Steps for setting up redis master-slave architecture and configuring slave nodes:
1. Make a copy redis.conf file 2. Modify the relevant configuration to the following values: port 6380 pidfile /var/run/redis_6380.pid # Write the pid process number to the pidfile configuration file logfile "6380.log" dir /usr/local/redis‐5.0.3/data/6380 # Specify data storage directory # bind needs to be commented out # bind 127.0.0.1 (bind is bound to the ip of the network card of the machine. If multiple network cards can be configured with multiple ip, it represents which network card ip of the machine the client is allowed to access. Bind can not be configured in the intranet. Just comment it out.) 3. Configure master-slave replication replicaof 192.168.159.140 6379 # Copy data from the redis instance of the local 6379. Before Redis 5.0, slaveof was used replica‐read‐only yes # Configure slave node read only 4. Start slave node redis‐server redis.conf 5. Connect slave node redis-cli -p 6380 6. Test whether data is written on the 6379 instance and whether the 6380 instance can synchronize the newly modified data in time 7. You can configure a 6381 slave node yourself
Download address of relevant configuration files: Click here to download
Effect of master-slave architecture configuration:

Redis master-slave working principle
If you configure a slave for the master, whether the slave is connected to the master for the first time or not, it will send a PSYNC command to the master to request data replication.
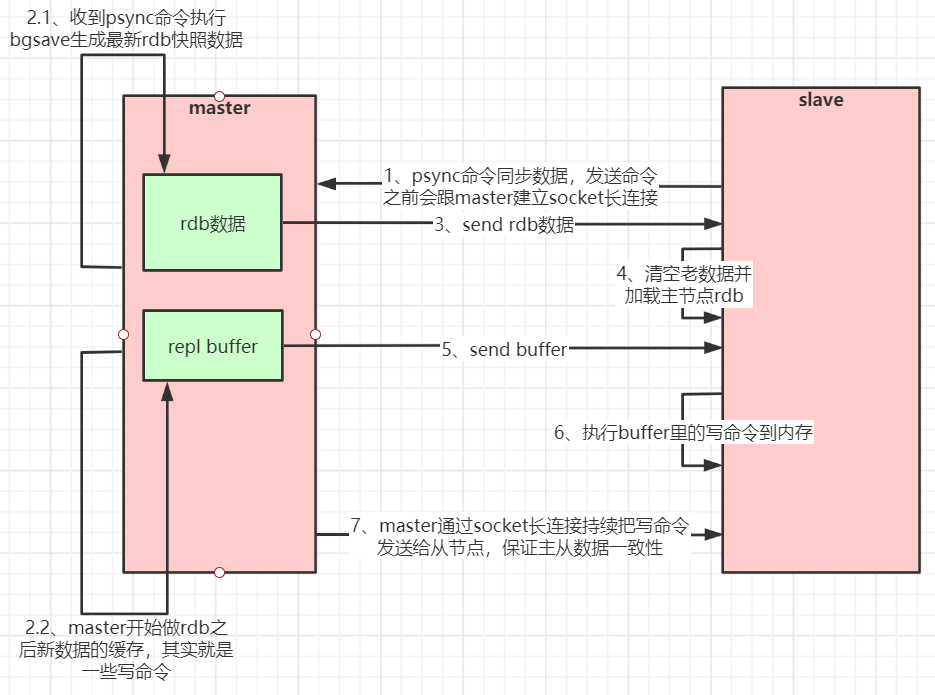
After receiving the PSYNC command, the master will perform data persistence in the background and generate the latest rdb snapshot file through bgsave. During persistence, the master will continue to receive requests from the client and cache these requests that may modify the dataset in memory. After the persistence is completed, the master will send the rdb file data set to the slave. The slave will persist the received data to generate rdb, and then load it into memory. Then, the master sends the commands previously cached in memory to the slave.
When the connection between the master and the slave is disconnected for some reason, the slave can automatically reconnect to the master. If the master receives multiple slave concurrent connection requests, it will only persist once instead of once for one connection, and then send this persistent data to multiple slave concurrent connections.
