1. What is a sentry
Sentry monitors the operation of Redis system. It is an independent process with two functions:
- Monitor whether the master database and slave database are running normally;
- After the master data fails, it will automatically convert the slave database to the master database;
2. Principle
Structure of a single sentry:
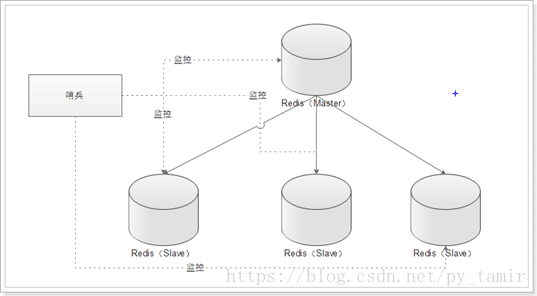
Architecture of multiple sentinels:
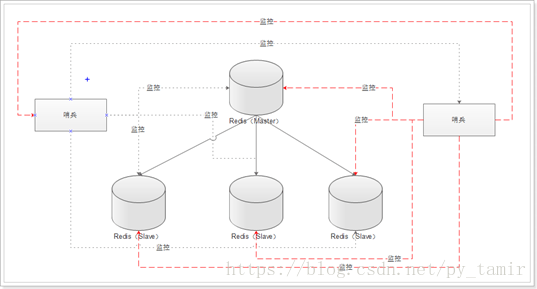
Multiple sentinels not only monitor the master-slave database at the same time, but also monitor each other.
Multiple sentinels to prevent single point of failure of sentinels.
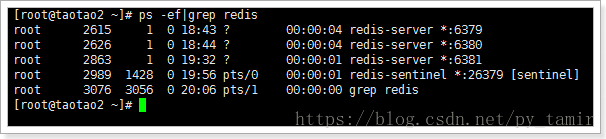
3. Environment
Currently in a master-slave environment:
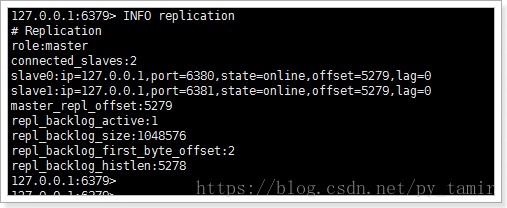
4. Set up sentry
To start the sentinel process, you first need to create a sentinel configuration file:
vim sentinel.conf
Input:
sentinel monitor taotaoMaster 127.0.0.1 6379 1
explain:
- taotaoMaster: the name of the monitoring master data. It can be customized. You can use uppercase and lowercase letters and ". -" Symbol
- 127.0.0.1: IP address of the monitored primary database
- 6379: port of the monitored primary database
- 1: Minimum number of votes
- (java project from fhadmin.cn)
Start sentinel process:
redis-sentinel ./sentinel.conf
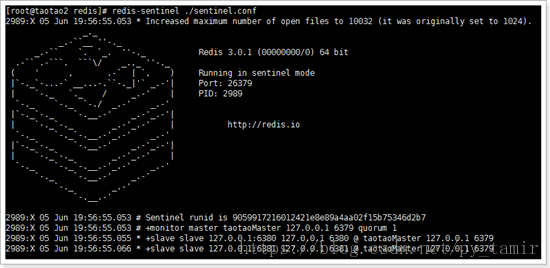
As can be seen from the above figure:
- Sentinel has been activated with id 9059917216012421e8e89a4aa02f15b75346d2b7
- Added a monitor for the master database
- Two slaves are found (it can be seen that the sentinel does not need to configure slaves, but only needs to specify the master, and the sentinel will automatically find slaves)
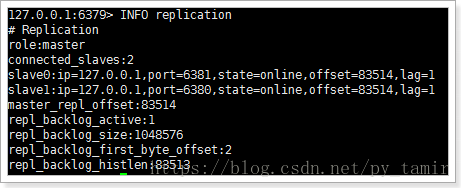
5. Recovery from downtime
After kill ing 2826 process, the sentry's console output after 30 seconds:
2989:X 05 Jun 20:09:33.509 # +sdown slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 6379
This indicates that the slave has been monitored for downtime. If we start the redis instance on port 3380, will it automatically join the master-slave replication?
