1, Introduction to Redis
Redis is an open-source SQL database developed based on C language for the underlying code. Redis runs and persists based on memory and adopts the storage form of key value (key value pair). It is an indispensable part of the current distributed architecture
Advantages of Redis
- It has extremely high data reading and writing speed: the maximum data reading speed can reach 110000 times / s, and the maximum data writing speed can reach 81000 times / s
- Support rich data types: key value, Strings, Lists, Hashes, Sets and Ordered Sets
Other data type operations - Support data persistence: the data in memory can be saved in disk and can be loaded again for use when restarting
- Atomicity: all Redis operations are atomicity
- Support data backup: that is, data backup in master save mode
2, Differences between Redis and Memcached
| Memcached | Redis | |
|---|---|---|
| Type key value | database | Key value database |
| Expiration Policies | support | support |
| data type | Single data type | Five data types |
| Persistence | I won't support it | support |
| Master-slave replication | I won't support it | support |
| virtual memory | I won't support it | support |
3, Redis deployment
1. Download, compile and install
systemctl stop firewalld systemctl disable firewalld setenforce 0 yum -y install gcc gcc-c++ make cd /opt wget -P /opt http://download.redis.io/releases/redis-6.2.2.tar.gz tar -zxvf redis-6.2.2.tar.gz cd redis-6.2.2 make && make PREFIX=/usr/local/redis install #The Redis source package directly provides the makefile file and directly executes the make and make install commands for installation cd /opt/redis-6.2.2/utils/ ./install_server.sh
Execution/ install_ server. Enter all vehicles after sh until
Please select the redis executable path [] and enter the content / usr / local / redis / bin / redis server

2. Configuration environment
#Modify configuration ln -s /usr/local/redis/bin/* /usr/local/bin/ #Create soft connection /etc/init.d/redis_6379 start #Open service netstat -natp | grep 6379 #Check whether the port service works

4, Redis common tools
1.Redis command tool
| command line | explain |
|---|---|
| redis-server | Tool for starting Redis |
| redis- benchmark | It is used to detect the operation efficiency of Redis on this machine |
| redis-check-aof | Fix AOF persistent file |
| redis-check-rdb | RDB persistent repair file |
| redis-cli | Redis command line tool |
2. Redis cli command line tool
Syntax:
redis-cli -h host -p port -a password
Example:
redis-cli -h 192.168.0.10 -p 6379
| Common options | explain |
|---|---|
| -h | Specify remote host |
| -p | Specify the port number of Redis service |
| -a | Specify the password. If the database password is not set, this option can be omitted |
3. Redis benchmark test tool
Redis benchmark is the official redis performance testing tool, which can effectively test the performance of redis services
Basic test syntax:
redis-benchmark [option] [Option value]
| Common options | explain |
|---|---|
| -h | Specify the server host name |
| -p | Specify server port |
| -s | Specify server socket |
| -c | Specifies the number of concurrent connections |
| -n | Specify the number of requests |
| -d | Specifies the data size of the SET/GET value in bytes |
| -k | 1=keep alive,0=reconnect |
| -r | SET/GET/INCR, use random key, SADD use random value |
| -p | Pipeline requests |
| -q | Force to exit redis and only display the query/sec value |
| –csv | Export in CSV format |
| -l | Generate a loop and permanently execute the test |
| -t | Run only a comma separated list of test commands |
| -I | Idle mode, only open N idle connections and wait |
redis-benchmark -h 192.168.0.10 -p 6379 -c 100 -n 100000
Send 100 concurrent connections and 100000 requests to the Redis server with IP address 192.168.0.10 and port 6379 to test the performance
redis-benchmark -h 192.168.0.10 -p 6379 -q -d 100
Test the performance of accessing packets with a size of 100 bytes
redis-benchmark -t set,lpush -n 100000 -q
Test the performance of Redis service on this machine when performing set and lpush operations
5, Common instructions
1. Data storage and acquisition
Set stores data. The command format is set key value
Get gets the data. The command format is get key
redis-cli set cathome cat get cathome

