Redis: Basic
Recommended java3y: https://mp.weixin.qq.com/s/SdE6MR9g-v93ZtJPme9e8Q
1: What is Redis?
Redis is a memory cache database. The full name of redis is: remote dictionary server (remote data service), which is written in C language. Redis is a key value storage system (key value storage system), which supports rich data types, such as String, list, set, zset and hash.
Redis is a storage system that supports multiple data structures such as key value. It can be used for caching, event publishing or subscription, high-speed queue and other scenarios. Written in C language, it supports network, provides string, hash, list, queue and collection structure, direct access, memory based and persistent.
2: Redis function and usage scenario
1. Redis's role
Obtain the latest n data; Obtain the data of TOP N; Set accurate rush buying time; Implement counter; Remove duplicate values; Using set command to make anti garbage system; Build a queue system.
3: Redis's bottleneck lies in memory and network, not CPU
Redis is based on memory operation, and cpu is not the bottleneck of redis. The bottleneck of redis is most likely from memory and network bandwidth. Single thread implementation is simpler, and cpu is not the bottleneck, so redis is implemented by single thread.
4: Why is Redis fast?
1. redis is based on memory. The read and write speed of memory is very fast
CPU is not the bottleneck of Redis. The most likely bottleneck of Redis is the size of machine memory or network bandwidth.
2. redis is single threaded, which saves a lot of time for context switching threads
2.1: the performance consumption of various locks is not required
Redis's data structures are not all simple key values, but also complex structures such as list and hash. These structures may carry out very fine-grained operations, such as adding an element after a long list and adding or deleting an element in the hash
An object. These operations may require a lot of locks, resulting in a significant increase in synchronization overhead.
In the case of single thread, there is no need to consider the problems of various locks. There is no operation of adding and releasing locks, and there is no performance consumption caused by possible deadlock.
2.2: single thread multi process cluster scheme
In fact, the power of single thread is very powerful, and the efficiency of each core is also very high. Multi thread can naturally have a higher performance limit than single thread. However, in today's computing environment, even the upper limit of single machine multi thread often can not meet the needs. What needs to be further explored is the scheme of multi server clustering, Multithreading technology in these schemes is still useless.
2.3: CPU consumption
Using single thread avoids unnecessary context switching and competition conditions, and there is no CPU consumption caused by switching caused by multiple processes or threads.
2.4: what if the CPU becomes a Redis bottleneck or does not want other CPU cores of the server to be idle
Several redis processes can be considered. Redis is a key value database, not a relational database, and there are no constraints between data. As long as the client can distinguish which keys are placed on which redis process.
3. redis uses multiplexing technology to handle concurrent connections.
The internal implementation of non blocking io adopts epoll, which adopts the simple event framework implemented by epoll + itself. The read, write, close and connection in epoll are converted into events, and then the multiplexing characteristics of epoll are used to never waste any time on io.
4. IO multiplexing technology
redis adopts network IO multiplexing technology to ensure the high throughput of the system when multiple connections are made.
Multiplexing - refers to multiple socket connections, multiplexing - refers to multiplexing a thread. There are three main multiplexing technologies: select, poll and epoll. Epoll is the latest and best multiplexing technology at present.
Here, "multiplexing" refers to multiple network connections, and "multiplexing" refers to multiplexing the same thread. Using multiplex I/O multiplexing technology can enable a single thread to efficiently process multiple connection requests (minimize the time consumption of network IO), and Redis operates data in memory very fast (the operation in memory will not become the performance bottleneck here). The above two points mainly make Redis have high throughput.
