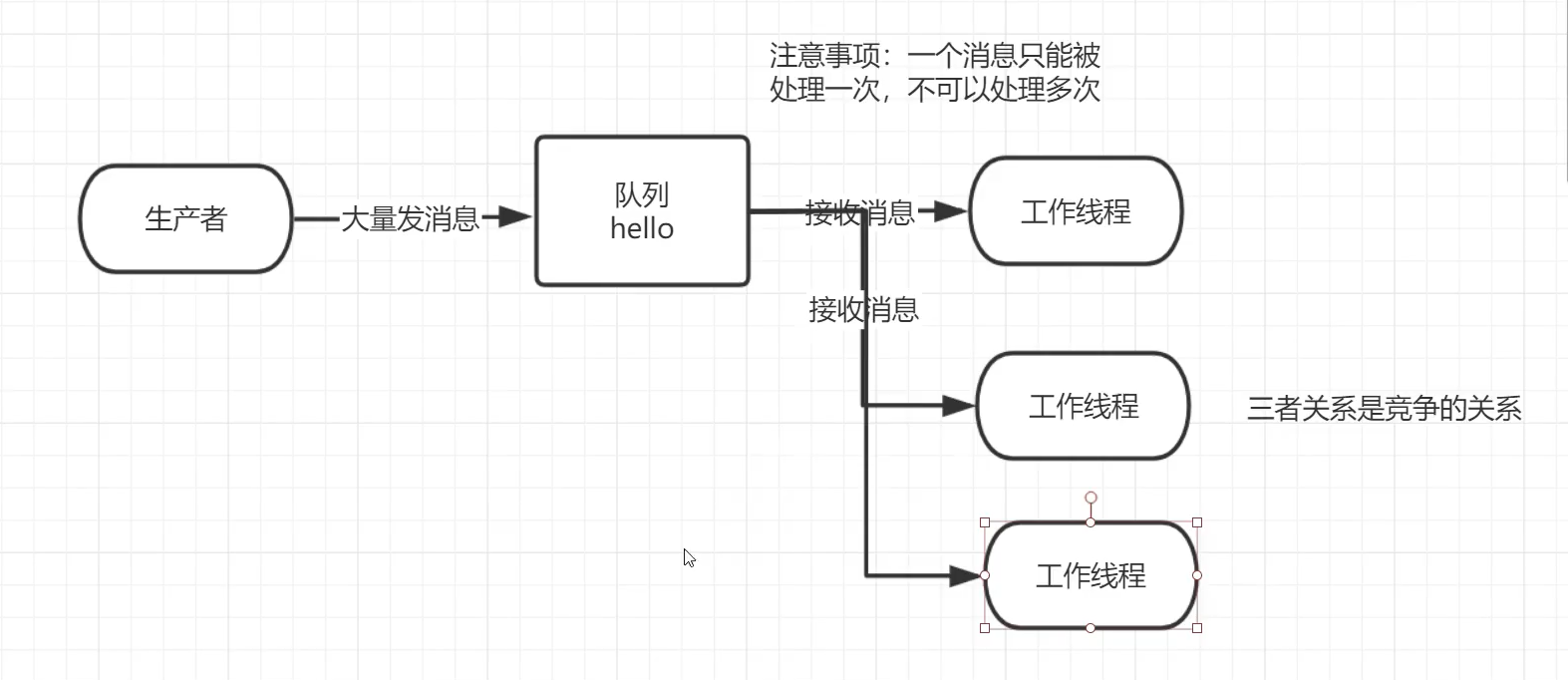
5.1. Information distribution for rotation training
Start two worker threads and one message sending thread. Let's see how the two worker threads work?
5.1.1 extraction tools
public class RabbitMQUtils {
public static Channel getChannel() throws IOException, TimeoutException {
//receive messages
//Create a connection factory that connects RabbitMQ
ConnectionFactory factory=new ConnectionFactory();
factory.setHost("39.107.103.173");
factory.setUsername("admin");
factory.setPassword("admin");
factory.setPort(5672);
Connection connection=factory.newConnection();
Channel channel=connection.createChannel();
return channel;
}
}
Worker received message code:
/**
* @author wcc
* @date 2021/11/4 10:47
* This is a worker thread, equivalent to the consumer mentioned earlier
*/
public class Worker01 {
//The name of the queue
public static final String QUEUE_NAME="hello";
//receive messages
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMQUtils.getChannel();
DeliverCallback deliverCallback=(consumeTag,message)->{
System.out.println("Received message:"+new String(message.getBody()));
};
CancelCallback cancelCallback=message ->{
System.out.println(message + "Interface callback logic for consumer to cancel consumption");
};
//Message reception
/**
* Consumer News
* 1.Which queue to consume
* 2.Whether to respond automatically after successful consumption. true means automatic response, and false means manual response
* 3.Callback function for successful consumer consumption
* 4.Consumer cancels the callback of consumption
*/
System.out.println("C2 Waiting to receive message...");
channel.basicConsume(QUEUE_NAME,true,deliverCallback,cancelCallback);
}
}
Producer generated code (console input data as message):
/**
* @author wcc
* @date 2021/11/4 11:04
* @Description Producers send a lot of messages
*/
public class Task01 {
//Queue name
public static final String QUEUE_NAME="hello";
//Send a large number of messages
public static void main(String[] args) throws Exception{
Channel channel = RabbitMQUtils.getChannel();
//queue
channel.queueDeclare(QUEUE_NAME,false,false,false,null);
//Receive information from the console
Scanner scanner=new Scanner(System.in);
while (scanner.hasNext()){
String message=scanner.next();
/**
* Send a message to the queue
* 1.To which switch
* 2.What is the key value of the route? It is the name of the queue this time
* 3.Other parameter information
* 4.The body of the message sent
*/
channel.basicPublish("",QUEUE_NAME,null,message.getBytes());
System.out.println("Send message complete:"+message);
}
}
}
According to the results of the last two worker threads receiving messages, the worker threads receive messages by polling. A message can only be processed once, not multiple times.
6. Message response
6.1 concept
It may take some time for a consumer to complete a task. What happens if one of the consumers processes a long task and only completes part of it, and suddenly it hangs up. Once RabbitMQ delivers a message to the consumer, it immediately marks the message for deletion. In this case, a consumer suddenly hangs up, and we will lose the message being processed. And subsequent messages sent to the consumer because it cannot be received.
In order to ensure that messages are not lost during reception, RabbitMQ introduces a message response mechanism. Message response is: after receiving and processing the message, the consumer tells RabbitMQ that it has been processed, and RabbitMQ can delete the message.
6.1.1 automatic response
The message is considered to have been successfully transmitted immediately after it is sent. This mode needs to make a trade-off between high throughput and data transmission security, because in this mode, if the connection is disconnected or the Channel is closed on the consumer side before the message is received, the message will be lost. On the other hand, of course, this mode can deliver overloaded messages on the consumer side, There is no limit on the number of messages delivered. Of course, this may cause consumers to receive too many messages that are too late to process, resulting in the backlog of these messages, eventually running out of memory, and finally these consumer threads are killed by the operating system, Therefore, this model is only applicable when consumers can process these messages efficiently and at a certain rate.
