Introduction to redis configuration file
Configuration programming in linux Environment
The Redis configuration file is located in the Redis installation directory. The file name is redis.conf. Generally, a separate copy will be made for operation. To ensure the security of the initial file
config get * # Get all configurations
include section
Combine multiple configurations. Similar to Spring configuration files, redis.conf can be included through includes as the general file, and other configuration files can be included!
network part
Network related configuration
bind 127.0.0.1 # Bound ip protected-mode yes # Protection mode port 6379 # Default port
General section
| Serial number | Configuration item | explain |
|---|---|---|
| 1 | daemonize no | Redis does not run as a daemon by default, and can be modified through this configuration item, Use yes to enable daemons (Windows does not support daemons. The configuration of daemons is no) |
| 2 | tcp-backlog | Set the tcp backlog, which is actually a connection queue one by one, Total backlog queue = queue with three incomplete handshakes + queue with three completed handshakes. Note that the Linux kernel reduces this value to the value of / proc/sys/ net/ core/somaxconn, Therefore, you need to confirm that somaxconn and TCP are increased_ max_ Syn backlog two values |
| 5 | timeout 300 | When the client is idle for several seconds, close the connection. If 0 is specified, it means that the function is closed |
| 6 | Tcp-keepalive 0 | Detect whether the connection is interrupted. Setting to 0 means that the service is disabled |
| 7 | loglevel notice | Redis supports four log levels: debug, verbose, notice and warning, The level increases gradually, and the printed information decreases with the level. The default is notice |
| 8 | syslog-enabled no | Whether to print logs to syslog. The default value is no |
| 9 | syslog-ident redis | Specifies the log flag in syslog |
| 10 | databases 16 | Set the number of databases. The default database is 0. You can use the SELECT command to connect to the specified database id |
| 11 | logfile "" | The location of the log file, when specified as an empty string, is standard output |
Snapshooting section
Snapshots, persistence rules
AOF
# At least one key value changes within 900 seconds (15 minutes) (database saving - persistence) save 900 1 # At least 10 key values change within 300 seconds (5 minutes) (database saving - persistence) save 300 10 # At least 10000 key values change within 60 seconds (1 minute) (database saving - persistence) save 60 10000
RGB
stop-writes-on-bgsave-error yes # Do you want to continue working after persistence errors rdbcompression yes # Use compressed rdb files yes: compressed, but requires some cpu consumption. No: no compression, more disk space is required rdbchecksum yes # Whether to verify rdb files is more conducive to file fault tolerance, but there will be about 10% performance loss when saving rdb files dbfilename dump.rdb # dbfilenamerdb file name dir ./ # dir data directory, where the database will be written. rdb and aof files will also be written in this directory
REPLICATION master-slave REPLICATION
Detailed description of subsequent master-slave replication
SECURITY section
# Start redis # Connect client # Get and set password config get requirepass config set requirepass "123456" #Leave password blank: config set requirepass '' #Test ping and find that verification is required 127.0.0.1:6379> ping NOAUTH Authentication required. # Authentication: auth password 127.0.0.1:6379> auth 123456 OK 127.0.0.1:6379> ping PONG
Client connection related
maxclients 10000 Maximum number of clients maxmemory <bytes> Maximum memory limit maxmemory-policy noeviction # Processing strategy for memory reaching limit
Six ways of maxmemory policy
-
Volatile LRU: LRU algorithm is used to remove the key s with expired time.
-
Allkeys lru: delete lkey using lru algorithm
-
Volatile random: randomly delete key s that are about to expire
-
Allkeys random: random deletion
-
Volatile TTL: delete expired
-
noeviction: no key is removed, but a write error is returned.
The default expiration policy in redis is volatile LRU.
Setting mode
config set maxmemory-policy volatile-lru
append only mode section
Relevant parts of AOF
appendonly no #By default, AOF mode is not enabled, but RGB mode is used for persistence. In most cases, RGB is fully sufficient
appendfilename "appendonly.aof" #Persistent file name
appendfsync everysec # appendfsync aof persistence policy configuration
# no means that fsync is not executed. The operating system ensures that the data is synchronized to the disk, and the speed is the fastest.