2. Query data
You can filter data similar to regular
| keys | The command can take the list of key values that meet the rules. Usually, it can be combined with *? And other options |
|---|---|
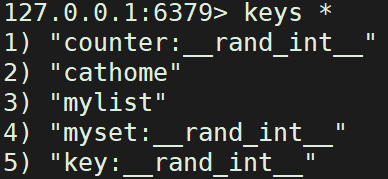
| keys * | View all data in the current database |
| keys c* | View data starting with v in the current database |
| keys c? | View the data that starts with v and then contains any bit in the current database |
| keys c?? | View the data that starts with v and contains any two digits in the current database |


3. Judgment of key value
Used to judge whether a key value exists
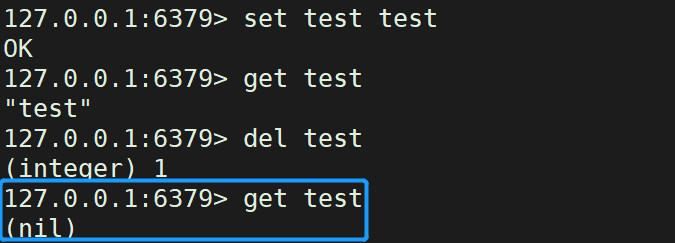
The exists command can determine whether the key value exists
exitsts Key value

The del command can delete the specified key of the current database
del Key value
The type command can obtain the value type corresponding to the key
type Key value

4. Override key value
If you overwrite an existing key value, the data will also be overwritten. Therefore, check the original key value when overwriting to avoid data loss
rename source key target key

The rename x command renames an existing key and detects whether the new name exists. If the target key exists, it will not be renamed. (do not overwrite the original data)
renamenx source key target key

The dbsize command is used to view the number of key s in the current database
dbsize

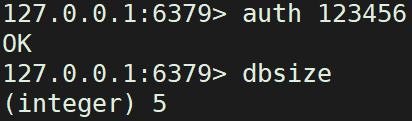
5. Password verification
For security, the password must be verified, otherwise the operation cannot be performed
config set requirepass password #Set a password auth password #Verify password elevation config get requirepass #View the password of the current database config set requirepass '' #Delete password
View blocked after changing password

Verify password
6. Multi database operation
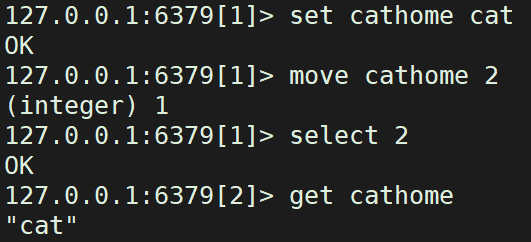
Redis supports multiple databases. By default, redis contains 16 databases, and the database names are named sequentially by the numbers 0-15. Multiple databases are independent and do not interfere with each other.
Library 0 is used by default when logging in to redis
select Serial number of the library #Switch to another library move Key library number #Move a key value to another library get key #Get key value
7. Clear the data in the database
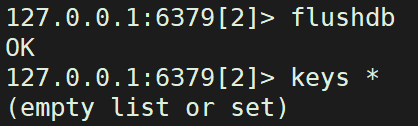
FLUSHDB: Clear current database data FLUSHALL: Clear the data of all databases and use it with caution!
6, Five data types
1. String data type (string)
String is the most basic type of redis (it can be understood that a key corresponds to a value). It can store 512MB of data at most
String type is binary safe and can store any data (such as numbers, pictures, serialized objects, etc.)
1.1 SET/GET/APPEND/STRLEN
1.1.1 APPEND
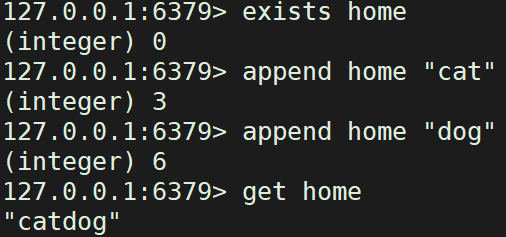
APPEND key value appends the key value and returns the length after appending (if the key does not exist, it is equivalent to creating)
exists home #Judge whether the key exists, return 1 if it exists, otherwise return 0 append home "cat" #The key does not exist, so the append command returns the length of the current Value append home " dog" #The key already exists, so the length of the appended Value is returned get home #Get the key through the get command to judge the result of append
1.1.2 SET/STRLEN
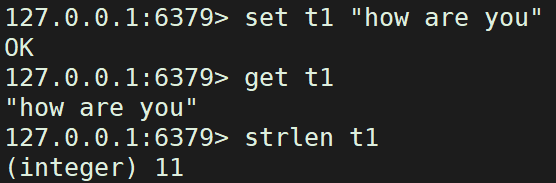
SET key value [expiration EX seconds|PX milliseconds] [NX|XX]: set key value pair
STRLEN key: counts the character length of the specified key
set t1 "how are you" #Set a new value for the key through the set command and overwrite the original value. get t1 strlen t1 #Gets the character length of the specified Key.
1.2 INCR/ DECR/INCRBY/DECRBY
1.2.1 INCR/ DECR
INCR key: the key value increases by 1 (the key value must be an integer)
DECR key: the key value increases or decreases by 1 (the key value must be an integer)
set home 20
#Set the value of Key to 20
set home 10 incr home #The value of this Key is incremented by 1 decr home #The value of this Key decreases by 1 del home #Delete existing keys. get home decr home #Decrement is performed on null values. The original value is set to 0 and the decremented value is - 1

