title: consistency Hash algorithm and Java implementation
date: 2022/1/15 15:15:30
Application fields of consistent Hash algorithm
For the consistent Hash algorithm, we can see its shadow in many places:
- Redis
- Nginx
- Dubbo
- ElasticSearch
- Hadoop
- Distributed database
- Other distributed data storage scenarios
Explain consistency Hash algorithm in detail
Taking cache as an example, let's think about why consistent Hash algorithm is frequently used in the above scenarios. For previous high concurrency scenarios, our usual processing methods are as follows:
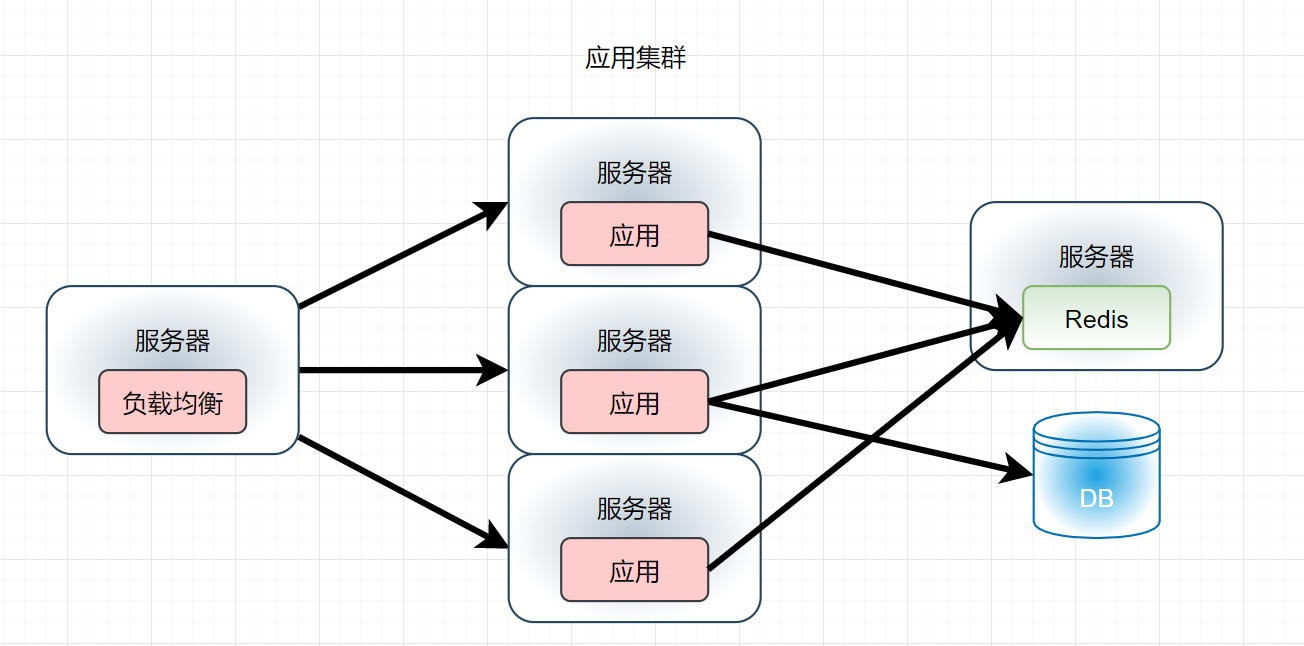
- You should also know about Redis's 10W concurrency, but what if the concurrency reaches 30W? However, it is not difficult for us to solve this problem, because since the application can add clusters, the cache can also add distributed cache clusters:
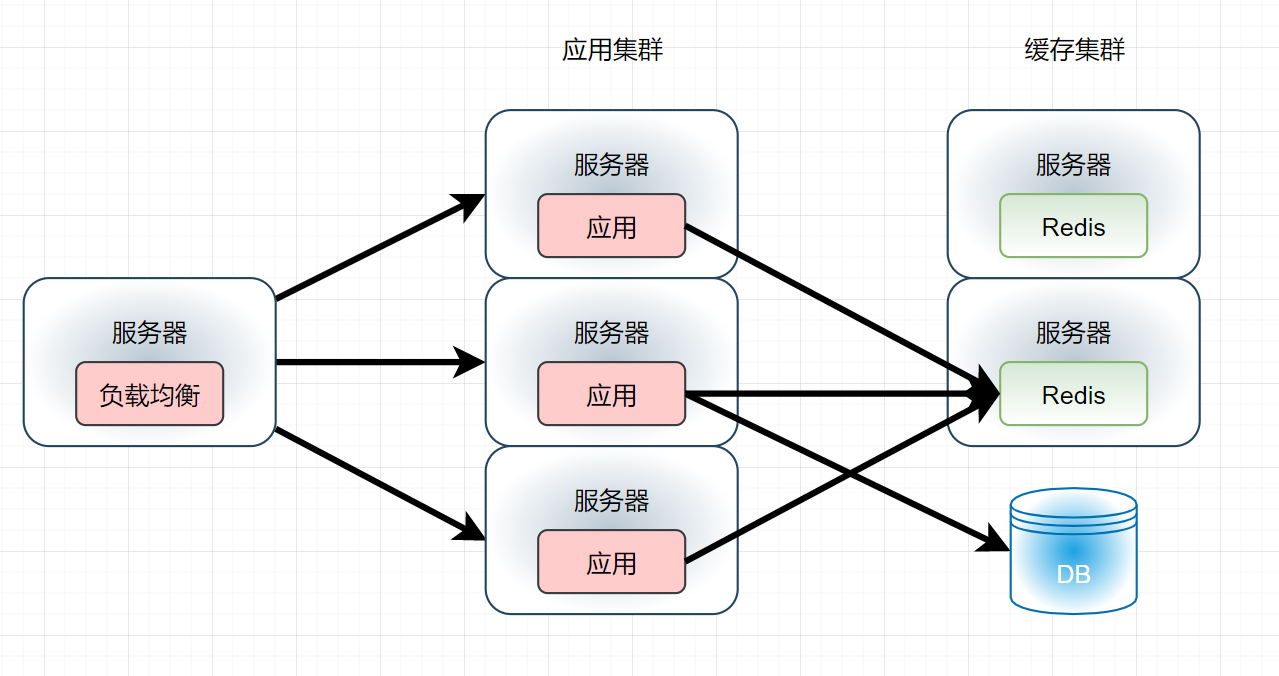