# always means that fsync is executed for each write to ensure data synchronization to disk.
# everysec means that fsync is executed every second, which may cause the loss of this 1s data.
LIMITS section
- Maxclients: set the maximum number of client connections at the same time. It is unlimited by default. The number of client connections that Redis can open at the same time is the maximum number of file descriptors that Redis process can open. If maxclients 0 is set, it means there is no limit. When the number of client connections reaches the limit, Redis will close the new connection and return the max number of clients reached error message to the client
- Maxmemory policy data clearing policy
- Volatile LRU: LRU (least recently used) algorithm is adopted for the data with expiration time set. If the expiration time is specified by using the "expire" instruction for the key, the key will be added to the "expiration set". Priority will be given to removing expired / LRU data. If all the data removed from the "expired collection" still cannot meet the memory requirements, OOM will be deleted.
- Allkeys LRU: LRU algorithm is adopted for all data
- Volatile random: the "random selection" algorithm is adopted for the data with expiration time set, and the selected K-V is removed until "enough memory". If you still cannot meet the requirement of removing all from the expired collection, OOM will be deleted
- Allkeys random: for all data, adopt the "random selection" algorithm and remove the selected K-V until "enough memory"
- Volatile TTL: TTL algorithm (minimum survival time) is adopted for the data with expiration time set to remove the data about to expire.
- noeviction: return the OOM exception directly without any interference. This is also the default option. This option is not used in actual development
- #Maxmemory samples 3: the above LRU and minimum TTL strategies are not rigorous strategies, but approximate estimation methods. Therefore, the sampling value can be selected for inspection. The default value is 3
redis persistence
Portal: redis -- persistence
redis subscription publication
brief introduction
Redis publish / subscribe (pub/sub) is a message communication mode: the sender (pub) sends messages and the subscriber (sub) receives messages.
Redis client can subscribe to any number of channels.
Subscribe / publish message diagram:
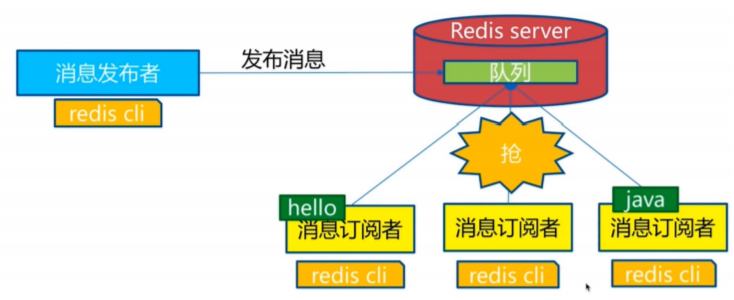
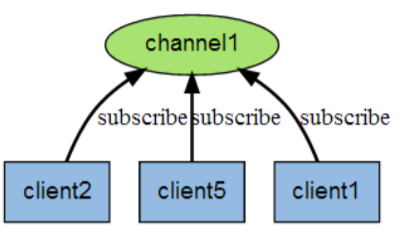
The following figure shows the relationship between channel 1 and the three clients subscribing to this channel - client2, client5 and client1:
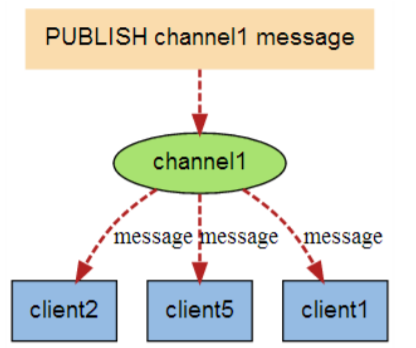
When a new message is sent to channel 1 through the PUBLISH command, the message will be sent to the three clients subscribing to it:
command
The following table lists common redis publish / subscribe commands:
| Serial number | Command and description |
|---|---|
| 1 | PSUBSCRIBE pattern [pattern ...] Subscribe to one or more channels that match the given pattern. |
| 2 | PUBSUB subcommand [argument [argument ...]] View subscription and publishing system status. |
| 3 | PUBLISH channel message Sends information to the specified channel. |
| 4 | PUNSUBSCRIBE [pattern [pattern ...]] Unsubscribe from all channels in a given mode. |
| 5 | SUBSCRIBE channel [channel ...]] Subscribe to information for a given channel or channels. |
| 6 | UNSUBSCRIBE [channel [channel ...]] Unsubscribe from a given channel. |
test
Let's open two redis cli clients first
In the first redis cli client as the subscription client, create a subscription channel named redisChat, and enter SUBSCRIBE redisChat
redis 127.0.0.1:6379> SUBSCRIBE redisChat Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "redisChat" 3) (integer) 1
Open the second client as the sender, publish the message twice on the specified channel, and the subscriber can receive the message.
