re module in python
The main function of re module in Python is to match and process strings through regular expressions
Step 1: import re
After importing the module, you can use all the methods and properties under the module
import re
re has many methods and properties
The re module provides many useful functions to match strings, such as:
compile function
match function
search function
findall function
Finder function
split function
sub function
subn function
The general use steps of re module are as follows:
Use the compile function to compile the string form of the regular expression into a Pattern object
The text is matched and searched through a series of methods provided by the Pattern object to obtain the matching result (a Match object)
Finally, use the attributes and methods provided by the Match object to obtain information and perform other operations as needed
compile function
The compile function is used to compile regular expressions and generate a Pattern object. Its general usage is as follows:
re.compile(pattern,flag=0) ''' pattern: canonical model falgs : Matching pattern,For example, ignore case, multiline mode, etc Return value: Pattern object '''
usage method:
import re # Compiling regular expressions into Pattern objects pattern = re.compile(r'\d+')
Above, we have compiled a regular expression into a Pattern object. Next, we can use a series of methods of Pattern to match and find the text. Some common methods of Pattern object mainly include:
match method
search method
findall method
Finder method
split method
sub method
subn method
Regular expression re compile()
Definition of compile():
compile(pattern, flags=0) Compile a regular expression pattern, returning a pattern object.
From the definition of the compile() function, it can be seen that the returned object is a matching object. If it is used alone, it has no meaning. It needs to be used with findall(), search(), match().
compile() is used with findall() to return a list.
import re
def main():
content = 'Hello, I am Jerry, from Chongqing, a montain city, nice to meet you......'
regex = re.compile('\w*o\w*')
x = regex.findall(content)
print(x)
if __name__ == '__main__':
main()
# ['Hello', 'from', 'Chongqing', 'montain', 'to', 'you']
compile() is used with match() to return a class, str, tuple, dict.
compile() is used with match() to return a class, str, tuple, dict. However, it must be noted that match() starts from position 0. If it does not match, it will return None. When it returns None, there will be no span/group attribute, and it is used with group. After returning a word 'Hello', the matching will end.
import re
def main():
content = 'Hello, I am Jerry, from Chongqing, a montain city, nice to meet you......'
regex = re.compile('\w*o\w*')
y = regex.match(content)
print(y)
print(type(y))
print(y.group())
print(y.span())
print(y.groupdict())
if __name__ == '__main__':
main()
# <_sre.SRE_Match object; span=(0, 5), match='Hello'>
# <class '_sre.SRE_Match'>
# Hello
# (0, 5)
# {}
compile() is used with search()
compile() is used in conjunction with search(), and the return type is similar to match(), but the difference is that search() can not start matching from position 0. But after matching a word, the matching is the same as match(), and the matching will end.
import re
def main():
content = 'Hello, I am Jerry, from Chongqing, a montain city, nice to meet you......'
regex = re.compile('\w*o\w*')
z = regex.search(content)
print(z)
print(type(z))
print(z.group())
print(z.span())
print(z.groupdict())
if __name__ == '__main__':
main()
# <_sre.SRE_Match object; span=(0, 5), match='Hello'>
# <class '_sre.SRE_Match'>
# Hello
# (0, 5)
# {}
Hidden compile function
Under normal circumstances, when we use the re module, we call the reply function of the re module to generate a pattern object, and use the pattern object to call the corresponding methods for regular matching. The general code is written as follows.
import re
pattern = re.compile('regular expression ')
text = 'A string'
result = pattern.findall(text)
But in Python, re is really not needed in most cases compile!, Direct use of re The corresponding method (pattern, string, flags=0) is OK. The reason is that the hot module places the call of the complie function in the corresponding method (pattern, string, flags=0). The return values of our common regular expression methods, whether findall, search, sub or match, are written as follows:
_compile(pattern, flag).Corresponding method(string)
View source code:
def findall(pattern, string, flags=0):
"""Return a list of all non-overlapping matches in the string.
If one or more capturing groups are present in the pattern, return
a list of groups; this will be a list of tuples if the pattern
has more than one group.
Empty matches are included in the result."""
return _compile(pattern, flags).findall(string)
Sure enough. In fact, our common regular expression methods have their own compile!
Generally, it is not necessary to use re first Compile then calls the regular expression method.
Take another look at re Compile source code
def compile(pattern, flags=0):
"Compile a regular expression pattern, returning a Pattern object."
return _compile(pattern, flags)
Also called_ compile(pattern, flags) returns the pattern object.
