Article catalog
This is a study and Reflection on "Redis in depth adventure"
Remote dictionary service
install
The book provides three ways of docker, source code and direct installation. I've played the other two ways. Now I'll talk about source code installation
The book looks like version 2.8, but now it's version 6.0, so I execute slightly different orders from the book
The new features of 6.0 haven't been understood yet. It seems that multithreading and ACL have been added
# This instruction is different from that in the book git clone https://github.com/antirez/redis.git cd redis # The speed is very slow. I can only come back after eating. It seems that the source code installation is reasonable to be abandoned make # There is no make test step in the book. I followed the prompt to perform the next step after executing make, but I reported Error twice make test cd src ./redis-server --daemonize yes
Infrastructure
There are five kinds mentioned in the book, which should be the old version
string
Redis string is a dynamic string The implementation of the internal structure is similar to the Java ArrayList, which uses the method of pre allocation of redundant space to reduce the frequent allocation of memory
If so, it's not known whether Redis can set the value capacity in advance to further reduce redistribution
The maximum length of string is 512MB
These instructions are also applicable to other data structures
set
Quotation marks
[qbit@manjaro src]$ ./redis-cli 127.0.0.1:6379> set Qbit qqq OK 127.0.0.1:6379> get Qbit "qqq" 127.0.0.1:6379> set Qbit "qqq" OK 127.0.0.1:6379> get Qbit "qqq" 127.0.0.1:6379> set Qbit "qqq Invalid argument(s) 127.0.0.1:6379> set Qbit "thiis"whatisaid"1" Invalid argument(s) 127.0.0.1:6379> set "Qbit" m OK 127.0.0.1:6379> get Qbit "m" set Qb"it m Invalid argument(s)
It can be seen from the above example that if key and value are enclosed by double quotes, and there is no double quotes, it is an effect. If the double quotes do not match or other positions appear, it is illegal
Options
First come to the official website:
The SET command supports a set of options that modify its behavior:
- EX seconds – Set the specified expire time, in seconds.
- PX milliseconds – Set the specified expire time, in milliseconds.
- NX – Only set the key if it does not already exist.
- XX – Only set the key if it already exist.
- KEEPTTL – Retain the time to live associated with the key.
Note: Since the SET command options can replace SETNX, SETEX, PSETEX, it is possible that in future versions of Redis these three commands will be deprecated and finally removed.
According to the instructions on the official website, which setnx, setex and psetex should not be used later
lock
obtain
Generally, the lock is acquired first, and then the modification time is determined according to the result. Now these can be completed by one instruction without any transaction
set lock:Qbit true ex 5 nx
release
The above lock is only to ensure that the lock will be released automatically when the lock maker is hung, but the problem is that if the lock maker is not hung but executes for too long, the lock will be released, and then the lock will be acquired by the second thread, then the lock will be released by the first lock maker? If the first lock maker uses DEL, the result will be released. In order to solve this problem, We need to add a mark (random number) to the lock, so that we can only release our own lock, and at the same time, we can sense our timeout, so as to report an error. The scheme given in the book is as follows (lua)
tag =random.nextint() if redis.set(key,tag,nx=True,ex=5): do_something() redis.delifequals(key,tag)
# delifequals
if redis.call("get",KEYS[1])==ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
This problem is not considered in spring's solution. The solution of the old version of spring is attached here
local lockClientId = redis.call('GET', KEYS[1]) if lockClientId == ARGV[1] then redis.call('PEXPIRE', KEYS[1], ARGV[2]) return true elseif not lockClientId then redis.call('SET', KEYS[1], ARGV[1], 'PX', ARGV[2]) return true end return false
The lockClientId above is a uuid that needs to be noted down
The new version of spring adopts the syntax of set ex nx. The key code is as follows
RedisSerializer<String> serializer = RedisLockRegistry.this.redisTemplate.getStringSerializer(); byte[][] actualArgs = new byte[][] { serializer.serialize(constructLockKey()), RedisLockRegistry.this.lockSerializer.serialize(RedisLock.this), serializer.serialize("NX"), serializer.serialize("EX"), serializer.serialize(String.valueOf(expireAfter)) }; return connection.execute("SET", actualArgs) != null;
Notice that nx is in front of ex, and it's OK
exists
Official website description
To determine whether there is a key, you can connect n keys later, and then return the number of existing keys. For the most common case (version before 3.0), the following is an official example to help you understand
redis> SET key1 "Hello" "OK" redis> EXISTS key1 (integer) 1 redis> EXISTS nosuchkey (integer) 0 redis> SET key2 "World" "OK" redis> EXISTS key1 key2 nosuchkey (integer) 2
expire
This order may be a lot, but Official website There are still many operations mentioned above
System clock
According to the introduction of the official website, Redis follows the system time, so the change of the system time is equivalent to the passage of time. Therefore, the official website supports that when the Redis storage files are migrated, if the clocks of the two systems are inconsistent, some keys will fail. Similarly, if the system time is modified, the keys will fail. The following is the original explanation:
Even running instances will always check the computer clock, so for instance if you set a key with a time to live of 1000 seconds, and then set your computer time 2000 seconds in the future, the key will be expired immediately, instead of lasting for 1000 seconds.
