Analysis of real-time scheduling source code
The fundamental difference between Linux real-time process and ordinary process is that there is a real-time process in the system and it can run, and the scheduler will always select it, unless there is another real-time process with higher priority.
SCHED_FIFO: there is no time slice. After the scheduler is selected, it can run for any long time;
SCHED_RR: there is a time slice whose value will decrease when the process is running.
Real time scheduling entity sched_rt_entity data structure and operation
There are three basic operations of process insertion, selection and deletion.
//entity
struct sched_rt_entity {
struct list_head run_list;
unsigned long timeout; // The watchdog counter is mainly used to judge whether the current process time exceeds RLIMIT_RTIME
unsigned long watchdog_stamp;
unsigned int time_slice; // Scheduling slot for RR scheduling policy
struct sched_rt_entity *back; // dequeue_rt_stack() as a temporary variable
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity *parent; // Point to the upper scheduling entity
/* rq on which this entity is (to be) queued: */
struct rt_rq *rt_rq; //Ready queue of the current real-time scheduling entity
/* rq "owned" by this entity/group: */
struct rt_rq *my_q; //The ready queue of the sub scheduling entity of the current real-time scheduling entity
#endif
};
//class
const struct sched_class rt_sched_class = {
.next = &fair_sched_class,
.enqueue_task = enqueue_task_rt, //Put a task into the head or tail of the ready queue
.dequeue_task = dequeue_task_rt, // Delete a task from the end of the ready queue
.yield_task = yield_task_rt, //Voluntarily give up execution
.check_preempt_curr = check_preempt_curr_rt,
.pick_next_task = pick_next_task_rt, // A task of the ready queue selected by the core scheduler will be scheduled
.put_prev_task = put_prev_task_rt, // Execute when a task is about to be scheduled
#ifdef CONFIG_SMP
.select_task_rq = select_task_rq_rt, //The core scheduler selects CPUs for tasks and distributes tasks to different CPUs for execution
.set_cpus_allowed = set_cpus_allowed_common,
.rq_online = rq_online_rt,
.rq_offline = rq_offline_rt,
.task_woken = task_woken_rt,
.switched_from = switched_from_rt,
#endif
.set_curr_task = set_curr_task_rt, // This function is called when a task modifies its scheduling class or modifies other task groups
.task_tick = task_tick_rt, // When the clock interrupt is triggered, it will be called to update the running statistics of the new process and whether it needs to be scheduled
.get_rr_interval = get_rr_interval_rt,
.prio_changed = prio_changed_rt,
.switched_to = switched_to_rt,
.update_curr = update_curr_rt,
};
//Process insert operation
/*
* Adding/removing a task to/from a priority array:
*/
// Update the scheduling information and insert the scheduling entity into the end of the corresponding priority queue
static void
enqueue_task_rt(struct rq *rq, struct task_struct *p, int flags)
{
struct sched_rt_entity *rt_se = &p->rt;
if (flags & ENQUEUE_WAKEUP)
rt_se->timeout = 0;
// Actual work
// Add the current real-time scheduling entity to the corresponding priority linked list. Whether it is added to the head or tail depends on whether the flags contain ENQUEUE_HEAD to judge
enqueue_rt_entity(rt_se, flags & ENQUEUE_HEAD);
if (!task_current(rq, p) && p->nr_cpus_allowed > 1)
enqueue_pushable_task(rq, p); //Add to hash table
}
// Process selection operation
// Real time scheduling selects the real-time process with the highest priority to run.
static struct task_struct *_pick_next_task_rt(struct rq *rq)
{
struct sched_rt_entity *rt_se;
struct task_struct *p;
struct rt_rq *rt_rq = &rq->rt;
do { //Traverse each process in the group schedule
rt_se = pick_next_rt_entity(rq, rt_rq);
BUG_ON(!rt_se);
rt_rq = group_rt_rq(rt_se);
} while (rt_rq);
p = rt_task_of(rt_se);
// Update execution domain
p->se.exec_start = rq_clock_task(rq);
return p;
}
static struct sched_rt_entity *pick_next_rt_entity(struct rq *rq,
struct rt_rq *rt_rq)
{
struct rt_prio_array *array = &rt_rq->active;
struct sched_rt_entity *next = NULL;
struct list_head *queue;
int idx;
// Found an available entity
idx = sched_find_first_bit(array->bitmap);
BUG_ON(idx >= MAX_RT_PRIO);
// Find the corresponding linked list from the linked list group
queue = array->queue + idx;
next = list_entry(queue->next, struct sched_rt_entity, run_list);
// Return to found running entity
return next;
}
// Process delete operation
// Delete the real-time process from the priority queue, update the scheduling information, and then add the process to the end of the queue.
static void dequeue_task_rt(struct rq *rq, struct task_struct *p, int flags)
{
struct sched_rt_entity *rt_se = &p->rt;
// Update scheduling data information
update_curr_rt(rq);
// The actual work will be rt_se is removed from the run queue and added to the end of the queue
dequeue_rt_entity(rt_se);
// Delete from hash table
dequeue_pushable_task(rq, p);
}
/*
* Update the current task's runtime statistics. Skip current tasks that
* are not in our scheduling class.