6.1.2 manual response
- Channel. Basicack (for positive confirmation)
- RabbitMQ already knows the message and successfully processes the message, so it can be discarded
- Channel. Basicnack (for negative confirmation)
- Channel. Basicreject (for negative confirmation)
- One less parameter than channel. Basicnack (Multiple for batch processing)
- If the message is rejected without processing, it can be discarded
The advantage of manual response is that it can respond in batches and reduce network congestion
Batch processing parameter Multiple Boolean value
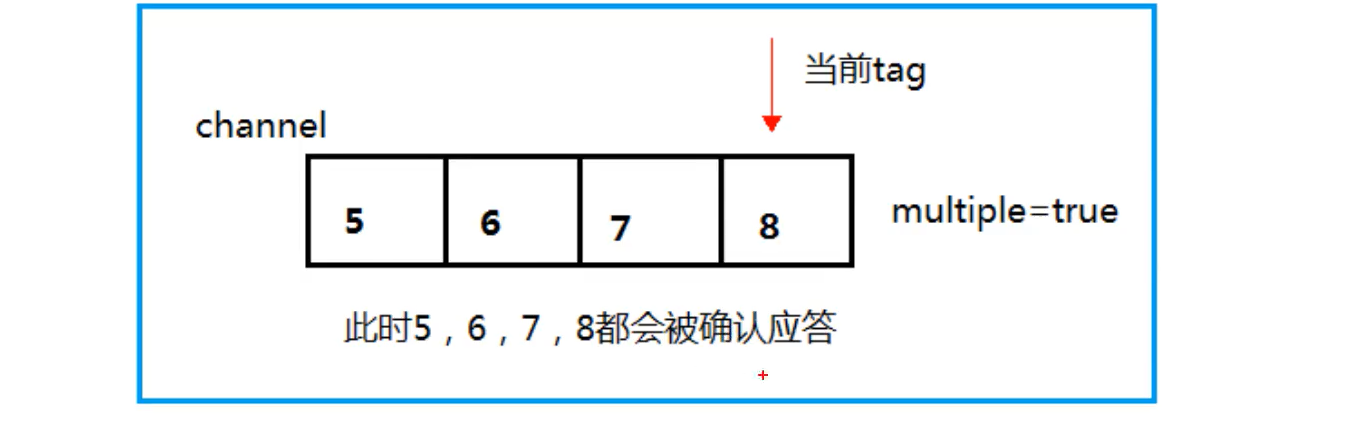
- true and false of Multiple represent different meanings
- true stands for batch answering of unacknowledged messages on the Channel
- For example, if there is a message transmitting a tag on the Channel, and the current tag of 5,6,7,8 is 8, then the unacknowledged messages of 5 ~ 8 will be confirmed to receive the message response
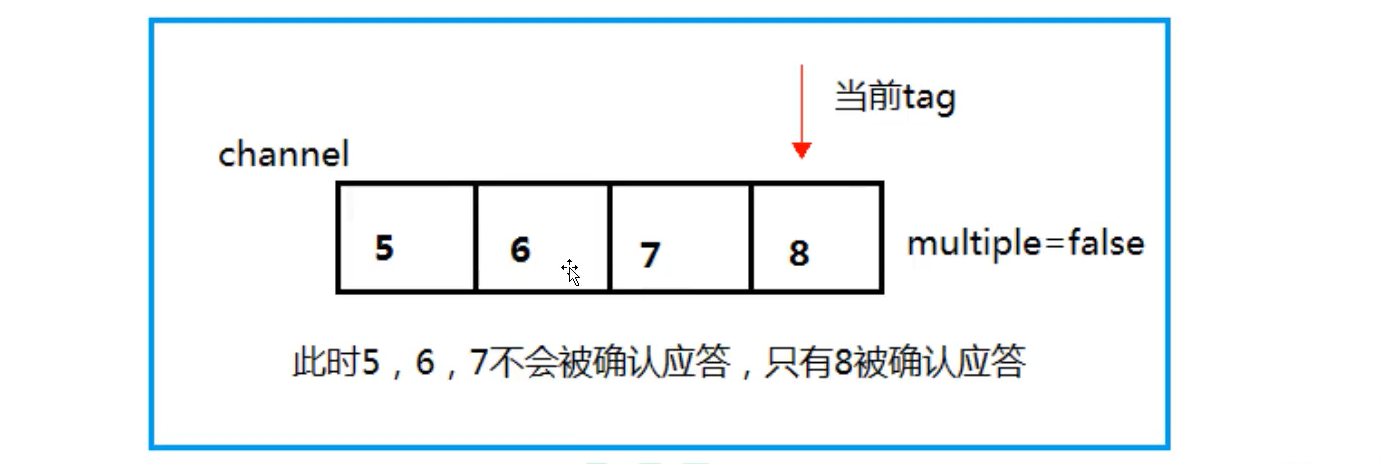
- false means that unacknowledged messages on the Channel will not be answered in batch
- Only the messages with current tag = 8 will be answered, and the three messages 5, 6 and 7 will not be confirmed to receive the message response
- true stands for batch answering of unacknowledged messages on the Channel
6.2. Message automatically rejoins the team
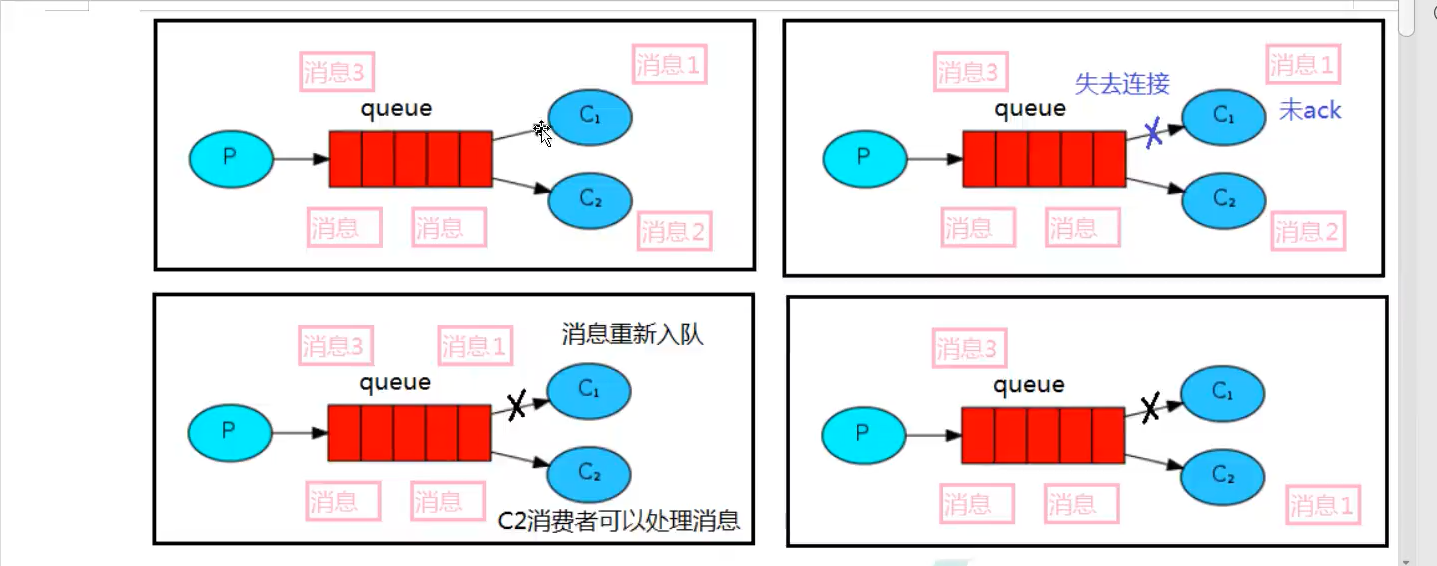
If the consumer loses the connection for some reason (its channel has been closed, the connection has been closed or the TCP connection has been lost), resulting in the message not sending ACK confirmation, RabbitMQ will understand that the message has not been fully processed and will queue it again. If other consumers can handle it at this time, it will soon redistribute it to another consumer. In this way, even if a consumer dies occasionally, it can be ensured that no message will be lost.
6.2.1 message manual response code
The default message adopts automatic response, so we need to change the automatic response to manual response in order to avoid loss in the process of message consumption.
producer:
/**
* @author wcc
* @date 2021/11/4 15:01
* Messages are not lost during manual response and are put back in the queue for re consumption
*/
public class Task02 {
//Queue name
public static final String task_queue_name = "ack_queue";
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMQUtils.getChannel();
//Declare a queue
channel.queueDeclare(task_queue_name,false,false,false,null);
//Enter from the console
Scanner scanner=new Scanner(System.in);
while (scanner.hasNext()){
String message = scanner.next();
channel.basicPublish("",task_queue_name,null,message.getBytes("UTF-8"));
}
}
}
consumer:
/**
* @author wcc
* @date 2021/11/4 15:07
* Messages are not lost during manual response and are put back in the queue for re consumption
*/
public class Worker03 {
//Queue name
public static final String task_queue_name = "ack_queue";
//receive messages
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMQUtils.getChannel();
System.out.println("C1 Short waiting time for receiving messages");
DeliverCallback deliverCallback=(consumeTag,message)->{
//Sleep for 1 second
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Received message:"+new String(message.getBody(),"UTF-8"));
//Manual response strategy
/**
* 1.The tag tag of the message indicates which message is answered
* 2.Whether to reply in batch false: indicates that messages in the channel are not replied in batch true: indicates that messages in the channel are replied in batch
*/
channel.basicAck(message.getEnvelope().getDeliveryTag(),false);
};
//Manual response is adopted. The second parameter is whether automatic response is adopted
channel.basicConsume(task_queue_name,false,deliverCallback,(message->{
System.out.println(message+"Consumer cancels message callback");
}));
}
}

After the sender sends the message dd, the C2 consumer is stopped. Normally, the C2 processes the message. However, due to its long processing time, C2 is stopped before it is processed, that is, C2 has not executed the ACK code. At this time, it will be seen that the message is received by C1, indicating that the message dd has been re queued, It is then allocated to C1 that can process the message.