But is it really that simple? First, think about a problem. What should I do when the massive cache data has exceeded the memory capacity of a single cache server? Of course, the answer should be: divide the massive data into several parts and cache them on each cache server. Then think about another problem. For massive data, how can we make it evenly distributed on each node of the cache cluster? If it is not evenly distributed to all nodes and a large number of caches are always stored on a cache server, what is the purpose of deploying cache clusters? There are several good solutions to this problem:
hash(key)% number of cluster nodes
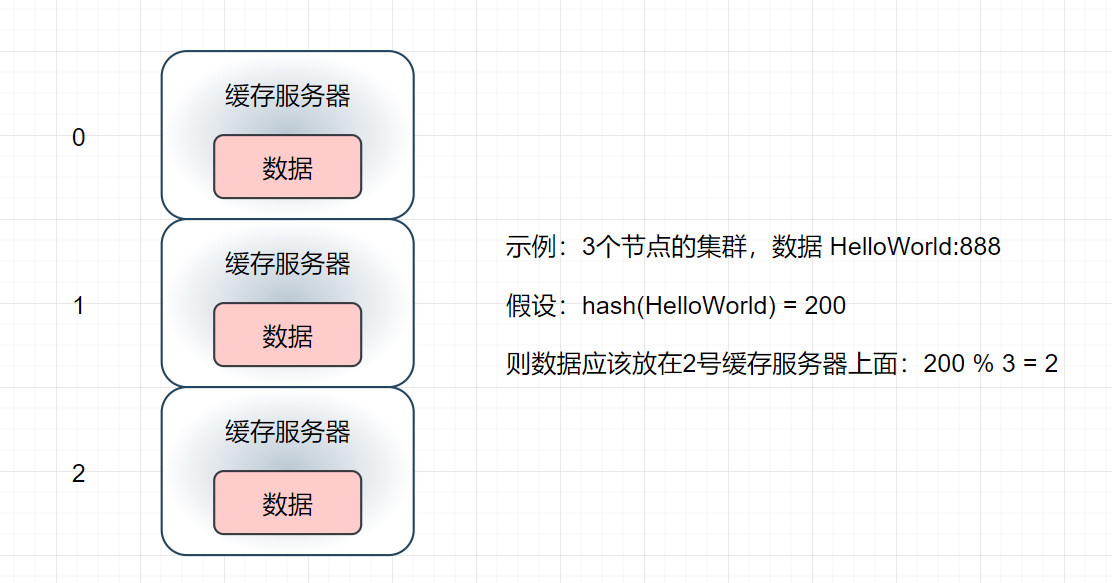
- There will be a problem with this scheme. When we temporarily decide to add a server to improve the cluster performance due to business needs, will it affect the original cached data?