*/
static void update_curr_rt(struct rq *rq)
{
struct task_struct *curr = rq->curr;
struct sched_rt_entity *rt_se = &curr->rt;
u64 delta_exec;
// Determine whether there is a real-time scheduling process
if (curr->sched_class != &rt_sched_class)
return;
// execution time
delta_exec = rq_clock_task(rq) - curr->se.exec_start;
if (unlikely((s64)delta_exec <= 0))
return;
schedstat_set(curr->se.statistics.exec_max,
max(curr->se.statistics.exec_max, delta_exec));
// Update the total execution time of the current process
curr->se.sum_exec_runtime += delta_exec;
account_group_exec_runtime(curr, delta_exec);
// Start time of update execution
curr->se.exec_start = rq_clock_task(rq);
cpuacct_charge(curr, delta_exec);
sched_rt_avg_update(rq, delta_exec);
if (!rt_bandwidth_enabled())
return;
for_each_sched_rt_entity(rt_se) {
struct rt_rq *rt_rq = rt_rq_of_se(rt_se);
if (sched_rt_runtime(rt_rq) != RUNTIME_INF) {
raw_spin_lock(&rt_rq->rt_runtime_lock);
rt_rq->rt_time += delta_exec;
if (sched_rt_runtime_exceeded(rt_rq))
resched_curr(rq);
raw_spin_unlock(&rt_rq->rt_runtime_lock);
}
}
}
static void dequeue_rt_entity(struct sched_rt_entity *rt_se)
{
struct rq *rq = rq_of_rt_se(rt_se);
dequeue_rt_stack(rt_se); // Remove from run queue
for_each_sched_rt_entity(rt_se) {
struct rt_rq *rt_rq = group_rt_rq(rt_se);
if (rt_rq && rt_rq->rt_nr_running)
__enqueue_rt_entity(rt_se, false);
}
enqueue_top_rt_rq(&rq->rt);
}
Symmetric multiprocessor SMP
The working mode of multiprocessor system is divided into asymmetric mulit processing and symmetric mulit processing (SMP).
In a symmetric multiprocessor system, the status of all processors is the same, and all resources, especially memory, interrupt and I/O space, have the same accessibility, eliminating structural obstacles.
On multiprocessor systems, the kernel must consider several additional problems to ensure good scheduling.
- CPU load must be shared among all processors as fairly as possible.
- The affinity between the process and some processors in the system must be settable.
- The kernel must be able to migrate processes from one CPU to another.
linux SMP scheduling is the process of scheduling / migrating processes to appropriate CPUs to maintain load balance among CPUs.
SMP benefits
- A cost-effective way to increase throughput;
- Since the operating system is shared by all processors, they provide a separate system image (easy to manage);
- Apply multiprocessor (parallel programming) to a single problem;
- Load balancing is realized by the operating system;
- The single processor (UP) programming model can be used in an SMP;
- Scalable for shared data;
- All data can be addressed by all processors, and continuity is maintained by hardware monitoring logic;
- Since the communication is performed via the global shared memory, it is not necessary to use the messaging library for communication between processors;
SMP limitations
- Scalability is limited due to cache correlation, locking mechanism, shared objects and other problems;
- New technologies are needed to take advantage of multiprocessors, such as thread programming and device driver programming.
CPU domain initialization
There is a data structure struct sched in the Linux kernel_ domain_ topology_ Level is used to describe the hierarchical relationship of CPU.
The kernel manages the CPU through bitmap, and defines four states: possible, present, online and active.
struct sched_domain_topology_level {
sched_domain_mask_f mask; //The function pointer is used to specify the cpumask position of an SDTL level
sched_domain_flags_f sd_flags; //The function pointer is used to specify the flag bit of an SDTL level
int flags;
int numa_level;
struct sd_data data;
#ifdef CONFIG_SCHED_DEBUG
char *name;
#endif
};
// Indicates how many CPU cores can be run in the system
const struct cpumask *const cpu_possible_mask = to_cpumask(cpu_possible_bits);
EXPORT_SYMBOL(cpu_possible_mask);
// Indicates how many CPU cores are running in the system
static DECLARE_BITMAP(cpu_online_bits, CONFIG_NR_CPUS) __read_mostly;
const struct cpumask *const cpu_online_mask = to_cpumask(cpu_online_bits);
EXPORT_SYMBOL(cpu_online_mask);
// Indicates how many CPU cores are online in the system. They are not necessarily online. Some CPU cores may be hot swapped.
static DECLARE_BITMAP(cpu_present_bits, CONFIG_NR_CPUS) __read_mostly;
const struct cpumask *const cpu_present_mask = to_cpumask(cpu_present_bits);
EXPORT_SYMBOL(cpu_present_mask);
//Indicates how many active CPU cores are in the system
static DECLARE_BITMAP(cpu_active_bits, CONFIG_NR_CPUS) __read_mostly;
const struct cpumask *const cpu_active_mask = to_cpumask(cpu_active_bits);
EXPORT_SYMBOL(cpu_active_mask);
//The above four variables are bitmap type variables.