7. RabbitMQ persistence
7.1 concept
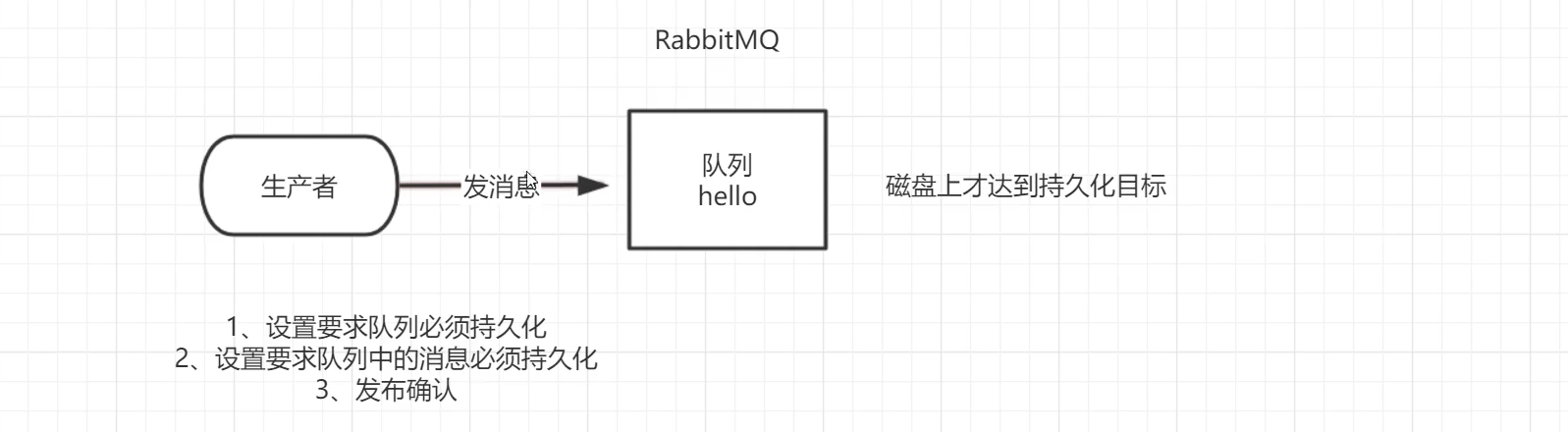
We have just seen how to handle the situation that tasks are not lost, but how to ensure that the messages sent by the message producer are not lost after the RabbitMQ service is stopped. By default, when RabbitMQ exits and crashes for some reason, it ignores queues and messages unless told not to do so. Two things need to be done to ensure that messages are not lost: we need to keep both queues and messages persistent.
7.2. How to realize queue persistence
The queues we created before are non persistent. If RabbitMQ is restarted, the queue will be deleted. If the queue is to be persistent, you need to set the durable parameter to persistent when declaring the queue
//Make the message queue persistent boolean durable = true; channel.queueDeclare(ACK_QUEUE_NAME,durable,false,false,null);
However, it should be noted that if the previously declared queue is not persistent, you need to delete the original queue or re create a persistent queue, otherwise an error will occur.
7.3 message persistence
To make the message persistent, you need to modify the code in the message producer, messageproperties.persistent_ TEXT_ Plan adds this attribute.
/**
* Send a message:
* 1.To which switch
* 2.The key value of the route is the name of the queue this time. Distribute messages to the queue according to the routing key
* 3.Other parameter information
* 4.The body of the message sent
*/
channel.basicPublish("",QUEUE_NAME,null,message.getBytes());
channel.basicPublish("",QUEUE_NAME,MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());
Marking messages as persistent does not completely guarantee that messages will not be lost. Although it tells RabbitMQ to save the message to disk, there is still an interval point where the message is still cached when it is just ready to be stored on disk. There is no real write to disk at this time. The persistence guarantee is not strong, but it is more than enough for our simple task queue. If you need a stronger persistence strategy, refer to the release confirmation section below.
7.4 unfair distribution
At the beginning, we learned that RabbitMQ distributes messages in rotation, but this strategy is not very good in a certain scenario. For example, there are two consumers processing tasks, one consumer 1 processes tasks very fast, while the other consumer 2 processes tasks very slowly. At this time, If we still use rotation training for distribution, we will understand that the fast processing consumer 1 is idle for a large part of the time, while the slow processing consumer has been working. This distribution method is not very good in this case, but RabbitMQ does not know this situation, and it is still very fair for distribution.
In order to avoid this situation (that is, to achieve more work, we can set the parameter: channel.basicQos(1);
The following is an example to demonstrate the implementation of unfair distribution:
producer:
public class Task02 {
//Queue name
public static final String task_queue_name = "ack_queue";
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMQUtils.getChannel();
//Declare a queue
channel.queueDeclare(task_queue_name,true,false,false,null);
//Enter from the console
Scanner scanner=new Scanner(System.in);
while (scanner.hasNext()){
String message = scanner.next();
channel.basicPublish("",task_queue_name,null,message.getBytes("UTF-8"));
}
}
}
consumer:
/**
* @author wcc
* @date 2021/11/4 15:07
* Messages are not lost during manual response and are put back in the queue for re consumption
*/
public class Worker03 {
//Queue name
public static final String task_queue_name = "ack_queue";
//receive messages
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMQUtils.getChannel();
System.out.println("C1 Short waiting time for receiving messages");
DeliverCallback deliverCallback = (consumeTag, message) -> {
//Sleep for 1 second
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Received message:" + new String(message.getBody(), "UTF-8"));
//Manual response strategy
/**
* 1.The tag tag of the message indicates which message is answered
* 2.Whether to reply in batch false: indicates that messages in the channel are not replied in batch true: indicates that messages in the channel are replied in batch
*/
channel.basicAck(message.getEnvelope().getDeliveryTag(), false);
};
int preCount = 1;
channel.basicQos(preCount);
//Manual response is adopted. The second parameter is whether automatic response is adopted
channel.basicConsume(task_queue_name, false, deliverCallback, (message -> {
System.out.println(message + "Consumer cancels message callback");
}));
}
}
/**
* @author wcc
* @date 2021/11/4 15:07
* Messages are not lost during manual response and are put back in the queue for re consumption
*/
public class Worker04 {
//Queue name
public static final String task_queue_name = "ack_queue";
//receive messages
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMQUtils.getChannel();
System.out.println("C2 Long waiting time for receiving messages");
DeliverCallback deliverCallback = (consumeTag, message) -> {
//Sleep for 1 second
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Received message:" + new String(message.getBody(), "UTF-8"));
//Manual response strategy
/**
* 1.The tag tag of the message indicates which message is answered
* 2.Whether to reply in batch false: indicates that messages in the channel are not replied in batch true: indicates that messages in the channel are replied in batch
*/
channel.basicAck(message.getEnvelope().getDeliveryTag(), false);
};
int preCount = 1;
channel.basicQos(preCount);
//Manual response is adopted. The second parameter is whether automatic response is adopted
channel.basicConsume(task_queue_name, false, deliverCallback, (message -> {
System.out.println(message + "Consumer cancels message callback");
}));
}
}
Test results:



RabbitMQ workflow:
This means that if I haven't finished processing this task or I haven't answered you, don't assign it to me first. I can only process one task at present, and then RabbitMQ will assign this task to the idle consumer who is not so busy. Of course, if all consumers haven't completed their tasks, the queue is still adding new tasks, The queue may be full. At this time, you can only add a new worker or change the strategy of other storage tasks.
7.4.1 pre value
The sending of messages is asynchronous, so there must be more than one message on the Channel at any time. In addition, the manual confirmation from consumers is asynchronous in nature. Therefore, there is an unacknowledged message buffer here. Therefore, we hope that developers can limit the size of this buffer to avoid unlimited unacknowledged messages in the buffer. At this time, you can set the prefetch count value by using the basic.qos method. This value defines the maximum number of unacknowledged messages allowed on the Channel. Once the number reaches the configured number, RabbitMQ will stop delivering more messages on the Channel unless at least one unprocessed message is confirmed. For example, assuming that there are unconfirmed messages 5, 6, 7 and 8 on the Channel and the prefetch count of the Channel is set to 4, RabbitMQ will not deliver any unconfirmed messages 5, 6, 7 and 8 on the Channel, And the prefetch count of the Channel is set to bit 4. At this time, RabbitMQ will not deliver any messages on the Channel unless at least one unanswered message is ACK. For example, the message tag = 6 has just been acknowledged, and RabbitMQ will perceive the situation and send another message. Message response and QoS pre value have a significant impact on user throughput. Generally, increasing prefetching will improve the speed of message delivery to consumers. Although the automatic response transmission efficiency is the best, in this case, the number of messages delivered but not processed will also increase, thus increasing the RAM consumption of consumers (random access memory). Care should be taken to use the automatic confirmation mode or manual confirmation mode with infinite preprocessing. Consumers consume a large number of messages if there is no confirmation, It will cause the memory consumption of consumers' connection nodes to become larger, so finding the appropriate pre value is a process of repeated experiments. Different load values are also different. Values in the range of 100 to 300 can usually provide the best throughput and will not bring too much risk to consumers. The pre value of 1 is the most conservative. Of course, this will make the throughput very low, especially when the consumer connection delay is very serious, especially in the environment where the consumer connection waiting time is long. For most applications, a slightly higher value will be optimal.