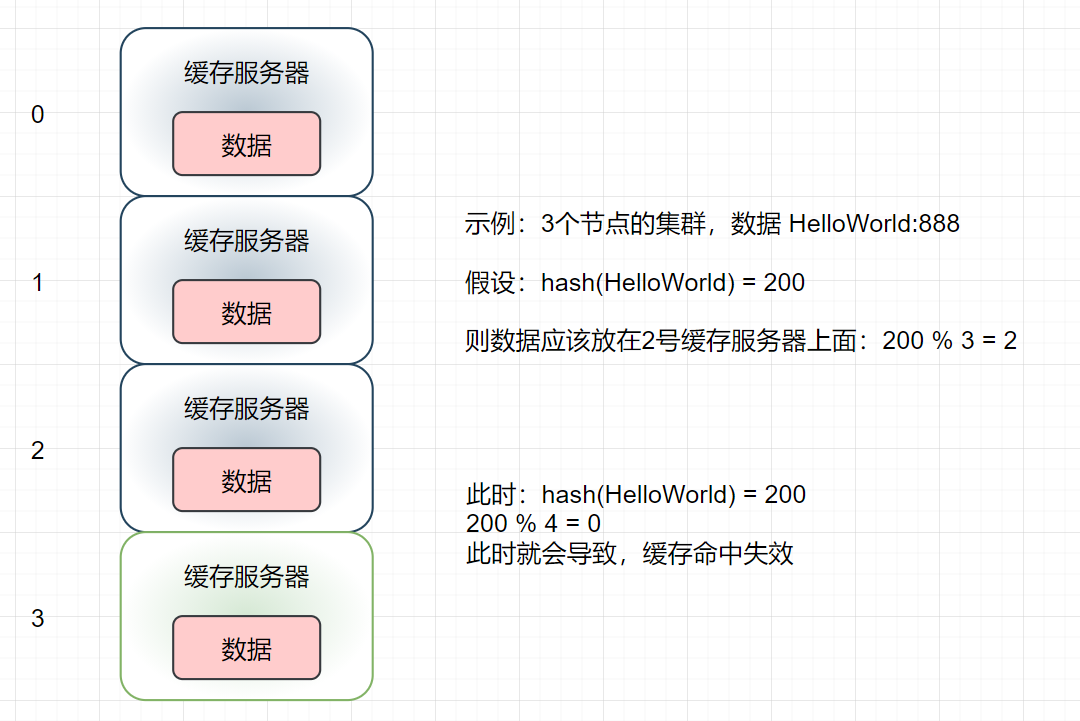
- After simple calculation, when the original 3 cache servers are increased to 4, 3 / 4 of our cache data will become invalid. Similarly, if there are 99 original cache servers and their capacity is expanded to 100, 99 / 100 of the cache data will become invalid! This is the result that cannot be received in the production environment. A large number of cache failures and a large number of requests directly access the database. Isn't this the consequence of cache avalanche?