redis 127.0.0.1:6379> PUBLISH redisChat "Hello,Redis" (integer) 1 redis 127.0.0.1:6379> PUBLISH redisChat "Hello,java" (integer) 1
The subscriber's client displays the following message
1. "message" 2. "redisChat" 3. "Hello,Redis" 1. "message" 2. "redisChat" 3. "Hello,java"
summary
Redis is implemented in C. by analyzing the pubsub.c file in redis source code, we can understand the underlying implementation of publish and subscribe mechanism to deepen our understanding of redis.
Redis implements PUBLISH and SUBSCRIBE functions through PUBLISH, SUBSCRIBE, PSUBSCRIBE and other commands.
After subscribing to a channel through the SUBSCRIBE command, a dictionary is maintained in the redis server. The keys of the dictionary are channels, and the values of the dictionary are a linked list, which stores all clients subscribing to the channel. The key of the SUBSCRIBE command is to add the client to the subscription linked list of a given channel.
Send a message to subscribers through the PUBLISH command. Redis server will use the given channel as the key, find the linked list of all clients subscribing to the channel in the channel dictionary maintained by redis server, traverse the linked list, and PUBLISH the message to all subscribers.
Pub/Sub literally means Publish and Subscribe. In Redis, you can set a key value for message publishing and message subscription. When a key value is published, all clients subscribing to it will receive corresponding messages. The most obvious use of this function is as a real-time messaging system, such as ordinary instant chat, group chat and other functions.
Usage scenario: Redis's Pub/Sub system can build a real-time messaging system, such as many examples of real-time chat systems built with Pub/Sub
Cluster environment construction
Redis supports three cluster schemes
- Master slave replication mode
- Sentinel mode
- Cluster mode
Master slave replication
Portal: Master slave replication to an blog Park of redis cluster (cnblogs.com)
Sentinel mode
Solve what problem
Before Sentinel mode, the method of master-slave switching is to manually switch a slave server to the master server after the master server goes down, which requires manual intervention, labor-intensive and unavailability of services for a period of time. This is not a recommended way. More often, we give priority to Sentinel mode. Redis has officially provided Sentinel architecture since 2.8 to solve this problem.
The automatic version of Mou Chao's usurpation can monitor whether the host fails in the background. If it fails, it will automatically convert from the library to the main library according to the number of votes.
Sentinel mode is a special mode. Firstly, Redis provides sentinel commands. Sentinel is an independent process. As a process, it will run independently. The principle is that the sentinel sends a command and waits for the response of the Redis server, so as to monitor multiple running Redis instances.
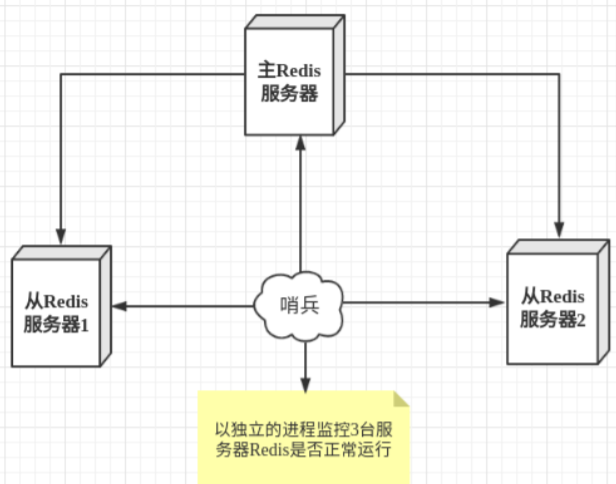
The sentry here has two functions
- Send a command to let Redis server return to monitor its running status, including master server and slave server.
- When the sentinel detects that the master is down, it will automatically switch the slave to the master, and then notify other slave servers through publish subscribe mode to modify the configuration file and let them switch hosts.
However, there may be problems when a sentinel process monitors the Redis server. Therefore, we can use multiple sentinels for monitoring. Each sentinel will also be monitored, which forms a multi sentinel mode.