Various key operations
According to the official documents, many operations (but not all) on the key will not change the expiration time, so it is not like the Session in Web development that can be automatically postponed. For specific instructions, I suggest you go to the official website when you use them
Expiration algorithm
Most people know that there are two strategies: passive and active. Passive ensures that overdue data will not be read, while active, in order to save space, provides a social proactive algorithm. The process is as follows
Specifically this is what Redis does 10 times per second:
- Test 20 random keys from the set of keys with an associated expire.
- Delete all the keys found expired.
- If more than 25% of keys were expired, start again from step 1.
It can be seen that this algorithm makes a balance between garbage collection consumption and memory usage, and makes a statistical assumption
colony
First of all, because both Master and Replica have expiration time, even if Replica does not wait for the Master's DEL instruction, it will not return the expired key. Second, this ensures that the new Master can continue to DEL the expired key after the Master hangs up
list
Redis's list is equivalent to LinkedList in Java language
quicklist
redis has made some internal optimizations. When there is less data stored, it tends to use ziplist. In addition, when the two will be combined, I will talk more about it later
rpush rpop lpop lpush
When xpush is used, you can connect multiple parameters, push them in turn, and generally use r first
lindex lrange ltrim llen
See what the name means. See the official website for details
blpop brpop
The book also introduces that list can also be used as a simple MQ,
It should be noted that consumers need to sleep when pop can't get poems, so as to reduce CPU consumption of themselves and Redis at the same time
