redis cluster summary and sentry explanation
Why cluster
1. A single redis is unstable. When the redis service goes down, there are no available services.
2. The reading and writing ability of a single redis is limited
redis master-slave replication
There is only one Master node, and there can be multiple Slave nodes
As long as the network connection is normal, the Master will always synchronize its own data updates to the slave to keep the Master-slave synchronization.
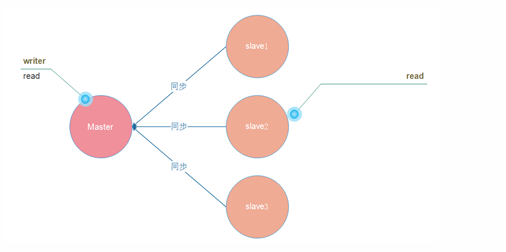
The Master node is readable and writable
Slave node slave is read-only. (read-only)
Therefore, the Master-slave model can improve the reading ability and alleviate the writing ability to a certain extent. Because there is still only one Master node that can write, all read operations can be handed over to the slave node, which improves the writing ability in a disguised form.
Sentinel sentinel mode
Why sentinels
Defects of master-slave mode:
When the primary node goes down, the whole cluster has no writable nodes.
Since all the data of the master node is backed up on the slave node, can this problem be solved if the slave node can be turned into a master node when the master node is down?
Yes, this is Sentinel's role
Basic knowledge of sentry
- During failover, it is judged that a master node is down, which requires the consent of most sentinels, and involves the problem of distributed election
- Sentinels need at least 3 instances to ensure their robustness
- The sentinel + redis master-slave deployment architecture will not guarantee zero data loss, but only the high availability of the redis cluster
How to confirm downtime
sdown and odown fail
- sdown is a subjective outage. If a sentinel thinks a master is down, it is a subjective outage
- odown is an objective outage. If a number of sentinels in quorum think that a master is down, it is an objective outage
- sdown's condition: if a sentinel ping a master exceeds the number of milliseconds specified by is master down after milliseconds, the master is considered to be down
- Odown conditions: if a sentinel receives a specified number of quota within the specified time, and other sentinels also think that the master is sdown, it is considered odown. Objectively, it is considered that the master is down
quorum is a number that indicates how many sentinel s consider a master to be invalid before the master is really invalid
Why do sentinels have at least 3 nodes
Sentinel cluster must deploy more than 2 nodes. If only two sentinel instances are deployed in the sentinel cluster, its priority is 2 (2's priority = 2, 3's priority = 2, 5's priority = 3, and 4's priority = 2). If one of the Sentinels goes down, the condition of priority > = 2 cannot be met, and master-slave switching cannot be performed in case of master failure.
Sentry workflow
[external chain picture transfer failed. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-quhjcoyu-1593674842218)( https://i.bmp.ovh/imgs/2020/07/5fdbd58226de96e6.png )]
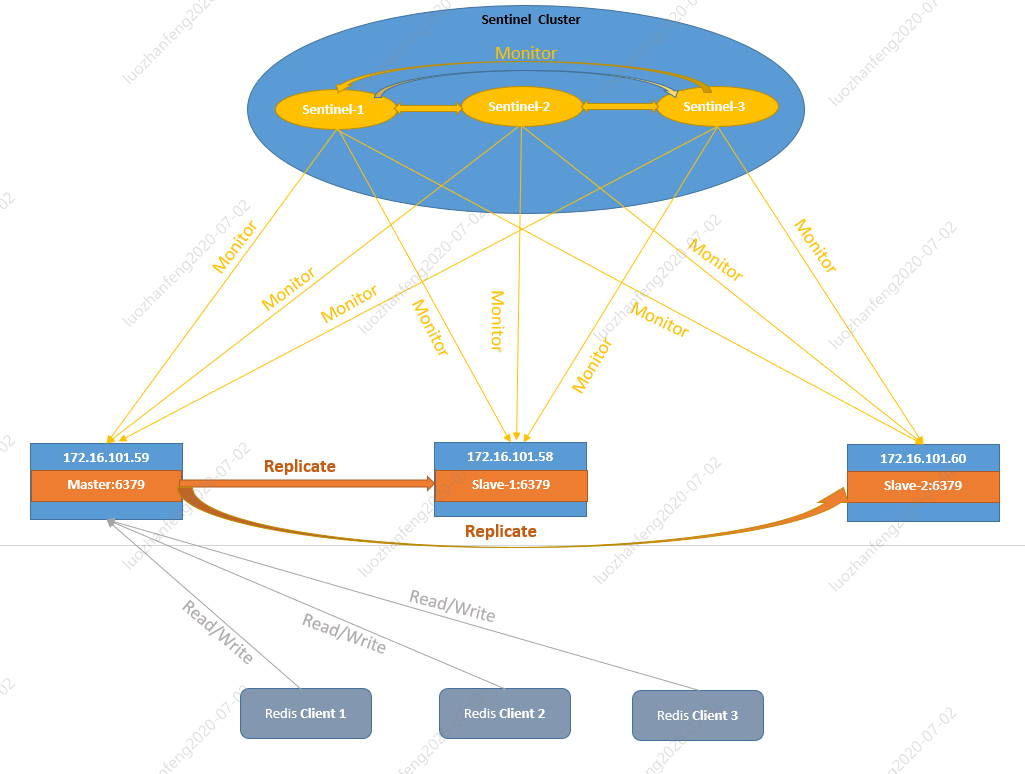
