1. Explanation of NoSQL (non relational database)
Why use Nosql
Big data age - > springboot + springcloud
The beautiful era of stand-alone Mysql!
In the 1990s, the number of visits to basic websites was small, and only a single database was enough.
Bottleneck of the whole website:
1. If the amount of data is too large, one machine cannot fit.
2. Index the data (if the mysql data exceeds 300w, the index must be established!), If the index is too large, one machine memory will not fit.
3. The number of accesses (mixed reading and writing) cannot be borne by one server.
As long as one of the above situations begins to occur, you must be promoted.
Memcached+Mysql + vertical split (read / write split)
80% of the website is reading, and it is very troublesome to query the database every time.
Therefore, if you want to reduce the pressure on the server, you can use cache to ensure efficiency.
The cache is mainly used to solve the problem of reading. Zhang San saves it in the cache after reading it once from the database, and takes it from the cache when Li Si reads it.
Cache development process: optimize data structure and index - > file cache - > memcached
Sub database and sub table + horizontal split + Mysql Cluster
Essence: database (read + Write)
Slowly, use sub database and sub table to realize the pressure of writing (make each individual business a separate database into a micro service).
Recent era
In the 30 years of technology explosion, relational databases such as mysql are not enough. If they are used to store blogs or files, mysql has a lot of pressure. If the database table is large, the efficiency will be reduced. If there is a database dedicated to processing this kind of data, the pressure of mysql can be reduced.
Why use NoSQL
Users' personal information, social networks, geographical location, self generated data and logs, etc
The relational database cannot be solved. NoSQL database is needed. NoSQL can solve the above situation well.
What is NoSql
NoSql
NoSQL = not only SQL (not just sql)
Relational database: composed of tables, rows and columns (POI uses Java code to operate Excel)
Generally refers to non relational database, with the development of web2 0 the birth of the Internet, the traditional relational database is difficult to deal with web2 0 era.
Especially in large-scale and highly concurrent communities.
Characteristics of NoSql
1. Easy to expand (there is no relationship between data, so it is easy to expand!)
2. Large amount of data and high performance (Redis writes 8w times and reads 11w times a second. NoSql cache is a fine-grained cache)
3. The data types are diverse (there is no need to design the database in advance! Directly Set Get on demand)
The difference between traditional relational database (RDBMS) and non relational database (NoSql)
Traditional relational database
-
Structured organization
-
SQL
-
Data and relationships are stored in separate tables (row and col)
-
Data operation, data definition language
-
Strict consistency (ACID principle)
-
Basic transaction
NoSql
- Not just data
- There is no fixed query language
- Key value pair storage, column storage, document storage, graphic database (social relationship)
- Final consistency
- CAP theorem and BASE
- High performance, high availability and high scalability
Understanding: 3V+3 high in the era of big data
Understanding: 3V+3 high
3V in the era of big data: it is mainly used to describe problems
- Massive Volume: large amount of data
- Diversity: database diversity
- Real time Velocity: the real-time nature of information transmission
High 3 in the era of big data: it is mainly used to solve problems
- High concurrency
- Highly scalable (can be split horizontally at any time)
- High performance (guaranteed user experience and performance)
Real company practice: NoSql+RDBMS is the strongest
2. Alibaba architecture evolution
| time | keyword |
|---|---|
| 1999 first generation network architecture | Perl,CGI,Oracle |
| 2000 enters the Java Era | Java+Servlet |
| 2001-2004 EJB Era | EJB(SLSB,CMP,MDB),Pattern(ServiceLocator,Delegate,Facade,DAO,DTO) |
| 2005-2007 without EJB refactoring | EJB Refactoring: Spring+iBatis+Webx, Antx, underlying architecture: iSearch, MQ+ESB, data mining, CMS |
| 2010 security image | Security, mirroring, application server upgrade, seckill, NoSql, SSD |
Mission of the fifth generation website
- agile
The business is growing rapidly and needs to be online every day
- to open up
Improve the openness of the website, provide SDK and attract third-party developers to join the website construction
- experience
The pressure of website concurrency is growing rapidly, and users put forward higher requirements for experience
Architect mission
# 1. Basic information of goods Name, price and merchant information; Relational database can be solved! - Mysql # 2. Description and comments of goods (when there are many words) - Document database, MongoDB # 3. Picture distributed file system - Hadhoop HDFS -Alibaba cloud OSS # 4. Keywords for items (search) - Search Engines solr elasticsearch # 5. Popular band information of products - Memory database redis # 6. Commodity transaction and external payment interface -Third party application
Problems encountered in the data layer and Solutions
problem
Problems encountered by large Internet:
- Too many data types
- There are many data sources, which are often reconstructed
- Data transformation, large-scale transformation
Solution
Data solution: unified data service layer UDSL
(nothing can't be solved by adding one layer)
Specific implementation method:
# A proxy unified data layer is built between the application cluster and the underlying data source - Characteristics of unified data layer: - Model data mapping - Realize the business model, and map each attribute to the model data of different types of data sources at the bottom -Currently supported relational databases: iSearch,redis,MongoDB - Unified query and update API - It provides unified query and update based on business model API,Simplify the development mode of website applications across different data sources - Performance optimization strategy - Field delay loading, return to settings on demand - L2 cache based on hotspot cache platform - Asynchronous parallel query data: fields from different data sources in asynchronous parallel loading model - Concurrency protection: deny access to hosts with high frequency or IP - Filter high-risk queries: for example, full table scanning that will cause database crash
3. Four categories of NoSQL
KV key value pair
+ Sina: Redis + Meituan: Redis+Tair + Ali/Baidu: Redis+memecache
Document database
Using * * * bson * * * format, it looks the same as JSON, only binary JSON
- Mongodb (generally required)
- MongoDB is a database based on distributed file storage, C++
- It is mainly used to process a large number of documents
- MongoDB is an intersection between * * * relational database and non relational data!
- MongoDB is the most functional and relational database among non relational databases!
- ConthDB (foreign)
Column storage database
- HBase
- Distributed file system Hadoop
Graph relational database
Relationships, not graphics
For example:
- Circle of friends social network
- Advertising recommendation
Neo4j,InfoGrid
4.CAP
5.BASE
6. Introduction to redis
summary
What is Redis?
Redis(Remote Dictionary Server), namely remote dictionary service, is also called * * * structured database***
Function: persistent periodic data and master-slave replication
- Is an open source
- Written in C language
- Support network, memory based and persistent log key value database
- Provides multilingual API s
What can Redis do?
-
Memory storage, persistence.
-- Memory is lost immediately after power failure, and persistence is very important # Key: rdb, aof
-
Efficient and can be used for caching
-
Publish subscribe system
-
Map information analysis
-
Timer, counter (views! incr decr)
-
...
characteristic
- Diverse data types
- Persistence
- colony
- affair
- ...
Things needed in learning
- Official website: https://redis.io/ - Chinese network:https://www.redis.cn/
Redis is single threaded
Officials say that Redis is based on memory operation, and the CPU is not the performance bottleneck of Redis. The * * * bottleneck * * * of Redis is determined according to the machine memory and network bandwidth.
If you can use a single thread, use a single thread.
Why is single thread so fast?
-
Myth 1: high performance servers must be multi-threaded?
-
Myth 2: multi thread (CPU) must be more efficient than single thread?
Speed comparison: CPU > memory > hard disk
Core: Redis puts all data into memory, so the efficiency of using single thread is the highest. (for the memory system, the switching efficiency without CPU context is the highest)
Logic: multithreaded CPU context switching is a time-consuming operation
7.Redis installation
Pressure test tool
Refis benchmark is an official
Redis benchmark command parameters
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-zgcj2qfv-1625378600109) (/ users / xingyuchen / library / Application Support / typora user images / image-20210520104154784. PNG)]
# Test: 100 concurrent 100000 requests redis-benchmark -h localhost -p 6379 -c 100 -n 100000
How do I view the analysis?