Consistent Hash algorithm
Consistent Hash ring
Firstly, some characteristics of consistency Hash are given, where max = 232-1, that is, the maximum value of int
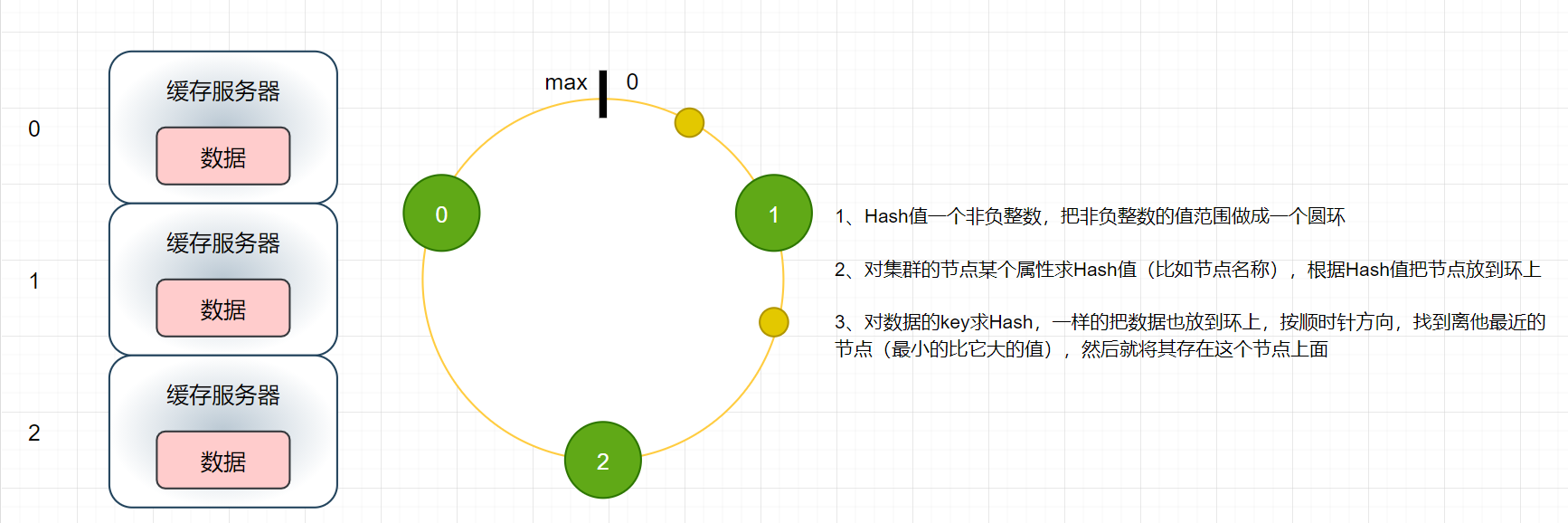
- For the same question, what impact will adding a cache server have on the original cache?
