Recently learned about Http connection pool – copy personal learning
One rpc Interface at 0~2 Point users' performance at the peak of orders rt High (more than 1) s,In fact, targeted optimized interfaces rt Exceeding this value is also problematic, usually rpc Even if the logic in the interface is complex, 300 ms It should be done), understandable, but in 4~5 Interface at the time of tps It's not high anymore, and the time is still 600 ms~700ms Can't understand between.
After checking, there is a logic that calls Alipay http interface, but every time a new HttpClient comes out to initiate the call, the calling time is about 300ms+, so that even at the non peak time, the interface time is still very high.
The problem is not difficult. Write an article to systematically summarize this.
Difference between using and not using thread pool
This article focuses on the impact of "pool" on system performance. Therefore, before starting to connect to the pool, you can start this article with the example of thread pool as an introduction. Let's briefly look at one effect difference of not using the pool. The code is as follows:
/**
* Thread pool test
*
* @author Cangjie in May https://www.cnblogs.com/xrq730/p/10963689.html
*/
public class ThreadPoolTest {
private static final AtomicInteger FINISH_COUNT = new AtomicInteger(0);
private static final AtomicLong COST = new AtomicLong(0);
private static final Integer INCREASE_COUNT = 1000000;
private static final Integer TASK_COUNT = 1000;
@Test
public void testRunWithoutThreadPool() {
List<Thread> tList = new ArrayList<Thread>(TASK_COUNT);
for (int i = 0; i < TASK_COUNT; i++) {
tList.add(new Thread(new IncreaseThread()));
}
for (Thread t : tList) {
t.start();
}
for (;;);
}
@Test
public void testRunWithThreadPool() {
ThreadPoolExecutor executor = new ThreadPoolExecutor(100, 100, 0, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>());
for (int i = 0; i < TASK_COUNT; i++) {
executor.submit(new IncreaseThread());
}
for (;;);
}
private class IncreaseThread implements Runnable {
@Override
public void run() {
long startTime = System.currentTimeMillis();
AtomicInteger counter = new AtomicInteger(0);
for (int i = 0; i < INCREASE_COUNT; i++) {
counter.incrementAndGet();
}
// Cumulative execution time
COST.addAndGet(System.currentTimeMillis() - startTime);
if (FINISH_COUNT.incrementAndGet() == TASK_COUNT) {
System.out.println("cost: " + COST.get() + "ms");
}
}
}
}
The logic is relatively simple: there are 1000 tasks, and what each task does is to use AtomicInteger to accumulate from 0 to 100W.
Each Test method runs 12 times, excluding the lowest and the highest. Take an average of the middle 10 times. When the thread pool is not used, the total task time is 16693s; When using thread pool, the average execution time of tasks is 1073s, more than 15 times. The difference is very obvious.
The reason is relatively simple. As we all know, there are two main points:
Reduce the overhead of thread creation and destruction
Control the number of threads to avoid creating a thread for a task, which will eventually lead to a sudden increase or even depletion of memory
Of course, as mentioned earlier, this is just an introduction to this article. When we use HTTP connection pool, the reason for the improvement of task processing efficiency is more than that.
Which httpclient to use
We should pay special attention to one point that is easy to make mistakes. HttpClient can find two similar toolkits. One is common HttpClient:
<dependency>
<groupId>commons-httpclient</groupId>
<artifactId>commons-httpclient</artifactId>
<version>3.1</version>
</dependency>
One is httpclient:
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.8</version>
</dependency>
That is, commons HttpClient is an old version of HttpClient. Up to version 3.1, the project has been abandoned and will not be updated (version 3.1, released on August 21, 2007). It has been classified into a larger Apache HttpComponents project. The version number of this project is HttpClient 4 X (latest version of 4.5.8, released on May 30, 19).
With the continuous update, the bottom layer of HttpClient is continuously optimized for code details and performance, so remember to choose org apache. Httpcomponents this groupId.