Redis Basics
- redis has 16 databases by default, and the 0 database is used by default
select switch database
You can use select to switch databases
# Switch to the fourth database and use select (index) select 3
dbsize view size
You can use dbsize to view the database size
# View database size dbsize
keys view key
You can use keys to view key keywords
#View all key s keys *
Flush DB empties the current library
You can use flushdb to empty the current library
# Empty current library flushdb
Flush empty all libraries
You can use flush to empty all libraries
# Empty all libraries flushall
exists determines the presence of
You can use exist to determine whether it exists
# Judge whether a key exists (key) exists name
move remove key
You can use move to remove the current key
# Remove current key move (key) (db) move name 1
expire time
You can use expire to set the expiration time
# Set the expiration time of a key expire (key) (seconds) expire name 10
ttl view expiration time
You can use ttl to view the expiration time
# View the expiration time ttl (key) of a key ttl name
Set set key
You can use set to write key s
# Set key (key) (value) set name zhangsan
get gets the key value
You can use get to read the key value
# Get the key value get (key) get name
Type view type
You can use type to view the type of key
# View the type of key (key) type name
- Port number 6379 is just an irony
8. Five basic data types
Redis-Key
Redis is an open source, memory based data structure storage system, which can be used as database, cache and message middleware MQ. Support data structures of multiple data types, such as strings, hashes, lists, sets, sorted sets, and range queries, bitmap, hyperlogs, and geospatial index radius queries. replication, Lua scripting, LRU events, transactions and different levels of disk persistence are built in, and high availability is provided through redis Sentinel and Cluster.
String (string)
90% of programmers only use String type when using Redis.
Redis cli - P 6379 running redis
command
Append append
You can append strings using append
# Append can be used to append strings. If the key does not exist, it is equivalent to set key append (key) (value) append name aaaa
strlen get length
You can use strlen to get the string length
# You can use strlen to get the string length strlen (key) strlen name
incr to achieve i + + effect
i + + effects can be achieved using incr
# i++ incr (key) can be implemented using incr incr view # Can be used to achieve browsing++ 127.0.0.1:6379> set view 0 OK 127.0.0.1:6379> get view "0" 127.0.0.1:6379> incr view (integer) 1 127.0.0.1:6379> get view "1"
decr implementation i – effect
decr can be used to achieve i – effect
# You can use decr to achieve i-- effect decr (key) decr view # Implementation data-- 127.0.0.1:6379> decr view (integer) 1 127.0.0.1:6379> get view "1"
incrby sets the incremental step size
You can use incrby to set the increment step
# You can use incrby to set the step size incrby (key) (increment) incrby view 10
decrby sets the step size for subtraction
You can use decrby to set the subtraction step
# You can use decrby to set the subtraction step decrby (key) (increment) decrby view 10
getrange gets a range string
You can use getrange to get a range of strings
# You can use getrange to get a range of strings getrange (key) (start) (end) getrange name 2 5
getrange gets all strings
You can use getrange to get all strings
# You can use getrange to get all strings getrange (key) 0 -1 getrange name 0 -1
setrange replacement
You can use setrange to change the value of the value bit from a certain position
# You can use setrange to change the value from the first offset position to value setrange (key) (offset) (value) setrange name 2 xx # example 127.0.0.1:6379> get name "abcaaasga" 127.0.0.1:6379> setrange name 2 xx (integer) 9 127.0.0.1:6379> get name "abxxaasga"
Setnx does not exist
If the key does not exist, use setnx to set the key | set if not exit | commonly used in distributed locks ⬇️
# Use setnx. If the key does not exist, setnx (key) (value) (key2) (value2) [one or more keys are allowed] setnx name abc # example 127.0.0.1:6379> setnx name abc (integer) 0 127.0.0.1:6379> get name "a"
setex set expiration time
You can use setex to set the expiration time of the key | set with expire
# Use setex to set the expiration time setex (key) (second) (value) setex name 30 abc
mset sets multiple key s at a time
Multiple key s can be set using mset
# Use mset to set multiple keys at once mset (key1) (value1) (key2) (Value2) mset k1 v1 k2 v2
mget gets multiple key s at a time
You can use mget to get multiple key values
# Use mget to get multiple key values at once mget (key1) (key2) mget k1 k2 k3
Object design
Storage of design objects
-
Setting object properties using mset
# mset user:{id}:{filed} mset user:1:name zhangsan user:1:age 21 # example 127.0.0.1:6379> mset user:1:name zhangsan user:1:age 21 OK 127.0.0.1:6379> keys * 1) "user:1:age" 2) "user:1:name" -
Setting objects using set
# set user:{id} {obj} set user:1 {name:zhangsan,age:3} # example 127.0.0.1:6379> set user:1 {name:zhangsan,age:3} OK 127.0.0.1:6379> keys * 1) "user:1" 127.0.0.1:6379> get user:1 "{name:zhangsan,age:3}"
getset get first and then set
Use getset to get and then set the key
# Use getset to get and then set getset (key) (value) getset db 123 # example 127.0.0.1:6379> getset db redis (nil) 127.0.0.1:6379> get db "redis" 127.0.0.1:6379> getset db redis222 "redis" 127.0.0.1:6379> get db "redis222"
All data structures are the same, and Jedis will be used in the future (method), command is method
String usage scenario example
- Counter
- Statistics of multi unit quantity: uid:952312:follow 0
- Number of fans
- Object storage cache
- ...
List
In Redis, we can complete the list stack, queue and blocking queue
List rule
All commands begin with l
lpush set list value / append to header
Use lpush to set list / append list | append a value to the head of the list
# Using lpush to set list lpush (listkey) (element1) (Element2) [elements] lpush name zhangsan lisi # Append list with lpush lpush name wangwu # example 127.0.0.1:6379> lpush name zhangsan lisi (integer) 2 127.0.0.1:6379> lrange name 0 -1 1) "lisi" 2) "zhangsan" 127.0.0.1:6379> lpush name wangwu (integer) 3 127.0.0.1:6379> lrange name 0 -1 1) "wangwu" 2) "lisi" 3) "zhangsan"
rpush set list value / append to tail
Use rpush to set list / append list to append a value to the end of the list
# Use rpush to set list rpush (listkey) (element1) (Element2) [elements] rpush name zhangsan lisi # Append list using rpush rpush name wangwu # example 127.0.0.1:6379> rpush name zhangsan lisi (integer) 2 127.0.0.1:6379> lrange name 0 -1 1) "zhangsan" 2) "lisi" 127.0.0.1:6379> rpush name wangwu (integer) 3 127.0.0.1:6379> lrange name 0 -1 1) "zhangsan" 2) "lisi" 3) "wangwu"
lrange view list value
Use lrange to view the list value (take it backwards)
# Using lrange to view the list range lrange name 1 3 # Use lrange to view all list s lrange name 0 -1
lpop is removed from the left side of the queue
Use lpop to remove elements from the left side of the queue
# Remove the first element lpop (listkey)[count] on the left of the queue lpop name # example 127.0.0.1:6379> lpush k1 1 2 3 4 5 (integer) 5 127.0.0.1:6379> lpop k1 "5" 127.0.0.1:6379> lrange k1 0 -1 1) "4" 2) "3" 3) "2" 4) "1" # Remove the n elements lpop (key) (num) on the left of the queue lpop name 3 # example 127.0.0.1:6379> lpush name a b c d e f g h (integer) 8 127.0.0.1:6379> lpop name 2 1) "h" 2) "g" 127.0.0.1:6379> lrange name 0 -1 1) "f" 2) "e" 3) "d" 4) "c" 5) "b" 6) "a"
rpop is removed from the right side of the queue
Use rpop to remove elements from the right side of the queue
# Use rpop to remove an element (listkey) from the right side of the queue rpop name # example 127.0.0.1:6379> lrange name 0 -1 1) "f" 2) "e" 3) "d" 4) "c" 5) "b" 6) "a" 127.0.0.1:6379> rpop name "a" 127.0.0.1:6379> lrange name 0 -1 1) "f" 2) "e" 3) "d" 4) "c" 5) "b" # Use rpop to remove n elements (listkey) (Num) from the right side of the queue rpop name 3 # example 127.0.0.1:6379> rpop name 3 1) "b" 2) "c" 3) "d" 127.0.0.1:6379> lrange name 0 -1 1) "f" 2) "e"
lindex gets a value of the list
Use lindex to obtain the value of a subscript of the key
# Use lindex to obtain the value of a subscript of the key lindex (listkey) (index) lindex name 0
llen get list length
Get the list length using len
# Use len to obtain the list length len (listkey) llen name
lrem removes the specified value
Use lrem to remove the specified key value | take off function
# Use lrem to remove count specified values lrem (listkey) (count) (value) lrem name 1 a # example 127.0.0.1:6379> lrem name 2 a (integer) 2
ltrim trim list
Use ltrim to trim the elements from n to m
# Use ltrim to build elements from n to m to intercept content ltrim (listkey) (start) (stop) ltrim name 2 5 # example 127.0.0.1:6379> lpush name a b c d e f g h i j k (integer) 11 127.0.0.1:6379> ltrim name 1 5 OK 127.0.0.1:6379> lrange name 0 -1 1) "j" 2) "i" 3) "h" 4) "g" 5) "f"
rpoplpush deletes the last element and appends it to another list
Use rpop lpush to delete the last element and append it to another list
# Use rpop lpush to delete one source, and then put it into another destination rpoplush list mylist # example 127.0.0.1:6379> lrange list 0 -1 1) "1" 2) "2" 3) "3" 4) "4" 127.0.0.1:6379> lrange mylist 0 -1 1) "5" 127.0.0.1:6379> rpoplpush list mylist "4" 127.0.0.1:6379> lrange list 0 -1 1) "1" 2) "2" 3) "3" 127.0.0.1:6379> lrange mylist 0 -1 1) "4" 2) "5"
Exists determines whether the list exists
Use exists to determine whether the list exists
# Use exists to determine whether there is exists (listkey) in the list exists list # example 127.0.0.1:6379> exists list (integer) 0 127.0.0.1:6379> lpush list a b c d (integer) 4 127.0.0.1:6379> exists list (integer) 1
lset modifies the value of the specified subscript in the list
Use lset to modify the value of the specified subscript
# Use lset to modify the value of the specified subscript lset (listkey) (index) (element) lset list 1 update # example 127.0.0.1:6379> lrange list 0 -1 1) "d" 2) "c" 3) "b" 4) "a" 127.0.0.1:6379> lset list 1 update OK 127.0.0.1:6379> lrange list 0 -1 1) "d" 2) "update" 3) "b" 4) "a"
linsert inserts before and after the specified keyword
Use linsert to insert a new value before and after the specified keyword
# Use linsert to insert a value linsert (listkey) (before|after) (pivot keyword) (element) linsert list before hello nihao # example 127.0.0.1:6379> lrange list 0 -1 1) "world" 2) "hello" 127.0.0.1:6379> linsert list before hello nihao (integer) 3 127.0.0.1:6379> lrange list 0 -1 1) "world" 2) "nihao" 3) "hello"
Summary
- It is actually a linked list. Before node, after, left and right can insert values
- If the key does not exist, you can create a new linked list
- If the key exists, add content
- If all value s are removed, it represents an empty linked list and does not exist!