5: Advantages and disadvantages of Redis single thread
1. Advantages of single process and single thread
Clearer code and simpler processing logic
There is no need to consider the problems of various locks. There is no operation of adding and releasing locks, and there is no performance consumption caused by possible deadlocks
There is no CPU consumption due to switching caused by multiple processes or threads
2. Disadvantages of single process and single thread
The performance of multi-core CPU cannot be brought into play, but it can be improved by opening multiple Redis instances on a single machine;
Redis: data type
String (string)
String: the simplest string type key value pair cache, which is also the most basic
1: key correlation
keys *: view all key s (not recommended for production, with performance impact)
type key: the type of key
2: Common commands
get/set/del: query/set up/delete set rekey data: Set existing key,Will cover setnx rekey data: Set existing key,Will not overwrite set key value ex time: Set data with expiration time expire key: Set expiration time ttl: View the remaining time,-1 Never expire,-2 be overdue append key: Merge string strlen key: String length incr key: Accumulate 1 decr key: Class minus 1 incrby key num: Accumulate the given value decrby key num: Decrement given value getrange key start end: Intercept data, end=-1 Representative to the end setrange key start newdata: from start Position start replace data mset: Continuous setting mget: Continuous value msetnx: Continuous setting, if it exists, it will not be set
4: Other
select index: Switch databases, with a total of 16 by default flushdb: Delete current lower edge db Data in flushall: Delete all db Data in
List
1: list introduction
Redis list is a simple string list, sorted by insertion order. You can add an element to the head (left) or tail (right) of the list.
- The list type is used to store multiple ordered strings, and supports the storage of 2 ^ 32 power - 1 elements.
- redis can insert (pubsh) and pop (POP) elements from both ends of the linked list to act as a queue or stack
- Supports reading the element set of the specified range
- Read the elements of the specified subscript, etc
List is a linked list structure, which is bidirectional. This means that the insertion and deletion operations of the list are very fast, and the time complexity is O(1), but the index positioning is very slow, and the time complexity is O(n)
In addition, when the last element pops up in the list, the data structure is automatically deleted and the memory is recycled.
list can also be regarded as a queue, so redis can be used as a message queue in many cases. At this time, its function is similar to activeMq;
Application cases include timeline data, comment list, message passing, etc. it can provide simple paging, reading and writing operations.
2: Common commands
lpush: Add data from the left header of the list example: lpush mylist 1 or lpush mylist 2 rpush: Add data from the right end of the list example: rpush mylist 1 or rpush mylist 2 lpop: Take an element from the left head(Remove the first element at the head of the list, and the return value is the removed element) example: lpop mylist see: lrange mylist rpop: Take an element from the left tail(The removed element returns the last value of the removed element) example: rpop mylist see: lrange mylist lrange: Gets the element of the specified range Lrem: Deletes the specified element of the list Example: number of deletes (if less than 0, delete from right to left; if equal to 0, delete all) lrem mylist 3 1 index: Get the value of the first few coordinates index mylist 2 llen: Gets the length of the list llen mylist lset: Modify the small value of coordinates lset mylist 1 tomcat ltrim: Trim list ltrim mylist 1 3 linsert: Add element at specified location linsert mylist befor 0 -1 lpushx: Insert a value into the existing list header; If there is a list, you can add it. If you don't save, you can't add it rpushx: Insert a value at the end of the existing list; If there is a list, you can add it. If you don't save, you can't add it blpop: If there is a value in the list, it will be taken out. If there is no value, it will be blocked until there is a value to get, and the timeout time will be( timeout 0 (for indefinite) blpop mylist 0 brpop: ditto brpoplpush: ditto
Hash (hash)
1: hash introduction
Similar to map, it stores structured data structures, such as storing an object (no nested objects).
Redis hash is a mapping table of field and value of string type. Hash is especially suitable for storing objects.
Each hash in Redis can store 232 - 1 key value pairs (more than 4 billion).
2: hash usage scenario
Generally, objects are stored in string + json, and some frequently changing attributes in objects are extracted and stored in hash.
When an attribute of an object needs to be modified frequently, string+json is not suitable because it is not flexible enough. Each modification requires re serialization and assignment of the whole object. If hash type is used, it can be modified separately for a certain attribute without serialization or modification of the whole object.
For example, attributes that may change frequently, such as commodity price, sales volume, number of concerns and number of evaluations, are suitable for storage in hash type.
3: Common commands
Hset key field value: The command is used to assign values to fields in a hash table.
If the hash table does not exist, a new hash table is created and updated HSET Operation.
If the field already exists in the hash table, the old value will be overwritten.
HSET myhash field1 "foo"
Return value
If the field is a new field in the hash table and the value is set successfully, 1 is returned. If the domain field in the hash table already exists and the old value has been overwritten by the new value, 0 is returned.