Operation effect without connection pool
With a tool class, you can write code to verify it. First, define a test base class, which can be shared when using the code demonstration of connection pool:
/**
* Connection pool base class
*
* @author Cangjie in May https://www.cnblogs.com/xrq730/p/10963689.html
*/
public class BaseHttpClientTest {
protected static final int REQUEST_COUNT = 5;
protected static final String SEPERATOR = " ";
protected static final AtomicInteger NOW_COUNT = new AtomicInteger(0);
protected static final StringBuilder EVERY_REQ_COST = new StringBuilder(200);
/**
* Get thread to run
*/
protected List<Thread> getRunThreads(Runnable runnable) {
List<Thread> tList = new ArrayList<Thread>(REQUEST_COUNT);
for (int i = 0; i < REQUEST_COUNT; i++) {
tList.add(new Thread(runnable));
}
return tList;
}
/**
* Start all threads
*/
protected void startUpAllThreads(List<Thread> tList) {
for (Thread t : tList) {
t.start();
// A little delay is needed to ensure that the requests are sent out in order
try {
Thread.sleep(300);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
protected synchronized void addCost(long cost) {
EVERY_REQ_COST.append(cost);
EVERY_REQ_COST.append("ms");
EVERY_REQ_COST.append(SEPERATOR);
}
}
Then take a look at the test code:
/**
* Do not use connection pool test
*
* @author Cangjie in May https://www.cnblogs.com/xrq730/p/10963689.html
*/
public class HttpClientWithoutPoolTest extends BaseHttpClientTest {
@Test
public void test() throws Exception {
startUpAllThreads(getRunThreads(new HttpThread()));
// Wait for the thread to run
for (;;);
}
private class HttpThread implements Runnable {
@Override
public void run() {
/**
* HttpClient It is thread safe, so the normal use of HttpClient should be made into a global variable. However, once the global shares one, a new connection pool will be created when HttpClient is built internally
* In this way, the effect of using connection pool cannot be reflected. Therefore, a new HttpClient is added here every time to ensure that the opposite end is not requested through the connection pool every time
*/
CloseableHttpClient httpClient = HttpClients.custom().build();
HttpGet httpGet = new HttpGet("https://www.baidu.com/");
long startTime = System.currentTimeMillis();
try {
CloseableHttpResponse response = httpClient.execute(httpGet);
if (response != null) {
response.close();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
addCost(System.currentTimeMillis() - startTime);
if (NOW_COUNT.incrementAndGet() == REQUEST_COUNT) {
System.out.println(EVERY_REQ_COST.toString());
}
}
}
}
}
Note that as the comment says here, HttpClient is thread safe, but once it is made global, it will lose the test effect, because HttpClient will create a new connection pool by default during initialization.
Take a look at the code running effect:
324ms 324ms 220ms 324ms 324ms
Each request is almost independent, so the execution time is more than 200ms. Then let's take a look at the effect of using connection pool.
