In our daily use of redis development, cache penetration, breakdown and avalanche are unavoidable problems. It is also a question we are often asked during the interview. Next, we will explain a variety of solutions to these three kinds of problems.
Buffer breakdown
Cache breakdown means that a Key is very hot and is accessed with high concurrency at some time points. When the Key breaks through the cache (Redis) at the moment of failure, it directly requests to the database (DB), resulting in problems in the database.
Solution 1: use mutex lock
The idea of this solution is relatively simple, that is, only one thread is allowed to query the database, while other threads wait for the thread querying the database to finish executing and re add the data to the cache, and other threads can obtain data from the cache.
If it is a stand-alone system, it can be processed with synchronized or lock. The distributed system can use the setnx operation of redis.
Stand alone environment
- The principle of the implementation in the stand-alone environment is that when the cached data expires, a large number of requests come in. Only the first thread can access the database, and other threads pause. When the main thread queries the data and releases the lock, other threads can directly read the data in the cache.
public String get(key){
//Get data from cache
String value = redis.get(key);
if(value == null){ //Data in cache does not exist
if(reenLock.tryLock()){ //Acquire lock
//Get data from database
value=db.get(key);
//Update cache data
if(value!=null){
redis.set(key, value, expire_secs);
}
//Release lock
reenLock.unlock();
}else{ //Failed to acquire lock
//Pause for 100ms and retrieve the data again
Thread.sleep(100);
value = redis.get(key);
}
}
}
distributed environment
- When the cache fails, first judge that the value is empty. Instead of checking the database immediately, first use some operations of the cache tool with the return value of successful operations (such as setnx of Redis) to set a mutex key. When the operation returns success, then check the database and reset the cache. Otherwise, retry the entire get cached method.
public String get(key){
//Get data from cache
String value = redis.get(key);
if(value == null){ //Represents that the cache value has expired
//Set a 3-minute timeout to prevent the next cache expiration from checking the database when the deletion operation fails
if(redis.setnx(key_mutex,1,3*60) == 1){ //=1 means the setting is successful
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
}else{ //At this time, it means that other threads at the same time have loaded dB and set it back to the cache. At this time, try again to obtain the cache value
sleep(50);
get(key); //retry
}
}else{
return value;
}
}
Solution 2: hotspot data never expires
It should be noted that the never expiration mentioned here is not to set the lifetime of hot data to unlimited. Instead, the expiration time is stored in the value corresponding to the key. If it is found to be expired, the cache is rebuilt through a background asynchronous thread.
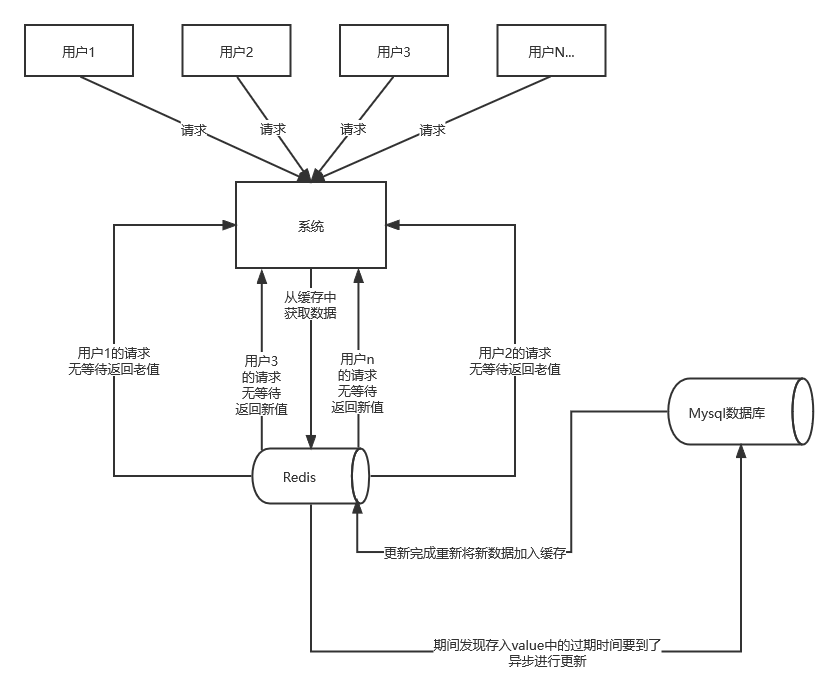
From the practical point of view, this method is very friendly for performance. The only disadvantage is that when rebuilding the cache, other threads (threads not rebuilding the cache) may access old data, but it is still tolerable for general Internet functions.