- Inserting / changing values on both sides is the most efficient! Intermediate elements are relatively inefficient!
Message queuing! Message queue Lpush Rpop, stack Lpush Rpop!
Set
Values in Set cannot be duplicated
Set law
All commands start with s
sadd add set set
Add elements to the Set collection using sadd
# Use sadd to add elements to the Set sadd (setkey) (element1) (element2) sadd list hello world # example 127.0.0.1:6379> sadd list hello world (integer) 2 127.0.0.1:6379> smembers list 1) "world" 2) "hello"
Smenbers view set set
Use smember to view the set collection
# Use smember to view the set smember (setkey) smember list # example 127.0.0.1:6379> smembers list 1) "world" 2) "hello"
sismember to see if value is a member of the collection
Use sismember to see if an element is a member of a collection
# Use sismember to check whether it is a collection member (sismember (setkey) (element) sismember list hello # example 127.0.0.1:6379> smembers list 1) "world" 2) "hello" 127.0.0.1:6379> sismember list hello (integer) 1
scard view collection size
Use scard to view the collection size
# Use scard to view the collection size (setkey) scard list # example 127.0.0.1:6379> scard list (integer) 2
srem deletes an element of a collection
Use srem to delete an element of the collection
# Use srem to remove an element of the set srem (setkey) (element) srem list hello # example 127.0.0.1:6379> srem list hello (integer) 1 127.0.0.1:6379> smembers list 1) "world"
srandmember randomly gets the values in the collection
Use srandmember to randomly get the values in the collection
# Use srandmember to randomly obtain the value srandmember (setkey) [count] in the collection srandmember list # example 127.0.0.1:6379> smembers list 1) "nihao" 2) "world" 3) "hello" 127.0.0.1:6379> srandmember list "world" 127.0.0.1:6379> srandmember list "nihao"
spop randomly removes elements
Removing elements randomly using spop
# Use spop to randomly remove the element spop (setkey) [count] spop list # example 127.0.0.1:6379> spop list "world" 127.0.0.1:6379> smembers list 1) "hello" 2) "nihao"
smove moves the specified element
Use smove to move the specified element from one set to another (if not, one will be created)
# Use smove to move the specified element from set1 to set2 smove (sourceList) (destinaionList) (member) smove list1 list2 whz
Platform functions (Union)
Numeric collection class:
- Difference set
Difference set: different elements in two sets
# Use sdiff to get different values in multiple collections sdiff (list1) (list2) sdiff list1 list2 ...
- Union (common concern, common hobby, second time friend)
Union: an element common to two different sets
# Use sunion to get the union of multiple sets sunion (list1) (list2) sunion list1 list2 ...
- intersection
Intersection: the same element in two different sets
# Use sinter to get the same value in multiple sets sinter (list1) (list2) sinter list1 list2 ...
Hash (hash Map)
Map set is in the form of key value, but it is a map set object. Its essence is not much different from String type
More suitable for object storage
Hash law
All commands begin with h
hset insert hash fields and values
Use hset to insert the field names and values in the hashMap
# Use hset to insert the field name field and value of the key hset (key) (field) (value) hset hashmap name zhangsan # example 127.0.0.1:6379> hset hashmap name zhangsan age 9 (integer) 2 127.0.0.1:6379> hget hashmap name "zhangsan" 127.0.0.1:6379> hget hashmap age "9"
hget gets the value of the hash field
Use hget to obtain the value of a field in the hashMap
# Use hget to get the value of a field in hashmap hget hashmap name # example 127.0.0.1:6379> hget hashmap age "9"
hmset inserts multiple hash fields and values
Use hmset to insert the field names and values in the hashMap
# Insert the field name field and value of the key using hmset hmset (key) (field) (value) hmset hash1 name zhangsan age 1 # example 127.0.0.1:6379> hmset hashmap name zhangsan age 9 (integer) 2 127.0.0.1:6379> hget hashmap name "zhangsan" 127.0.0.1:6379> hget hashmap age "9"
hmget gets the values of multiple hash fields
Use hmget to get the field values of multiple hashmaps
# Get the field values of multiple hashmaps using hmget (key) (field1) (field2) hmget hashmap name age # example 127.0.0.1:6379> hmget hashmap name age 1) "zhangsan" 2) "9"
hgetall gets all hash values in a key
Use hgetall to obtain all hash values in a key
# Use hgetall to obtain the values of all hashmaps in a key. hgetall (key) hgetall hashmap # example 127.0.0.1:6379> hgetall hashmap 1) "name"Field 1 2) "zhangsan"Field value 1 3) "age"Field 2 4) "9"Field value 2
hdel deletes a field in a hash
Use hdel to delete a specific field in a hashMap
# Delete a specific field in a hash using hdel hdel (key) (field1) (field2) hdel hashmap age # example 127.0.0.1:6379> hdel hashmap age (integer) 1
hlen gets the length of the hash
Get the length of the hash set using hlen
# Use hlen to obtain the length of the hash set hlen (key) hlen hashmap # example 127.0.0.1:6379> hlen hashmap (integer) 1
hexists determines whether the fields in the hash exist
Use hexists to determine whether the fields in the hash exist
# Use hexists to determine whether there are hexists (key) (field) in the field in the hash hexists hashmap name # example 127.0.0.1:6379> hexists hashmap name (integer) 1
hkeys gets all field s in all hash es
Use hkeys to get the field names in all hash es
# Use hkeys to obtain the field name hkeys (key) in all hash es hkeys hashmap # example 127.0.0.1:6379> hkeys hashmap 1) "name"
hvals gets all value field values
Use hvals to get all the value field values
# Use hvals to get all the value field values hvals (key) hvals hashmap # example 127.0.0.1:6379> hvals hashmap 1) "zhangsan"
Implementation of hincrby in auto increment / Auto decrement hash
Using hincrby to realize self increase / self decrease in hash
# Use hincrby to realize hashmap Field Auto increment hincrby (key) (field) (increment) hincrby hashmap age 3 # example 127.0.0.1:6379> hget hashmap age "0" 127.0.0.1:6379> HINCRBY hashmap age 3 (integer) 3 127.0.0.1:6379> hget hashmap age "3" # Use hincrby to realize the field subtraction of hashmap hincrby (key) (field) (increment) hincrby hashmap age -1
hsetnx no settings exist
Use hsetnx. If it does not exist, it will be set. If it exists, it will not be processed
# Use hsetnx. If it does not exist, set hsetnx (key) (field) (value) hsetnx hashmap age 9 # example 127.0.0.1:6379> hsetnx hashmap age 9 (integer) 0
Operation of object
Imitate String type
In particular, it can be used for/*Frequently changing information such as user information*/Save changes to the database
Zset (ordered set)
A value is added to set
contrast:
Set: set key1 value1
Zset:zset key1 source1 value1
zadd insert key value pair
Use zadd to insert an ordered collection, and the flag is used for sorting
# Insert Zset ordered set zadd (key) (score flag) (member) zadd list 1 one # example 127.0.0.1:6379> zadd list 1 one (integer) 1 127.0.0.1:6379> zadd list 2 two (integer) 1 127.0.0.1:6379> ZRange list 0 -1 1) "one" 2) "two"
zrange read zset