Run results using connection pool
The BaseHttpClientTest class remains unchanged. Write a test class using connection pool:
/**
* Test with connection pool
*
* @author Cangjie in May https://www.cnblogs.com/xrq730/p/10963689.html
*/
public class HttpclientWithPoolTest extends BaseHttpClientTest {
private CloseableHttpClient httpClient = null;
@Before
public void before() {
initHttpClient();
}
@Test
public void test() throws Exception {
startUpAllThreads(getRunThreads(new HttpThread()));
// Wait for the thread to run
for (;;);
}
private class HttpThread implements Runnable {
@Override
public void run() {
HttpGet httpGet = new HttpGet("https://www.baidu.com/");
// Long connection ID, it's OK without adding, http1 1. The default is connection: keep alive
httpGet.addHeader("Connection", "keep-alive");
long startTime = System.currentTimeMillis();
try {
CloseableHttpResponse response = httpClient.execute(httpGet);
if (response != null) {
response.close();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
addCost(System.currentTimeMillis() - startTime);
if (NOW_COUNT.incrementAndGet() == REQUEST_COUNT) {
System.out.println(EVERY_REQ_COST.toString());
}
}
}
}
private void initHttpClient() {
PoolingHttpClientConnectionManager connectionManager = new PoolingHttpClientConnectionManager();
// Total number of connection pools
connectionManager.setMaxTotal(1);
// You can set a separate number of connection pools for each domain name
connectionManager.setMaxPerRoute(new HttpRoute(new HttpHost("www.baidu.com")), 1);
// setConnectTimeout indicates to set the timeout for establishing a connection
// setConnectionRequestTimeout indicates the waiting timeout for getting a connection from the connection pool
// setSocketTimeout indicates the timeout time of waiting for the response from the opposite end after the request is sent
RequestConfig requestConfig = RequestConfig.custom().setConnectTimeout(1000).setConnectionRequestTimeout(2000)
.setSocketTimeout(3000).build();
// The retry processor, StandardHttpRequestRetryHandler, is officially provided. I feel frustrated after reading it. Many errors cannot be retried. I can implement the HttpRequestRetryHandler interface myself
HttpRequestRetryHandler retryHandler = new StandardHttpRequestRetryHandler();
httpClient = HttpClients.custom().setConnectionManager(connectionManager).setDefaultRequestConfig(requestConfig)
.setRetryHandler(retryHandler).build();
// The server assumes that the connection is closed and is not transparent to the client. In order to alleviate this problem, HttpClient will detect whether a connection is out of date before using it. If it is out of date, the connection will fail, but this method will be used for each request
// Add some additional overhead, so a scheduled task is dedicated to reclaim the connections that are determined to be invalid due to long-term inactivity, which can solve this problem to some extent
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
try {
// Close failed connections and remove them from the connection pool
connectionManager.closeExpiredConnections();
// Close connections that are inactive for 30 seconds and remove them from the connection pool. The idle time starts when they are returned to the connection manager
connectionManager.closeIdleConnections(20, TimeUnit.SECONDS);
} catch (Throwable t) {
t.printStackTrace();
}
}
}, 0 , 1000 * 5);
}
}
This class demonstrates the usage of HttpClient in detail. Notes are written for relevant points of attention, so I won't talk about it.
As above, take a look at the code execution effect:
309ms 83ms 57ms 53ms 46ms
Apart from the 309ms of the first call, the overall execution time of the next four calls has been greatly improved, which is the advantage of using the connection pool. Then, let's explore the reasons for using the connection pool to improve the overall performance.
Long and short connections that cannot be wound
When it comes to HTTP, one topic that must be avoided is long and short connections. The previous articles on this topic have been written many times. Write it again here.
We know that there are roughly the following steps between the client initiating an HTTP request and the server responding to the HTTP request:
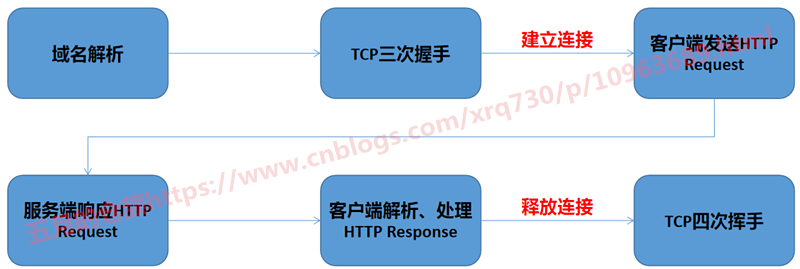
HTTP1.0 was first used in web pages in 1996. At that time, it only used some simple web pages and network requests. Each request needs to establish a separate connection, and the last request and the next request are completely separated. In this way, even if the amount of requests each time is very small, it is a relatively time-consuming process for the client and server to establish and close the TCP connection each time, which seriously affects the performance of the client and server.