public String get(Sting key){
V v = redis.get(key);
String value = v.getValue();
long timeout = v.getTimeout();
if (v.timeout <= System.currentTimeMillis()){
// Asynchronous update background exception execution
threadPool.execute(new Runnable(){
public void run(){
String keyMutex = "mutex:" + key;
if(redis.setnx(keyMutex, "1")){
//3 min timeout to avoid mutex holder crash
redis.expire(keyMutex, 3 * 60);
String dbValue = db.get(key);
redis.set(key, dbValue);
redis.delete(keyMutex);
}
}
});
}
return value;
}
Solution 3: regular refresh
A job (scheduled task) is defined in the background to actively update the cached data. For example, if the expiration time of the data in a cache is 30 minutes, the job will regularly refresh the data every 29 minutes (update the data found from the database to the cache).
This scheme is easy to understand, but it will increase the complexity of the system. It is more suitable for those keys that are relatively fixed. For services with large cache granularity, those with scattered keys are not suitable, and the implementation is also complex.
Cache penetration
Cache penetration refers to that users maliciously initiate a large number of requests to query data that is not available in a redis and database. For fault tolerance, if the data cannot be found from the database (DB), it will not be written to the redis. This will cause each request to query in the database (DB), which will lose the significance of cache, resulting in the database hanging up due to excessive pressure.
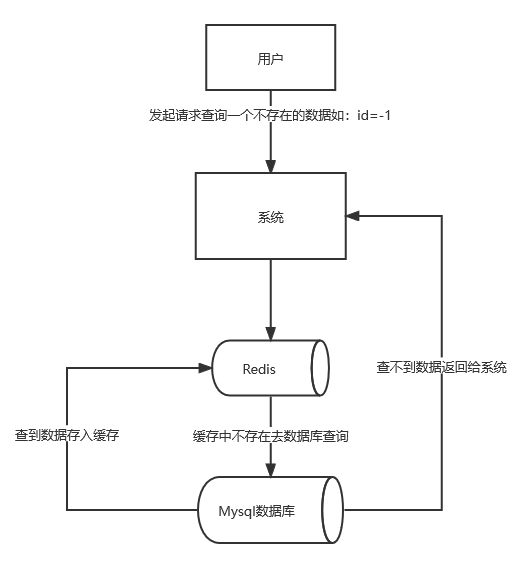
Solution 1: cache empty data
Caching empty data is a simple and crude method. If the data returned by a query is empty (whether the data does not exist or the system fails), we still cache the empty result, but its expiration time will be very short, no more than five minutes.
Although this method can block a large number of penetration requests, this null value does not have any practical business. Moreover, if a large number of penetration requests for non-existent data are sent (such as malicious attacks), it will waste cache space. If this null value is excessive, it will eliminate the data in its own cache, which will reduce our cache hit rate.
//Pseudo code
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
String cacheValue = CacheHelper.Get(cacheKey);
if (cacheValue != null) {
return cacheValue;
}
cacheValue = CacheHelper.Get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
//The database cannot be queried and is empty
cacheValue = GetProductListFromDB();
if (cacheValue == null) {
//If it is found to be empty, set a default value and cache it
cacheValue = string.Empty;
}
//product_list, null value, expiration time
CacheHelper.Add(cacheKey, cacheValue, cacheTime);
return cacheValue;
}
}
Solution 2: bloom filter
This technology adds a layer of barrier before caching, which stores all the keys existing in the current database. When the business system has a query request, first query whether the key exists in BloomFilter. If it does not exist, it means that the data does not exist in the database, so do not check the cache and directly return null. If it exists, continue the follow-up process, first query in the cache, and then query in the database if it does not exist in the cache.