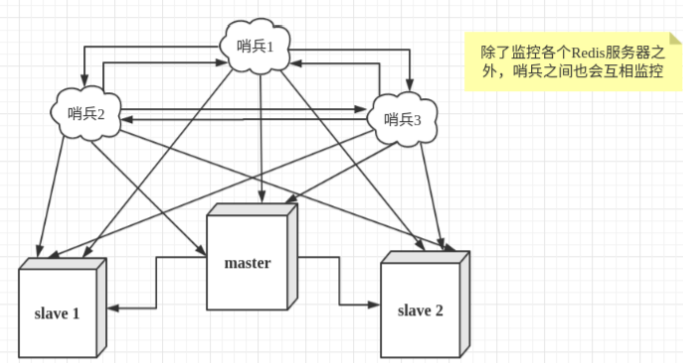
Assuming that the main server goes down, sentry 1 detects this result first, and the system will not fail immediately. Sentry 1 subjectively thinks that the main server is unavailable, which becomes a subjective offline phenomenon. When the following sentinels also detect that the primary server is unavailable and the number reaches a certain value, a vote will be held between sentinels. The voting result is initiated by one sentinel to perform the "failover" operation. After the switch is successful, each sentinel will switch its monitored slave server to the host through the publish and subscribe mode. This process is called objective offline.
Related configuration
Mode configuration file sentinel.conf
# Example sentinel.conf # The port on which the sentinel sentinel instance runs is 26379 by default port 26379 # Sentry sentinel's working directory dir /tmp # ip port of the redis master node monitored by sentinel # The master name can be named by itself. The name of the master node can only be composed of letters A-z, numbers 0-9 and the three characters ". - _. # Quorumwhen the sentinel of these quorum s thinks that the master master node is lost, it objectively thinks that the master node is lost # sentinel monitor <master-name> <ip> <redis-port> <quorum> sentinel monitor mymaster 127.0.0.1 6379 1 # When the requirepass foobared authorization password is enabled in the Redis instance, all clients connecting to the Redis instance must provide the password # Set the password of sentinel sentinel connecting master and slave. Note that the same authentication password must be set for master and slave # sentinel auth-pass <master-name> <password> sentinel auth-pass mymaster MySUPER--secret-0123passw0rd # After the specified number of milliseconds, the primary node does not respond to the sentinel sentinel. At this time, the sentinel subjectively thinks that the primary node goes offline for 30 seconds by default # sentinel down-after-milliseconds <master-name> <milliseconds> sentinel down-after-milliseconds mymaster 30000 # This configuration item specifies the maximum number of slave s that can synchronize the new master at the same time when a failover active / standby switch occurs, The smaller the number, the better failover The longer it takes, But if this number is larger, it means more slave because replication Not available. You can ensure that there is only one at a time by setting this value to 1 slave Is in a state where the command request cannot be processed. # sentinel parallel-syncs <master-name> <numslaves> sentinel parallel-syncs mymaster 1 # Failover timeout can be used in the following aspects: #1. The interval between two failover of the same sentinel to the