Use zrange to read ordered collections
# Read the ordered set zrange (key) (start) (stop) zrange list 0 -1
zrangebyscore is sorted by ID from small to large
Use zrangebyscore to sort by ID from small to large
# From infinitely small row to infinitely large (inf) zrangebyscore (key) (min) (max) by ID zrangebyscore list -inf +inf # example 127.0.0.1:6379> ZRANGEBYSCORE list -inf +inf 1) "one" 2) "two" # Add the parameter zrangebyscore (key) (min) (max) [WithCores] from infinitely small to infinitely large (inf) according to the identification ZRANGEBYSCORE list -inf +inf withscores # example 127.0.0.1:6379> ZRANGEBYSCORE list -inf +inf withscores 1) "one" 2) "1" 3) "two" 4) "2"
zrevrange is sorted by ID from large to small
Use zrevrange to sort IDs from large to small
# From infinity to infinity zrevrange (key) (max) (min) zrevrange list 0 -1 # example 127.0.0.1:6379> ZREVRANGE list 0 -1 1) "four" 2) "three" 3) "two" 4) "one"
zrem remove elements from identity
Use zrem to remove elements from the identity
# Remove element zrem (key) (member) from ordered set zrem list age # example 127.0.0.1:6379> zrem list one (integer) 1
zcard gets the number of in the set
Use zcard to get the number of in the collection
# Use zcard to get the number of sets (key) zcard list
zcount gets the number of elements in the range
Use zcount to get the number of elements within the identifier range
# Use zcount to obtain the number of elements within the identifier range zcount (key) (min) (max) zcount list 2 4 # example 127.0.0.1:6379> zcount list 2 4 (integer) 3
Case thinking
- set sort
Store class grade sheet and payroll sorting
- Weight sorting
Ordinary message-1 important message-2
- Ranking List
9. Three special data types
geospatial geographic location
Friend positioning | nearby people | taxi distance calculation
There are only six commands
geoadd add add geographic location
Parameter (longitude latitude city)
Rules:
- The effective latitude is from - 85 degrees to + 85 degrees
- The effective longitude is from - 180 degrees to + 180 degrees
# Two levels cannot be added directly. They are usually imported through java programs # geoadd (key) (longitude) (latitude) (city) geoadd china:city 121.47 31.34 shanghai
geopos gets the longitude and latitude of the specified city
Get current positioning (coordinate value)
# geopos (key) (city) geopos china:city shanghai
geodist measured distance
The distance between two people
Company:
- m is the meter
- km means kilometers
- mi means miles
- ft stands for feet
# geodist (key) (city 1) (city 2) [m|km|mi|ft] geodist china:city chongqing xian km
georadius takes the given latitude and longitude as the center to find out the elements of a certain radius
people nearby
# georadius (key) (longitude) (latitude) (radius) [parameter] georadius china:city 114 38 1000 km
Get the specified quantity
# georadius (key) (longitude) (latitude) (radius) [parameter] [count] [num] # Find three georadius china:city 114 38 1000 km count 3
Geordiusbymember takes a given city as the center and finds out the elements of a certain radius
Nearby cities
# Geordiusbymember (key) (city) (radius) [parameters] [count] [num] # Find out 10 cities near Beijing georadiusbymember china:city beijing 10 km count 10
geohash returns a hash representation of one or more strings
This command returns an 11 character Geohash string
# Convert two-dimensional latitude and longitude into one-dimensional string. The closer the two characters are, the closer the distance is 127.0.0.1:6379> GEOHASH china:city nanjing shanghai 1) "ws14f5h28w0" 2) "wtw6k17b8p0"
Implementation principle of bottom layer
In fact, it is a Zset ordered set, so we can use the * * * Zset command to operate geo***
type china:city =>zset
So you can use the zset command to perform other operations
Hyperloglog (cardinality)
What is cardinality?
---- > non repeating elements
A {1,3,5,7,9,7}
B {1,3,5,7,9}
=>
base=5,Acceptable error
brief introduction
redis hyperloglog data structure:
(if fault tolerance is allowed, the error rate is 0.81%)
It is mainly used as an algorithm for * * cardinality statistics * *. Advantages: it occupies fixed memory. 2 ^ 64 different element technologies only need to waste 12kb of memory!
Application scenario
Page views (a person visits the website many times, but it is still a person)
pfadd new cardinality key
Count non duplicate key content fields
# Count non duplicate key fields pfadd key (element1) (element2) PFADD mumber a b c d d d e f f g h i k # example 127.0.0.1:6379> PFADD mumber a b c d d d e f f g h i k (integer) 1
pfcount statistics base quantity
Count the number of cardinal value s in a group
# Count the number of cardinal value s in a group pfcount (key) pfcount mumber # example 127.0.0.1:6379> PFCOUNT mumber (integer) 10
pfmerge merge multi group cardinality
Merge multiple cardinality groups = = Union
# Merge multiple cardinality groups pfmerge (destkey) (sourcekey1) (sourcekey2) pfmerge newKey key1 key2 # example 127.0.0.1:6379> PFADD mumber1 a b s r g h j i p f g h k k l (integer) 1 127.0.0.1:6379> PFMERGE newKey mumber mumber1 OK 127.0.0.1:6379> pfcount newKey (integer) 15
essence
String type
127.0.0.1:6379> type mumber string
Bitmap (bitmap)
Bit storage 0 | 1
Statistics of user information, active | inactive
Login | not logged in
Punch in | not punch in
bitmap can be used as long as it is in both States
Data structures are recorded by operating binary bits, non-0 is 1
365 days = 365bit=46 bytes 1 byte = 8 bits
Use bitmap to store seven day clock outs
setbit adds bitmap data
# setbit (key) (record) (binary bit) 127.0.0.1:6379> setbit daysign 0 1 (integer) 0 127.0.0.1:6379> setbit daysign 1 0 (integer) 0 127.0.0.1:6379> setbit daysign 2 1 (integer) 0 127.0.0.1:6379> setbit daysign 3 1 (integer) 0 127.0.0.1:6379> setbit daysign 4 1 (integer) 0 127.0.0.1:6379> setbit daysign 5 0 (integer) 0 127.0.0.1:6379> setbit daysign 6 0 (integer) 0
getbit get bitmap data
# getbit (key) (record) # Check whether you punch in one day 127.0.0.1:6379> getbit daysign 6 (integer) 0
biycount counts the number of bitmaps
# bitcount (key) [start] [end] # I've clocked in for four days 127.0.0.1:6379> bitcount daysign (integer) 4
10. Services
Essence (often asked in interview)
-----queue=Join the team+implement set set set -----
A set of commands: a set of commands is executed in one piece. All commands in a transaction will be serialized and executed in order during the execution of the transaction.
MySQL transaction - ACID
It has four features, namely * atomicity, consistency, isolation and persistence, which is referred to as the ACID * feature of * * transaction**
Atomicity
A group of things either succeed or fail at the same time.
Redis transaction
-
Redis: atomicity is not guaranteed. It is sequential, one-time and exclusive
-
Redis transactions do not have the concept of isolation level. They are not executed when joining the queue. They will only be executed when issuing the execution command!