Based on the above problems, http1 1 was widely used in the current major browser network requests in 1999, and HTTP 1 1 is also the most widely used HTTP protocol at present (HTTP2 was born in 2015, but it has not been applied on a large scale). There is no detailed comparison of http1 1 for http1 What has 0 improved, just in the connection, http1 1 supports transmitting multiple HTTP requests and responses on one TCP connection, which reduces the consumption delay of establishing and closing connections and makes up for http1 to a certain extent 0. The disadvantage of creating a connection every request is that it is a long connection, http1 1 long connection is used by default.
So how does a long connection work? First of all, we need to make it clear that long and short connections are the concept of the communication layer (TCP), and HTTP is the application layer protocol. It can only tell the communication layer that I intend to reuse the TCP channel for a period of time without the ability to establish and release the TCP channel myself. So how does HTTP tell the communication layer to reuse TCP channels? See the following figure:

It is divided into the following steps:
The client sends a header with connection: keep alive, indicating that the connection needs to be maintained
The client can take the header keep alive: timeout = 5, max = 100 to the server, which means that the tcp connection can be maintained for up to 5 seconds. The long connection will be disconnected after receiving 100 requests. However, the browser looks at some requests and doesn't seem to see those with this parameter
The server must be able to recognize the header of connection: keep alive and tell the client that I can maintain the connection through the Response Header with the same connection: keep alive
The client and server send and receive data through the maintained channel
The last time data is requested, the client takes the header of Connection: close, indicating that the Connection is closed
At this point, the process of exchanging data on one channel ends. By default:
The number of requests for long connections is limited to 100 consecutive requests. If the limit is exceeded, the connection will be closed
The timeout between two consecutive requests of a long connection is 15 seconds (with an error of 1 ~ 2 seconds). After the timeout, the TCP connection will be closed. Therefore, when using a long connection, try to send a request within 13 seconds
These limitations are a compromise between reusing long connections and excessive long connections, because although long connections are good, long TCP connections are easy to lead to invalid occupation of system resources and waste of system resources.
Finally, let's talk about the difference between http's keep alive and tcp's keep alive. A frequently asked question, please record it by the way:
http keep alive is to reuse existing connections
tcp keep alive is to keep the peer alive, that is, to ensure that the peer is still alive. Otherwise, the peer is gone. I still occupy the connection with the peer, wasting server resources. The way is to send a heartbeat packet to the peer server every other period of time. Once no response is received for a long time, I will take the initiative to close the connection
Reasons for performance improvement
Through the previous analysis, it is obvious that the most important reason for using HTTP connection pool to improve performance is to save a lot of connection establishment and release time. In addition, I would like to say one more point.
When TCP establishes a connection, there is the following process:

As shown in the figure, there are two queues, syns queue and accept queue. I won't talk about the process in detail. I have an article before https://www.cnblogs.com/xrq730/p/6910719.html I've written about this topic.
Once the long connection is not used and the handshake is repeated for each connection, the server will send an econnreused error message to the client as soon as the queue is full, which is equivalent to that this request will fail. Even if it does not fail, subsequent requests need to wait for the previous request processing, and queuing will increase the response time.
By the way, based on the above analysis, not only HTTP, but all application layer protocols, such as database connection pool and hsf interface connection pool provided by hsf, the use of connection pool can greatly improve the interface performance for the same reason.
Optimization of TLS layer
All the above are the reasons for using connection pool for application layer protocol to improve performance. However, for HTTP requests, we know that most websites run on HTTPS protocol, that is, there is an additional layer of TLS between communication layer and application layer:
Insert picture description here

The message is encrypted through the TLS layer to ensure data security. In fact, at the HTTPS level, the use of connection pool improves the performance, and the optimization of the TLS layer is also a very important reason.