7.5 release confirmation
7.5.1 release confirmation principle
The producer sets the channel to Confirm mode. Once the channel enters the Confirm mode, all messages published on the channel will be assigned a unique ID (starting from 1). Once the message is delivered to all matching queues, the broker will send a confirmation to the producer (including the unique ID of the message), This makes the producer know that the message has correctly arrived at the destination queue. If the message and queue are persistent, the confirmation message will be sent after the message is written to the disk. The broker returns the multiple field of basci.ack, indicating that all messages before this serial number have been processed.
The biggest advantage of Confirm mode is that it is asynchronous. Once a message is published, the producer application can continue to send the next message while waiting for the channel to return the confirmation. After the message is finally confirmed, the producer application can process the confirmation message through the callback method. If RabbitMQ loses the message due to its internal error, A nack message is sent, and the producer application can also process the nack message in the callback method.
7.5.2 single release confirmation
This is a simple confirmation method. It is a synchronous publishing confirmation method, that is, after publishing a message, only it is published for confirmation, and subsequent messages can continue to be published. waitForConfirmsOrDie(long) returns only when the message is confirmed. If the message is not confirmed within the specified time range, it will throw an exception.
The biggest disadvantage of this confirmation method is that the publishing speed is particularly slow, because if no confirmation message is published, the publishing of all subsequent messages will be blocked. This method provides a throughput of no more than hundreds of published messages per second. Of course, this may be sufficient for some applications.
//Single release confirmation
public static void publishMessageIndividually() throws Exception{
Channel channel = RabbitMQUtils.getChannel();
//Declaration of queue
String queue_name = UUID.randomUUID().toString();
channel.queueDeclare(queue_name,true,false,false,null);
//Enable single release confirmation mode
channel.confirmSelect();
//Start time
Long begin=System.currentTimeMillis();
for (int i = 0; i < MESSAGE_COUNT; i++) {
String message=i+" ";
channel.basicPublish("",queue_name,null,message.getBytes());
//A single message is immediately released for confirmation
boolean b = channel.waitForConfirms();
if(b){
System.out.println("Message sent successfully"+(i+1));
}
}
//End time
Long end=System.currentTimeMillis();
System.out.println("release"+MESSAGE_COUNT+"Single confirmation message, time consuming:"+(end-begin));
}

7.5.3 batch release confirmation
The above single release confirmation method is very slow. Compared with a single release confirmation message, publishing a batch of messages first and then confirming them together can greatly improve the throughput. Of course, the disadvantage of this method is that when a failure causes a release problem, we don't know which message has a problem. We must save the whole batch in memory, To record important information and then republish the message. Of course, this scheme is still synchronous and blocks the release of messages.
//Batch release confirmation
public static void publishMessageBatch() throws Exception{
Channel channel = RabbitMQUtils.getChannel();
//Declaration of queue
String queue_name = UUID.randomUUID().toString();
channel.queueDeclare(queue_name,true,false,false,null);
//Enable single release confirmation mode
channel.confirmSelect();
//Start time
Long begin=System.currentTimeMillis();
int batchSize=100;
for (int i = 1; i <= MESSAGE_COUNT; i++) {
String message=i+" ";
if(i%batchSize==0){
channel.waitForConfirms();
System.out.println("Message sent successfully"+i);
}
}
//End time
Long end=System.currentTimeMillis();
System.out.println("release"+MESSAGE_COUNT+"Single confirmation message, batch confirmation time:"+(end-begin));
}

7.5.4 asynchronous release confirmation
Although the programming logic of asynchronous release confirmation is more complex than the above two synchronous release confirmation, it has the highest cost performance. It can not be said whether it is reliable or efficient. It uses callback functions to achieve reliable message delivery. This middleware also ensures whether the delivery is successful through function callback.
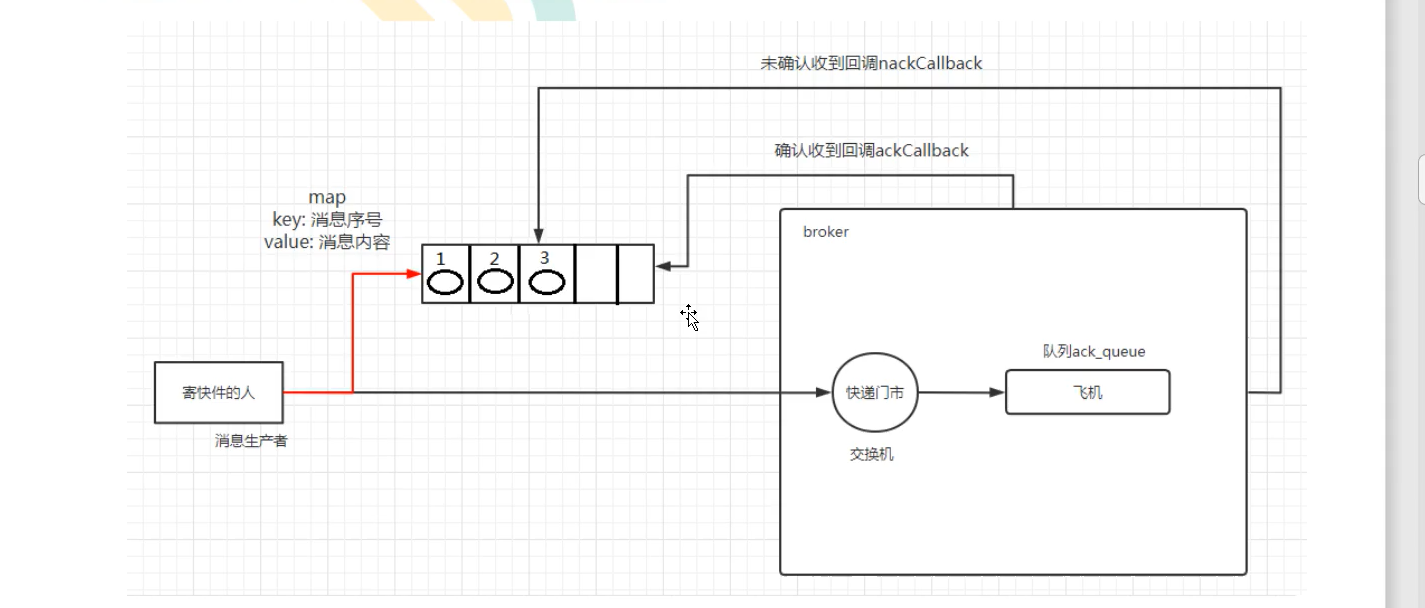
//Asynchronous publish confirmation
public static void publishMessageAsync() throws Exception{
Channel channel = RabbitMQUtils.getChannel();
//Declaration of queue
String queue_name = UUID.randomUUID().toString();
channel.queueDeclare(queue_name,true,false,false,null);
//Enable single release confirmation mode
channel.confirmSelect();
//Start time
Long begin=System.currentTimeMillis();
//Message confirmation successful callback
/**
* 1.Confirmed message ID
* 2.Batch processing
*/
ConfirmCallback var1 = (deliveryTag,multiple) ->{
System.out.println("Confirmed message:"+deliveryTag);
};
//Message confirmation failure callback
/**
* 1.Identification of the message
* 2.Is batch processing not performed
*/
ConfirmCallback var2 = (deliveryTag,multiple) ->{
System.out.println("Unacknowledged messages:"+deliveryTag);
};
//The message preparation listener listens for which messages succeed and which messages fail
/**
* 1.Listen for which messages are successfully called back
* 2.Listen for which messages failed to call back
*/
channel.addConfirmListener(var1,var2);
//Batch send messages
for (int i = 0; i < MESSAGE_COUNT; i++) {
String message=i+" ";
channel.basicPublish("",queue_name,null,message.getBytes());
}
//End time
Long end=System.currentTimeMillis();
System.out.println("release"+MESSAGE_COUNT+"Asynchronous publishing confirmation message, time consuming:"+(end-begin));
}

There will be some problems here. When sending a confirmation asynchronously, the confirmation will not end after the message is sent. At this time, the asynchronous unconfirmed message will be followed. How to deal with it?