Transaction execution:
- Open transaction (multi)
- Order to join the team
- Execute transaction (exec)
Normal execution of transactions
# Open transaction 127.0.0.1:6379> multi OK # Order to join the team 127.0.0.1:6379(TX)> set k1 v1 QUEUED 127.0.0.1:6379(TX)> set k2 v2 QUEUED 127.0.0.1:6379(TX)> get k2 QUEUED 127.0.0.1:6379(TX)> set k3 v3 QUEUED # Execute transaction 127.0.0.1:6379(TX)> exec 1) OK 2) OK 3) "v2" 4) OK
Abandon transaction
# Open transaction 127.0.0.1:6379> multi OK # Order to join the team 127.0.0.1:6379(TX)> set k1 v1 QUEUED 127.0.0.1:6379(TX)> set k2 v2 QUEUED # Abandon transaction 127.0.0.1:6379(TX)> DISCARD OK # None of the commands in the transaction queue will be executed 127.0.0.1:6379> get k2 (nil)
error
-
Compiled exception (code problem! Command error)
- all commands in the transaction will not be executed
-
Runtime exception (1 / 0) (Syntax in transaction queue)
- when executing a command, other commands can be executed
Monitor Watch monitor
Pessimistic lock
Pessimistic, lock and unlock at any time
Optimistic lock
Optimistic and not locked. When updating the data, judge whether someone has modified the data during this period
MySQL optimistic lock operation:
- Get version
- Compare version when updating
Redis optimistic lock monitoring test
Normal execution successful
127.0.0.1:6379(TX)> decrby money 20 QUEUED 127.0.0.1:6379(TX)> incrby money 20 QUEUED 127.0.0.1:6379(TX)> exec 1) (integer) 80 2) (integer) 100
Thread execution failed after being modified by queue jumping
Return nil value
resolvent:
# Unlock unwatch. If the transaction fails, unlock it first # Lock the watch money again, obtain a new watch, and monitor again # Unlock 127.0.0.1:6379> unwatch OK # Add optimistic lock 127.0.0.1:6379> watch money OK 127.0.0.1:6379> multi OK 127.0.0.1:6379(TX)> decrby money 20 QUEUED 127.0.0.1:6379(TX)> incrby money 20 QUEUED # Check whether the monitored value changes 127.0.0.1:6379(TX)> exec 1) (integer) 80 2) (integer) 100
Redis's optimistic lock operation is to use the watch
11.Jedis
Jedis uses Java to operate redis
What is Jedis?
Jedis is a Java connection development tool officially recommended by Redis and a Java Redis middleware. If you want to use java to operate Redis, you must be very familiar with jedis.
Know what it is and why
actual combat
Import pom dependencies
<dependencies>
<!--jedis Correlation dependency-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
</dependencies>
Coding test
- Connect to database
- Operation command
- Disconnect
public class test {
public static void main(String[] args) {
//1. new a Jedis object
Jedis jedis = new Jedis("127.0.0.1",6379);
//2. The jedis command is all the commands we learned before
String ping = jedis.ping();
System.out.println(ping);
//3. Release the connection
if(jedis!=null){
jedis.close();
}
}
}
--------------------------------------------------------------------------------------------
=>PONG/*success*/
affair
public class test {
public static void main(String[] args) {
//1. new a Jedis object
Jedis jedis = new Jedis("127.0.0.1",6379);
//2. Start transaction
Transaction multi = jedis.multi();
try{
multi.set("user","zhangsan");
multi.get("user");
multi.exec();
System.out.println(jedis.get("user"));
}catch(Exception e){
multi.discard();
e.printStackTrace();
}finally{
//3. Release the connection
jedis.close();
}
}
}
--------------------------------------------------------------------------------------------
=>zhangsan/*success*/
12. Spring boot integrates redis
SpringBoot operation data: * * SpringData ** (jpa,jdbc,mongodb,redis)
SpringData
Projects as famous as SpringBoot

Import dependency
<!--operation redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
Deep into the bottom
<dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-redis</artifactId> <version>2.3.6.RELEASE</version> <scope>compile</scope> </dependency> <dependency> <groupId>io.lettuce</groupId> <artifactId>lettuce-core</artifactId> <version>5.3.5.RELEASE</version> <scope>compile</scope> </dependency>
In springboot 2 After 0, the original jedis is replaced by lettuce
Difference: jedis letture
Jedis: using direct connection and multi thread operation is unsafe. If you want to avoid insecurity, use jedis pool connection pool
Leture: with netty, instances can be shared among multiple threads. There is no thread insecurity. It has high performance and can reduce thread data
Configuration class
All configuration classes of SpringBoot have an automatic configuration class RedisAutoConfiguration
Automatic configuration classes will bind a properties configuration file RedisProperties
Source code analysis:
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(RedisOperations.class)
@EnableConfigurationProperties(RedisProperties.class)
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
@Bean
/*We can define a redisTemplate to replace the default one!*/
@ConditionalOnMissingBean(name = "redisTemplate")
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {
//The default RedisTemplate does not have too many settings. redis objects need to be serialized
//The nio asynchronous with netty needs serialization in particular
//Both generic types are object types. We need to cast < string, Object > for subsequent use
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean
/*Because String types are commonly used, they can be used separately. You can directly use the default*/
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
}
Configure properties
# redis configuration spring.redis.host=127.0.0.1 spring.redis.port=6379
test
opsForValue(): similar to String
opsForList(): similar to List
...
// Get redis connection object RedisConnection connection = redisTemplate.getConnectionFactory().getConnection(); connection.flushDb();
@Autowired
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
redisTemplate.opsForValue().set("name","lisi");
System.out.println(redisTemplate.opsForValue().get("name"));
}
--------------------------------------------------------------------------------------------
=>lisi(success)
Chinese garbled code problem
jdk serialization is used by default. You need to define a JSON serialization yourself
The solution is in redis Configuration resolution in conf
13.Redis configuration Conf detailed explanation
!!! All objects need to be serialized!!!
In the enterprise, all our pojo classes will be serialized! SpringBoot!
User.java
@Data
@AllArgsConstructor
@NoArgsConstructor
@Component
public class User implements Serializable {
private int uId;
private String name;
}
RedisConfig.java
@Configuration
public class RedisConfig {
//Write your own RedisTemplate
@Bean
//Warning suppressor
@SuppressWarnings("all")
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
//It is convenient for self-development. Generally, use < string, Object >
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
//Configure the specific JSON serialization method
Jackson2JsonRedisSerializer<Object> objectJackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<Object>(Object.class);
ObjectMapper objectMapper=new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
objectJackson2JsonRedisSerializer.setObjectMapper(objectMapper);
//Serialization of String
StringRedisSerializer stringRedisSerializer=new StringRedisSerializer();
//The key is serialized by String
template.setKeySerializer(stringRedisSerializer);
//hash adopts String serialization
template.setHashKeySerializer(stringRedisSerializer);
//value is serialized by jackson
template.setValueSerializer(objectJackson2JsonRedisSerializer);
//The value of hash is serialized by jackson
template.setHashValueSerializer(objectJackson2JsonRedisSerializer);
template.afterPropertiesSet();
return template;
}
}
Test.java
@Autowired
//@Qualifier identifies which bean it automatically injects
@Qualifier("redisTemplate")/*It is used to view the redisTemplate configured by yourself*/
private RedisTemplate redisTemplate;
@Test
void contextLoads() {
User user=new User();
user.setName("Zhang San");
user.setUId(10);
redisTemplate.opsForValue().set("user",user);
System.out.println(redisTemplate.opsForValue().get("user"));
}
--------------------------------------------------------------------------------------------
=>User(uId=10, name=Zhang San)
RedisUtils.java
Packaged RedisUtils are generally used in actual enterprise development
@Component
public final class RedisUtils {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// =============================common============================
/**
* Specify cache expiration time
*
* @param key key
* @param time Time (seconds)
*/
public boolean expire(String key, long time) {
try {
if (time > 0) {
redisTemplate.expire(key, time, TimeUnit.SECONDS);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* Get expiration time according to key
*
* @param key Key cannot be null
* @return Time (seconds) returns 0, which means it is permanently valid
*/
public long getExpire(String key) {
return redisTemplate.getExpire(key, TimeUnit.SECONDS);
}
/**
* Determine whether the key exists
*
* @param key key
* @return true Exists false does not exist
*/
public boolean hasKey(String key) {
try {
return redisTemplate.hasKey(key);
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* Delete cache
*
* @param key One or more values can be passed
*/
@SuppressWarnings("unchecked")
public void del(String... key) {
if (key != null && key.length > 0) {
if (key.length == 1) {
redisTemplate.delete(key[0]);
} else {
redisTemplate.delete(CollectionUtils.arrayToList(key));
}
}
}
// ============================String=============================
/**
* Normal cache fetch
*
* @param key key
* @return value
*/
public Object get(String key) {
return key == null ? null : redisTemplate.opsForValue().get(key);
}
/**
* Normal cache put
*
* @param key key
* @param value value
* @return true Success false failure
*/
public boolean set(String key, Object value) {
try {
redisTemplate.opsForValue().set(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* Normal cache put in and set time
*
* @param key key
* @param value value
* @param time Time (seconds) time must be greater than 0. If time is less than or equal to 0, the infinite period will be set
* @return true Success false failure
*/
public boolean set(String key, Object value, long time) {
try {
if (time > 0) {
redisTemplate.opsForValue().set(key, value, time, TimeUnit.SECONDS);
} else {
set(key, value);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* Increasing
*
* @param key key
* @param delta How many to add (greater than 0)
*/
public long incr(String key, long delta) {
if (delta < 0) {
throw new RuntimeException("The increment factor must be greater than 0");
}
return redisTemplate.opsForValue().increment(key, delta);
}
/**
* Diminishing
*
* @param key key
* @param delta How many to reduce (less than 0)
*/
public long decr(String key, long delta) {
if (delta < 0) {
throw new RuntimeException("Decrement factor must be greater than 0");
}
return redisTemplate.opsForValue().increment(key, -delta);