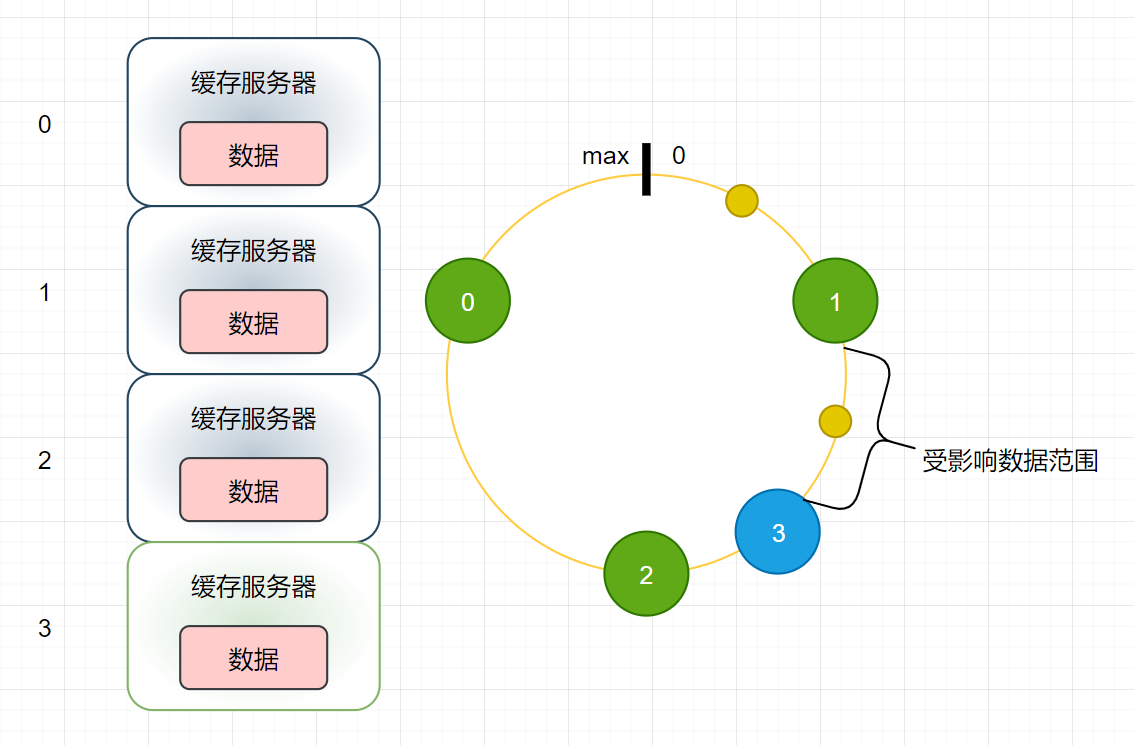
-
It is easy to deduce that the affected data range is related to the difference between the new node and the previous node, which can be easily compared. This error is much smaller than the previous pure Hash remainder
Now start to think about two questions. Can the new nodes balance the pressure of the original nodes in the link? Will the nodes of the cluster be evenly distributed over the ring?
-
For the first question, the answer is No. for example, No. 3 in the above figure can only share the pressure from No. 2 server, but can not share the pressure from No. 0 and No. 1
-
For the second question, the answer is no, because the figure only shows that under an ideal condition, the hash value calculated according to the service attributes will not be strictly uniform
Virtual node
In order to solve the above two problems, the concept of virtual node is introduced:
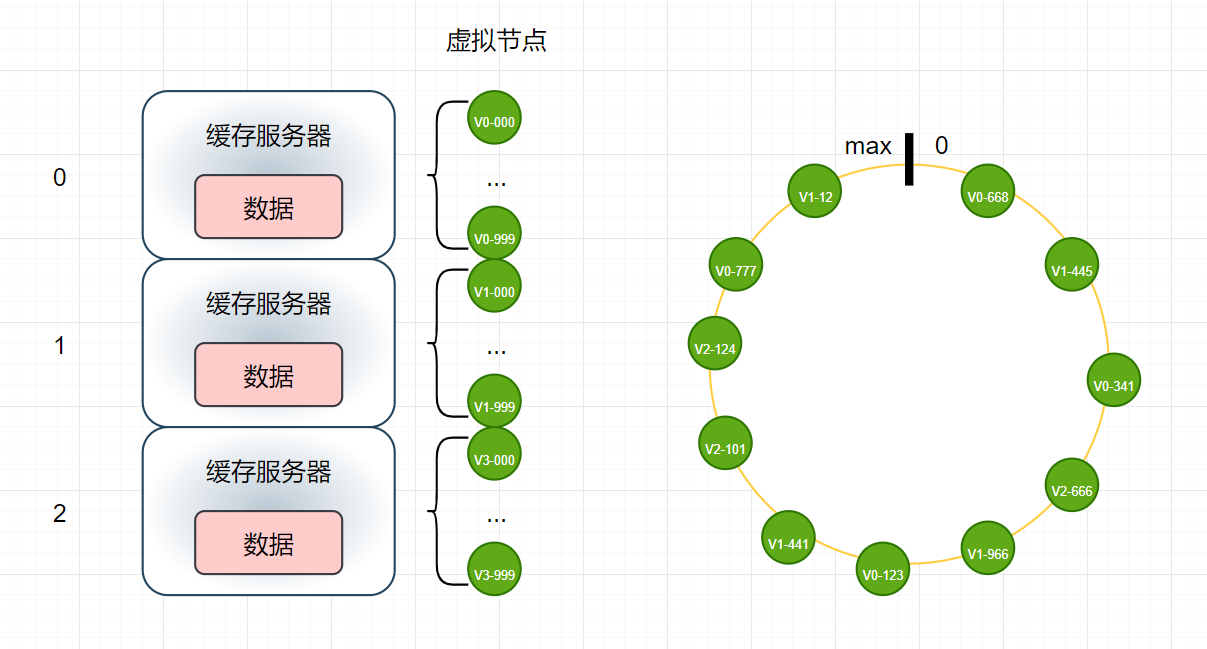
- Add another cache server:
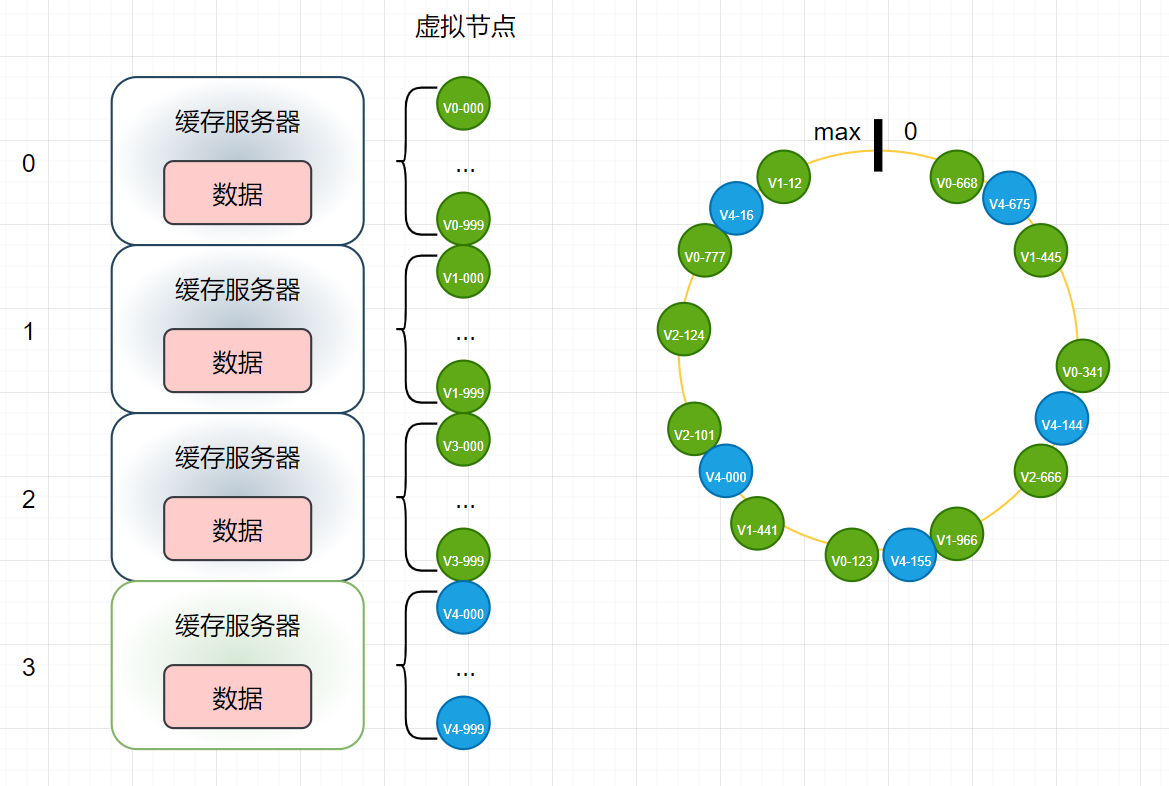
- It is obvious from the figure that the more virtual nodes, the more balanced the distribution will be (the first problem), and the more balanced the impact of new nodes on the original nodes (the second problem). Further, it can be calculated that after adding new nodes, the proportion of cache invalidation will be only 1/n (n represents the number of original servers)
If you know about Redis distributed cache, you will know the concept of one hash slot. There are 16384 (214) built-in hash slots. Its essence is still a virtual node, but the hash slot is divided at the beginning. When there is only one node, all hash slots will be allocated to it. If a node is added, Half of the original nodes will be transferred out. If you continue to add another node, one third of the slots will be transferred out of the original two nodes, and so on
