gravity is a heterogeneous/isomorphic data replication channel software for Mobay bicycle ticketing, providing support for mainstream software and native k8s cloud.Better see its development.
Project address: https://github.com/moiot/gravity
Official documents: https://github.com/moiot/gravity/blob/master/docs/2.0/01-quick-start.md
The compilation and deployment of gravity is not the focus here, so let's skip it.
gravity deployment:
cd /root/ git clone https://github.com/moiot/gravity.git cd gravity && make mkdir /usr/local/gravity/ cd /usr/local/gravity/ cp /root/gravity/bin/gravity /usr/local/gravity/ //Configuration files are ignored here.
Below is my schematic diagram:
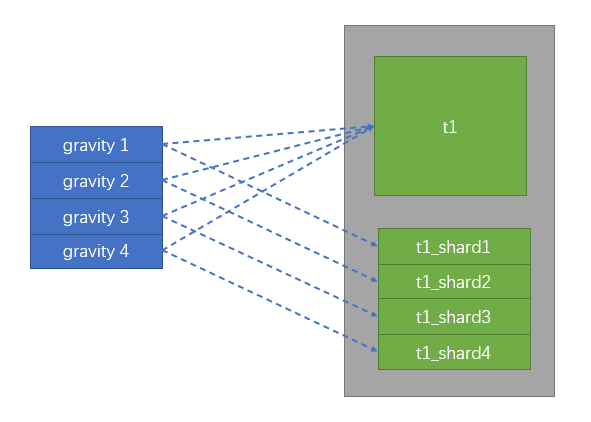
Business Scenario:
An old table, as business grows, takes into account table breakup, does hash modelling according to user_id, and then does data CRUD operation at the business level.
The data table is as follows:
create database testdb; use testdb; CREATE TABLE `gravity_t1` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT 'Self-increasing id', `user_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT 'user id', `s_status` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT 'state', PRIMARY KEY (`id`), KEY `idx_uid` (`user_id`) USING BTREE ) COMMENT = 'Test Table' ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; //Four tables to be split: use testdb; create table t1_shard1 LIKE gravity_t1 ; create table t1_shard2 LIKE gravity_t1 ; create table t1_shard3 LIKE gravity_t1 ; create table t1_shard4 LIKE gravity_t1 ;
Test database connection:
Database address: 192.168.2.4 Super Account: dts Password: dts Assume that the normal account used for business is rd, and the password does not matter.
Make some data for testing:
for i in {1..10000} ; do
mysql -hdts -pdts -h 192.168.2.4 -e "insert into testdb.gravity_t1 (user_id,s_status) values (\"$RANDOM\",'0');"
doneThe results are roughly as follows:
[test] > select count(*) from gravity_t1 ; +----------+ | count(*) | +----------+ | 10000 | +----------+ 1 row in set (0.007 sec) [testdb] > select (user_id%4) as hash_id,count(*) FROM gravity_t1 group by (user_id%4); +---------+----------+ | hash_id | count(*) | +---------+----------+ | 0| 2537 | | 1 | 2419 | | 2 | 2509 | | 3| 2535 | +---------+----------+ 4 rows in set (0.009 sec)
The configuration file for shard1 is as follows:
cat config_shard1.toml
#name is required, which maintains the uniqueness of each profile name = "shard1" #Internal library name for locus, heartbeat, etc. Default is _gravity. It is useless to change the name here. Keep the default internal-db-name = "_gravity" # #Definition of the Input plug-in, where mysql is used # [input] type = "mysql" mode = "replication" [input.config.source] host = "192.168.2.4" username = "dts" password = "dts" port = 3306 # #Definition of the Output plug-in, using mysql here # [output] type = "mysql" [output.config.target] host = "192.168.2.4" username = "dts" password = "dts" port = 3306 #Definition of routing rules [[output.config.routes]] match-schema = "testdb" match-table = "gravity_t1" target-schema = "testdb" target-table = "t1_shard1" #This target-table represents the name of the slice to be written to and needs to be modified in the configuration of each gravity instance
Open 4 windows to demonstrate:
cd /usr/local/gravity/ ./bin/gravity -config config_shard1.toml -http-addr ":8083" ./bin/gravity -config config_shard2.toml -http-addr ":8184" ./bin/gravity -config config_shard3.toml -http-addr ":8185" ./bin/gravity -config config_shard4.toml -http-addr ":8186"
TIPS:
If we open the general_log of the database at this point, we can see that gravity to dest inserts the full amount of data using the replace into method.The incremental data is then leveled based on the binlog that was listened for at startup.