- 1 Sentinel cluster includes three sentinel nodes, sentinel1, sentinel2 and SENTINEL3. Each node of sentinel cluster monitors the operation status of sentinels.
- 2. Each node of sentinel cluster ping s the Redis master node to check the running status of the Redis master node.
- 3. Assuming that the Sentinel cluster detects that the Master node of Redis is down and fails to recover within the specified time, the Sentinel cluster will fail over Redis.
- 3.1 first, Sentinel cluster selects a slave node with the highest priority from each slave node and promotes it to the Master node.
- 3.2 secondly, the new Master node sends the slaveof command to all slave nodes of the original Master, makes them serve as the slave nodes of the new Master, copies the data of the new Master node to each slave node, and the failover is completed.
- 3.3 finally, Sentinel cluster will continue to monitor the old Master node. After the old Master is back online, Sentinel will set it as the slave node of the new Master.
- 3.4 the topology diagram after failover is as follows. In the diagram, slave node slave-1 is elected as the node of the new Master.
Failover log analysis
The master is 140 and the slave node slave is 75236141
I now manually delete 140 nodes to simulate master downtime
# A new Sentinel has been identified and added 1:X 01 Jul 2020 07:41:54.867 * +sentinel sentinel c757c2a6d7e488bb4b421e6875c8032442efdb27 10.42.1.142 26379 @ mymaster 10.42.1.140 6379 # Start a new era (version number of each failover). See below for details 1:X 01 Jul 2020 07:41:56.949 # +new-epoch 13 # Start electing leaders 1:X 01 Jul 2020 07:41:56.951 # +vote-for-leader 0fdb8118769d9d4ff83d4576ec327290fd00146c 13 # Both master and sentinel are in subjective offline status 1:X 01 Jul 2020 07:41:57.706 # +sdown master mymaster 10.42.1.140 6379 1:X 01 Jul 2020 07:41:57.706 # +sdown sentinel ddb8223728d2f1f9bbb8d30bb3630463a83378a5 10.42.1.140 26379 @ mymaster 10.42.1.140 6379 # Vote, judge 140 objective downtime 1:X 01 Jul 2020 07:41:57.772 # +odown master mymaster 10.42.1.140 6379 #quorum 3/2 # In some cases, delay the failover time 1:X 01 Jul 2020 07:41:57.772 # Next failover delay: I will not start a failover before Wed Jul 1 07:42:33 2020 # Start a new era 1:X 01 Jul 2020 07:42:33.363 # +new-epoch 14 # Try failover master 1:X 01 Jul 2020 07:42:33.363 # +try-failover master mymaster 10.42.1.140 6379 # A new round of elections, start voting 1:X 01 Jul 2020 07:42:33.365 # +vote-for-leader 58a6c1ddde9afd2ed0e2881c59ce9349759e5d3a 14 1:X 01 Jul 2020 07:42:33.369 # c757c2a6d7e488bb4b421e6875c8032442efdb27 voted for 58a6c1ddde9afd2ed0e2881c59ce9349759e5d3a 14 1:X 01 Jul 2020 07:42:33.369 # 0fdb8118769d9d4ff83d4576ec327290fd00146c voted for 58a6c1ddde9afd2ed0e2881c59ce9349759e5d3a 14 1:X 01 Jul 2020 07:42:33.369 # 04386a502ecfe29d1769ea18eb3d6018b3c10159 voted for 58a6c1ddde9afd2ed0e2881c59ce9349759e5d3a 14 # After winning the election of the specified era, you can perform the failover operation 1:X 01 Jul 2020 07:42:33.466 # +elected-leader master