Flow chart of master-slave replication (full replication):
Data partial replication
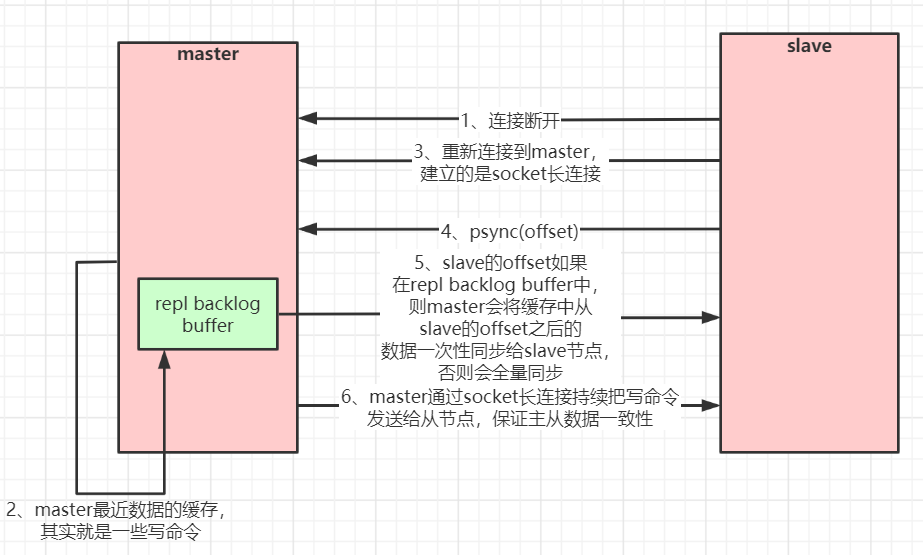
When the master and slave are disconnected and reconnected, the whole data is usually copied. However, since redis version 2.8, redis has used the command PSYNC that supports partial data replication to synchronize data with the master. Slave and master can only replicate partial data after the network connection is disconnected and reconnected (continuous transmission at breakpoints).
The master will create a cache queue for copying data in its memory to cache the data of the latest period. The master and all its slave maintain the copied data subscript offset and the master process id. therefore, when the network connection is disconnected, the slave will request the master to continue the incomplete replication, starting from the recorded data subscript. If the master process id changes, or the subscript offset of the slave node data is too old and is no longer in the cache queue of the master, a full amount of data will be copied.
Flow chart of master-slave copy (partial copy, breakpoint continuation):
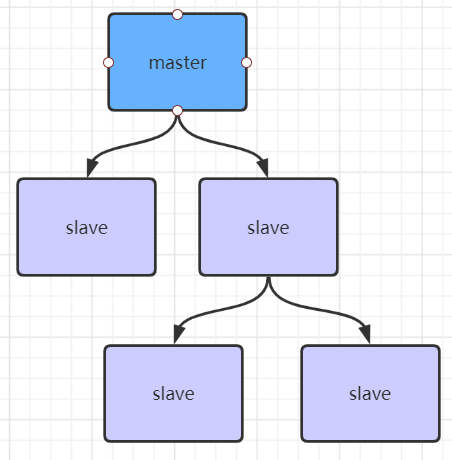
If there are many slave nodes, in order to alleviate the master-slave replication storm (multiple slave nodes replicate the master node at the same time, resulting in excessive pressure on the master node), the following architecture can be made to synchronize data between some slave nodes and slave nodes (synchronized with the master node)
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import redis.clients.jedis.Pipeline;
import java.io.IOException;
import java.util.List;
public class JedisSingleTest {
public static void main(String[] args) throws IOException {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(20);
jedisPoolConfig.setMaxIdle(10);
jedisPoolConfig.setMinIdle(5);
// Timeout, which is both a connection timeout and a read-write timeout. Starting from Jedis 2.8, the constructors of connectionTimeout and setTimeout are distinguished
JedisPool jedisPool = new JedisPool(jedisPoolConfig, "192.168.159.140",6379,3000,null);
Jedis jedis = null;
try {
// Take a connection from the redis connection pool and execute the command
jedis = jedisPool.getResource();
System.out.println(jedis.set("single","tom"));
System.out.println(jedis.get("single"));
// Pipe example
// Command execution mode of pipeline: cat redis.txt | redis cli - H 127.0.0.1 - a password - P 6379 -- pipe
/*Pipeline p1 = jedis.pipelined();
for(int i = 0; i < 10; i++){
p1.incr("pipelineKey");
p1.set("tom" + i, "tom");
}
List<Object> results = p1.syncAndReturnAll();
System.out.println(results);*/
}catch (Exception e){
e.printStackTrace();
}finally {
// Note: This is not to close the connection. In JedisPool mode, Jedis will be returned to the resource pool.
