Redis is an in-memory database that stores data in memory and is much faster to read and write than traditional databases that store data on disk.However, once the process exits, Redis's data will be lost.
To solve this problem, Redis provides two persistence schemes, RDB and AOF, to save in-memory data to disk and avoid data loss.
In Redis Persistent Decryption, antirez states that there are generally three common strategies for persistent operations to prevent data corruption:
- Method 1 is that the database does not care about the failure and recovers from the data backup or snapshot after the data file is damaged.Redis's RDB persistence is this way.
- Method 2 is a database that uses operation logs to record the operation behavior at each operation to restore consistency through the logs after a failure.Since the operation log is written in a sequential append, there will be no cases where the operation log cannot be recovered.Similar to Mysql's redo and undo logs, see this InnoDB Disk Files and Dropping Mechanism Article.
- Method 3 is that the database does not modify the old data, but only writes by appending, so the data itself is a log, so there will never be an unrecoverable situation of data.CouchDB is a good example of this.
RDB is the first method, which saves a point-in-time snapshot of the current Redis process's data to the storage device.
Use of RDB
RDB triggering mechanisms are divided into manual triggering using instructions and automatic triggering using redis.conf configuration.
The instructions that manually trigger Redis for RDB persistence are:
- Save, which blocks the current Redis server. Redis cannot process other commands until the RDB process is complete while executing the save command.
- bgsave, Redis executes the snapshot asynchronously in the background when the command is executed, and Redis can still respond to client requests.The specific operation is that the Redis process performs a fork operation to create a subprocess, and the RDB persistence process is the responsibility of the subprocess, which automatically ends when completed.Redis will only get blocked during fork, but generally it will only take a short time.However, if Redis has a very large amount of data, fork time will increase and memory usage will double, which requires special attention.
The default configuration for automatically triggering an RDB is as follows:
save 900 1 # Indicates that if at least one key value changes within 900 seconds, the RDB is triggered save 300 10 # Indicates that if at least 10 key s change in value within 300 seconds, the RDB is triggered save 60 10000 # Indicates that if at least 10,000 key s change in value within 60 seconds, the RDB is triggered
If Redis is not required for persistence, you can comment out all save lines to deactivate the save function, or you can deactivate persistence directly with an empty string: save'.
The Redis Server Cycle Operations function serverCron is executed by default every 100 milliseconds and is used for maintenance on running servers. One of its jobs is to check if one of the conditions set by the save option is met and, if so, execute the bgsave command.
RDB Overall Process
After understanding the basic use of RDB, we need to continue to learn more about RDB persistence.Before that, we can think about how to implement a persistence mechanism, which is a module required by many middleware.
First, the content structure of persisted files must be compact. Especially for databases, the amount of data that needs to be persisted is very large and the persisted files need to be guaranteed not to occupy too much storage.
Secondly, when persisting, the middleware should also be able to respond quickly to user requests, and the operation of persistence should minimize the impact on other middleware functions.
Finally, after all, persistence consumes performance, how to balance performance with data security, and how to configure flexibly to trigger persistence operations.
Next we'll go to the source code with these questions.
The source code in this article is from Redis 4.0, and the source code for the RDB persistence process is in the rdb.c file.A general flow is shown in the following figure.