A better solution is to use blpop brpop, where b means blocking, but there is still a pit here, even if the Redis server may break the link for a long time of idle
hash
There are many operations beginning with x corresponding to some operations of redis itself, such as hincrby corresponding to incr
set
zset
This is a set with sorting. The sorting rule is score. Correspondingly, there will be various operations starting with z, which are commonly used here
zrange zrevrange
Output in ascending and descending order respectively. Generally, 0-1 is followed to indicate output from the 0th to the last
zcard
Equivalent to count
Current limiting
sliding window
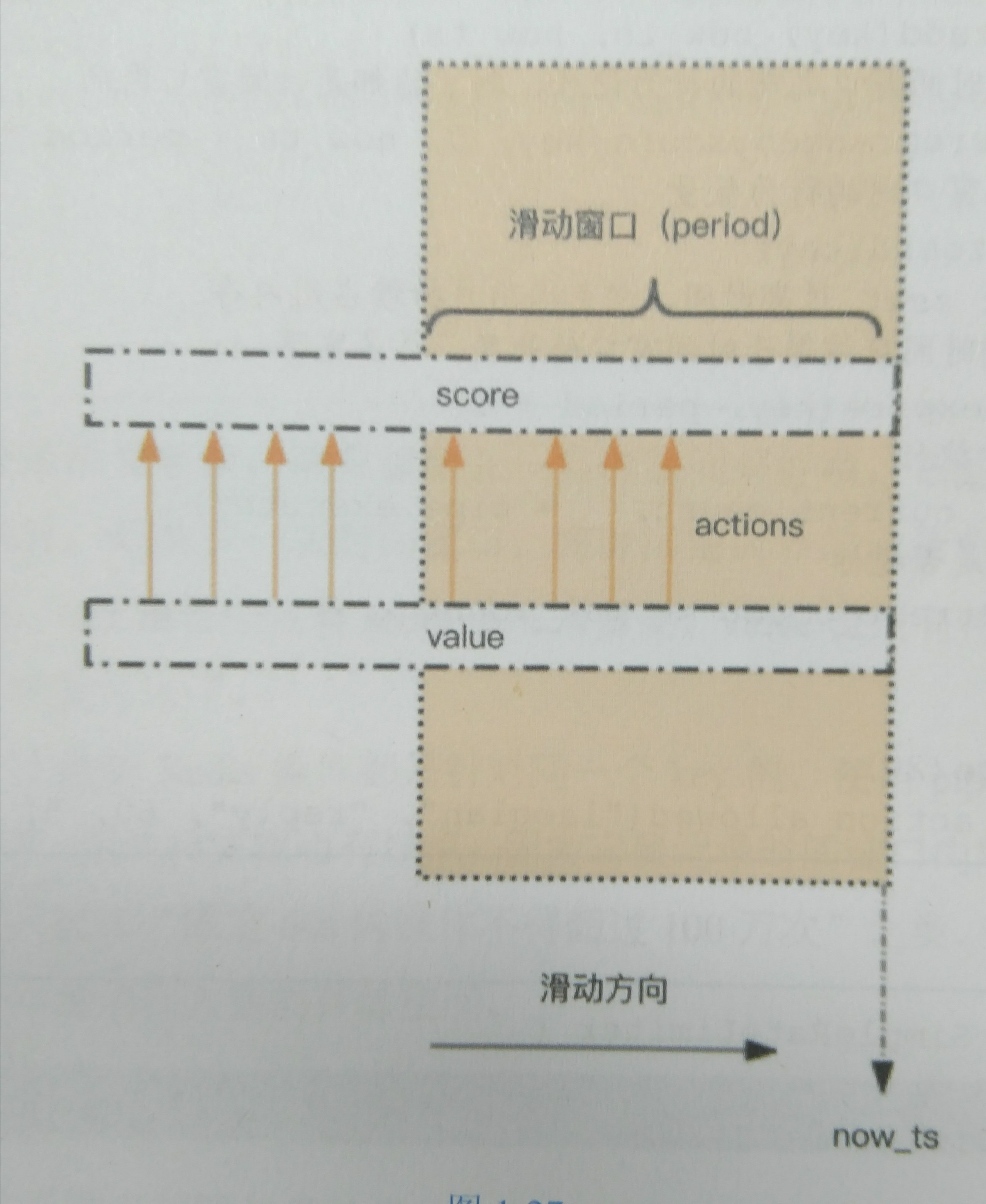
zset is used for current limiting. Current limiting is for specific operations. For example, the following code is for specific users_ Specific action of ID
import time import redis client=redis.StrictRedis() def is_allowed(user_id,action,period,max_count): #The key means to the user_ This action of ID is current limiting key='hist:%s:%s'%(user_id,action) now=int(time.time()*1000) with client.pipeline() as pipe: #Record this operation pipe.zadd(key,now,now) #Remove actions outside the window pipe.zremrangebyscore(key,0,now-period*1000) #Get the number of windows pipe.zcard(key) #Set expiration time to exclude cold data pipe.expire(key,period+1) #implement _,_,count,_=pipe.execute() return count<max_count
It can be seen that if continuous operation is carried out, even if the operation is not successful due to current limiting, it will also have a negative impact on the later operation
HyperLogLog
This data structure involves three instructions beginning with pf (pf means its inventor Philippe Flajolet): pfadd,pfcount,pfmerge In which, pfcount can follow multiple key s, which is equivalent to first merging them to get the number
Bloom Filter
When a value of the bloon filter exists, the value may not exist; when it says that a value does not exist, it certainly does not exist