2989:X 05 Jun 20:13:22.716 * +reboot slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 6379 2989:X 05 Jun 20:13:22.788 # -sdown slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 6379
It can be seen that slave is newly added to master-slave replication- sdown: the description is to restore the service.
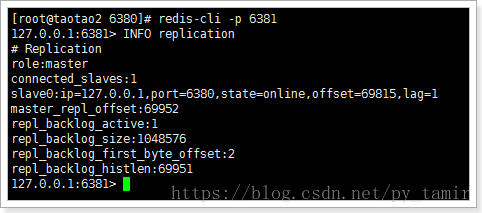
6. Primary downtime and recovery
The sentry console prints the following information:
2989:X 05 Jun 20:16:50.300 # +sdown master taotaoMaster 127.0.0.1 6379 indicates that the master service has been down 2989:X 05 Jun 20:16:50.300 # +odown master taotaoMaster 127.0.0.1 6379 #quorum 1/1 2989:X 05 Jun 20:16:50.300 # +new-epoch 1 2989:X 05 Jun 20:16:50.300 # +Try failover master taotaomaster 127.0.0.1 6379 start recovery failure 2989:X 05 Jun 20:16:50.304 # +Vote for leader 9059917216012421e8e89a4aa02f15b75346d2b7 1 vote for a sentinel leader. There is only one sentinel now, so the leader is on his own 2989:X 05 Jun 20:16:50.304 # +Selected leader master taotaomaster 127.0.0.1 6379 select leader 2989:X 05 Jun 20:16:50.304 # +Failover state select slave master taotaotmaster 127.0.0.1 6379 select one of the slave as the master 2989:X 05 Jun 20:16:50.357 # +Selected slave 127.0.0.1: 6381 127.0.0.1 6381 @ taotaomaster 127.0.0.1 6379 6381 2989:X 05 Jun 20:16:50.357 * +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ taotaoMaster 127.0.0.1 6379 send out slaveof no one command 2989:X 05 Jun 20:16:50.420 * +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ taotaoMaster 127.0.0.1 6379 Waiting for upgrade master 2989:X 05 Jun 20:16:50.515 # +Promoted slave 127.0.0.1: 6381 127.0.0.1 6381 @ taotaomaster 127.0.0.1 6379 upgrade 6381 to master 2989:X 05 Jun 20:16:50.515 # +failover-state-reconf-slaves master taotaoMaster 127.0.0.1 6379 2989:X 05 Jun 20:16:50.566 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 6379 2989:X 05 Jun 20:16:51.333 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 6379 2989:X 05 Jun 20:16:52.382 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 6379 2989:X 05 Jun 20:16:52.438 # +Failover end master taotaomaster 127.0.0.1 6379 fault recovery completed 2989:X 05 Jun 20:16:52.438 # +Switch master taotaomaster 127.0.0.1 6379 127.0.0.1 6381 main database changed from 6379 to 6381 2989:X 05 Jun 20:16:52.438 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 6381 Add a slave library with 6380 as 6381 2989:X 05 Jun 20:16:52.438 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ taotaoMaster 127.0.0.1 6381 Add a slave library with 6379 as 6381 2989:X 05 Jun 20:17:22.463 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ taotaoMaster 127.0.0.1 6381 found that 6379 had been down, waiting for 6379 to recover
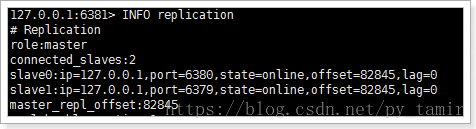
It can be seen that at present, 6381 master has a slave of 6380
Next, we restore 6379 view status:
2989:X 05 Jun 20:35:32.172 # -Sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ taotaomaster 127.0.0.1 6381 6379 has resumed service 2989:X 05 Jun 20:35:42.137 * +convert-to-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ taotaoMaster 127.0.0.1 6381 Set 6379 to 6381 slave
7. Configure multiple Sentinels
vim sentinel.conf
Input:
sentinel monitor taotaoMaster1 127.0.0.1 6381 1 sentinel monitor taotaoMaster2 127.0.0.1 6381 2