A consistent Hash algorithm for handwriting
Before implementing the consistent Hash algorithm, let's review what we need to do:
- Physical node
- Virtual node
- Hash algorithm. The hash value hash obtained by the HashCode method provided by Java by default is not very good, and there will be negative values (absolute values can be taken). There are many hash algorithms on the market, such as CRC32_HASH,FNV1_32_HASH,KETAMA_HASH (consistent hash algorithm recommended by MemCache), we use fnv1 here_ 32_ Hash algorithm
private static int getHash(String string) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < string.length(); i++) {
hash = (hash ^ string.charAt(i)) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
return hash < 0 ? Math.abs(hash) : hash;
}
- If we look at the consistency Hash ring clockwise, it is actually a sorted set. When adding nodes, we should also ensure that the original set is orderly (it can be extended that for the sorted data set, the fastest way to find elements is to use binary search). What data structure is used at this time? Array is not very friendly to insertion. Linked list can't realize binary search. What about tree? The answer is the red black tree. At this time, we need to use the TreeMap in the collection framework. Its bottom layer is implemented by the red black tree!
- How virtual nodes are placed on the ring
- How to find the corresponding virtual node
The complete code is as follows:
import lombok.Data;
import java.util.*;
/**
* @author PengHuanZhi
* @date 2022 17:08, January 15
*/
@Data
public class ConsistenceHash {
/**
* Number of virtual nodes
**/
private int virtualNums = 100;
/**
* Physical node
**/
private List<String> realNodes = new ArrayList<>();
/**
* Correspondence