mymaster 10.42.1.140 6379 # The failover operation is now in the select slave state -- Sentinel is looking for a slave server that can be upgraded to the master server 1:X 01 Jul 2020 07:42:33.466 # +failover-state-select-slave master mymaster 10.42.1.140 6379 # Successfully found the slave server suitable for upgrading, and selected 141 as the new master 1:X 01 Jul 2020 07:42:33.521 # +selected-slave slave 10.42.1.141:6379 10.42.1.141 6379 @ mymaster 10.42.1.140 6379 # After upgrading the specified slave server (141) to the master server, wait for the upgrade function to complete 1:X 01 Jul 2020 07:42:33.521 * +failover-state-send-slaveof-noone slave 10.42.1.141:6379 10.42.1.141 6379 @ mymaster 10.42.1.140 6379 1:X 01 Jul 2020 07:42:33.587 * +failover-state-wait-promotion slave 10.42.1.141:6379 10.42.1.141 6379 @ mymaster 10.42.1.140 6379 1:X 01 Jul 2020 07:42:34.105 # +promoted-slave slave 10.42.1.141:6379 10.42.1.141 6379 @ mymaster 10.42.1.140 6379 1:X 01 Jul 2020 07:42:34.105 # +failover-state-reconf-slaves master mymaster 10.42.1.140 6379 # Sentinel of the leader sends the SLAVEOF command to the instance to set a new master server for the instance 1:X 01 Jul 2020 07:42:34.161 * +slave-reconf-sent slave 10.42.0.236:6379 10.42.0.236 6379 @ mymaster 10.42.1.140 6379 1:X 01 Jul 2020 07:42:34.471 # -odown master mymaster 10.42.1.140 6379 # Modify replication destination from server 1:X 01 Jul 2020 07:42:35.107 * +slave-reconf-inprog slave 10.42.0.236:6379 10.42.0.236 6379 @ mymaster 10.42.1.140 6379 1:X 01 Jul 2020 07:42:35.107 * +slave-reconf-done slave 10.42.0.236:6379 10.42.0.236 6379 @ mymaster 10.42.1.140 6379 1:X 01 Jul 2020 07:42:35.173 * +slave-reconf-sent slave 10.42.2.75:6379 10.42.2.75 6379 @ mymaster 10.42.1.140 6379 1:X 01 Jul 2020 07:42:36.160 * +slave-reconf-inprog slave 10.42.2.75:6379 10.42.2.75 6379 @ mymaster 10.42.1.140 6379 1:X 01 Jul 2020 07:42:36.160 * +slave-reconf-done slave 10.42.2.75:6379 10.42.2.75 6379 @ mymaster 10.42.1.140 6379 1:X 01 Jul 2020 07:42:36.218 * +slave-reconf-sent slave 10.42.1.139:6379 10.42.1.139 6379 @ mymaster 10.42.1.140 6379 # End failover 1:X 01 Jul 2020 07:42:36.218 # +failover-end master mymaster 10.42.1.140 6379 # The IP and address have changed 1:X 01 Jul 2020 07:42:36.218 # +switch-master mymaster 10.42.1.140 6379 10.42.1.141 6379 # All slave nodes are reconfigured as slave nodes of the new master 1:X 01 Jul 2020 07:42:36.218 * +slave slave 10.42.0.236:6379 10.42.0.236 6379 @ mymaster 10.42.1.141 6379 1:X 01 Jul 2020 07:42:36.218 * +slave slave 10.42.2.75:6379 10.42.2.75 6379 @ mymaster 10.42.1.141 6379 1:X 01 Jul 2020 07:42:36.218 * +slave slave 10.42.1.139:6379 10.42.1.139 6379 @ mymaster 10.42.1.141 6379 1:X 01 Jul 2020 07:42:36.218 * +slave slave 10.42.1.140:6379 10.42.1.140 6379 @ mymaster 10.42.1.141 6379
Detailed explanation of epoch
- The sentinel performing the switch will get a configuration epoch from the new master (save - > Master) to which you want to switch, which is a version number. The version number must be unique for each switch.