same master. #2. When a slave synchronizes data from an incorrect master, the time is calculated. Until the slave is corrected to synchronize data to the correct master. #3. The time required to cancel an ongoing failover. #4. During failover, configure the maximum time required for all slaves to point to the new master. However, even after this timeout, the slave will still be correctly configured to point to the master, but it will not follow the rules configured by parallel syncs # The default is three minutes # sentinel failover-timeout <master-name> <milliseconds> sentinel failover-timeout mymaster 180000 # SCRIPTS EXECUTION #Configure the script to be executed when an event occurs. You can notify the administrator through the script. For example, send an email to notify relevant personnel when the system is not running normally. #There are the following rules for the running results of scripts: #If the script returns 1 after execution, the script will be executed again later. The number of repetitions is currently 10 by default #If the script returns 2 after execution, or a return value higher than 2, the script will not be executed repeatedly. #If the script is terminated due to receiving a system interrupt signal during execution, the behavior is the same as when the return value is 1. #The maximum execution time of a script is 60s. If this time is exceeded, the script will be terminated by a SIGKILL signal and then re executed. #Notification script: this script will be called when any warning level event occurs in sentinel (such as subjective failure and objective failure of redis instance), #At this time, the script should notify the system administrator about the abnormal operation of the system through e-mail, SMS, etc. When the script is called, two parameters will be passed to the script, #One is the type of event, #One is the description of the event. #If the script path is configured in the sentinel.conf configuration file, you must ensure that the script exists in this path and is executable, otherwise sentinel cannot start successfully. #Notification script # sentinel notification-script <master-name> <script-path> sentinel notification-script mymaster /var/redis/notify.sh # Client reconfiguration master node parameter script # When a master changes due to failover, this script will be called to notify the relevant clients of the change of the master address. # The following parameters will be passed to the script when calling the script: # <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port> # At present, < state > is always "failover", # < role > is one of "leader" or "observer". # The parameters from IP, from port, to IP and to port are used to communicate with the old master and the new master (i.e. the old slave) # This script should be generic and can be called multiple times, not targeted. # sentinel client-reconfig-script <master-name> <script-path> sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
Actual test