**/
private Map<String, List<Integer>> real2VirtualNodeMap = new HashMap<>();
/**
* Consistent Hash ring
**/
private SortedMap<Integer, String> hashRing = new TreeMap<>();
/**
* Add server
*
* @param node Real node
**/
public void addServer(String node) {
realNodes.add(node);
//How many virtual nodes are virtual
String visualNode;
List<Integer> virNodes = new ArrayList<>(virtualNums);
real2VirtualNodeMap.put(node, virNodes);
for (int i = 0; i < virtualNums; i++) {
visualNode = node + "-" + i;
//Put it on the ring
//1. The hash value is calculated. Because the hash value obtained by the HashCode method provided by Java by default is not very good, we adopt a new HashCode algorithm
int hash = getHash(visualNode);
//2. Put it on the ring
hashRing.put(hash, node);
//3. Save correspondence
virNodes.add(hash);
}
}
/**
* Find the storage node of the data
*
* @param virtualNode Virtual node key
* @return Return real node
*/
public String getServer(String virtualNode) {
int hashValue = getHash(virtualNode);
SortedMap<Integer, String> subMap = hashRing.tailMap(hashValue);
if (subMap.isEmpty()) {
//Data should be placed on the smallest node
return hashRing.get(hashRing.firstKey());
}
return subMap.get(subMap.firstKey());
}
/**
* Remove node
*
* @param node Node name
**/
public void removeNode(String node) {
realNodes.remove(node);
real2VirtualNodeMap.remove(node);
String visualNode;
for (int i = 0; i < virtualNums; i++) {
visualNode = node + "-" + i;
int hash = getHash(visualNode);
hashRing.remove(hash);
}
}
/**
* FNV1_32_HASH algorithm
*
* @param string key
* @return int Returns the Hash value
**/
private static int getHash(String string) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < string.length(); i++) {
hash = (hash ^ string.charAt(i)) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
return hash < 0 ? Math.abs(hash) : hash;
}
}