- If the first elected sentry fails to switch, the other sentries will wait for the failover timeout time, and then continue to perform the switch. At this time, a new configuration will be obtained again
Common configuration of sentry
-
Sentinel down after milliseconds this configuration sets a sentinel to think that the host is unavailable if it still doesn't respond after a specified time. For other sentinels, this is not the case. The sentinel will record this message. When the number of sentinels who think they are offline reaches the configured number of sentinel monitor, a vote will be initiated to fail. At this time, the sentinel will rewrite the sentinel configuration file of Redis to meet the needs of the new scene.
-
Sentinel failover timeout mymaster if the sentinel fails to complete the failover operation within the configured value, the task fails this time.
-
Sentinel auth pass mymaster redispass if redis is configured with a password, authentication must be configured here, otherwise it cannot be switched automatically
-
Protected mode no unprotects the mode so that sentinels can monitor the master and slave
Introduction to sentry log
- +reset-master <instance details>: The master server has been reset. · +slave <instance details>: A new slave server has been Sentinel Identify and correlate. · +failover-state-reconf-slaves <instance details>: Failover state switched to reconf-slaves Status. · +failover-detected <instance details>: the other one Sentinel A failover operation is started, or a slave server is converted to the master server. · +slave-reconf-sent <instance details>: Lead( leader)of Sentinel Sent to instance SLAVEOF Command to set a new master server for the instance. · +slave-reconf-inprog <instance details>: The instance is setting itself as the slave server of the specified master server, but the corresponding synchronization process has not been completed. · +slave-reconf-done <instance details>: The slave server has successfully completed synchronization with the new master server. · -dup-sentinel <instance details>: One or more that monitor a given primary server Sentinel Has been removed for recurrence - when Sentinel This happens when the instance is restarted. · +sentinel <instance details>: A new server that monitors a given primary server Sentinel Has been identified and added. · +sdown <instance details>: The given instance is now in a subjective offline state. · -sdown <instance details>: The given instance is no longer in the subjective offline state. · +odown <instance details>: The given instance is now in an objective offline state. · -odown <instance details>: The given instance is no longer in the objective offline state. · +new-epoch <instance details>: The current era( epoch)Has been updated. · +try-failover <instance details>: A new failover operation is in progress and is waiting to be replaced by the majority Sentinel Select( waiting to be elected by the majority). · +elected-leader <instance details>: After winning the election of the specified era, you can perform the failover operation. · +failover-state-select-slave <instance details>: The failover operation is now in select-slave Status—— Sentinel Looking for a slave server that can be upgraded to the master server. · no-good-slave <instance details>: Sentinel The operation failed to find a suitable slave server for upgrade. Sentinel After a period of time, it will try again to find a suitable slave server to upgrade, or directly give up the failover operation. · selected-slave <instance details>: Sentinel Successfully find the slave server suitable for upgrading. · failover-state-send-slaveof-noone <instance details>: Sentinel Upgrading the specified slave server to master server, waiting for the upgrade function to complete. · failover-end-for-timeout <instance details>: Failover is aborted because of a timeout, but eventually all slave servers start replicating the new master server( slaves will eventually be configured to replicate with the new master anyway). · failover-end <instance details>: The failover operation completed successfully. All slave servers are replicating the new master server. · +switch-master <master name> <oldip> <oldport> <newip> <newport>: Configuration change, master server IP And address have changed. This is the information that most external users are concerned about. · +tilt: get into tilt pattern. . -tilt: sign out tilt pattern.