I'm surprised that the instructions at the beginning of BF are not supported by the official native. I don't support them after using the source code installation. I'll continue to study them later bf.reserve To control errors_ Rate, you can write it down
In a nutshell, here is the diagram in the book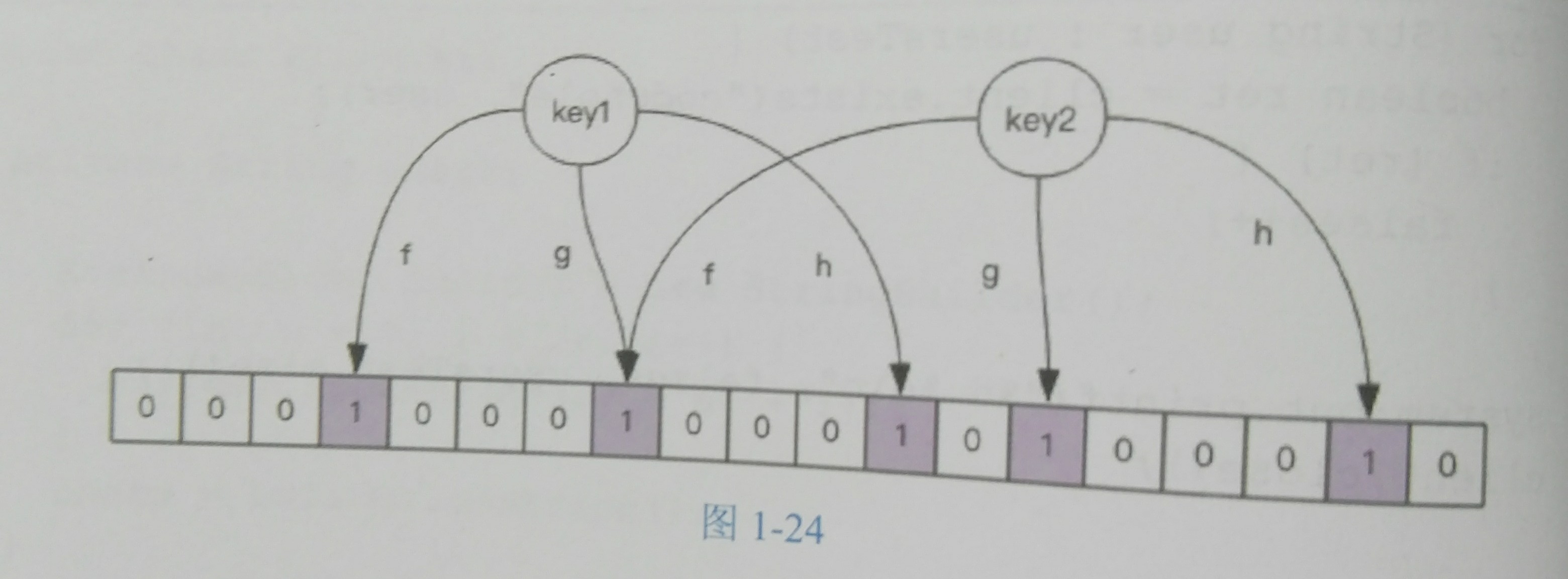
I will hash each key (f,g,h are used in the figure), and then set the position of the corresponding bitmap to 1. When I look up, I will see if the corresponding bitmap is 1. So the bitmap is large enough to avoid collision. In addition, the more hash functions, the more accurate
Here's a website Help calculation
GeoHash
There is no doubt that this involves some data at the beginning of geo. It should be mentioned that the zrem instruction of zset is used for deletion
Another problem is that for the key of geo, the value is often very large, and there will be a jam during migration in the cluster mode, so it is recommended to deploy separately
keys vs scan
scan provides the function of searching, but it doesn't block like keys and supports paging. However, there is a special feature here that the number of returned pieces is not accurate, especially if the return set is empty, it doesn't mean there is no subsequent data. Because its limit is actually the number of specified slot s rather than the number of records. In addition, it uses high-order addition (corresponding, Ordinary addition can be understood as low order addition), as shown in the figure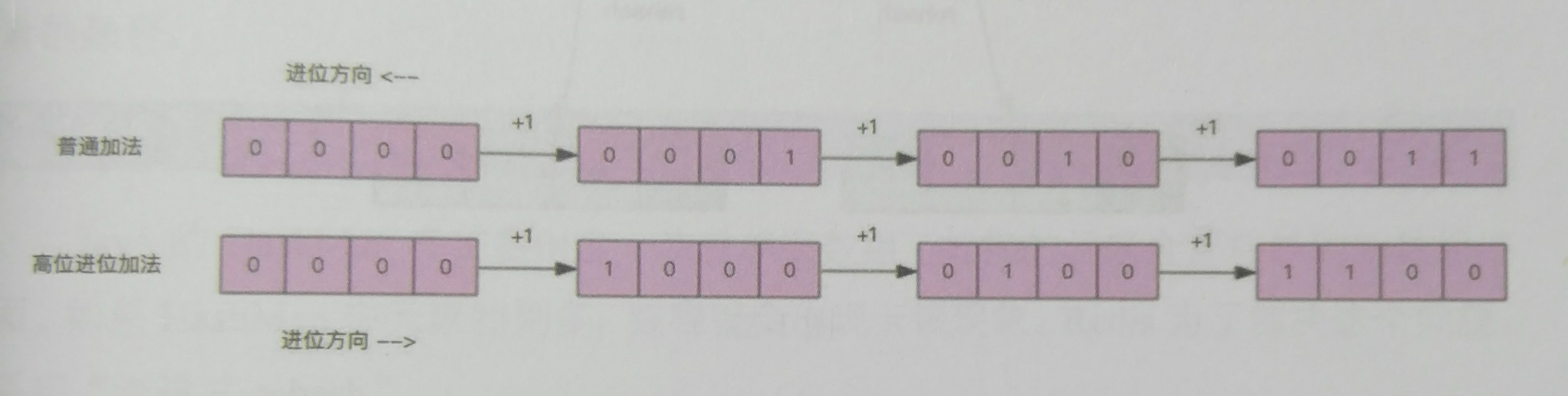
rehash
Because Redis adopts progressive rehash, it needs to go to the old and new slots to find
Search for big key
redis-cli -h 127.0.0.1 -p 6379 --bigkeys -i 0.1
The above i parameter refers to sleeping for 0.1s every scan100 to avoid ops surge triggering operation and maintenance monitoring alarm, which will be slower, so it can also be removed