Recently, I was preparing for an interview. When I asked about redis, I could only scratch the surface. What I said was neither in-depth nor comprehensive, so I paid close attention to the assault and learned redis design and implementation first.
The reasons for choosing to read are:
The book is comprehensive and in-depth, and it must be very attentive to publish the book;
Search blog can not find more comprehensive articles than books, and it takes time;
Looking at the source code directly, one is that you don't have a good grasp of C, and it's easy to be sleepy and inefficient. Therefore, learning the source code with books is the best choice I think now.
I: five common data types
Simple dynamic string
redis makes an SDS used as a string. Except for some scenes that do not need to be modified, it uses SDS
The underlying implementation of C string is always an array with a length of N+1 characters
sds.h:
struct sdshdr { // buf Length of occupied space in int len; // buf Length of free space remaining in int free; // Data space char buf[]; };
| 1 | C string | SDS |
| 2 | To find the length, you need to traverse O(n) | Take len directly to O(1) |
| 3 | It is easy to cause buffer overflow | |
| 4 |
Reduced memory reallocation times (the speed requirement is strict to avoid the time-consuming allocation of memory) |
|
| 5 | Binary security |
4: SDS has free, which can reserve more space than C string. There are two main space optimization strategies:
- Space pre allocation
- When SDS is modified, additional unused space will be obtained.
- Modified space n
- n<1M; Free allocation n + 1byte (null character)
- n>=1M; Free allocation 1M+1byte
- Inert space release
- When SDS is shortened, the deleted space is not released and added to free.
API of SDS
- sdsnew create
- sdsempty create an empty SDS
- sdsfree release
- sdslen get len
- sdsvail gets the number of free
- Sdup creates a copy of sds
- . .
Linked list
redis builds its own linked list:
/* * Double ended linked list node */ typedef struct listNode { // Front node struct listNode *prev; // Post node struct listNode *next; // Value of node void *value; } listNode;
/* * Double ended linked list iterator */ typedef struct listIter { // Node currently iterated to listNode *next; // Direction of iteration int direction; } listIter;
/* * Double ended linked list structure */ typedef struct list { // header node listNode *head; // Footer node listNode *tail; // Node value copy function void *(*dup)(void *ptr); // Node value release function void (*free)(void *ptr); // Node value comparison function int (*match)(void *ptr, void *key); // Number of nodes contained in the linked list unsigned long len; } list;
Dictionaries
Also known as: symbol table, associative array and mapping, which are used to save key value pairs;
/* * Dictionaries */ typedef struct dict { // Type specific function dictType *type; // Private data void *privdata; // Hashtable dictht ht[2]; // rehash Indexes // When rehash When not in progress, the value is -1 int rehashidx; /* rehashing not in progress if rehashidx == -1 */ // Number of security iterators currently running int iterators; /* number of iterators currently running */ } dict;
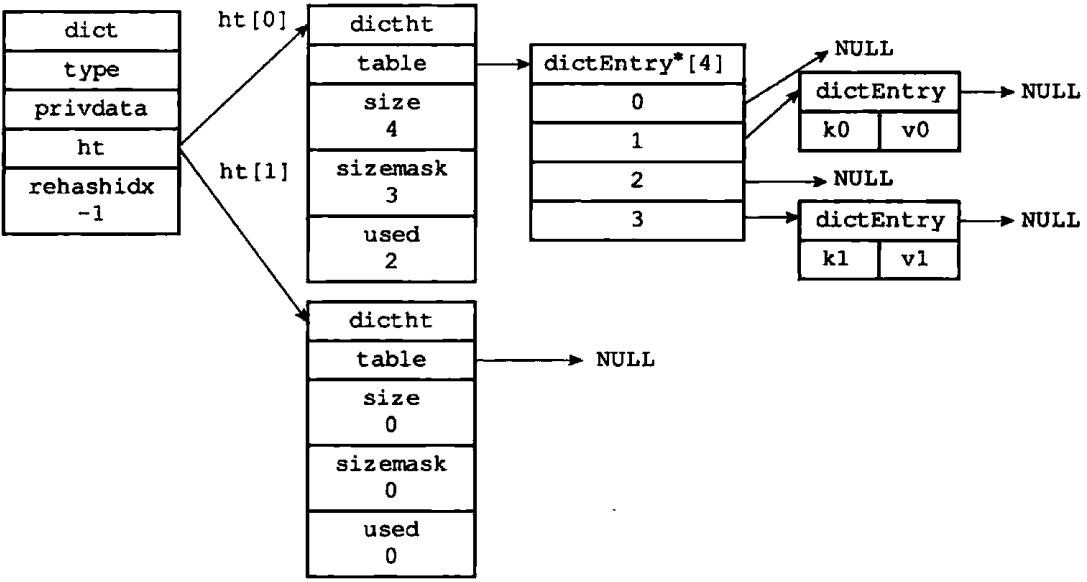
Understanding:
- Dictionary dict;
- Attribute type refers to dictType; dictType is a function that holds key value pairs of a specific type; redis will set different functions for different dictionaries.
- The property privateData is an optional parameter that stores the corresponding type.
- ht is a reference to dictht;
- Where table is a two-dimensional reference to dictEntry, with two levels.
- The first level is the value after the hash. When it reaches the threshold, it is necessary to rehash the expansion capacity
- dictEntry is a hash node
- Key is the key
- Value is a value
- There is also a reference next to the next node for chaining.
hash algorithm
conflict resolution
The hash table uses the chain address method to resolve key conflicts:
The pointers of the hash table node dictEntry form a chain, and the same hash is listed in the next of the current dictEntry
rehash
1. Allocate space for ht[1], compare with ht[0], and allocate space for capacity expansion
// The size of the new hash table is at least twice the number of nodes currently in use // T = O(N) return dictExpand(d, d->ht[0].used*2);
Shrink allocates a size equal to ht[0]?
/* * Reduce the given dictionary * Make the ratio between the number of used nodes and the size of the dictionary close to 1:1 * Return to DICT_ERR indicates that the dictionary is already in rehash or dict_can_resize is false. * When the smaller ht[1] is successfully created and can be resize d, it returns DICT_OK. */ int dictResize(dict *d) { int minimal; // Cannot close at rehash Or is rehash Called when if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR; // Calculate the minimum number of nodes required to make the ratio close to 1:1 minimal = d->ht[0].used; if (minimal < DICT_HT_INITIAL_SIZE) minimal = DICT_HT_INITIAL_SIZE; // Resize dictionary // T = O(N) return dictExpand(d, minimal); }
2. Copy ht[0] and re hash it to ht[1]
3. Release ht[0] and set ht[1] to ht[0].
Expansion and contraction of hash table
The hash table automatically adjusts the size of the table to the second power.
When there is no bgSave or bgRewriteAOF command, the load factor is greater than 1; Or when there are bgSave or bgRewriteAOF commands, the load factor is greater than 5; Time execution
Load factor = saved / hash table size
Progressive rehash
Jump table
skipList
todo
Integer set
Compression table
object
2: Single machine
principle
Method of saving key value pairs
Expiration Policies
Persistence mechanism
Other events, redis initialization process, etc
3: Distributed
Sentinel
copy
colony
4: Independent function
Publish and subscribe
affair
Lua script
sort
Slow query
1
1
1
1
1
1
1
1
1
1
1