HGET key field: Gets the value of the specified field stored in the hash table.
hget testhash name
Returns the value of the given field. If a given field or key If it does not exist, return nil.
HGETALL key: Gets the value specified in the hash table key All fields and values for
Returns the fields and field values of the hash table in list form. if key Does not exist, return empty list.
hgetall testhash
HKEYS key: Gets the fields in all hash tables
Contains all fields in the hash table( field)List. When key Returns an empty list when it does not exist.
hkeys testhash
HEXISTS key field: View hash table key Whether the specified field exists in.
Returns 1 if the hash table contains the given field. If the hash table does not contain the given field, or key Does not exist, return 0.
hexists testhash name
HLEN key: Gets the number of fields in the hash table
Returns the number of fields in the hash table. When key Returns 0 if it does not exist.
hlen testhash
hlen testsss
HVALS key: Obtain all values in the hash table;
One contains all fields in the hash table(field)List of values. When key When it does not exist, an empty table is returned.
hvals testhash
HSETNX key field value: Only in field field When it does not exist, set the value of the hash table field;
Set successfully, return 1. If the given field already exists and no operation is performed, return 0.
hsetnx testhash score 100
HINCRBY key field increment: Is a hash table key The integer value of the specified field in plus the increment increment .
Return value: Execute HINCRBY After the command, the value of the field in the hash table.
hgetall testhash
hincrby testhash age 2
HINCRBYFLOAT key field increment: Is a hash table key The floating-point value of the specified field in plus the increment increment .
Return value: Execute Hincrbyfloat After the command, the value of the field in the hash table.
hgetall testhash
hincrbyfloat testhash age 1.1
HMSET key field1 value1 [field2 value2 ]
Multiple at the same time field-value (field-value)Hash to table settings key Yes.
hmset student name xiaohu age 18 gender men
see:
hget student name
hget student age
hget student gender
HMGET key field1 [field2]
Gets the value of all the given fields
A table containing the associated values of multiple given fields. The table values are arranged in the same order as the request order of the specified fields. No, return nil
hmset student name xiaohu age 18 gender men
see:
hget student name
hget student age
hget student gender
Get all:
hmget student name age gender body
Hdel:
Delete one or more hash table fields
HSET myhash field1 "foo"
Return value: the number of fields successfully deleted, excluding the ignored fields.
success:(integer) 1;Cannot exist:(integer) 0
HSTRLEN key field
Gets the name of the specified field field The length of the. three.2 Later version
Set (unordered set)
1: Set set introduction
Redis Set is an unordered Set of String type. Collection members are unique, which means that duplicate data cannot appear in the collection.
The code of the collection object can be intset or hashtable.
The collection in Redis is realized through hash table, so the complexity of adding, deleting and searching is O(1).
The largest number of members in the collection is 232 - 1 (4294967295, each collection can store more than 4 billion members).
2: set common commands
1,sadd Add an element to the collection (the elements in the collection are unordered and unique) sadd myset ceshi1 sadd myset ceshi2 ceshi3 smembers myset 2,smembers View all elements in the collection smembers myset 3,srem Deletes the element specified in the union srem myset ceshi1 1 returned successfully 4,scard Returns the number of collection elements scard myset 5,sRandMember If the number returned is not filled in, the default value is 1. If the number filled in is greater than the number of sets size,Then all elements of the collection are returned If you fill in a negative number, if the absolute value is greater than the value of the set size,Then an element will appear multiple times in the return value. If key If it does not exist, return nil srandmember myset srandmember myset1 6,smove Transfer elements from one set to another srandmember myset 5 srandmember myset1 ceshi6 smove myset myset1 ceshi3 7,spop Randomly remove an element from the collection smembers myset spop myset smembers myset 8,sismember Judge whether the element is in the collection. If it exists, return 1; otherwise, return 0 smembers myset sismember myset ceshi1 sismember myset kkkk 9,sscan Use cursors to get values in the collection sscan scantest 0 match scanceshi* Starting from 0 and looping all the time, two sets will be returned. The first one is the position of the cursor. If it is 0, the execution ends, If it is not 0, the value returned by the first set will be used as the starting position next time, as follows 10,sunion Set union operation(Set merging/hand over/Difference operation) sadd bing1 1 11 111 sadd bing2 2 22 222 sadd bing3 3 33 333 sunion bing1 bing2 bing3 11,SUNIONSTORE Save the union set to a new set (if the result set is saved to the existing set, it will overwrite the later data set) sunionstore bing4 bing1 bing2 smembers bing4 12,sinter/sinterstore ditto 13,sdiff/sdiffstore ditto
Zset (ordered set)
1: Introduction to ZSet
Redis ordered collections, like collections, are collections of string elements, and duplicate members are not allowed.