The principle of HTTPS is not discussed in detail. Anyway, it is basically a process of certificate exchange – > server encryption – > client decryption. In the whole process, repeatedly exchanging data between client and server is a time-consuming process, and data encryption and decryption is a calculation intensive operation, consuming CPU resources, Therefore, if the encryption and decryption of the same request can be omitted, the whole performance can be greatly improved under the HTTPS protocol. In fact, this optimization is available. A session reuse technology is used here.
The TLS handshake starts with the client sending the Client Hello message and ends with the server returning the Server Hello. Two different session reuse mechanisms are provided in the whole process. Let's take a brief look at this place and know that there is such a thing:
session id session reuse: for the established TLS session, use the session id as key (the session id from Server Hello in the first request) and the master key as value to form a pair of key value pairs, which are saved locally on the server and client. During the second handshake, if the client wants to reuse the session, it will bring the session id in the initiated Client Hello. After receiving this session id, the server will check whether it exists locally. If so, it is allowed to reuse the session for subsequent operations
Session ticket session reuse - a session ticket is an encrypted data blob, which contains TLS connection information to be reused, such as session key. It is generally encrypted with ticket key, because the ticket key server also knows that in the initialization handshake, the server sends a session ticket to the client and stores it locally. When the session is reused, The client sends the session ticket to the server, and the server can reuse the session after successful decryption
The disadvantages of session id are obvious. The main reason is that in load balancing, sessions are not synchronized between multiple machines. If two requests do not fall on the same machine, matching information cannot be found. In addition, the server needs to consume a lot of resources to store a large number of session IDs, and session ticket is a better solution to this problem, However, it is up to the browser to decide which method to use in the end. About the session ticket, I found a picture on the Internet, showing the process of the client initiating the request for the second time and carrying the session ticket:
Insert picture description here

The timeout time of a session ticket is 300s by default. Certificate exchange + asymmetric encryption in TLS layer is a major performance consumer. The performance can be greatly improved through session reuse technology.
Considerations for using connection pool
When using connection pooling, keep in mind that the execution time of each task should not be too long.
Because HTTP requests, database requests and hsf requests all have timeout time. For example, there are 10 threads in the connection pool and 100 requests come concurrently. Once the task execution time is very long, the connections are occupied by the first 10 tasks, and the latter 90 requests are not processed by the connection, which will lead to slow response or even timeout.
Of course, the business of each task is different, but according to my experience, try to control the execution time of the task within 50ms and 100ms at most. If it exceeds, the following three schemes can be considered:
Optimize task execution logic, such as introducing cache
Appropriately increase the number of connections in the connection pool
Task splitting: splitting a task into several small tasks
How to set the number of connections in the connection pool
Some friends may ask, I know that connection pools need to be used, so what is the general number of connection pools? Is there any experience value? First of all, we need to make it clear that too many or too few connections in the connection pool are not good:
For example, qps=100, because the upstream request rate cannot be constant 100 requests / s, 900 requests in the first second and 100 requests in the last 9 seconds. On average, qps=100. When there are too many connections, the possible scenario is to establish connections under high traffic - > release some connections under low traffic - > re establish connections under high traffic, which is equivalent to using connection pool, However, due to uneven traffic, repeatedly establish connections and release links
Of course, too few threads is also bad. There are too many tasks and too few connections, resulting in many tasks waiting in line for the previous execution to get the connection for processing, which reduces the processing speed
The answer to the question of how to set the number of connections in the connection pool is not fixed, but an estimated value can be obtained through estimation.
First of all, the development students need to have a clear idea of the daily call volume of a task. Suppose 1000W times a day and there are 10 servers on the line, then the average call volume of each server is 100W, 100W is 86400 seconds a day, and the call volume per second is 1000000 / 86400 ≈ 11.574 times. Add a little margin according to the average response time of the interface, It is more appropriate to set it at 15 ~ 30, and make adjustment according to the actual situation of online operation.
Original link: https://www.cnblogs.com/xrq730/p/10963689.html