If I have a million strings and use a regular expression to match, I can write the code as follows:
texts = [A list of one million strings]
pattern = re.compile('regular expression ')
for text in texts:
pattern.search(text)
At this time, re Compile is executed only once, and if you write code like this:
texts = [A list of one million strings]
for text in texts:
re.search('regular expression ', text)
It is equivalent to that you execute the same regular expression 1 million times at the bottom compile. Is that right? The answer is: No,
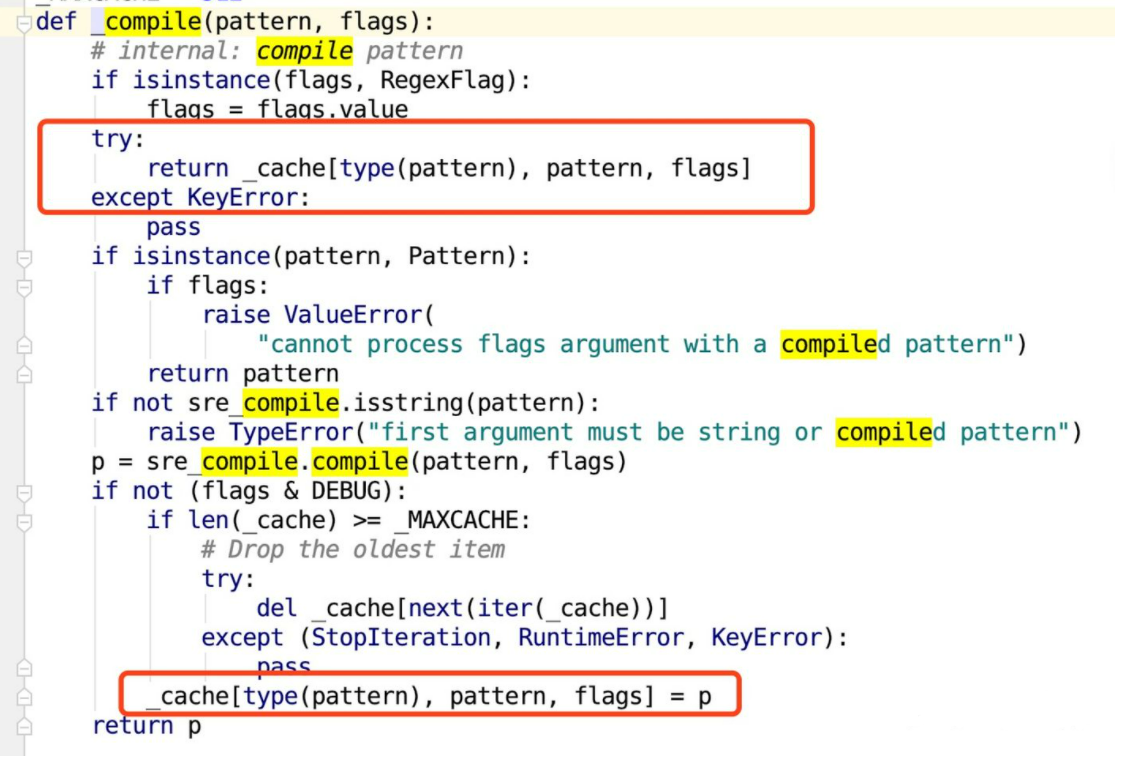
The code in the red box indicates_ compile has its own cache. It will automatically store up to 512 keys composed of type (pattern), pattern and flags). As long as it is the same regular expression and the same flag, it will be called twice_ When compiling, the cache will be read directly the second time.
To sum up, it is unnecessary to call re manually in most cases Compile, unless your project involves millions of regular expression queries.