1.2.2 INCRBY/DECRBY
INCRBY key increment: the key value is incremented by the specified integer
Decrby key increment: the key value decrements the specified integer
set home 10 decrby home 20 #Reduce the specified value incrby home 20 #Increase the specified value

1.3 GETSET
GETSET key value: get the key value and return it. At the same time, set a new value for the key
set home 10 getset home 20 #Get the value first and then set the value get home

1.4 SETEX
setex key seconds value: sets the expiration time of the specified key to seconds
setex home 5 "no way" #Setting home has a 5-second life cycle ttl home #Check lifecycle get home ttl home

1.5 SETNX
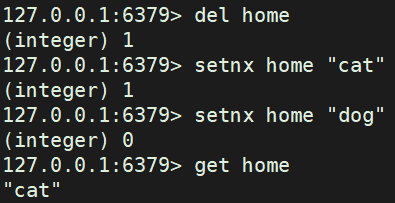
SETNX key value: if there is no key, set operation will be executed; if there is, set operation will not be executed
del home setnx home "cat" #Create when key does not exist setnx home "dog" #nx has the function of detection. All existing values will not be modified get home
1.6 MSET/MGET/MSETNX
MSET key value [key value...]: batch setting key value pairs
MGET key [key...]: get key value pairs in batch
MSETNX key value [key value...]: batch setting key value pairs, if none exist, execute and return 1; As long as one exists, it will not execute and return 0
mset 1 "oh" 2 "yes!" #Batch create keys and values mget 1 2 #Batch get value msetnx 2 "no" 3 "way" mget 1 2 3

2. List data type
Overview: the element type of the list is string, which is sorted according to the insertion order. Add elements at the head or tail of the list
2.1 LPUSH/LPUSHX/LRANGEL/POP/LIEN
LPUSH key value [value...] insert the list elements in sequence in the header (left side): LPUSHX key value: the key must exist to execute. Insert the element value in the header and return and return the number of list elements
LRANGE key start stop: get all elements from location index start to location index stop (so start with 0)
lpush home a b c d #The home key does not exist. The command will create the key and its associated List, and then insert the values in the parameter on the left in turn. lrange home 0 2 #Take 3 elements from position 0 to position 2. lrange home 0 -1 #Take all the elements in the linked list, where 0 represents the first element and - 1 represents the last element. lpushx home2 e #The home2 key does not exist at this time, so the lpushx command will not do anything, and its return value is 0. lrange home2 0 -1 #You can see that home2 is not associated with any list values. lpushx home e #The home key already exists at this time, so the lpushx command is successfully inserted and returns the number of current elements in the linked list. lrange home 0 0 #Gets the header element of the List Value of the key. lpushx home f g #Can be inserted in batch lrange home 0 -1

lpop home #Remove and return the first element, starting from scratch llen home #View the number of elements in the list lrange home 0 -1 #View all elements in the list