}
// ================================Map=================================
/**
* HashGet
*
* @param key Key cannot be null
* @param item Item cannot be null
*/
public Object hget(String key, String item) {
return redisTemplate.opsForHash().get(key, item);
}
/**
* Get all key values corresponding to hashKey
*
* @param key key
* @return Corresponding multiple key values
*/
public Map<Object, Object> hmget(String key) {
return redisTemplate.opsForHash().entries(key);
}
/**
* HashSet
*
* @param key key
* @param map Corresponding to multiple key values
*/
public boolean hmset(String key, Map<String, Object> map) {
try {
redisTemplate.opsForHash().putAll(key, map);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* HashSet And set the time
*
* @param key key
* @param map Corresponding to multiple key values
* @param time Time (seconds)
* @return true Success false failure
*/
public boolean hmset(String key, Map<String, Object> map, long time) {
try {
redisTemplate.opsForHash().putAll(key, map);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* Put data into a hash table. If it does not exist, it will be created
*
* @param key key
* @param item term
* @param value value
* @return true Success false failure
*/
public boolean hset(String key, String item, Object value) {
try {
redisTemplate.opsForHash().put(key, item, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* Put data into a hash table. If it does not exist, it will be created
*
* @param key key
* @param item term
* @param value value
* @param time Time (seconds): Note: if the existing hash table has time, the original time will be replaced here
* @return true Success false failure
*/
public boolean hset(String key, String item, Object value, long time) {
try {
redisTemplate.opsForHash().put(key, item, value);
if (time > 0) {
expire(key, time);
}
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* Delete values in hash table
*
* @param key Key cannot be null
* @param item Item can make multiple non null able
*/
public void hdel(String key, Object... item) {
redisTemplate.opsForHash().delete(key, item);
}
/**
* Judge whether there is the value of this item in the hash table
*
* @param key Key cannot be null
* @param item Item cannot be null
* @return true Exists false does not exist
*/
public boolean hHasKey(String key, String item) {
return redisTemplate.opsForHash().hasKey(key, item);
}
/**
* hash If increment does not exist, it will create one and return the added value
*
* @param key key
* @param item term
* @param by How many to add (greater than 0)
*/
public double hincr(String key, String item, double by) {
return redisTemplate.opsForHash().increment(key, item, by);
}
/**
* hash Diminishing
*
* @param key key
* @param item term
* @param by To reduce (less than 0)
*/
public double hdecr(String key, String item, double by) {
return redisTemplate.opsForHash().increment(key, item, -by);
}
// ============================set=============================
/**
* Get all the values in the Set according to the key
*
* @param key key
*/
public Set<Object> sGet(String key) {
try {
return redisTemplate.opsForSet().members(key);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* Query from a set according to value whether it exists
*
* @param key key
* @param value value
* @return true Exists false does not exist
*/
public boolean sHasKey(String key, Object value) {
try {
return redisTemplate.opsForSet().isMember(key, value);
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* Put data into set cache
*
* @param key key
* @param values Values can be multiple
* @return Number of successful
*/
public long sSet(String key, Object... values) {
try {
return redisTemplate.opsForSet().add(key, values);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* Put set data into cache
*
* @param key key
* @param time Time (seconds)
* @param values Values can be multiple
* @return Number of successful
*/
public long sSetAndTime(String key, long time, Object... values) {
try {
Long count = redisTemplate.opsForSet().add(key, values);
if (time > 0)
expire(key, time);
return count;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* Gets the length of the set cache
*
* @param key key
*/
public long sGetSetSize(String key) {
try {
return redisTemplate.opsForSet().size(key);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* Remove with value
*
* @param key key
* @param values Values can be multiple
* @return Number of removed
*/
public long setRemove(String key, Object... values) {
try {
Long count = redisTemplate.opsForSet().remove(key, values);
return count;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
// ===============================list=================================
/**
* Get the contents of the list cache
*
* @param key key
* @param start start
* @param end End 0 to - 1 represent all values
*/
public List<Object> lGet(String key, long start, long end) {
try {
return redisTemplate.opsForList().range(key, start, end);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* Gets the length of the list cache
*
* @param key key
*/
public long lGetListSize(String key) {
try {
return redisTemplate.opsForList().size(key);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
/**
* Get the value in the list through the index
*
* @param key key
* @param index When index index > = 0, 0 header, 1 second element, and so on; When index < 0, - 1, footer, - 2, the penultimate element, and so on
*/
public Object lGetIndex(String key, long index) {
try {
return redisTemplate.opsForList().index(key, index);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* Put the list into the cache
*
* @param key key
* @param value value
*/
public boolean lSet(String key, Object value) {
try {
redisTemplate.opsForList().rightPush(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* Put list into cache
*
* @param key key
* @param value value
* @param time Time (seconds)
*/
public boolean lSet(String key, Object value, long time) {
try {
redisTemplate.opsForList().rightPush(key, value);
if (time > 0)
expire(key, time);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* Put list into cache
*
* @param key key
* @param value value
* @return
*/
public boolean lSet(String key, List<Object> value) {
try {
redisTemplate.opsForList().rightPushAll(key, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* Put list into cache
*
* @param key key
* @param value value
* @param time Time (seconds)
* @return
*/
public boolean lSet(String key, List<Object> value, long time) {
try {
redisTemplate.opsForList().rightPushAll(key, value);
if (time > 0)
expire(key, time);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* Modify a piece of data in the list according to the index
*
* @param key key
* @param index Indexes
* @param value value
* @return
*/
public boolean lUpdateIndex(String key, long index, Object value) {
try {
redisTemplate.opsForList().set(key, index, value);
return true;
} catch (Exception e) {
e.printStackTrace();
return false;
}
}
/**
* Remove N values as value
*
* @param key key
* @param count How many are removed
* @param value value
* @return Number of removed
*/
public long lRemove(String key, long count, Object value) {
try {
Long remove = redisTemplate.opsForList().remove(key, count, value);
return remove;
} catch (Exception e) {
e.printStackTrace();
return 0;
}
}
}
External conf configuration
Start through configuration file at startup
Company
The configuration file is not case sensitive to unit units
INCLUDE
Combine multiple configuration files, such as import
NETWORK network
bind 127.0.0.1 # Bound ip protected-mode yes # Protection mode port 6379 # The default port must be modified when clustering
GENERAL
daemonize yes # Daemon, which is enabled in the background. The default value is no pidfile /var/run/redis_6379.pid # If you are running in background mode, you need to specify a pid # journal # debug is generally used in the testing and development phases # verbose is very similar to debug. It is generally not used # notice is only used in production environments # warning very important or critical information loglevel notice logfile "" # The generated file log name. If it is empty, it is the standard output database 16 # The default number of databases is 16 by default always-show-logo yes #Always show logo
Snapshot snapshot
Persistence: the number of operations performed within a specified time will be persisted to the file rdb .aof
Redis is an in memory database. If there is no persistence, the data will lose power
# Persistence rules. After learning persistence, you will define persistence by yourself save 900 1 # If at least one key is modified within 15 minutes, we will perform the persistence operation save 300 10 # If at least 10 key s are modified within 5 minutes, we will perform the persistence operation save 60 10000 # If 10000 key s are modified within one minute (high concurrency), we will perform the persistence operation stop-writes-on-bgsave-error yes # Persistence error. Continue working? Enabled by default rdbcompression yes # Whether to compress rdb files. It is enabled by default and requires cpu resources rdbchecksum yes # Whether to check and verify errors when maintaining rdb files dir ./ # The generation directory of rdb files. The default is the current directory
REPLICATION master-slave REPLICATION can only be implemented by multiple redis later
SECURITY
requirepass 123456 # The default value is blank. Set the redis password # Or set from the command line config set requirepass "123456" # Set in redis # After executing the command, you need to log in and use auth auth 123456
Restrict CLIENTS
maxclients 10000 # Set the maximum number of clients that can connect to redis maxmemory <bytes> # redis configuration memory, maximum memory capacity setting maxmemory-policy noeviction # Processing strategy for reaching the maximum memory limit
AOF configure APPEND ONLY
appendonly no # aof is not enabled by default, and rdb is sufficient in most cases appendfilename "appendonly.aof" # Persistent aof name appendfsync everysec # sync synchronization is performed once per second, and 1s of data may be lost
14.Redis persistence
Interview and work, persistence is the focus
RDB(Redis DataBase)
Save a snapshot of the data in the memory within a specified time interval and write it to the disk. When reading, it will be directly read from the snapshot to the memory
In master-slave replication, rdb is used as standby by the slave
About persistence
Redis will separately create (fork) a sub process for persistence. It will first write the data to a temporary file. After the persistence process is completed, redis will use this temporary file to replace the last persistent file. In the whole process, the main process does not carry out any I/O operation, ensuring extremely high performance. If you are not very sensitive to the integrity of the recovered data. RDB is more efficient than AOF. Disadvantages of RDB: the last persistent data may be lost.