//Pseudo code
String get(String key) {
String value = redis.get(key);
if (value == null) {
if(!bloomfilter.mightContain(key)){
//If it does not exist, return
return null;
}else{
//If possible, check the database
value = db.get(key);
redis.set(key, value);
}
}
return value;
}
Cache avalanche
Cache avalanche refers to the restart of the cache server or the massive expiration of the data in the cache (Redis) at the same time. Due to the large amount of query data, the database is under too much pressure or even down.
Solution 1: lock queue
Locking queuing is only to reduce the pressure on the database and does not improve the system throughput. Assuming that the key is locked during cache reconstruction under high concurrency, 999 of the last 1000 requests are blocked. It will also cause users to wait for timeout, which is a way to cure the symptoms rather than the root cause!
Note: in high concurrency scenarios, do not use it as much as possible!
//Pseudo code
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
String lockKey = cacheKey;
String cacheValue = CacheHelper.get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
synchronized(lockKey) {
cacheValue = CacheHelper.get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
//This is generally sql query data
cacheValue = GetProductListFromDB();
CacheHelper.Add(cacheKey, cacheValue, cacheTime);
}
}
return cacheValue;
}
}
Solution 2: set the random value of expiration time
Avoid setting a similar validity period for the cache, and add a random value (1-5 minutes) for the validity period to make the failure time evenly distributed. In this way, the repetition rate of the expiration time of each cache will be reduced, and it is difficult to cause collective failure events.
redis.set(key, value, random);
Solution 3: set the expiration flag to update the cache
Cache flag: Records whether the cache data has expired. If it has expired, it will trigger another thread to update the cache of the actual key in the background;
Cache data: its expiration time is twice longer than that of the cache mark. For example, the mark cache time is 30 minutes and the data cache is set to 60 minutes. In this way, when the cache mark key expires, the actual cache can return the old data to the caller, and will not return the new cache until another thread completes the background update.
//Pseudo code
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
//Cache tag
String cacheSign = cacheKey + "_sign";
String sign = CacheHelper.Get(cacheSign);
//Get cache value
String cacheValue = CacheHelper.Get(cacheKey);
if (sign != null) {
return cacheValue; //Not expired, return directly
} else {
CacheHelper.Add(cacheSign, "1", cacheTime);
ThreadPool.QueueUserWorkItem((arg) -> {
//This is generally sql query data
cacheValue = GetProductListFromDB();
//The date is set to twice the cache time for dirty reading
CacheHelper.Add(cacheKey, cacheValue, cacheTime * 2);
});
return cacheValue;
}
}
Summary
- Buffer breakdown 👇
The data corresponding to the key exists, but it expires in redis. At this time, if a large number of concurrent requests come, if these requests find that the cache expires, they will generally load data from the back-end dB and set it back to the cache. At this time, large concurrent requests may crush the back-end DB instantly. This problem is generally solved by mutual exclusion, hot data never expires, and regularly refreshing the expiration time.
- Cache penetration 👇
The data corresponding to the key does not exist in the data source. Every time a request for this key cannot be obtained from the cache, the request will be sent to the data source, which may crush the data source. For example, using a nonexistent user id to obtain user information, no matter in the cache or the database, if hackers use this vulnerability to attack, it may crush the database. Generally, this problem is solved by caching empty data and bloom filter.
- Cache avalanche 👇
When the cache server restarts or a large number of caches fail in a certain period of time, it will also bring great pressure to the back-end system (such as DB). This problem is usually solved by locking queue, setting expiration time and random value.
The above solutions should be used for business systems. There is no best, only the most appropriate!