2.2 LREM/ LSET/LINDEX/LTRIM
LREM key count value: delete count elements with value from the header and return the actual deleted quantity
LSET key index value: set the element whose location index is index to the new value value
LINDEX key index: get the element with index
LTRIM key start stop: only the elements from the location index start to the index stop are retained
lpush home a b c d a c #Prepare test data for the following examples lrem home 2 a #From the left to the right variable linked list, delete two elements with a value equal to a, and the return value is the actual number deleted. #Delete the specified element or quantity, calculated from left to right lrange home 0 -1 #See all the elements in the linked list after deletion lindex home 1 #Gets the element value with an index value of 1 (the second element of the header) lset home 1 e #Set the element value with the index value of 1 (the second element of the header) to the new value e lindex home 1 #Check whether the settings are successful lindex home 6 #If the index value 6 exceeds the number of elements in the linked list, the command returns nil lset home 6 h #The set index value 6 exceeds the number of elements in the linked list. The setting fails. The command returns an error message ltrim home 0 2 #Only 3 elements with index values between 0 and 2 are reserved. Note that both the 0th and 2nd elements are reserved lrange home 0 -1 #View the results after trim

2.3 LINSERT
LINSERT key BEFORE|AFTER pivot value: insert a new element value before (left) or after (right) the element pivot
del home #Delete this key for later testing lpush home a b c d e #Prepare test data for the following examples linsert home before a a1 #Insert a new element a1 before a lrange home 0 -1 #Check whether the insertion is successful. The result shows that it has been inserted linsert home after e e2 #Insert the new element e2 after e. from the returned result, it can be seen that the insertion has been successful lindex home 1 #Check again to see if the insertion is successful linsert home after k a #When a new element is inserted before or after a non-existent element, the linsert command operation fails and returns - 1 linsert home1 after a a2 #Insert a new element for a nonexistent Key. The linsert command operation fails and returns 0