Regular matching function in re
1. match() function (commonly used later)
Match: match a string that conforms to the rules from the beginning, and match from the starting position. An object is returned if the matching is successful, and None is returned if the matching is not successful
match(pattern, string, flags=0) # pattern: regular model # String: the string to match # Falls: match pattern
import re
str="hello egon bcd egon lge egon acd 19"
r=re.match("h\w+",str) #match: start matching from the starting position. An object will be returned if the matching is successful. None, non letters, Chinese characters, numbers and underscores will be returned if the matching is not successful
print(r.group()) # Get all the matching results, whether grouped or not, and take out all the matching results
print(r.groups()) # Get the grouping results matched in the model, and only take out the results of the grouping part of the matched string
print(r.groupdict()) # Get the matching group results in the model, and only take out the group results in which the key is defined in the grouping part of the matching string
# hello
# ()
# {}
r2=re.match("h(\w+)",str) #Match, starting from the starting position, returns an object if the match is successful, and None if the match is not successful
print(r2.group())
print(r2.groups())
print(r2.groupdict())
# hello
# ('ello',)
# {}
r3=re.match("(?P<n1>h)(?P<n2>\w+)",str) #? P < > defines the key (key) of the matched content in the group. The key name is written in < > and the value is the matched content
print(r3.group())
print(r3.groups())
print(r3.groupdict())
# hello
# ('h', 'ello')
# {'n1': 'h', 'n2': 'ello'}
2. search() function
search, browse all strings, match the first string that meets the rule, browse the whole string to match the first one, and return None if it is not matched successfully
search(pattern, string, flags=0) # pattern: regular model # String: the string to match # Falls: match pattern
Note: the match() function basically has the same function as the search() function. The difference is that match() matches a regular string at the beginning of the string, and search() matches the first regular string globally
import re
str="hello egon bcd egon lge egon acd 19"
r=re.search("h\w+",str) #match: start matching from the starting position. An object will be returned if the matching is successful. None, non letters, Chinese characters, numbers and underscores will be returned if the matching is not successful
print(r.group()) # Get all the matching results, whether grouped or not, and take out all the matching results
print(r.groups()) # Get the grouping results matched in the model, and only take out the results of the grouping part of the matched string
print(r.groupdict()) # Get the matching group results in the model, and only take out the group results in which the key is defined in the grouping part of the matching string
# hello
# ()
# {}
r2=re.search("h(\w+)",str) #Match, starting from the starting position, returns an object if the match is successful, and None if the match is not successful
print(r2.group())
print(r2.groups())
print(r2.groupdict())
# hello
# ('ello',)
# {}
r3=re.search("(?P<n1>h)(?P<n2>\w+)",str) #? P < > defines the key (key) of the matched content in the group. The key name is written in < > and the value is the matched content
print(r3.group())
print(r3.groups())
print(r3.groupdict())
# hello
# ('h', 'ello')
# {'n1': 'h', 'n2': 'ello'}
3. findall() function
Browse all strings, match all regular strings, put the matched strings into a list, and return an empty list if they are not matched successfully
findall(pattern, string, flags=0) # pattern: regular model # String: the string to match # Falls: match pattern
Note: once the matching is successful, the second matching starts with the last one. It can also be understood as a string that has been successfully matched and will not participate in the next matching
'''
Note: once the matching is successful, the second matching starts with the last one. It can also be understood as a string that has been successfully matched and will not participate in the next matching
'''
import re
r=re.findall("\d+\w\d+","a2b3c4d5") #Browse all strings, match all regular strings, and put the matched strings into a list
print(r)
# ['2b3', '4d5'] #The string that matches successfully will not participate in the next matching, so 3c4 also meets the rules, but it does not match
Note: if no matching rule is written, that is, an empty rule, an empty string list with one more bit than the original string is returned
'''
Note: if no matching rule is written, that is, an empty rule, an empty string list with one more bit than the original string is returned
'''
import re
r=re.findall("","a2b3c4d5") #Browse all strings, match all regular strings, and put the matched strings into a list
print(r)
# ['', '', '', '', '', '', '', '', ''] #If there is no write matching rule, that is, the empty rule, returns an empty string list one bit more than the original string. The above is 8 characters and the return is 9 empty characters
Note: in the case of regular matching to empty characters, if there is only one group in the rule, and the group is followed by, it means that the content in the group can be 0 or more, so there are two meanings in the group, one means to match the content in the group, and the other means to match the 0 content in the group (i.e. blank), so try to avoid using it, otherwise it may match an empty string
Note: regular only takes the last bit in the group. If there is only one group in the rule, the content of the group in the matched string is, and the last bit of the matched content is
'''
Note: in the case of regular matching to null characters, if there is only one group in the rule and the group is followed by*It means that the content in the group can be 0 or more, so there are two meanings in the group. One means to match the content in the group, and the other means to match the 0 content in the group (i.e. blank), so try to avoid using it*Otherwise, it is possible to match an empty string