1 - adjust the structure, 6379 with 80, 81
2 - create a sentinel.conf file in the redis.conf directory with a fixed file name
3 - configure sentry and fill in the content
#sentinel monitor monitored host name 127.0.0.1 6379 n For example: sentinel monitor mymaster 127.0.0.1 6379 1,
The last number n above indicates the number of votes obtained. After the host hangs up, the slave will vote to succeed as the host, and the slave who obtains the number of votes to n will succeed as the host
4 - start sentry
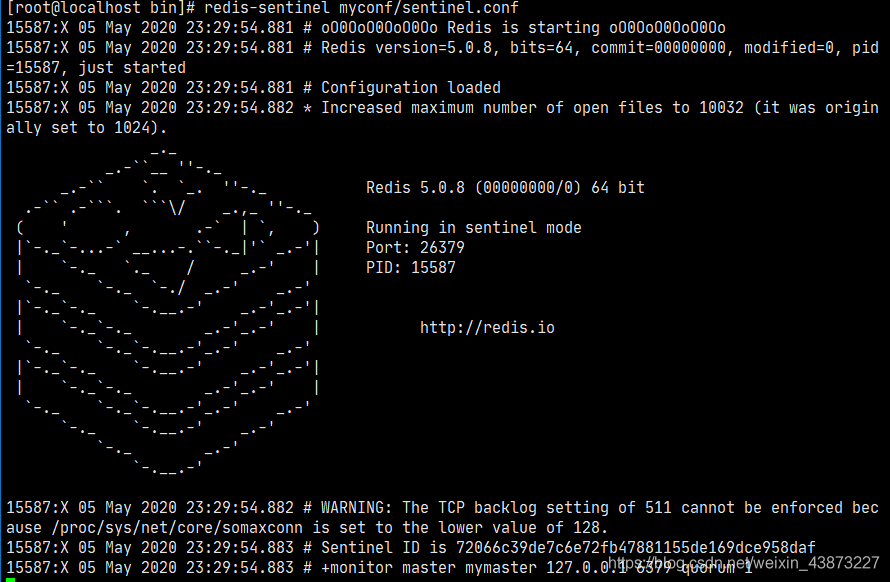
Redis-sentinel myconfig/sentinel.conf
The above directories are configured according to their actual conditions, which may be different
Sentry mode started successfully
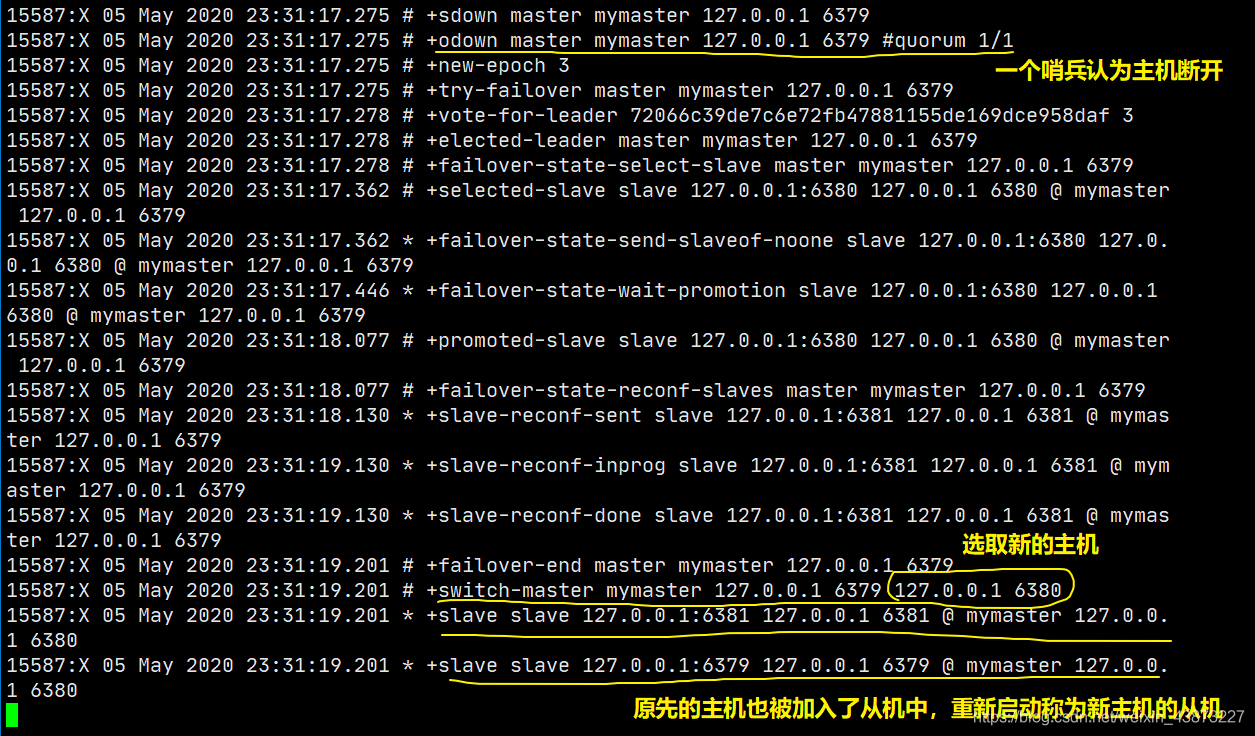
At this time, the sentry is monitoring our host 6379. When we disconnect the host:
Advantages and disadvantages of sentinel mode
advantage
- Sentinel cluster is based on master-slave replication mode. It has all the advantages of master-slave replication
- The master and slave can be switched, the fault can be transferred, and the system availability is better
- Sentinel mode is the upgrade of master-slave mode. It is more robust from manual to automatic
Disadvantages:
- Redis is not easy to expand online. Once the cluster capacity reaches the upper limit, online expansion will be very troublesome
- The configuration of sentinel mode is actually very troublesome. There are many configuration items
cluster mode
Cache penetration and avalanche
Cache penetration (not found)
By default, when users request data, they will first find it in the redis. If it is not found, the cache misses, and then find it in the database. A small number may not be a problem. However, once a large number of requested data (such as seckill scenario) fail to hit in the cache, they will all be transferred to the database, causing great pressure on the database, May cause the database to crash. In network security, some people maliciously use this means to attack, which is called flood attack.
Solution
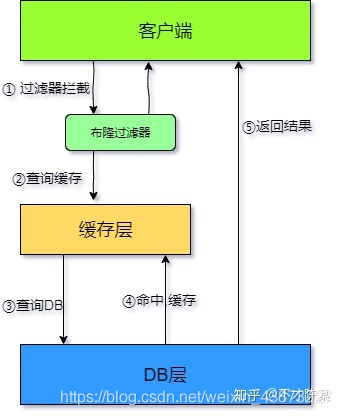
Bloom filter
All possible query parameters are stored in the form of Hash in order to quickly determine whether this value exists. Interception verification is carried out at the control layer first. The verification is not returned directly, which reduces the pressure on the storage system.
Cache empty objects
If a request is not found in the cache or database, an empty object will be used in the cache to process the subsequent request.