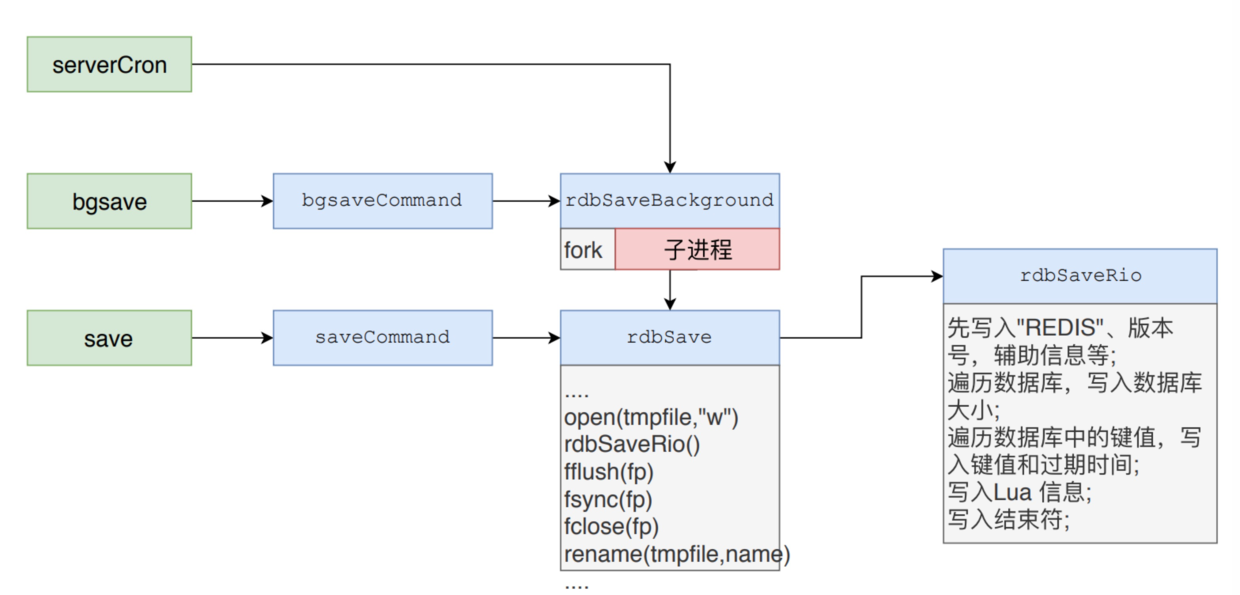
The diagram above illustrates the overall relationship among the three triggers for RDB persistence.An RDB triggered automatically by serverCron is equivalent to a process that directly calls the bgsave instruction for processing.After the bgsave process starts the child process, the save instruction's process is invoked.
Let's start with the serverCron autotrigger logic.
Automatically trigger RDB persistence
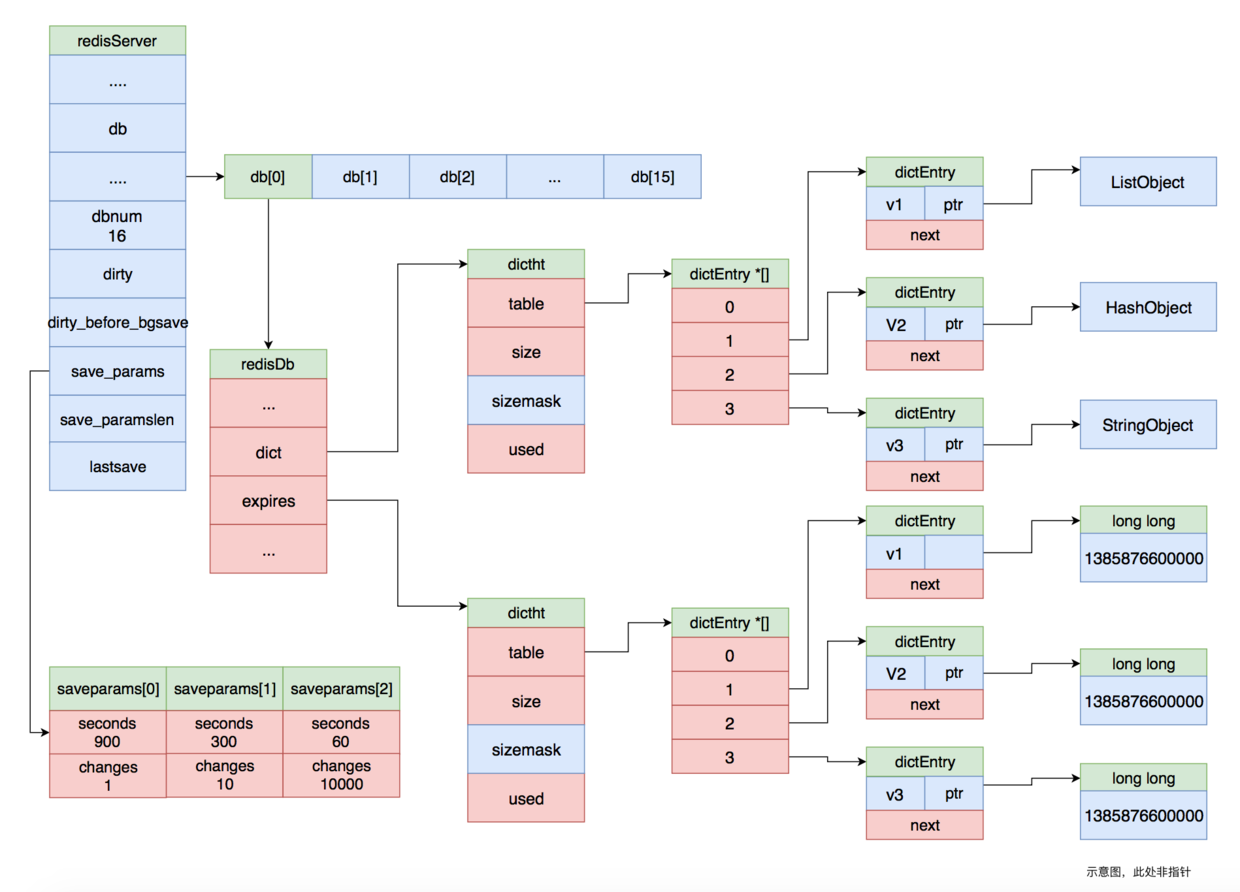
As shown in the figure above, the save_params of the redisServer structure points to an array of three values that correspond to the save configuration item in the redis.conf file.They are save 9001, save 300 10, and save 60 10000.dirty records how many key values have changed, and lastsave s records how long RDB was last persisted.