2.4 RPUSH/RPUSHX/RPOP/RPOPLPUSH
RPUSH key value [value...] insert value at the end of the list
RPUSHX key value: the key must exist before it can be executed. Insert value from the tail and return the number of all elements
RPOP key: pop up (remove) an element at the tail and return it
Rpolpush source destination: pop up an element at the end of key1 and return it, and insert it into the head of key2
del mykey #Delete this key for later testing rpush mykey a b c d #Insert the values given in the parameters from the tail of the linked list in the order from right to left lrange mykey 0 -1 #You can know the insertion order of rpush when inserting multiple values through lrange command rpushx mykey e #The key already exists and contains four elements. The rpushx command will execute successfully and insert element e into the tail of the linked list lindex mykey 4 #From the lindex command, we can see that the previous rpushx command is indeed successful, because the element with index value of 4 is already a new element rpushx mykey2 e #Since the mykey2 key does not exist, the rpushx command will not insert data and its return value is 0 lrange mykey 0 -1 #Before executing the rpoplpush command, first look at the elements of the linked list in mykey and pay attention to their positional relationship RPOP mykey #Remove and return the first element of the mykey key, taken from the right LRANGE mykey 0 -1 rpoplpush mykey mykey2 #Pop up the tail element e of MyKey and insert it into the head of mykey2 at the same time (complete these two operations atomically) lrange mykey 0 -1 #Use the lrange command to view the result of mykey after popping the tail element lrange mykey2 0 -1 #View the result of mykey2 after inserting the element through the lrange command rpoplpush mykey mykey #Set source and destination to the same key and move the tail element in mykey to its head lrange mykey 0 -1 #View move results
3. Hash data type (hash)
Redis hash is a mapping table of field and value of string type. Hash is especially suitable for storing objects
Redis hash is a set of key value (key = > value) pairs
This naming method can be adopted: the object category and ID constitute the key name, the field is used to represent the attribute of the object, and the field value stores the attribute value
If the Hash contains few fields, this type of data will also take up very little disk space
Each Hash can store about 4.2 billion key value pairs
3.1 HEST,HGET,HDEL,HEXISTS
HSET hash field1 a field2 b field3 c #Create three fields and corresponding field values for the hash key HGET hash field1 #Get the hash key, and the field is the value of field1 HDEL hash field2 #Delete the hash key, the field is the value of field2, and 1 is returned successfully HEXISTS hash field2 #Check whether the value with field 2 in the hash key exists, and return 1 if it exists
3.2 HLEN,HSETNX,HINCRBY
HLEN hash #Gets the number of fields for the hash key HSETNX hash1 field3 z #Add a new field field3 to the hash1 key. The value is z. whether to execute is based on whether this field exists or not. No matter whether the key exists or not, a return of 1 indicates that the execution is successful KEYS hash* #After adding new data, the hash1 key exists HSETNX hash field3 d #This field does not exist, so the execution was unsuccessful HINCRBY hash3 field1 1 #Add 1 to the field1 field value of the hash3 key HGET hash3 field1 #The confirmed value is 1 HINCRBY hash3 field1 -10 #Field value minus 10 HGET hash3 fiel
3.3 HGETALL,HKEYS,HVALS,HVALS,HMGET,HMSET
HGETALL hash1 #Returns all fields of the hash1 key and their values, listed pair by pair HGETALL hash3 HKEYS hash1 #Only get all field names in hash1 key HKEYS hash3 HVALS hash1 #Get only the values of all fields in the hash1 key HVALS hash3 HMSET hash4 field1 hello field2 world HMGET hash4 field1 field2
4. Set data type (unordered set)
Unordered collection, element type is String type
Element is unique. Duplicate members are not allowed
Union, intersection and difference operations can be performed among multiple set types
Scope of application
Redis's Set data type can be used to track some unique data
For example, the unique IP address information of a blog
For this scenario, we only need to store the visitor's IP in Redis every time we visit the blog, and the Set data type will automatically ensure the uniqueness of the IP address
Make full use of the convenient and efficient characteristics of Set type server aggregation operation, which can be used to maintain the association relationship between data objects
For example, all customer IDs for purchasing an electronic device are stored in a specified Set, while customer IDs for purchasing another electronic product are stored in another Set
If we want to know which customers have purchased these two products at the same time, the Set intersections command can give full play to its advantages of convenience and efficiency
4.1 SADD,SMEMBERS,SCARD,SISMEMBER
SADD myset a b c d e #If one or more member elements are added to the set, the member elements that already exist in the set will be ignored. If the set key does not exist, a set containing only the added elements as members will be created (integer) 5 SMEMBERS myset #View the insertion results. The order of output is independent of the insertion order SCARD myset #Gets the number of members in the collection SISMEMBER myset d #Judge whether the member in the key exists. Return 0 to indicate that it does not exist and 1 to indicate that it exists SISMEMBER myset f
4.2 SPOP,SREM,SRANDMEMBER,SMOVE
SPOP myset #Randomly remove and return a member of the key SMEMBERS myset #Viewing the results, the order of output is independent of the insertion order SPOP myset SMEMBERS myset SREM myset a b e #Remove a/b/e from the key and return the number of removed members. a/e has just been removed, so return 1 SMEMBERS myset SRANDMEMBER myset #This command returns a member randomly SRANDMEMBER myset SRANDMEMBER myset SMOVE myset myset1 c #Move the c member of the key myset to the key myset1, return 1 for success and 0 for failure SMEMBERS myset SMEMBERS myset1
5. Zset data type (Sorted Set)
Like Set, Zset is also a collection of String type elements, and duplicate members are not allowed
Each element is associated with a score of double type. redis sorts the members of the collection from small to large through scores
The members of zset are unique, but the score can be repeated
Score (indicates weight), which can be sorted by the size of the weight
Scope of application
Leaderboard that can be used for a large online game:
Whenever a player's score changes, you can execute the ZADD command to update the player's score, and then obtain the user information of the top 10 through the ZRANGE command
5.1 ZADD,ZRANK,ZCARD,ZRANK,ZCOUNT
ZADD zset 1 a 2 b 3 c 4 d 5 e #Add one or more member elements and their fractional values to the ordered set ZRANGE zset 0 -1 #View members ZRANGE zset 0 -1 withscores #View members and corresponding scores ZCARD zset #Gets the number of members in the key ZRANK zset e #Gets the location index value of the member ZRANK zset a ZCOUNT zset 2 4 #Number of members whose score satisfies the expression [x < = score < = x]