Solution: put unconfirmed messages into a memory based queue that can be accessed by the publishing thread. For example, use the ConcurrentLinkedQueue queue to transfer messages between confirm callbacks and the publishing thread.
//Asynchronous publish confirmation
public static void publishMessageAsync() throws Exception{
Channel channel = RabbitMQUtils.getChannel();
//Declaration of queue
String queue_name = UUID.randomUUID().toString();
channel.queueDeclare(queue_name,true,false,false,null);
//Enable single release confirmation mode
channel.confirmSelect();
//Start time
Long begin=System.currentTimeMillis();
//A thread safe and orderly hash table, which is suitable for high concurrency
/**
* 1.Easily associate sequence numbers with messages
* 2.Easy batch deletion of entries as long as the serial number is given
* 3.Support high concurrency operation
*/
ConcurrentSkipListMap<Long,String> concurrentSkipListMap = new ConcurrentSkipListMap();
//Message confirmation successful callback
/**
* 1.Confirmed message ID
* 2.Batch processing
*/
ConfirmCallback var1 = (deliveryTag,multiple) ->{
if(multiple){
//Delete the confirmed messages, and the rest are unconfirmed messages
//Here, partial views of this map are returned for headMap(int), and its key value is strictly less than or equal to tokey
ConcurrentNavigableMap<Long, String> confirmed =
concurrentSkipListMap.headMap(deliveryTag);
//clear(): removes all mapping relationships from this mapping
confirmed.clear();
}else{
concurrentSkipListMap.remove(deliveryTag);
}
System.out.println("Confirmed message:"+deliveryTag);
};
//Message confirmation failure callback
/**
* 1.Identification of the message
* 2.Is batch processing not performed
*/
ConfirmCallback var2 = (deliveryTag,multiple) ->{
String message = concurrentSkipListMap.get(deliveryTag);
System.out.println("The unconfirmed message is:"+message+":::Unacknowledged messages tag:"+deliveryTag);
};
//The message preparation listener listens for which messages succeed and which messages fail
/**
* 1.Listen for which messages are successfully called back
* 2.Listen for which messages failed to call back
*/
channel.addConfirmListener(var1,var2);
//Batch send messages
for (int i = 0; i < MESSAGE_COUNT; i++) {
//When sending messages here, record the sum of all messages to be sent
String message=i+" ";
concurrentSkipListMap.put(channel.getNextPublishSeqNo()-1,message);
channel.basicPublish("",queue_name,null,message.getBytes());
}
//End time
Long end=System.currentTimeMillis();
System.out.println("release"+MESSAGE_COUNT+"Asynchronous publishing confirmation message, time consuming:"+(end-begin));
}
7.5.5 comparison of the above three release confirmation speeds
- Publish message separately
- Synchronization waiting for confirmation is simple, but the throughput is very limited
- Batch publish message
- Batch synchronization waits for confirmation, which is simple and reasonable throughput. Once a problem occurs, it is difficult to infer which message has the problem.
- Asynchronous processing
- The optimal use of resources and performance can be well controlled in case of errors, but the implementation i is slightly complex.
8. Exchanges (switches)
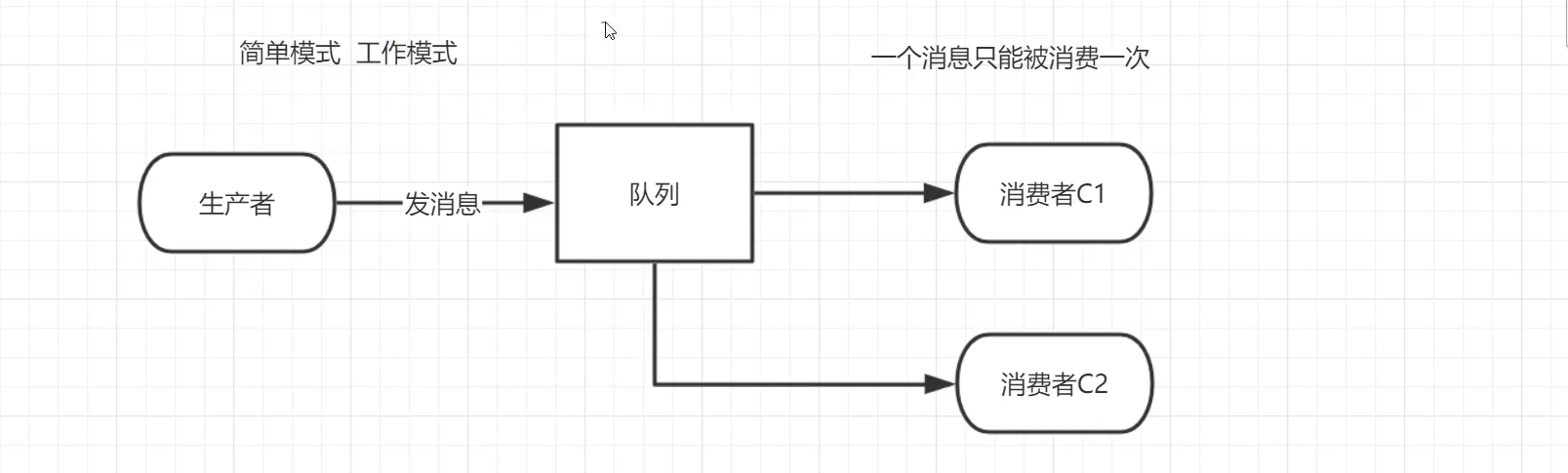
We create a queue, and we assume that behind the work queue, each task is delivered to exactly one consumer (work process). In this section, we will do something completely different - we will convey the message to multiple consumers. This pattern is called publish / subscribe.
8.1 concept
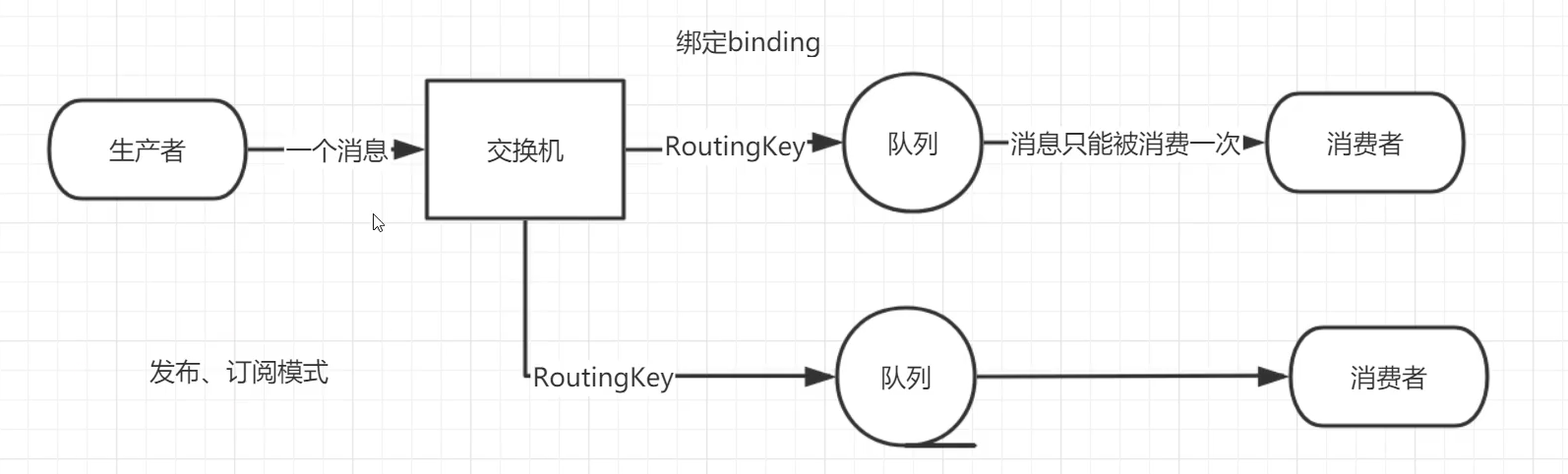
The core idea of RabbitMQ messaging model is that messages produced by producers are never sent directly to queues. In fact, usually producers don't even know which queues these messages are delivered to.
On the contrary, the producer can only send messages to the Exchange. The work of the Exchange is very simple. On the one hand, it receives messages from the producer, on the other hand, it pushes them into the queue. The switch must know exactly how to process the received message. Should these messages be placed in a specific queue, or should they be placed in many queues, or should they be discarded. This is determined by the type of switch.