The difference is that each element is associated with a score of type double. redis sorts the members of the collection from small to large through scores.
Members of an ordered set are unique, but scores can be repeated.
The set is implemented through hash table, so the complexity of adding, deleting and searching is O(1). The largest number of members in the collection is 232 - 1 (4294967295, each collection can store more than 4 billion members).
2: Common commands
1,zadd Add (one or more)
zadd key score1 member1 [score2 member2]
Add one or more members to an ordered collection, or update the scores of existing members.
Command is used to add one or more member elements and their fractional values to an ordered set.
If a member is already a member of an ordered set, update the score value of the member and reinsert the member element to ensure that the member is in the correct position.
The fractional value can be an integer value or a double precision floating-point number.
If ordered set key If it does not exist, an empty ordered set is created and executed ZADD Operation.
When key An error is returned when an ordered set type exists but is not.
example:
zadd myzset 1 name 2 age 3 gender
zrang myzset 0 -1 withscore
zadd myzset 1 names
zrang myzset 0 -1 withscores
2,zincrby Modify member score
zincrby key increment member
ZINCRBY key increment member
Increments the score of a specified member in an ordered set increment
Redis zincrby The command increments the fraction of a specified member in an ordered set increment
You can pass a negative value increment ,Subtract the corresponding value from the score, such as ZINCRBY key -5 member ,Just let member of score Value minus 5.
When key Does not exist, or the score is not key When members of, ZINCRBY key increment member Equivalent to ZADD key increment member .
When key An error is returned when it is not an ordered set type.
The fractional value can be an integer value or a double precision floating-point number.
Return value: member The new score value of the member, expressed in string form.
zrang myzset 0 -1 withscores
zincrby myzset -1 class
zrang myzset 0 -1 withscores
zincrby myzset -1 class
3,zrang Query (index query)-Score (increment)
Returns the members in the specified interval of the ordered set through the index interval
Syntax: ZRANGE key start stop [WITHSCORES]
Return value: within the specified interval, with score value(Optional)A list of ordered set members.
## Show entire ordered set members
zrang myzset 0 -1 withscores
## When displaying members of ordered set subscript ranges 1 to 2
zrang myzset 1 2 withscores
## Test the condition when the end subscript exceeds the maximum subscript
zrang myzset 0 1000 withscores
4,zcard Gets the number of ordered collection members
Syntax: zcard key
Redis zcard The command calculates the number of elements in a collection.
Return value:When key Returns the cardinality of an ordered set when it exists and is an ordered set type. When key Returns 0 if it does not exist
zcard myzset
zcard myzsets
5,zcount Query the number of members of the specified interval score
Syntax: zcount key min max
Calculates the number of members of a specified interval score in an ordered set
The command is used to calculate the number of members of a specified score interval in an ordered set.
Return value: the score value is min and max Number of members between.
zrang myzset 0 -1
zrang myzset 0 -1 withscores
zcount myset 1 2
zcount myzsets 1 2
6,zlexcount Query the number of members in the specified dictionary range
zlexcount key min max
Calculates the number of members in the specified dictionary interval in an ordered set
Return value:Specifies the number of members in the interval.
zrang myzset 0 -1 withscores
zlexcount myset [a [b
zlexcount myset [a [d
zlexcount myset [a [z
7,zrangebyscore Query the members of the specified score range - Increasing score
Syntax: zrangebyscore key min max [withscores] [limit]
Returns the members in the specified interval of an ordered set through scores
zrangebyscore Returns a list of members of a specified score range in an ordered set. The members of the ordered set are incremented by the score value(from small to large)Order.