The serverCron function traverses the values of the array to check if the current Redis state meets the conditions that trigger RDB persistence, such as 900 seconds since the last RDB persistence and at least one data change.
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) { .... /* Check if a background saving or AOF rewrite in progress terminated. */ /* Determine whether background rdb or aof operations are in progress */ if (server.rdb_child_pid != -1 || server.aof_child_pid != -1 || ldbPendingChildren()) { .... } else { // Here you can confirm that the current wood has rdb or aof operations // Traverse through each rdb save condition for (j = 0; j < server.saveparamslen; j++) { struct saveparam *sp = server.saveparams+j; //The BGSAVE operation is only performed if the data save record is greater than the specified number of modifications and the time since the last save is longer than the specified time or if the last BGSAVE command was successfully executed if (server.dirty >= sp->changes && server.unixtime-server.lastsave > sp->seconds && (server.unixtime-server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY || server.lastbgsave_status == C_OK)) { //Logging serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...", sp->changes, (int)sp->seconds); rdbSaveInfo rsi, *rsiptr; rsiptr = rdbPopulateSaveInfo(&rsi); // Asynchronous save operation rdbSaveBackground(server.rdb_filename,rsiptr); break; } } } .... server.cronloops++; return 1000/server.hz; }
If the condition that triggers RDB persistence is met, serverCron calls the rdbSaveBackground function, which is the function triggered by the bgsave directive.
Subprocess background RDB persistence
When the bgsave directive is executed, Redis triggers bgsaveCommand to check the current state before calling rdbSaveBackground, the logic shown below.
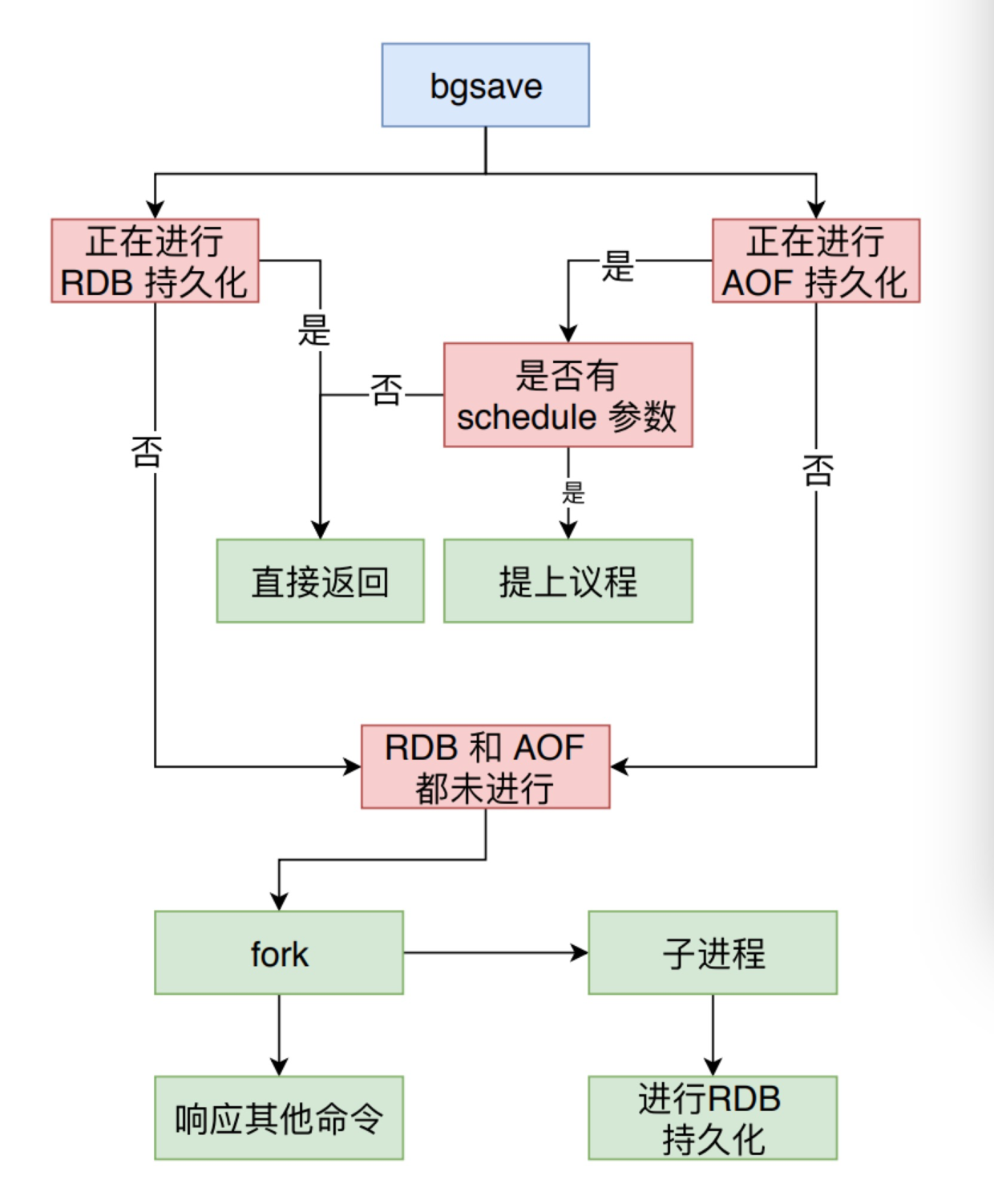
The main task of the rdbSaveBackground function is to call the fork command to generate a subprocess, and then execute the rdbSave function in the subprocess, which is the function that the save command will ultimately trigger.