8.2 types of Exchanges
There are the following types:
direct, topic, headers, fanyt
8.2.1. Default switch
When we send messages to consumers without setting up a switch, we can still send messages to the queue. The switch used is the default switch, which is identified by an empty string ("").
channel.basicPublish("",queue_name,null,message.getBytes());
The first parameter is the name of the switch. An empty string indicates the default or unnamed switch: messages can be routed to the queue, which is actually specified by * * routingKey(bindingKey) * * binding key, if it exists
8.2.2 temporary queue
In the previous example, we used queues with specific names (remember hello and ack_queue?). The name of the queue is very important to us – we need to specify which queue of messages our consumers consume.
Whenever we connect to RabbitMQ, we need a new empty queue. Therefore, we can create a queue with random name, or let the server choose a random queue name for us. Secondly, once we disconnect the consumer, the queue will be deleted automatically.
8.2.3. bindings
**What is binding? (bindbindings) * * bindings is actually a bridge between exchange and queue. It tells us which queue exchange is bound to.
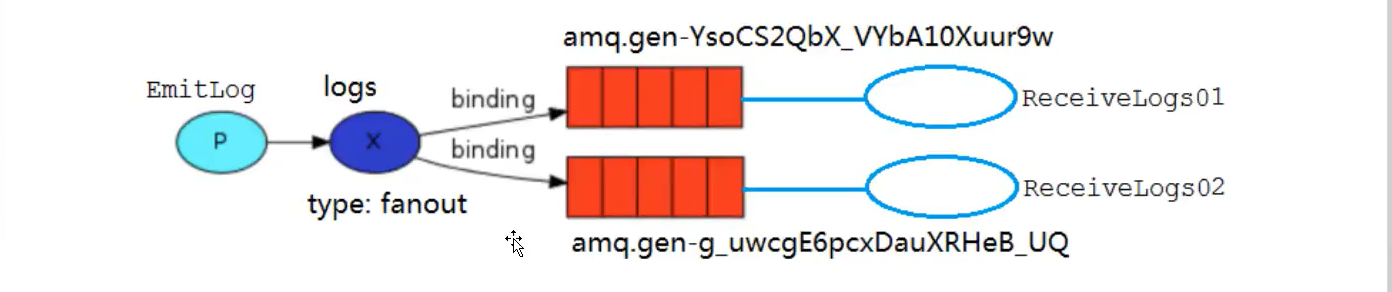
8.3. Fanout (outgoing switch)
Fanout is a very simple type. As you can guess from the name, it broadcasts all received messages to all queues it knows. There are some exchange types in the system by default
What is message idempotency?
When consumers repeatedly consume a message, the result of repeated consumption is the same as that of one consumption, and multiple consumption does not have any negative impact on the business system, then the whole process can achieve message idempotence.
producer
/**
* @author wcc
* @date 2021/11/10 17:54
* Send message to switch
*/
public class EmitLog {
//Name of the switch
public static final String EXCHANGE_NAME="logs";
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMQUtils.getChannel();
channel.exchangeDeclare(EXCHANGE_NAME,"fanout");
Scanner sc =new Scanner(System.in);
while (sc.hasNext()){
String message = sc.next();
/**
* First parameter: switch name
* The second parameter: routing key
* Third parameter: other configuration information
* Fourth parameter: message data
*/
channel.basicPublish(EXCHANGE_NAME,"",null,message.getBytes());
System.out.println("The message sent by the producer is:"+message);
}
}
}
Consumer 01 Code:
/**
* @author wcc
* @date 2021/11/10 15:44
* Message reception
*/
public class ReceiveLogs01 {
//Name of the switch
public static final String EXCHANGE_NAME="logs";
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMQUtils.getChannel();
//Declare a switch
channel.exchangeDeclare(EXCHANGE_NAME,"fanout");
//Declare a temporary queue
/**
* Generate a temporary queue whose name is random
* The queue is automatically deleted when the consumer disconnects from the queue
*/
String queue = channel.queueDeclare().getQueue();
//Binding switches and queues
channel.queueBind(queue,EXCHANGE_NAME,"");
System.out.println("ReceiveLogs01 Wait for the received message and print the received message on the screen....");
DeliverCallback deliverCallback=(consumeTag,message)->{
System.out.println("ReceiveLogs01 The console prints the received message:"+new String(message.getBody(),"UTF-8"));
};
channel.basicConsume(queue,true,deliverCallback,consumeTag->{});
}
}
Consumer 02 Code:
/**
* @author wcc
* @date 2021/11/10 15:44
* Message reception
*/
public class ReceiveLogs02 {
//Name of the switch
public static final String EXCHANGE_NAME="logs";
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMQUtils.getChannel();
//Declare a switch
channel.exchangeDeclare(EXCHANGE_NAME,"fanout");
//Declare a temporary queue
/**
* Generate a temporary queue whose name is random
* The queue is automatically deleted when the consumer disconnects from the queue
*/
String queue = channel.queueDeclare().getQueue();
//Binding switches and queues
channel.queueBind(queue,EXCHANGE_NAME,"");
System.out.println("ReceiveLogs02 Wait for the received message and print the received message on the screen....");
DeliverCallback deliverCallback=(consumeTag,message)->{
System.out.println("ReceiveLogs02 The console prints the received message:"+new String(message.getBody(),"UTF-8"));
};
channel.basicConsume(queue,true,deliverCallback,consumeTag->{});
}
}
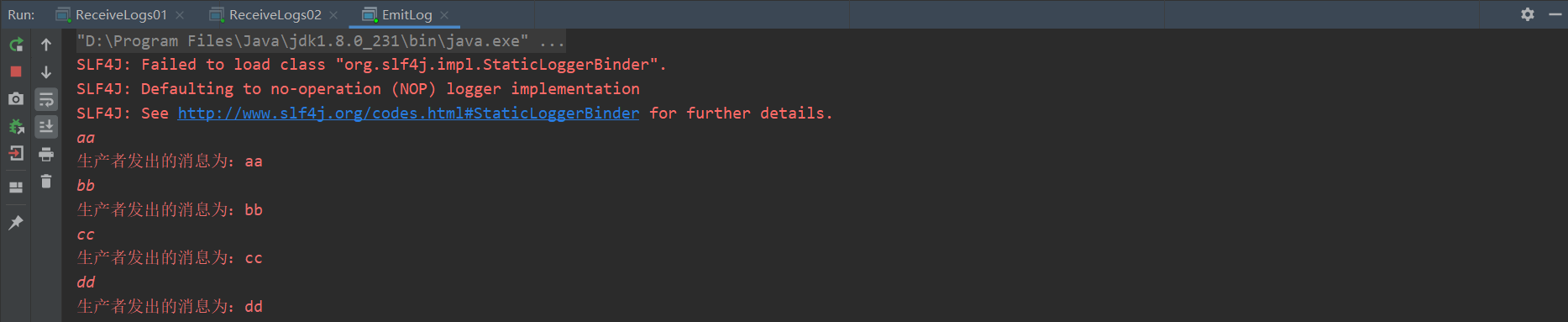
The results are as follows:


8.4. Direct exchange
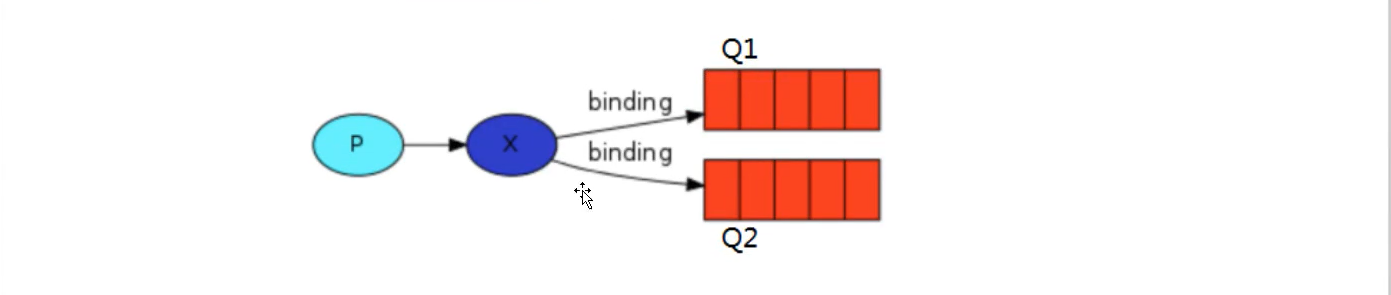
Last time, our log system broadcast all messages to all consumers. We want to make some changes. For example, we want the program that writes log messages to disk to only receive serious errors without storing warning s or info log messages, so as to avoid wasting disk space. Fanout does not bring us much flexibility. It can only broadcast unconsciously. Here, we will replace it with direct. The working mode of this type is that messages can only go to the routingKey queue bound to it.