Then, look at gravity's automatically generated library, which holds information about data replication:
[testdb] > show tables from _gravity ;
+----------------------+
| Tables_in__gravity |
+----------------------+
| gravity_heartbeat_v2 |
| gravity_positions |
+----------------------+
2 rows in set (0.000 sec)
[testdb] > select * from _gravity.gravity_heartbeat_v2;
+--------+--------+----------------------------+----------------------------+
| name | offset | update_time_at_gravity | update_time_at_source |
+--------+--------+----------------------------+----------------------------+
| shard1 | 57 | 2020-03-26 16:19:08.070483 | 2020-03-26 16:19:08.070589 |
| shard2 | 51 | 2020-03-26 16:19:07.469721 | 2020-03-26 16:19:07.469811 |
| shard3 | 50 | 2020-03-26 16:19:09.135751 | 2020-03-26 16:19:09.135843 |
| shard4 | 48 | 2020-03-26 16:19:08.448371 | 2020-03-26 16:19:08.448450 |
+--------+--------+----------------------------+----------------------------+
4 rows in set (0.001 sec)
[testdb] > select * from _gravity.gravity_positions\G
*************************** 1. row ***************************
name: shard1
stage: stream
position: {"current_position":{"binlog-name":"mysql-bin.000014","binlog-pos":28148767,"binlog-gtid":"fd2adbd9-e263-11e8-847a-141877487b3d:1-2600359"},"start_position":{"binlog-name":"mysql-bin.000014","binlog-pos":12866955,"binlog-gtid":"fd2adbd9-e263-11e8-847a-141877487b3d:1-2559919"}}
created_at: 2020-03-26 16:16:14
updated_at: 2020-03-26 16:19:26
*************************** 2. row ***************************
name: shard2
stage: stream
position: {"current_position":{"binlog-name":"mysql-bin.000014","binlog-pos":28155813,"binlog-gtid":"fd2adbd9-e263-11e8-847a-141877487b3d:1-2600366"},"start_position":{"binlog-name":"mysql-bin.000014","binlog-pos":16601348,"binlog-gtid":"fd2adbd9-e263-11e8-847a-141877487b3d:1-2569941"}}
created_at: 2020-03-26 16:16:31
updated_at: 2020-03-26 16:19:29
*************************** 3. row ***************************
name: shard3
stage: stream
position: {"current_position":{"binlog-name":"mysql-bin.000014","binlog-pos":28151964,"binlog-gtid":"fd2adbd9-e263-11e8-847a-141877487b3d:1-2600363"},"start_position":{"binlog-name":"mysql-bin.000014","binlog-pos":20333055,"binlog-gtid":"fd2adbd9-e263-11e8-847a-141877487b3d:1-2579960"}}
created_at: 2020-03-26 16:16:35
updated_at: 2020-03-26 16:19:29
*************************** 4. row ***************************
name: shard4
stage: stream
position: {"current_position":{"binlog-name":"mysql-bin.000014","binlog-pos":28152473,"binlog-gtid":"fd2adbd9-e263-11e8-847a-141877487b3d:1-2600364"},"start_position":{"binlog-name":"mysql-bin.000014","binlog-pos":24076960,"binlog-gtid":"fd2adbd9-e263-11e8-847a-141877487b3d:1-2589987"}}
created_at: 2020-03-26 16:16:40
updated_at: 2020-03-26 16:19:29
4 rows in set (0.000 sec)TIPS:
At this point, the data synchronization of our four subtables is ready, and we can insert a few more data tests.
-- insert into testdb.gravity_t1(user_id,s_status) values ('11111','0');
-- insert into testdb.gravity_t1(user_id,s_status) values ('11112','0');
-- I won't plug in the demo hereComparison of the number of data bars between the original and split tables:
[testdb] > select (user_id%4) as hash_id,count(*) FROM gravity_t1 group by (user_id%4); +---------+----------+ | hash_id | count(*) | +---------+----------+ | 0 | 2537 | | 1 | 2419 | | 2 | 2509 | | 3 | 2535 | +---------+----------+ 4 rows in set (0.009 sec
select count(*) FROM t1_shard1 where user_id%4=0; select count(*) FROM t1_shard2 where user_id%4=1; select count(*) FROM t1_shard3 where user_id%4=2; select count(*) FROM t1_shard4 where user_id%4=3;
Do a deletion of unnecessary data in the table first to prevent the deletion of too much data after a later switch:
delete from t1_shard1 where user_id %4!=0; delete from t1_shard2 where user_id %4!=1; delete from t1_shard3 where user_id %4!=2; delete from t1_shard4 where user_id %4!=3; ##Note: pt-archiver is recommended for deleting large tables of production environments
Then, go to the original table and the table to see if the data is consistent when compared with the query:
select (user_id%4),count(*) as hash_id FROM gravity_t1 group by (user_id%4); select count(*) FROM t1_shard1 where user_id%4=0; select count(*) FROM t1_shard2 where user_id%4=1; select count(*) FROM t1_shard3 where user_id%4=2; select count(*) FROM t1_shard4 where user_id%4=3;
Then wait until the rush hour for the operation.
1. dba reclaims write permissions on this large table for business accounts involved
revoke insert,update,delete on testdb.gravity_t1 from rd@'%'; flush hosts; flush tables;
2. Notify the business party to issue a release, switch the database to connect to four new tables
3. After the switch is completed, dba executes the operation of deleting dirty data of each sub-table again.
delete from t1_shard1 where user_id %4!=0; delete from t1_shard2 where user_id %4!=1; delete from t1_shard3 where user_id %4!=2; delete from t1_shard4 where user_id %4!=3;
4. Write permissions to open four new tables
GRANT select,insert,update,delete on testdb.t1_shard1 TO rd@'%'; GRANT select,insert,update,delete on testdb.t1_shard2 TO rd@'%'; GRANT select,insert,update,delete on testdb.t1_shard3 TO rd@'%'; GRANT select,insert,update,delete on testdb.t1_shard4 TO rd@'%';
5. Then notify the business party to test.
6. The business party shall finish work after verifying that there are no problems.At this point, the operation of splitting the form into split tables is complete.
7. A fallback scheme to be supplemented (Open gravity's two-way replication?)