SMP load balancing
SMP load balancing mechanism starts from registering soft interrupts. Each time the system processes a scheduling tick, it will check whether it needs to handle SMP load balancing.
Load balancing timing
- Call the process scheduler periodically_ tick()->trigger_ load_ In balance(), load balancing is triggered by soft interrupt.
- There are no runnable processes on a CPU__ Before schedule() prepares to schedule idle processes, it will try to pull a batch of processes from other CPUs.
Two 4-core 8-core CPUs, logical relationship of CPU scheduling domain
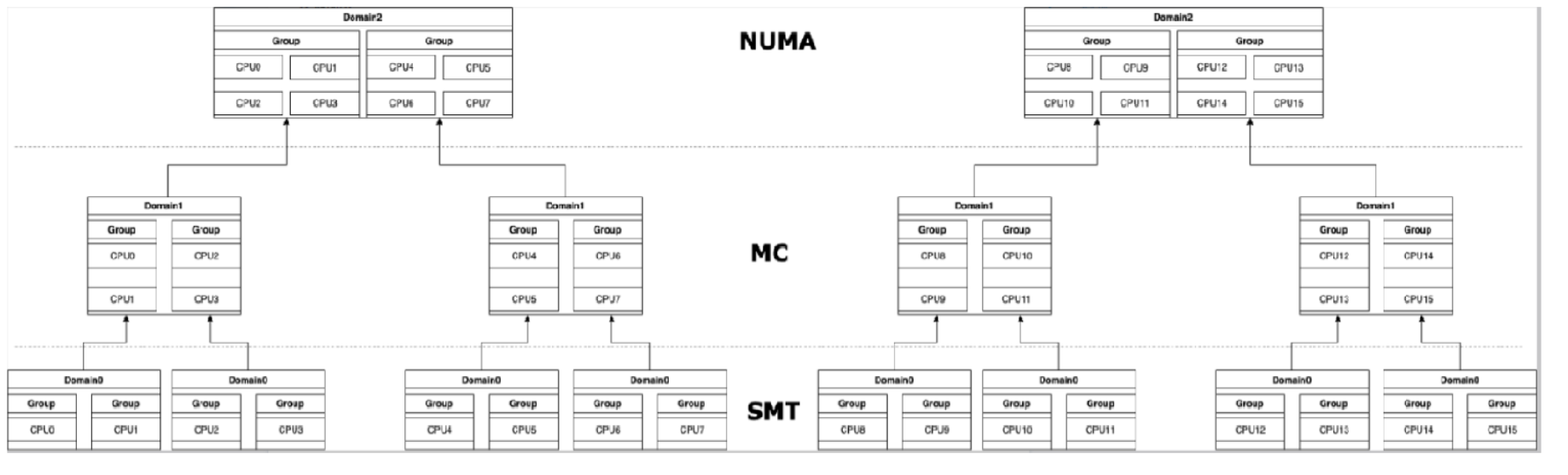
Layered angle analysis
All CPUs are divided into three levels: SMT, MC and NUMA. Each layer contains all CPUs, but the division granularity is different. According to the correlation between Cache and memory, the scheduling domain is divided, and the CPU in the scheduling domain is divided into scheduling groups again. The smaller the lower layer scheduling domain, the larger the upper layer scheduling domain. Process load balancing can be solved within the underlying scheduling domain as much as possible, so as to optimize Cache utilization.
Periodic load balancing: the data structure of the run queue corresponding to the CPU records the next periodic load balancing time. When this time point is exceeded, sched will be triggered_ Sofirq soft interrupt for load balancing.
When to use SMP load balancing model
During kernel operation, SMP load balancing model needs to be used to determine the best running CPU in some cases:
- When process A wakes up process B, try_ to_ wake_ The CPU on which process B will run will be considered in up();
- When the process calls execve() system call;
- fork out the child process. The child process is scheduled to run for the first time.
Linux runtime tuning:
Linux introduces important sysctls to tune the scheduler at run time (ns)
sched_ child_ runs_ First: the child is scheduled after the fork. It is the default device. If set to 0, the parent is scheduled first.
sched_min_granularity_ns: minimum preemption granularity for CPU intensive tasks.
sched_latency_ns: target preemption delay for CPU intensive tasks.
sched_stat_granularity_ns: granularity of collecting scheduler statistics.
summary
This paper mainly introduces the source code analysis of real-time scheduling, including real-time scheduling data structure and its related operations (insert, select, delete, etc.); The advantages and disadvantages of SMP, load balancing mechanism, CPU layering analysis, linux runtime tuning and other related parameters are introduced.
Technical reference
https://ke.qq.com/webcourse/3294666/103425320#taid=11144559668118986&vid=5285890815288776379