The file saved by rdb is dump When rdb = > * * * production environment * * *, dump rdb backup
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-G6MdiXp6-1625378600118)(image-20210526094032009.png)]
=>In addition to the time len gt h configured in the conf file to generate an rdb file, you can also forcibly generate an rdb file through flush.
Trigger mechanism
- If the save rule is satisfied, the rdb rule will be triggered
- Executing the flush command will also trigger rdb rules
- When exit exits redis, rdb rules will also be triggered
The backup will automatically generate a dump rdb
How to recover rdb files
- You only need to put the rdb file in the redis startup directory. When redis is started, dump.exe will be checked automatically rdb recovery data
- View the location to store config get dir
When all programmers use rdb, automatic (default) configuration is almost enough
advantage:
- Suitable for large-scale data recovery! dump.rdb
- Low requirements for data integrity
Disadvantages:
- Process operations that require a certain time interval
- If redis goes down unexpectedly, there will be no data for the last modification
- When fork ing a process, it will occupy memory space
AOF(Append Only File)
Record all the commands = history, and execute all the files during recovery.
What is it?
About persistence
Record the operation in the form of log. Record all instructions executed by redis (do not record the read operation). Only the file can be added, but the file cannot be changed. Redis will read the file and rebuild the data at the beginning of moving, that is, execute it again.
The file saved by aof is appendonly When aof = > production environment, aof needs to be backed up
If there is an error in the AOF file, redis cannot start up. We need to repair the AOF file. Redis check AOF -- fix appendonly aof
If the file is repaired, restart is normal
Rewrite rule description
auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb
If the aof file is larger than 64M, a new process will fork to rewrite the file.
advantage:
- Each modification is synchronized, and the file management will be better
- Synchronize data every second, and you may lose one second of data
- Never synchronized, most efficient
Disadvantages:
- Compared with data file rdb, rdb is smaller, aof is much larger than rdb, and the repair speed is slower than rdb
- aof also runs slower than rdb, using I/O operations
15.Redis realizes subscription and publishing
Redis publish / subscribe (pub/sub) is a message communication mode: the publisher (pub) sends messages and the subscriber (sub) receives messages
Redis client can subscribe to any number of channels.
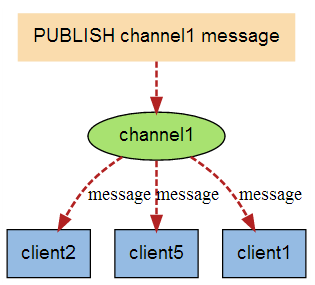
Subscribe / publish message graph
The following figure shows the relationship between channel 1 and the three clients subscribing to this channel - client2, client5 and client1:

When a new message is sent to channel 1 through the PUBLISH command, the message will be sent to the three clients subscribing to it:
Subscribe to common commands
| Serial number | Command and description |
|---|---|
| 1 | [PSUBSCRIBE pattern pattern ...] Subscribe to one or more channels that match the given pattern. |
| 2 | [PUBSUB subcommand argument [argument ...]] View subscription and publishing system status. |
| 3 | PUBLISH channel message Sends information to the specified channel. |
| 4 | [ PUNSUBSCRIBE pattern [pattern ...]] Unsubscribe from all channels in a given mode. |
| 5 | [SUBSCRIBE channel channel ...] Subscribe to information for a given channel or channels. |
| 6 | [UNSUBSCRIBE channel [channel ...]] Unsubscribe from a given channel. |
SUBSCRIBE subscription
Subscribe to information for a given channel or channels
PC1127.0.0.1:6379> SUBSCRIBE gushi # Subscribe to a channelreading messages (press Ctrl-C to quit)1) "subscribe"2) "gushi"3) (integer) 1
PUBLISH send message
Sends information to the specified channel.
PC2127.0.0.1:6379> PUBLISH gushi nihao #Send message to channel(integer) 1PC1127.0.0.1:6379> SUBSCRIBE gushiReading messages... (press Ctrl-C to quit)1) "subscribe"2) "gushi"3) (integer) 1# Received messages 1) "message"2) "gushi"3) "nihao"
principle
Redis implements PUBLISH and SUBSCRIBE functions through PUBLISH, SUBSCRIBE, PSUBSCRIBE and other commands.
After subscribing to the channel through the SUBSCRIBE command, a dictionary is maintained in the redis server. The keys of the dictionary are channels, and the values of the dictionary are a linked list, which stores all clients subscribing to the channel. The key of the SUBSCRIBE command is to add the client to the subscription linked list of a given channel.
Usage scenario
- Real time messaging system!
- Live chat! (if the channel is regarded as a chat room, the message will be displayed)
- Subscribe, follow
For slightly more complex scenarios, message oriented middleware MQ will be used.
16.Redis master-slave replication
concept
!! Read write separation!!
Master slave replication refers to copying data from one Redis server to other Redis servers. The former is the master node and the latter is the slave node.
Data replication is * * * one-way * * * and can only be from master node to Slave node. Master mainly writes, Slave mainly reads.
By default, each Redis server is the master node; A master node can have multiple slave nodes, but a slave node can only have one master node.
The main functions of master-slave replication include:
- Data redundancy: master-slave replication realizes the hot backup of data, which is a data redundancy method other than persistence.
- Fault recovery: when the master node has problems, the slave node can provide services to achieve rapid fault recovery; It is actually a kind of service redundancy.
- Load balancing: on the basis of master-slave replication, combined with read-write separation, the master node can provide write services and the slave node can provide read services (connect the Redis slave node when reading and the Redis master node when writing) to share the server load. Especially in the scenario of less writing and more reading, the read load can be shared through multiple slave nodes, It can greatly improve the concurrency of Redis server.
- High availability (cluster) basis: in addition to the above functions, master-slave replication is also the basis for sentinel and cluster. Therefore, master-slave replication is the basis of high availability.
Generally speaking, in a project using redis, it is absolutely impossible to use only one redis. The reasons are as follows:
- Structurally, a single Redis will have a single point of failure, and a server needs to handle a large load of requests.
- In terms of capacity, the memory capacity of a single Redis server is limited. Generally speaking, the maximum memory used by a single Redis server does not exceed 20G.
In the company, the real project cannot be a single machine, but must be a master-slave replication cluster
Environment configuration
Configure only the slave database, not the master database ----- redis is the master database by default
Main library
info replication # Copy and view the information of the current library# Replicationrole:master # Attribute role masterconnected_slaves:0 # Connected slave 0 Masters_ failover_ state:no-failovermaster_ replid:61cc3cc55461b71dc40d3b10b8dcf5ff6a12ef42master_ replid2:0000000000000000000000000000000000000000master_ repl_ offset:0second_ repl_ offset:-1repl_ backlog_ active:0repl_ backlog_ size:1048576repl_ backlog_ first_ byte_ offset:0repl_ backlog_ histlen:0
From library
cp redis.conf redis79.confcp redis.conf redis80.confcp redis.conf redis81.confvim redis79.conf--------------------------------------------------------------------------------------------port 6379 # The default host does not need to be changed pidfile /var/run/redis_6379.pidlogfile "6379.log" # log file# dump.rdb The files must also be the same dbfilename dump6379.rdb--------------------------------------------------------------------------------------------vim redis80.conf--------------------------------------------------------------------------------------------port 6380 # Slave 1 Port changed to 6380 pidfile /var/run/redis_6380.pid # modify pidlogfile "6380.log" # log file dbfilename dump6380.rdb--------------------------------------------------------------------------------------------vim redis81.conf--------------------------------------------------------------------------------------------port 6381 # Slave 1 Port changed to 6380 pidfile /var/run/redis_6381.pid # modify pidlogfile "6381.log" # Log file dbfilename dump6381 rdb--------------------------------------------------------------------------------------------
Copy three configuration files and modify the corresponding information:
1. port
2. pid name
3. log file name
4. rdb backup file name
Open service
redis-server kconfig/redis79.conf
redis-server kconfig/redis80.conf
redis-server kconfig/redis81.conf
View process information
ps -ef|grep redis
One master and two slaves
By default, each redis server is the primary node
Configure slave
Cluster configuration: slaveof instruction
# slaveof host port127.0.0.1:6380>slaveof 127.0.0.1 6379 # Who do you think is the boss# Check the host info replacement = > you can see how many younger brothers the slave has
The real master-slave configuration should be configured in the REPLICATION of the configuration file. In this case, it is * * * permanent * * *.