int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) { pid_t childpid; long long start; // Check whether the background is performing an aof or rdb operation if (server.aof_child_pid != -1 || server.rdb_child_pid != -1) return C_ERR; // Take out the data to save the record as the last record server.dirty_before_bgsave = server.dirty; // bgsave time server.lastbgsave_try = time(NULL); start = ustime(); // fork subprocess if ((childpid = fork()) == 0) { int retval; /* Turn off socket listening inherited by child processes */ closeListeningSockets(0); // Subprocess title Modification redisSetProcTitle("redis-rdb-bgsave"); // Perform rdb write operation retval = rdbSave(filename,rsi); // After execution .... // Exit subprocess exitFromChild((retval == C_OK) ? 0 : 1); } else { /* Parent process, making fork time statistics and information records, such as rdb_save_time_start, rdb_child_pid, and rdb_child_type */ .... // rdb save start time bgsave subprocess server.rdb_save_time_start = time(NULL); server.rdb_child_pid = childpid; server.rdb_child_type = RDB_CHILD_TYPE_DISK; updateDictResizePolicy(); return C_OK; } return C_OK; /* unreached */ }
Why does Redis use child processes instead of threads for background RDB persistence?Mainly for Redis performance reasons, we know that Redis's working model for responding to requests from clients is single-process and single-threaded, which can result in competing conditions for data if a thread is started within the main process.So to avoid using locks to degrade performance, Redis chose to start a new child process, have a separate memory copy of the parent process, and perform RDB persistence on that basis.
However, it is important to note that fork takes a certain amount of time, and the parent-child processes occupy the same amount of memory. When the Redis key value is large, fork takes a long time, during which Redis is unable to respond to other commands.In addition, Redis takes up twice as much memory space.
Generate RDB files and persist to hard disk
Redis's rdbSave function is really a function for RDB persistence, and its general flow is as follows:
- First, open a temporary file.
- Call the rdbSaveRio function to write the current Redis memory information to this temporary file.