Members with the same score are arranged in dictionary order(This attribute is provided by an ordered set and requires no additional calculation).
By default, closed intervals are used for interval values (Less than or equal to),You can also add ( Symbol to use the optional open interval (Less than or greater than).
zrang myset 0 -1 withscores
zrangebyscore myset -1 3 withscores
8,zrank Queries the index of the specified member (Sorting by increasing fractional value)
zrank key member
Returns the index of a specified member in an ordered collection
zrank Returns the ranking of specified members in an ordered set. The members of the ordered set are incremented by the score value(from small to large)Order.
zadd myset 1 11 2 22 3 33 4 55 6 66
zrang myset 0 -1 withscores
zrank myset 11
zrank myset 22
9,zrevrank Query the index of the specified member (sort by decreasing the score value)
Syntax: zrevrank key member
Returns the ranking of the specified members in the ordered set. The members of the ordered set are decremented by the score value(From small to large)sort
Return value: if the member is an ordered set key Returns the ranking of members. If the member is not an ordered set key Member, return nil .
zrevrank Command returns the ranking of members in an ordered set. The members of the ordered set decrease according to the score value(From small to large)Sort.
The ranking is based on 0, that is, the member with the largest score is ranked as 0.
use ZRANK Command can get members to increase by points(from small to large)Rank in order.
zrang myset 0 -1 withscores
zrevrank myset 11
zrevrank myset 22
Redis: version comparison
Redis2.0
1,Redis2.6 Redis2.6 It was released in 2012. It has experienced 17 versions and reached 2.6.17 Version, relative to Redis2.4,The main features are as follows: (1)Server support Lua script. (2)Remove virtual memory related functions. (3)Release the hard coding limit on the number of client connections. (4)The expiration time of the key supports milliseconds. (5)The slave node supports read-only function. (6)Two new bitmap commands: bitcount and bitop. (7)Enhanced redis-benchmark Function: support customized pressure measurement, CSV Output and other functions. (8)Floating point based autoincrement command: incrbyfloat and hincrbyfloat. (9)redis-cli have access to--eval Parameter realization Lua Script execution. (10)shutdown Command enhancement. (11)A large number of core codes have been reconstructed, and all cluster related codes have been removed, cluster The function will be 3.0 The biggest highlight of the version. (12)info Can follow section Output, and added some statistics (13)sort Command optimization 2,Redis2.8 Redis2.8 Officially released on November 22, 2013, it has experienced 24 versions and reached 2.8.24 Version, compared to Redis2.6,The main features are as follows: (1)Adding the function of partial master-slave replication reduces the generation of frequent full replication due to network problems to a certain extent RDB Pressure on the system. (2)Tentative support IPv6. (3)Can pass config set Command settings maxclients. (4)Can use bind Bind multiple commands IP Address. (5)Redis Set an obvious process name for easy use ps Command to view system processes. (6)config rewrite The command can config set Persist to Redis In the configuration file. (7)Publish subscription added pubsub. (8)Redis Sentinel Second edition, compared with Redis2.6 of Redis Sentinel,This version has become available for production.
Redis3.0
1,Redis3.0((milestone) Redis3.0 Officially released on April 1, 2015, compared with Redis2.8 The main features are as follows: Redis The biggest change is to add Redis Distributed implementation of Redis Cluster. (1)Redis Cluster: Redis Official distributed implementation of. (2)all-new embedded string As a result of object coding, the memory access of small objects is optimized, and the download speed is greatly improved in a specific workload. (3)Iru The algorithm is greatly improved. (4)migrate Connect the cache to greatly improve the speed of key migration. (5)migrate Command two new parameters copy and replace. (6)new client pause Command to stop processing client requests within a specified time. (7)bitcount Improved command performance. (8)cinfig set set up maxmemory Different units can be set at different times (previously only bytes). (9)Redis Minor adjustments to the log: the role of the current instance will be reflected in the log( master perhaps slave). (10)incr Improved command performance. 2,Redis3.2 Redis3.2 Officially released on May 6, 2016, compared with Redis3.0 The main features are as follows: (1)add to GEO Related functions. (2)SDS It has been optimized in terms of speed and space saving. (3)Support use upstart perhaps systemd Administration Redis Process. (4)new List Code type: quicklist. (5)Read expired data from the node to ensure consistency. (6)Added hstrlen Command. (7)Enhanced debug Command, which supports more parameters. (8)Lua Script enhancements. (9)Added Lua Debugger. (10)config set Support more configuration parameters. (11)Optimized Redis Relevant reports after the crash. (12)new RDB Format, but it is still compatible with the old one RDB. (13)accelerate RDB Loading speed. (14)spop The command supports number parameters. (15)cluster nodes The command is accelerated. (16)Jemalloc Update to 4.0.3 edition.