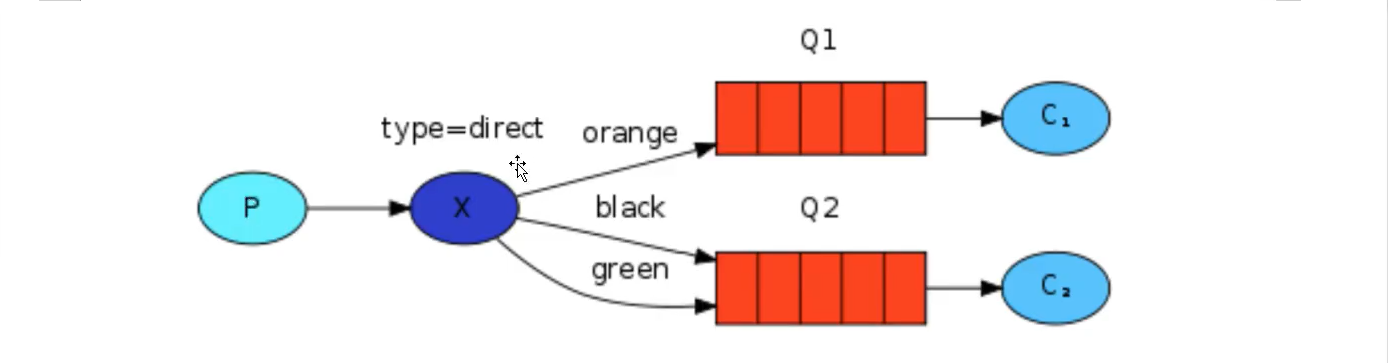
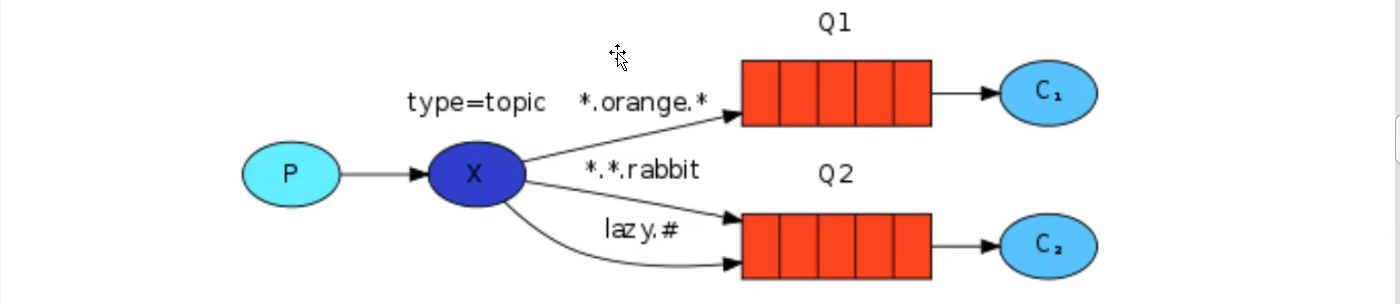
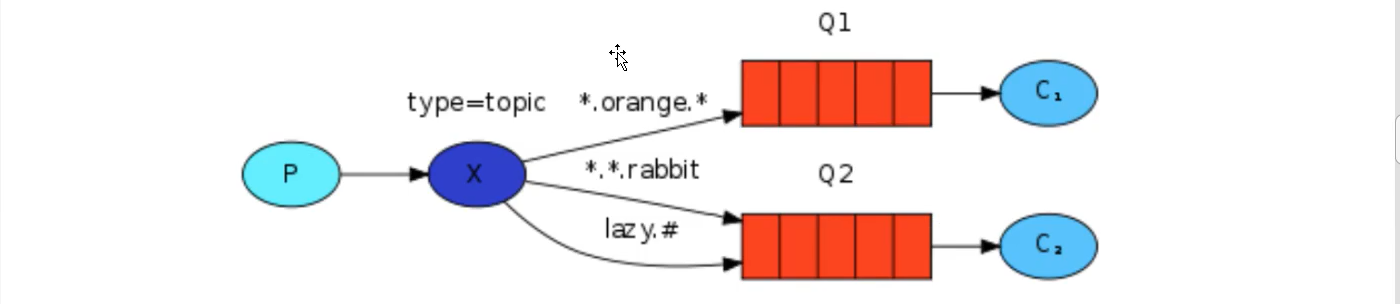
In the above figure, we can see that switch X binds two queues, and the binding type is direct. The binding key of queue Q1 is orange, and there are two binding keys of queue Q2: one is black and the other is green.
In this binding case, the producer publishes messages to exchange, messages with the binding key orange will be published to queue Q1, messages with the binding keys black and green will be published to queue Q2, and messages of other message types will be discarded.
Direct switches also support multiple bindings
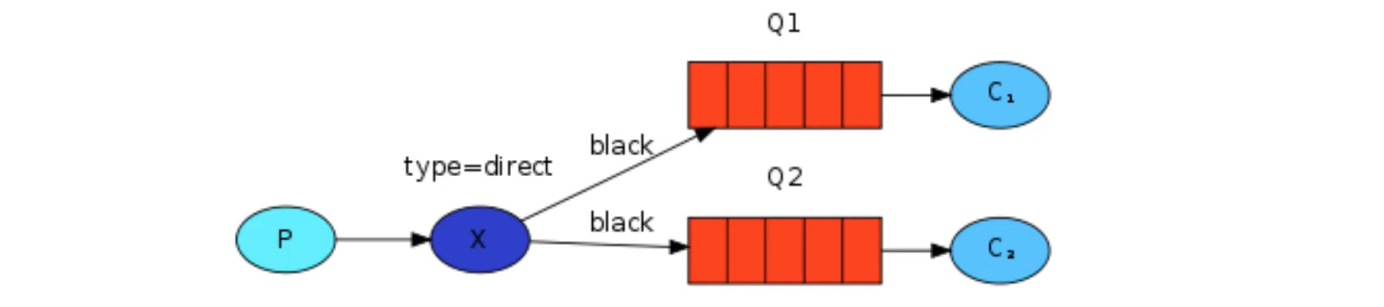
Of course, if the binding type of exchange is direct, but the key s of multiple queues bound to it are the same, in this case, although the binding type is direct, its performance is somewhat similar to that of fanout, which is almost like broadcasting.
Code demonstration:
/**
* @author wcc
* @date 2021/11/11 10:16
* producer
*/
public class DirectLogs {
//Name of the switch
public static final String EXCHANGE_NAME = "direct_logs";
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMQUtils.getChannel();
Scanner scanner=new Scanner(System.in);
while (scanner.hasNext()){
String message=scanner.next();
/**
* First parameter: the name of the switch
* The second parameter: routing key
* Third parameter: other configuration information
* Fourth parameter: message data
*/
channel.basicPublish(EXCHANGE_NAME,"error",null,message.getBytes("UTF-8"));
System.out.println("Message sent by producer:"+message);
}
}
}
Note that to realize the direct sending feature here, you only need to change the routingKey of the message sent by the producer to correspond to different consumers. (a consumer can also support multiple binding, that is, a consumer can bind the same queue multiple times and set different routingkeys to achieve the effect of multiple binding).
/**
* @author wcc
* @date 2021/11/10 21:30
* Consumer 1
*/
public class ReceiveLogsDirect01 {
public static final String EXCHANGE_NAME="direct_logs";
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMQUtils.getChannel();
//Declare a switch
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.DIRECT);
//Declare a queue
channel.queueDeclare("console", false, false, false, null);
/**
* Binding switches and queues
*/
channel.queueBind("console",EXCHANGE_NAME,"info");
channel.queueBind("console",EXCHANGE_NAME,"warning");
DeliverCallback deliverCallback=(consumeTag, message)->{
System.out.println("ReceiveLogsDirect01 The console prints the received message:"+new String(message.getBody(),"UTF-8"));
};
//The second parameter represents whether to answer automatically
channel.basicConsume("console",true,deliverCallback,consumeTag->{});
}
}
/**
* @author wcc
* @date 2021/11/10 21:30
* Consumer 2
*/
public class ReceiveLogsDirect02 {
public static final String EXCHANGE_NAME="direct_logs";
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMQUtils.getChannel();
//Declare a switch
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.DIRECT);
//Declare a queue
channel.queueDeclare("disk", false, false, false, null);
/**
* Binding switches and queues
*/
channel.queueBind("disk",EXCHANGE_NAME,"error");
DeliverCallback deliverCallback=(consumeTag, message)->{
System.out.println("ReceiveLogsDirect02 The console prints the received message:"+new String(message.getBody(),"UTF-8"));
};
//The second parameter represents whether to answer automatically
channel.basicConsume("disk",true,deliverCallback,consumeTag->{});
}
}
8.5. Topic switch
In the previous example, we improved the logging system. Instead of using a fanout switch that can only broadcast at will, we use a direct switch to selectively accept logs.