- The fflush, fsync, and fclose interfaces are then called to write the file to disk.
- rename the temporary file to a formal RDB file.
- Finally, state information such as dirty and lastsave is recorded.This status information is used when serverCron is used.
int rdbSave(char *filename, rdbSaveInfo *rsi) { char tmpfile[256]; // Current working directory char cwd[MAXPATHLEN]; FILE *fp; rio rdb; int error = 0; /* Generate tmpfile file file name temp-[pid].rdb */ snprintf(tmpfile,256,"temp-%d.rdb", (int) getpid()); /* Open File */ fp = fopen(tmpfile,"w"); ..... /* Initialize rio structure */ rioInitWithFile(&rdb,fp); if (rdbSaveRio(&rdb,&error,RDB_SAVE_NONE,rsi) == C_ERR) { errno = error; goto werr; } if (fflush(fp) == EOF) goto werr; if (fsync(fileno(fp)) == -1) goto werr; if (fclose(fp) == EOF) goto werr; /* Rename rdb file, change previous temporary name to formal rdb file name */ if (rename(tmpfile,filename) == -1) { // exception handling .... } // Write complete, print log serverLog(LL_NOTICE,"DB saved on disk"); // Clean up data to save records server.dirty = 0; // The last time the SAVE command was completed server.lastsave = time(NULL); // Last bgsave status placement succeeded server.lastbgsave_status = C_OK; return C_OK; .... }
Here is a brief explanation of the differences between fflush and fsync.Both are used to flush the cache, but at different levels.The fflush function is used on the FILE* pointer to refresh the cache data from the application-tier cache to the kernel, while the fsync function is used on the file descriptor to refresh the kernel cache to the physical device.
The exact principle of Linux IO can be referenced Chat Linux IO
Memory data to RDB file
rdbSaveRio writes data in Redis memory to a file in a relatively compact format, illustrated below.
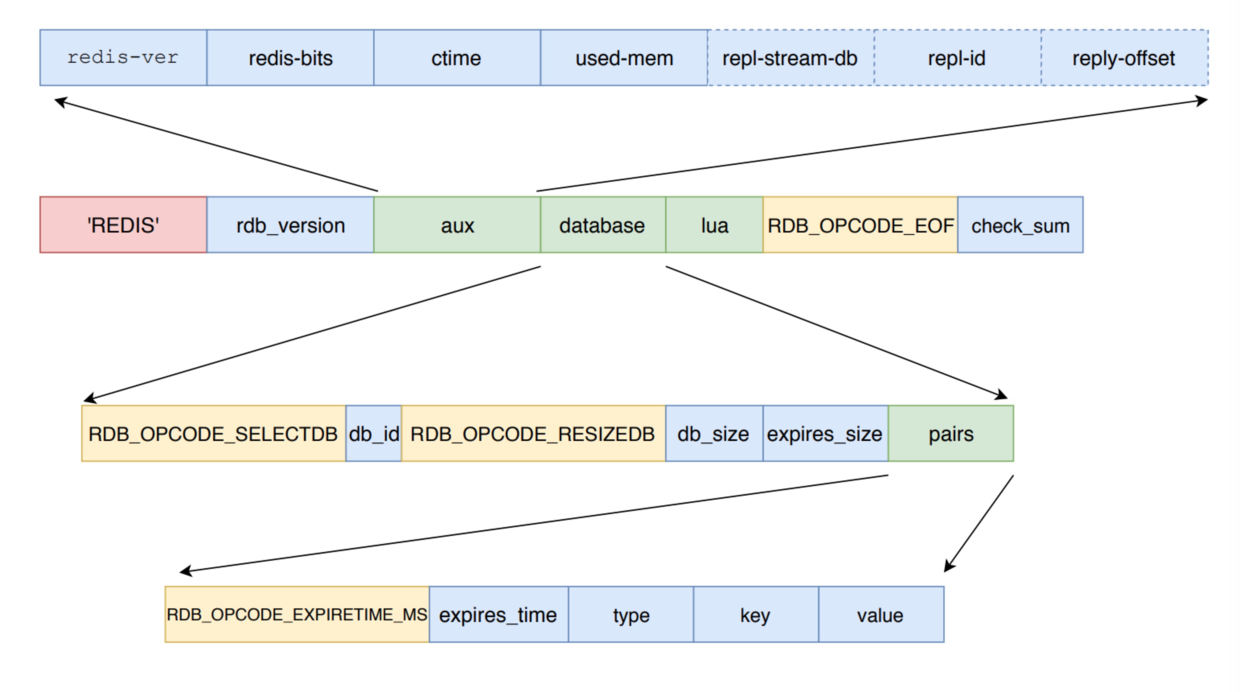
The general flow for writing the rdbSaveRio function is as follows:
- Write the REDIS magic value first, then the RDB file version (rdb_version), additional auxiliary information (aux).Auxiliary information includes Redis version, memory usage and repl-id library, repl-offset, and so on.