Note: regular only takes the last bit in the group. If there is only one group in the rule, the content of the group in the matched string is, and the last bit of the matched content is
'''
import re
r=re.findall("(ca)*","ca2b3caa4d5") #Browse all strings, match all regular strings, and put the matched strings into a list
print(r)
# ['ca', '', '', '', 'ca', '', '', '', '', '']#Using the * sign will match the empty character
No grouping: matches all regular strings, and the matched strings are placed in a list
'''
No grouping: matches all regular strings, and the matched strings are placed in a list
'''
import re
r=re.findall("a\w+","ca2b3 caa4d5") #Browse all strings, match all regular strings, and put the matched strings into a list
print(r)
# ['a2b3', 'aa4d5']#Match all regular strings and put the matched strings into the list
Grouping: only the matched string, and the part of the group is returned in the list, which is equivalent to the groups() method
'''
Grouping: only the matched string, and the part of the group is returned in the list, which is equivalent to groups()method
'''
import re
r=re.findall("a(\w+)","ca2b3 caa4d5") #Grouping: only the matching string will be returned, and the part of the group will be returned in the list
print(r)
# ['2b3', 'a4d5']#Returns the content that matches the group
Multiple grouping: only the matched string, the part of the group into a tuple, and finally all tuples into a list
It is equivalent to taking out the parts of the group and putting them into a tuple in the group() result, and finally putting all tuples into a list for return
'''
Multiple grouping: only the matched string, the part of the group into a tuple, and finally all tuples into a list
Equivalent to in group()In the result, take out the parts of the group and put them into a tuple. Finally, put all tuples into a list and return
'''
import re
r=re.findall("(a)(\w+)","ca2b3 caa4d5") #Multiple grouping: only the matched string, the part of the group into a tuple, and finally all tuples into a list to return
print(r)
# [('a', '2b3'), ('a', 'a4d5')]#Returns a multidimensional array
There are groups in the group: only the part of the group in the matched string is put into a tuple. First, the group containing the group is regarded as a whole, that is, a group. Put the whole group into a tuple, then put the group in the group into a tuple, and finally put all the groups into a list to return
'''
There are groups in the group: only the part of the group in the matched string is put into a tuple. First, the group containing the group is regarded as a whole, that is, a group. Put the whole group into a tuple, then put the group in the group into a tuple, and finally put all the groups into a list to return
'''
import re
r=re.findall("(a)(\w+(b))","ca2b3 caa4b5") #There are groups in the group: only the part of the group in the matched string is put into a tuple. First, the group containing the group is regarded as a whole, that is, a group. Put the whole group into a tuple, then put the group in the group into a tuple, and finally put all the groups into a list to return
print(r)
# [('a', '2b', 'b'), ('a', 'a4b', 'b')]#Returns a multidimensional array
?: In the case of grouping, the findall() function takes not only the strings in the grouping, but also all the matching strings. Note: Only for functions that do not return regular objects, such as findall()
'''
?:In case of grouping findall()Function, not only take the string in the group, but also take all the matching strings. Note?:Only for functions that do not return regular objects, such as findall()
'''
import re
r=re.findall("a(?:\w+)","a2b3 a4b5 edd") #?: In the case of grouping, take not only the strings in the grouping, but also all matching strings. Note?: Only for functions that do not return regular objects, such as findall()
print(r)
# ['a2b3', 'a4b5']
4. split() function
According to the regular matching segmentation string, a list after segmentation is returned
split(pattern, string, maxsplit=0, flags=0) # pattern: regular model # String: the string to match # Maxplit: Specifies the number of divisions # flags: match pattern
import re
r=re.split("a\w","sdfadfdfadsfsfafsff")
print(r)
r2=re.split("a\w","sdfadfdfadsfsfafsff",maxsplit=2)
print(r2)
# C:\Users\zhaow\AppData\Local\Programs\Python\Python37\python.exe D:/study/python/atp/lib/t.py
# ['sdf', 'fdf', 'sfsf', 'sff']
# ['sdf', 'fdf', 'sfsfafsff']
5. sub() function
Replace the specified location string that matches successfully
sub(pattern, repl, string, count=0, flags=0) # pattern: regular model # repl: string to replace # String: the string to match # count: Specifies the number of matches # flags: match pattern
import re
r=re.sub("a\w","replace","sdfadfdfadsfsfafsff")
print(r)
# C:\Users\zhaow\AppData\Local\Programs\Python\Python37\python.exe D:/study/python/atp/lib/t.py
# sdf replaces fdf replaces sfsf replaces sff
6. subn() function
Replace the string at the specified position that matches successfully, and return the number of times of replacement, which can be accepted by two variables respectively
subn(pattern, repl, string, count=0, flags=0) # pattern: regular model # repl: string to replace # String: the string to match # count: Specifies the number of matches # flags: match pattern
import re
a,b=re.subn("a\w","replace","sdfadfdfadsfsfafsff") #Replace the string at the specified position that matches successfully, and return the number of times of replacement, which can be accepted by two variables respectively
print(a) #Returns the replaced string
print(b) #Returns the number of replacements
# C:\Users\zhaow\AppData\Local\Programs\Python\Python37\python.exe D:/study/python/atp/lib/t.py
# sdf replaces fdf replaces sfsf replaces sff
# 3
reference material
https://blog.csdn.net/weixin_42793426/article/details/88545939
https://zhuanlan.zhihu.com/p/70680488
https://www.cnblogs.com/xiaokuangnvhai/p/11213308.html