5.2 ZREM,ZSCOREZINCRBY
ZREM zset a b #Delete members and return the actual number of deleted members ZSCORE zset d #Get members' scores ZINCRBY zset 2 a #If the member does not exist, the zincrby command adds the member with a score of 2 (and assumes its initial score of 0) ZINCRBY zset -1 a ZRANGE zset 0 -1 withscores
5.3 ZRANGEBYSCORE,ZREMRRANGEBYSCORE,ZREMRANGEBYRANK
DEL zset (integer) 1 ZADD zset 1 a 2 b 3 c 4 d 5 e #Add one or more member elements and their fractional values to the ordered set ZRANGEBYSCORE zset 2 4 #Get the member whose score satisfies the expression [x < = score < = x], i.e. 2 3 4 ZRANGEBYSCORE zset -inf +inf limit 2 3 #-Inf and + inf denote the first and last members, and limit 23 denotes the three members (a0, b1, c2, d3, e4, i.e. c, d, e) with index 2 ZREMRANGEBYSCORE zset 1 3 #Delete members whose scores meet the expression [x < = score < = x], and return the actual deleted quantity ZRANGE zset 0 -1 #View and confirm the results ZREMRANGEBYRANK zset 1 2 #Delete members whose position index satisfies the expression [x < = rank < = x], that is (0d, 1e, delete 1 and 2 index values, and only 1E is deleted) ZRANGE zset 0 -1 #Check and confirm the result. There are only d left
5.4 ZREVRANGE,ZREVRANGEBYSCORE,ZREVRANK
DEL zset ZADD zset 1 a 2 b 3 c 4 d 5 e ZRANGE zset 0 -1 ZREVRANGE zset 0 -1 #Get and return the members in this interval from high to low by location index ZREVRANK zset a #Gets the member index. The usage is reverse index sorting ZREVRANK zset e ZRANK zset a #The forward direction is 0 ZRANK zset e ZREVRANGEBYSCORE zset 5 3 #Get the members whose scores satisfy the expression [x > = score > = x] and output them in the order from high to bottom ZREVRANGEBYSCORE zset 3 1 limit 1 2 #Members with scores of 1-3 and indexes of 1-2
7, Redis high availability
In the web server, high availability refers to the time when the server can be accessed normally. The measurement standard is how long it can provide normal services (99.9%, 99.99%, 99.999%, etc.)
However, in the context of Redis, the meaning of high availability seems to be broader. In addition to ensuring the provision of normal services (such as master-slave separation and fast disaster recovery technology), it is also necessary to consider the expansion of data capacity and data security will not be lost
In Redis, the technologies to achieve high availability mainly include persistence, master-slave replication, sentinel and cluster. Next, explain their functions and what problems they solve:
1. Persistence
Persistence is the simplest high availability method (sometimes not even classified as a high availability means)
The main function is data backup, that is, the data is stored in the hard disk to ensure that the data will not be lost due to the exit of the process
2. Master slave copy
Master-slave replication is the basis of highly available Redis. Sentinels and clusters achieve high availability on the basis of master-slave replication
Master-slave replication mainly realizes multi machine backup of data, load balancing for read operation and simple fault recovery
The defects are that the fault recovery cannot be automated, the write operation cannot be load balanced, and the storage capacity is limited by a single machine
3. Sentry
On the basis of master-slave replication, sentry realizes automatic fault recovery
The disadvantages are that the write operation cannot be load balanced, and the storage capacity is limited by a single machine
4. Cluster
Through the cluster, Redis solves the problems that the write operation cannot be load balanced and the storage capacity is limited by a single machine
A relatively perfect high availability scheme is realized
8, Redis persistence
1. Persistent function
Redis is an in memory database, and all data are stored in memory. In order to avoid permanent loss of data after the redis process exits abnormally due to server power failure and other reasons, it is necessary to regularly save the data in redis from memory to hard disk in some form (data or command)
When redis restarts next time, use persistent files to realize data recovery
In addition, for disaster backup, persistent files can be copied to a remote location
2. Redis provides two methods for persistence
RDB persistence: the principle is to save the database records of IDS in memory to disk regularly
AOF persistence (append only file): the principle is to write the IDS operation log to the file by appending, which is similar to MySQL binlog
Because AOF persistence has better real-time performance, that is, less data is lost when the process exits unexpectedly, AOF is the mainstream persistence method at present, but RDB persistence still has its place
9, RDB persistence
rdb persistence refers to saving the generated snapshot of the data in the current process in memory to the hard disk within a specified time interval (so it is also called snapshot persistence), and storing it in binary compression. The saved file suffix is rdb
When Redis restarts, you can read the snapshot file recovery data
1. Trigger conditions
The trigger of RDB persistence can be divided into manual trigger and automatic trigger
1.1 manual trigger
Both the save command and bgsave command can generate RDB files
The save command will block the Redis server process until the RDB file is created. During the Redis server blocking period, the server cannot process any command requests
The bgsave command will create a child process, which will be responsible for creating RDB files, and the parent process (i.e. Redis main process) will continue to process requests
During the execution of bgsave command, only fork subprocess will block the server, while for Save command, the whole process will block the server. Therefore, save has been basically abandoned, and the use of save should be eliminated in the online environment
1.2 automatic triggering
When RDB persistence is triggered automatically, Redis will also choose bgsave instead of save for persistence
save m n
#The most common case is that the BG is automatically triggered n times in the specified save file in Mn seconds
vim /etc/redis/6379.conf #219. bgsave will be called when any of the following three save conditions is met save 900 1 :When the time reaches 900 seconds, if redis If the data has changed at least once, execute bgsave save 300 10 :When the time reaches 300 seconds, if redis If the data has changed at least 10 times, execute bgsave save 60 10000 :When the time reaches 60 seconds, if redis If the data has changed at least 10000 times, execute bgsave #Line 254, specify the RDB file name dbfilename dump.rdb #264 line, specify the directory where the RDB file and AOF file are located dir /var/lib/redis/6379 #Line 242, whether to enable RDB file compression rdbcompression yes
2. Execution process