Enter redis80 Conf
# replicaof <masterip> <marsterport>replicaof 127.0.0.1 6379# If the host has a password, masterauth < master password > can be configured
details
- The host can write, and the slave can only read
- All information and data in the host will be automatically saved by the slave
- If the master-slave configured on the command line is used, it will change back to the master if restarted. As long as it changes back to the slave, the data will be written back immediately
Replication principle
After Slave is successfully started and connected to the master, it will send a sync synchronization command (there will be a full synchronization when connecting for the first time)
After receiving the command, the master starts the background save program and synchronizes all commands received by the mobile phone to modify the dataset. After the background process is executed, the master will transfer the entire data file to the slave and complete a complete synchronization.
Full copy: after receiving the database file data, the slave service saves it and loads it into memory
Incremental replication: the master continues to transmit all new collected modification commands to the slave in turn to complete synchronization
However, as long as the master is reconnected, a full synchronization (full replication) will be performed.
Layer by layer link
---------Each layer is a master node and a slave node relationship
The previous M links to the next S!
Host downtime
# Simulate host shutdown
Solve the master-slave problem caused by downtime
Manual! Under the premise of no sentinel mode, sentinel mode can automatically select the boss.
Can only "seek to usurp the throne"
So execute a slaveof command
# sloveof no one
17.Redis sentinel mode
(all company clusters now use sentinel mode)
concept
(automatically select the boss)
Mode of master-slave switching technology: when the master server is down, a slave server needs to be manually switched to the master server, which requires manual intervention, which is laborious and laborious, and the service will not be available for a period of time. This is not a recommended way. Sentinel mode is more often given priority. Redis has officially provided * * * sentinel * * * (sentinel) architecture since 2.8 to solve this problem.
principle
The background monitors whether the host fails. If it fails, it will automatically change from library to main library according to the number of votes.
Operation mode
Sentinel mode is a special mode. Firstly, Redis provides sentinel commands. Sentinel is an independent process * * *. As a process, it will run independently. The principle is that the Sentry can monitor and run multiple Redis instances by sending commands and waiting for the response of the Redis server*
[the external link image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-YjI1VuI3-1625378600120)(image-20210528222611520.png)]
A single Sentry will cause new problems if the sentry goes down, so the multi sentry mode is generally used
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-pv8qzfts-1625378600120) (image-20210528225554. PNG)]
Assuming that the primary server is down and sentinel 1 detects this result first, the system will not immediately carry out the failover process. Only sentinel 1 subjectively thinks that the primary server is unavailable, it is called "subjective offline". When the subsequent sentinels also detect that the primary server is unavailable and the number reaches a certain value, the Sentinels will vote once, and the voting will be initiated by a random sentinel, Perform failover. After the switch is successful, each sentinel will switch its monitoring from the server to the host through the publish and subscribe mode, which is called "objective offline"
test
1. Configure sentry profile
vim sentinel.conf # Sentry mode configuration-># Configure sentry, monitor, master redis name, monitor object IP, monitor object port, vote sentinel monitor myredis 127.0.0.1 6379 1 after host downtime
2. Start sentinel service
redis-sentinel kcongig/sentinel.conf
Sentinel mode
advantage:
- Sentinel cluster, based on master-slave replication, has all the advantages of master-slave replication
- The master and slave can be switched, the fault can be transferred, and the system availability is better
- Sentinel mode is the upgrade of master-slave mode, which is more robust from manual to automatic
Disadvantages:
- redis is not easy to expand. If the cluster capacity is full, online expansion is very troublesome
- The configuration of sentinel mode is actually very troublesome. There are many choices
Full configuration of sentinel mode
# port port 26379# Whether to start in the background daemonize yes# pid File path pidfile /var/run/redis-sentinel.pid# log file path logfile "/var/log/sentinel.log"# Define working directory dir /tmp# definition Redis Alias of master, IP, Ports. 2 here means that at least 2 ports are required Sentinel Think Lord Redis Hang up before you finally take the next step sentinel monitor mymaster 127.0.0.1 6379 2# If mymaster 30 If there is no response within seconds, it is considered as subjective failure sentinel down-after-milliseconds mymaster 30000# If master After re selection, other slave Nodes can be regenerated in parallel at the same time master How many synchronous data sets are there? Obviously, the greater the value, all slave The faster the overall speed of the node to complete synchronous switching, but if someone happens to be accessing these nodes at this time slave,It may cause reading failure and affect a wider range. The most conservative setting is 1. At the same time, only one machine can do this, so the others slave Can continue to serve, but all slave The process of fully completing cache update synchronization will slow down. sentinel parallel-syncs mymaster 1# This parameter specifies a time period. If the failover is not successful within this time period, the failover operation will be initiated again, in milliseconds sentinel failover-timeout mymaster 180000# Setting notification script and client reconfig script with SENTINEL SET is not allowed. sentinel deny-scripts-reconfig yes
18. Cache penetration and Solutions
Interview frequency
What is cache penetration
Concept (not found)
Cache penetration means that when no data is found in the cache (second kill), it will send requests to the persistence layer database. If a large number of requests are sent to the persistence layer database, it will cause great pressure on the database and even crash.
Solution
Bloom filter
*Interview questions
Bloom filter is a data structure that stores all possible query parameters in the form of hash. It is verified in the control layer first, and discarded if it does not meet the requirements, so as to avoid the pressure on the underlying storage system.
use
Just guide the package
Cache empty objects
When the storage layer fails to hit, the returned empty object will also be cached, and an expiration time will be set. Then accessing the data will be obtained from the cache to protect the back-end data source.
Existing problems
- If empty objects can be stored, this means that the cache needs more space to store more keys, because there may be many null keys.
- Even if the expiration time is set for a null value, there will still be inconsistency between the data of the cache layer and the storage layer for a period of time, which will have an impact on the business that needs to maintain consistency. (that is, the persistence layer has, and there are still null values cached within the expiration time)
19. Cache breakdown and Solutions
Concept (too much, cache expired)
Cache breakdown means that a key is very hot. It is constantly carrying large concurrency and accessing one point. When the key fails, the continuous large concurrency will penetrate the cache and directly request the database, like opening a hole in the barrier.
When a key expires, there are a large number of requests for concurrent access, usually hot data. It will access the database to query the latest data at the same time, and write back to the cache, which will cause the pressure on the database to increase instantaneously.
Solution
Set hotspot never expires
From the cache level, the expiration time is not set, so there will be no problem after the hot key expires.
Add mutex (setnx)
Distributed lock: ensure that each key has only one thread to query the back-end service at the same time, and other threads do not have the permission to obtain the distributed lock, so they need to wait. This method transfers the pressure of high concurrency to distributed locks, which is a great test for distributed locks.
20. Cache avalanche and Solutions
Interview frequency
concept
Cache avalanche refers to the expiration of a cache set in a certain period of time. For example, Redis goes down (power failure).
When a hotspot data expires, it will be centrally accessed to the data persistence layer, which is easy to cause the persistence layer database to crash.
Double Eleven: stop some services to ensure the availability of main services.
Solution
Redis high availability
That is, the Redis service may hang up. I set up several more Redis, one hung up and the other continued to work. In fact, it is to build a cluster.
Current limiting degradation
After the cache expires, the number of threads reading and writing to the database cache is controlled by locking or queuing. For example, for a key, only one thread is allowed to query data and write cache, while other threads wait.
Data preheating
The meaning of data heating is that before the formal deployment, I first preset access to the possible data, so that part of the data that may be accessed in large quantities will be loaded into the cache. Before the large concurrency, manually trigger the loading of different cache key s and set different expiration times to make the cache failure time as uniform as possible.
21. Summary and expansion
Development route