jedis.close();
}
}
}
Incidentally, let's talk about the redis pipeline and calling lua script. The code example has been given above:
Pipeline
The client can send multiple requests at one time without waiting for the response of the server. After all commands are sent, the response of the service can be read at one time, which can greatly reduce the network transmission overhead of multiple commands. In fact, the network overhead of pipeline executing multiple commands is only equivalent to the network overhead of one command execution. It should be noted that the commands are sent by pipeline packaging. redis must cache the processing results of all commands before * * processes all commands** The more commands are packaged, the more memory the cache consumes. So it's not that the more commands you package, the better. Each command sent in the pipeline will be executed immediately by the server. If the execution fails, information will be obtained in the subsequent response; That is, pipeline does not express the semantics of "all commands succeed together". If the previous command in the pipeline fails, the subsequent command will not be affected. Continue to execute.
See jedis connection example above for detailed code examples:
// Command execution mode of pipeline: cat redis.txt | redis cli - H 127.0.0.1 - a password - P 6379 -- pipe
Pipeline p1 = jedis.pipelined();
for(int i = 0; i < 10; i++){
p1.incr("pipelineKey");
p1.set("tom" + i, "tom");
}
List<Object> results = p1.syncAndReturnAll();
System.out.println(results);
Redis Lua script
Redis launched the script function in 2.6, allowing developers to write scripts in Lua language and transfer them to redis for execution. The benefits of using scripts are as follows:
- **Reduce network overhead: * * the original five network requests can be completed with one request, and the logic of the original five requests is completed on the redis server. The use of scripts reduces the network round-trip delay. This is similar to a pipe.
- Atomic operation: redis will execute the entire script as a whole without being inserted by other commands. The pipeline is not atomic, but the batch operation commands of redis (similar to mset) are atomic.
- Replace the transaction function of redis: the transaction function of redis is very weak, and the lua script of redis almost realizes the conventional transaction function. It is officially recommended that if you want to use the transaction function of redis, you can use redis lua instead.
There is a paragraph on the official website:
A Redis script is transactional by definition, so everything you can do with a Redis t ransaction, you can also do with a script,and usually the script will be both simpler and faster.
Starting from redis version 2.6.0, through the built-in Lua interpreter, you can use the EVAL command to evaluate Lua scripts. The EVAL command has the following format:
EAVL script numkeys key [key ...] arg [arg...]
The script parameter is a Lua script program, which will be run in the context of Redis server. This script does not need (and should not) be defined as a Lua function. The numkeys parameter specifies the number of key name parameters. The key name parameter key [key...] starts from the third parameter of EVAL and represents the Redis KEYS used in the script. These key name parameters can be accessed in Lua through the global variable KEYS array with 1 as the base address (KEYS[1], KEYS[2], and so on).
At the end of the command, those additional parameters arg [arg...] that are not key name parameters can be accessed in Lua through the global variable ARGV array, which is similar to the KEYS variable (ARGV[1], ARGV[2], and so on). for example

Where "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" is the evaluated Lua script, the number 2 specifies the number of key name parameters, key1 and key2 are key name parameters, which are accessed by KEYS[1] and KEYS[2] respectively, and the last first and second are additional parameters, which can be accessed through ARGV[1] and ARGV[2].
In Lua script, you can use * * redis.call() * * function to execute Redis command
See jedis connection example above for jedis call example:
jedis.set("product_stock_10016", "15");
String script = "local count = redis.call('get', KEYS[1])" +
" local a = tonumber(count) " +
" local b = tonumber(ARGV[1]) " +
" if a >= b then " +
" redis.call('set', KEYS[1], a-b)" +
" return 1 " +
" end " +
" return 0";
Object obj = jedis.eval(script, Arrays.asList("product_stock_10016"),
Arrays.asList("10"));
System.out.println(obj);
Note: do not have dead loops and time-consuming operations in Lua script, otherwise redis will block and will not accept other commands. Therefore, be careful not to have dead loops and time-consuming operations. Redis is a single process, single thread execution script. The pipeline will not block redis.