- Redis parent process first judges whether save or bgsave/bgrewriteaof child process is currently executing. If it is executing, bgsave
The command returns directly, bgsave/bgrewriteaof
Child processes of cannot be executed at the same time; It is mainly based on performance considerations: two concurrent sub processes perform a large number of disk write operations at the same time, which may cause serious performance problems - The parent process performs a fork operation to create a child process. In this process, the parent process is blocked, and Redis cannot execute any commands from the client
- After the parent process fork s, the bgsave command returns "Background saving"
The "started" message no longer blocks the parent process and can respond to other commands - The child process creates an RDB file, generates a temporary snapshot file according to the memory snapshot of the parent process, and performs atomic replacement of the original file after completion
- The child process sends a signal to the parent process to indicate completion, and the parent process updates the statistical information
3. Start loading
- The loading of RDB files is automatically executed when the server is started, and there is no special command
- However, due to the higher priority of AOF, Redis will give priority to loading AOF files to recover data when AOF is enabled
- RDB files will be detected and loaded automatically when Redis server starts up only when AOF is closed
- The server is blocked while loading RDB files until loading is complete
- When Redis loads an RDB file, it will verify the RDB file. If the file is damaged, an error will be printed in the log (Redis startup fails)
10, AOF persistence
When Redis operates on the data, record the log [except query operation], and recover the data by executing the command in the AOF file again when restarting
1. Configure to enable AOF
vim /etc/redis/6379.conf #700 line modification, enable AOF appendonly yes /etc/init.d/redis_6379 restart
2. Execution process
Command append
- Write commands are not directly written to the disk, but appended to the buffer to avoid disk I/O bottlenecks
- Plain text format with strong compatibility, easy processing and high readability
File writing and file synchronization
In order to avoid accidental loss of data in the memory buffer, synchronization functions such as fsync and fdatasync are provided to force the operating system to write the data in the buffer to the hard disk immediately, so as to ensure the security of the data
There are three synchronization methods for the synchronization file policy of AOF cache
vim /etc/redis/6379.conf #Line 729 appendfsync always: #Write command to AOF_ After buf, call the system fsync operation immediately to synchronize to the AOF file. After fsync is completed, the thread returns #In this case, every time there is a write command, it must be synchronized to the AOF file. The hard disk IO has become a performance bottleneck. Redis can only support about hundreds of TPS writes, which seriously reduces the performance of redis #Even with solid state drives (SSDs), they can only process tens of thousands of commands per second, which will greatly reduce the life of SSDs appendfsync no: #Write command to AOF_ After buf, the system write operation is invoked, and fsync synchronization is not done for AOF files. #Synchronization is the responsibility of the operating system, and usually the synchronization cycle is 30 seconds #In this case, the time of file synchronization is uncontrollable, and there will be a lot of data accumulated in the buffer, so the data security cannot be guaranteed appendfsynceverysec: #Write command to AOF_ After buf, the system write operation is invoked, and the thread returns after write completes. #The fsync sync file operation is invoked by a dedicated thread once per second #everysec is a compromise between the above two strategies and a balance between performance and data security. Therefore, it is the default configuration of Redis and the configuration we recommend
file overwrite
Periodically convert the internal data of the process into write commands and synchronize them to the new AOF file, so as to reduce the volume of the AOF file [the old AOF file will not be processed]