Although the use of direct switch improves our system, it still has limitations - for example, the types of days we want to receive are info.base and info.advanced. A queue only wants to receive info.base messages, so direct can't do it at this time. At this time, topic type switches appear.
The routingKey of the message sent to the topic switch cannot be written arbitrarily. It must meet certain requirements. It must be a word list separated by a dot. These words can be any word, such as stock.usd.nyse, nyse.vmw. Of course, note that the word list cannot exceed 255 bytes at most.
In this rule list, there are two substitutes that you should pay attention to:
- *(asterisk) can replace a word
- #(pound sign) can replace zero or more words
Attention should be paid when the queue binding relationship is the following:
- When the binding key of a queue is #, the queue will receive all data, which is a bit like fanout
- If there is no # and * in the queue binding key, the queue binding type is direct
Producer code
/**
* @author wcc
* @date 2021/11/11 11:27
* producer
*/
public class EmitLogsTopic {
//Name of the switch
public static final String EXCHANGE_NAME = "topic_logs";
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMQUtils.getChannel();
/**
* The binding relationship with consumers is:
* Q1 --> Bound is
* String with 3 words in the middle (*. orange. *)
* Q2 --> Bound is
* The last word is three words of rabbit (*. *. rabbit)
* The first word is multiple words of lazy (lazy. #)
*/
Map<String,String> bindingMap = new HashMap<>();
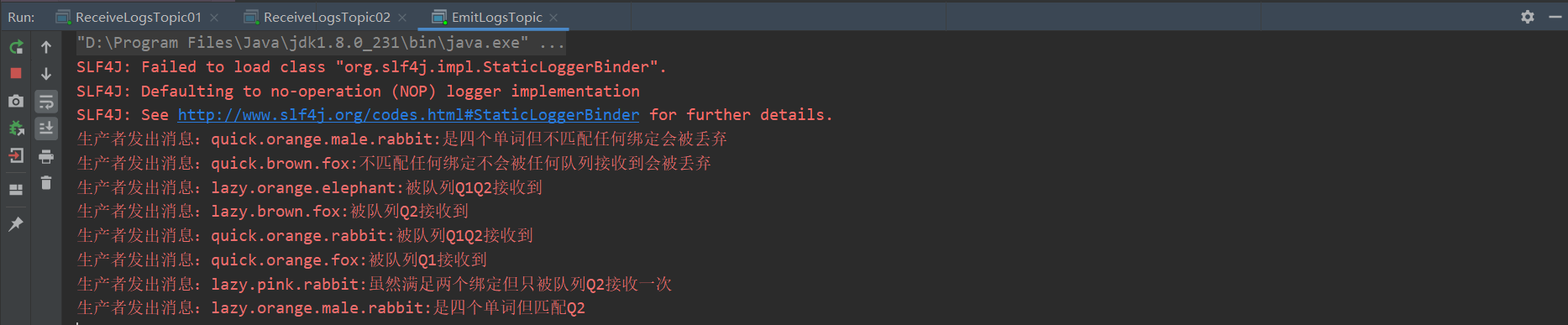
bindingMap.put("quick.orange.rabbit","By queue Q1Q2 Received");
bindingMap.put("lazy.orange.elephant","By queue Q1Q2 Received");
bindingMap.put("quick.orange.fox","By queue Q1 Received");
bindingMap.put("lazy.brown.fox","By queue Q2 Received");
bindingMap.put("lazy.pink.rabbit","Although two bindings are satisfied, they are only used by the queue Q2 Receive once");
bindingMap.put("quick.brown.fox","Any binding that does not match will not be received by any queue and will be discarded");
bindingMap.put("quick.orange.male.rabbit","Is four words but does not match. Any binding will be discarded");
bindingMap.put("lazy.orange.male.rabbit","It's four words, but it doesn't match Q2");
for (Map.Entry<String, String> entry : bindingMap.entrySet()) {
String key = entry.getKey();
String message = entry.getValue();
channel.basicPublish(EXCHANGE_NAME,key,null,message.getBytes("UTF-8"));
System.out.println("Producer sends message:"+key+":"+message);
}
}
}
Consumer 01 code
/**
* @author wcc
* @date 2021/11/11 11:15
* Declare the subject switch and related queues
* Consumer 1
*/
public class ReceiveLogsTopic01 {
//Switch name
public static final String EXCHANGE_NAME = "topic_logs";
public static void main(String[] args) throws IOException, TimeoutException {
//receive messages
Channel channel = RabbitMQUtils.getChannel();
//Claim switch
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.TOPIC);
//Declaration queue
channel.queueDeclare("Q1",false,false,false,null);
/**
* First parameter: queue name
* Second parameter: switch name
* The third parameter: routingKey
*/
channel.queueBind("Q1",EXCHANGE_NAME,"*.orange.*");
System.out.println("ReceiveLogsTopic01 Waiting to receive message...");
DeliverCallback deliverCallback=(consumeTag, message)->{
System.out.println("ReceiveLogsTopic01 The console prints the received message:"+new String(message.getBody(),"UTF-8"));
System.out.println("Receive queue:"+"Q1"+" Binding key:"+message.getEnvelope().getRoutingKey());
};
//The second parameter represents whether to answer automatically
channel.basicConsume("Q1",true,deliverCallback,consumeTag->{});
}
}
Consumer 02 code
/**
* @author wcc
* @date 2021/11/11 11:15
* Declare the subject switch and related queues
* Consumer 2
*/
public class ReceiveLogsTopic02 {
//Switch name
public static final String EXCHANGE_NAME = "topic_logs";
public static void main(String[] args) throws IOException, TimeoutException {
//receive messages
Channel channel = RabbitMQUtils.getChannel();
//Claim switch
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.TOPIC);
//Declaration queue
channel.queueDeclare("Q2",false,false,false,null);
/**
* First parameter: queue name
* Second parameter: switch name
* The third parameter: routingKey
*/
channel.queueBind("Q2",EXCHANGE_NAME,"*.*.rabbit");
channel.queueBind("Q2",EXCHANGE_NAME,"lazy.#");
System.out.println("ReceiveLogsTopic02 Waiting to receive message...");
DeliverCallback deliverCallback=(consumeTag, message)->{
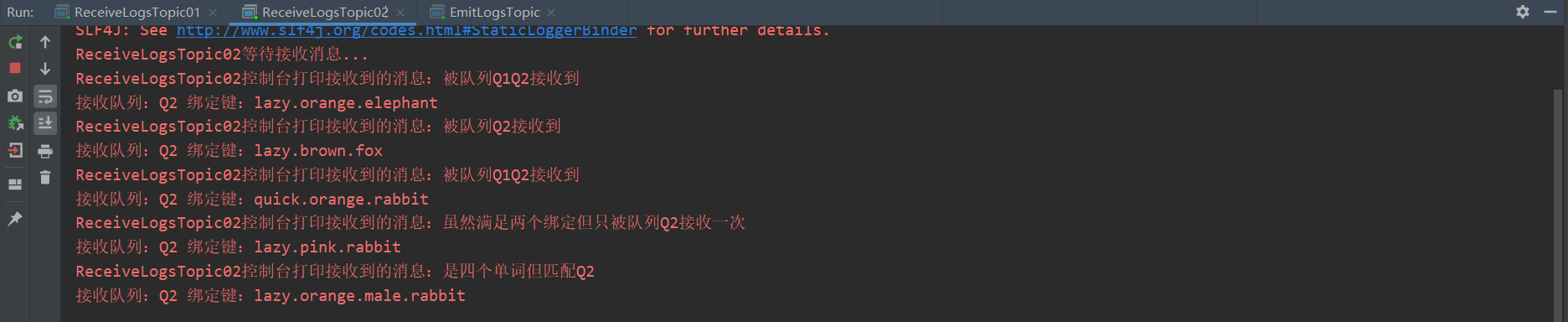
System.out.println("ReceiveLogsTopic02 The console prints the received message:"+new String(message.getBody(),"UTF-8"));
System.out.println("Receive queue:"+"Q2"+" Binding key:"+message.getEnvelope().getRoutingKey());
};
//The second parameter represents whether to answer automatically
channel.basicConsume("Q2",true,deliverCallback,consumeTag->{});
}
}
The test results are as follows:

At this point, the introduction to RabbitMQ is over, and the advanced part will be updated in another article.