Redis4.0
Here is Redis4.0 New features: (1)A module system is provided to facilitate the expansion of third-party developers Redis The function of. (2)PSYNC2.0: It optimizes the problem of full replication caused by master-slave node switching in the previous version. (3)Provides a new cache culling algorithm: LFU(Last Frequently Used),The existing algorithms are optimized. (4)Provides non blocking del and flushall/flushdb Function, which effectively solves the problem of deletion bigkey Possible causes Redis Blocking. (5)Provided memory Command to realize more comprehensive monitoring and statistics of memory. (6)It provides interactive database function and realizes Redis Data replacement of internal database. (7)Provided RDB-AOF Mixed persistence format, making full use of AOF and RDB Respective advantages. (8)Redis Cluster compatible NAT and Docker.
Redis5.0
(1)new Stream Data type. (2)new Redis modular API: Timers and Cluster API. (3)RDB Now store LFU and LRU Information. (4)Cluster manager from Ruby(redis-trib.rb)Transplant to C code. Can be in redis-cli Yes. see`redis-cli —cluster help`Learn more. (5)new sorted set Command: ZPOPMIN / MAX And blocking variables. (6)Active defragmentation V2. (7)enhance HyperLogLog realization. (8)Better memory statistics report. (9)Many commands with subcommands now have one HELP Subcommand. (10)Better performance when customers often connect and disconnect. (11)Bug fixes and improvements. (12)Jemalloc Upgrade to 5.1 edition
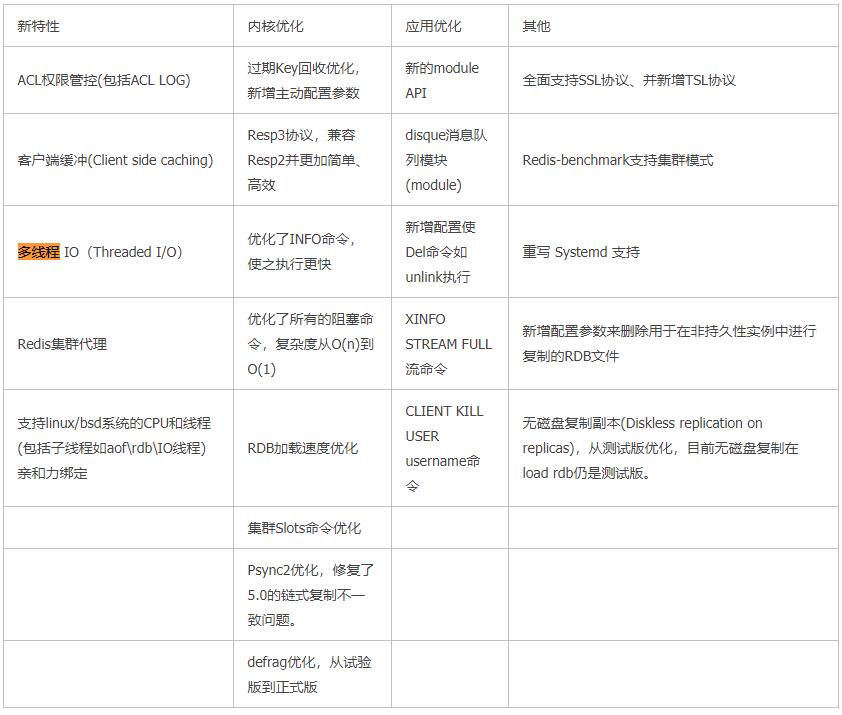
Redis6.0
https://zhuanlan.zhihu.com/p/76788470