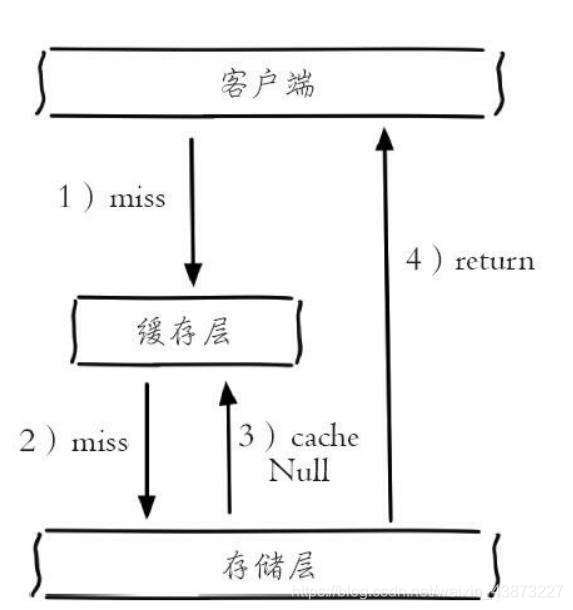
There is a drawback to this: storing empty objects also requires space. A large number of empty objects will consume a certain space, and the storage efficiency is not high. The solution to this defect is to set a shorter expiration time. Even if the expiration time is set for a null value, there will still be inconsistency between the data of the cache layer and the storage layer for a period of time, which will have an impact on the business that needs to maintain consistency
Cache breakdown (too large, cache expired)
Compared with cache penetration, cache breakdown is more purposeful. When the original key in the cache expires, there are a large number of requests at the same time. These requests will break down to the database, resulting in a large number of instantaneous DB requests and a sudden increase in pressure. This means that the cache is broken down. It is only because the cache of one key is unavailable, but other keys can still use the cache response.
For example, on the hot search ranking, a hot news is accessed in large numbers at the same time, which may lead to cache breakdown.
Solution
-
Set hotspot data never to expire
In this way, the hot data will not expire, but when the Redis memory space is full, some data will be cleaned up, and this scheme will occupy space. Once there are more hot data, some space will be occupied.
-
Add mutex lock (distributed lock)
Before accessing the key, SETNX (set if not exists) is used to set another short-term key to lock the access of the current key. After the access is completed, the short-term key is deleted. Ensure that only one thread can access at the same time. In this way, the requirements for locks are very high.
Cache avalanche
A large number of key s set the same expiration time, resulting in all cache failures at the same time, resulting in large instantaneous DB requests, sudden pressure increase and avalanche.
For example, it will be double eleven o'clock soon, and there will be a wave of rush buying soon. This wave of goods will be put into the cache in a concentrated time. Suppose the cache is for an hour. Then at one o'clock in the morning, the cache of these goods will expire. The access and query of these commodities fall on the database, which will produce periodic pressure peaks. Therefore, all requests will reach the storage layer, and the call volume of the storage layer will increase sharply, resulting in the storage layer hanging up.
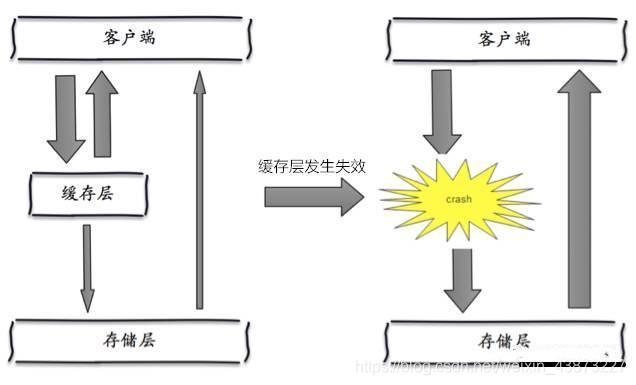
In fact, centralized expiration is not very fatal. The more fatal cache avalanche is the downtime or disconnection of a node of the cache server. Because of the naturally formed cache avalanche, the cache must be created centrally in a certain period of time. At this time, the database can withstand the pressure. It is nothing more than periodic pressure on the database. The downtime of the cache service node will cause unpredictable pressure on the database server, which is likely to crush the database in an instant.
Solution
-
redis high availability
The meaning of this idea is that since redis may hang up, I will add several more redis. After one is hung up, others can continue to work. In fact, it is a cluster
-
Current limiting degradation
The idea of this solution is to control the number of threads reading and writing to the database cache by locking or queuing after the cache expires. For example, for a key, only one thread is allowed to query data and write cache, while other threads wait.
-
Data preheating
The meaning of data heating is that before the formal deployment, I first access the possible data in advance, so that some data that may be accessed in large quantities will be loaded into the cache. Before a large concurrent access is about to occur, manually trigger the loading of different cache key s and set different expiration times to make the time point of cache invalidation as uniform as possible.