- (1) The Redis parent process first determines whether there is a child process executing bgsave/bgrewriteaof. If so, the
The bgrewriteaof command returns directly. If there is a bgsave command, wait until bgsave is completed - (2) The parent process performs a fork operation to create a child process. In this process, the parent process is blocked
- (3.1) after the parent process fork s, the bgrewriteaof command returns "Background append only file"
rewrite started "the message no longer blocks the parent process and can respond to other commands; all write commands of Redis are still written to the AOF buffer and
The appendfsync policy is synchronized to the hard disk to ensure the correctness of the original AOF mechanism - (3.2) because the fork operation uses the copy on write technology, the subprocess can only share the memory data during the fork operation; Since the parent process is still responding to commands, Redis
Use AOF rewrite_buf to save this part of data to prevent new AOF
This part of data is lost during file generation; That is, during the execution of bgrewriteaof, Redis's write command is appended to aof at the same time_ BUF and aof_
rewirte_ buf two buffers - (4) The child process writes to the new AOF file according to the memory snapshot and the command merge rules
- (5.1) after the child process writes a new AOF file, it sends a signal to the parent process, and the parent process updates the statistical information, which can be viewed through info persistence
- (5.2) the parent process writes the data of AOF rewrite buffer to the new AOF file, which ensures that the database state saved by the new AOF file is consistent with the current state of the server
- (5.3) replace the old file with the new AOF file to complete AOF rewriting
Trigger mode
Manual trigger
Call the bgrewriteaof command directly. The execution of this command is somewhat similar to that of bgsave
All fork subprocesses do specific work, and they are blocked only when forking
Automatic trigger
BGREWRITEAOF is automatically executed by setting auto AOF rewrite min size option and auto AOF rewrite percentage option
Only when the auto AOF rewrite min size and auto AOF rewrite percentage options are met at the same time will AOF rewriting be triggered automatically, that is, bgrewriteaof operation
vim /etc/redis/ 6379. conf #Line 771 auto-aof- rewrite-percentage 100 #BGREWRITEAOF occurs when the current AOF file size (i.e. aof_current_size) is twice the AOF file size (aof_base_size) when the log was rewritten last time auto-aof -rewrite-min-size 64mb #Minimum value of BGREWRITEAOF command executed by current AOF file #Avoid frequent BGREWRITEAOF due to small file size when starting IDS at the beginning