- rdbSaveRio then iterates through all the databases in the current Redis, writing the database information in turn.Write the RDB_OPCODE_SELECTDB identifier and database number first, then the RDB_OPCODE_RESIZEDB identifier and the number of database key values and the number of key values to be invalidated, then iterate through all key values and write them in turn.
- When a key value is written, when it has an expiration time, the RDB_OPCODE_EXPIRETIME_MS identifier and the expiration time are written first, then the identifier of the key type is written, and then the key and value are written.
- After the database information is written, Lua-related information is also written, followed by the RDB_OPCODE_EOF end identifier and check values.
int rdbSaveRio(rio *rdb, int *error, int flags, rdbSaveInfo *rsi) { snprintf(magic,sizeof(magic),"REDIS%04d",RDB_VERSION); /* 1 Write magic characters'REDIS'and RDB versions */ if (rdbWriteRaw(rdb,magic,9) == -1) goto werr; /* 2 Write auxiliary information REDIS version, server operating system digits, current time, replication information such as repl-stream-db,repl-id, repl-offset, etc.*/ if (rdbSaveInfoAuxFields(rdb,flags,rsi) == -1) goto werr; /* 3 Traverse through each database, saving database data one by one */ for (j = 0; j < server.dbnum; j++) { /* Get the database pointer address and database dictionary */ redisDb *db = server.db+j; dict *d = db->dict; /* 3.1 Start identification for writing to the database section */ if (rdbSaveType(rdb,RDB_OPCODE_SELECTDB) == -1) goto werr; /* 3.2 Write the current database number */ if (rdbSaveLen(rdb,j) == -1) goto werr; uint32_t db_size, expires_size; /* Gets the database dictionary size and expiration key dictionary size */ db_size = (dictSize(db->dict) <= UINT32_MAX) ? dictSize(db->dict) : UINT32_MAX; expires_size = (dictSize(db->expires) <= UINT32_MAX) ? dictSize(db->expires) : UINT32_MAX; /* 3.3 Write the type of data currently to be written, here RDB_OPCODE_RESIZEDB, indicating the size of the database */ if (rdbSaveType(rdb,RDB_OPCODE_RESIZEDB) == -1) goto werr; /* 3.4 Write to get database dictionary size and expiration key dictionary size */ if (rdbSaveLen(rdb,db_size) == -1) goto werr; if (rdbSaveLen(rdb,expires_size) == -1) goto werr; /* 4 Traverse key-value pairs of the current database */ while((de = dictNext(di)) != NULL) { sds keystr = dictGetKey(de); robj key, *o = dictGetVal(de); long long expire; /* Initialize key because it operates on a key string object rather than directly manipulating the string contents of the key */ initStaticStringObject(key,keystr); /* Get expired data for keys */ expire = getExpire(db,&key); /* 4.1 Save key-value pair data */ if (rdbSaveKeyValuePair(rdb,&key,o,expire) == -1) goto werr; } } /* 5 Save Lua script*/ if (rsi && dictSize(server.lua_scripts)) { di = dictGetIterator(server.lua_scripts); while((de = dictNext(di)) != NULL) { robj *body = dictGetVal(de); if (rdbSaveAuxField(rdb,"lua",3,body->ptr,sdslen(body->ptr)) == -1) goto werr; } dictReleaseIterator(di); } /* 6 Write Terminator */ if (rdbSaveType(rdb,RDB_OPCODE_EOF) == -1) goto werr; /* 7 Write CRC64 checksum */ cksum = rdb->cksum; memrev64ifbe(&cksum); if (rioWrite(rdb,&cksum,8) == 0) goto werr; return C_OK; }
When rdbSaveRio writes a key value, it calls the rdbSaveKeyValuePair function.This function writes in turn the expiration time of the key value, the type of key, the key, and the value.
int rdbSaveKeyValuePair(rio *rdb, robj *key, robj *val, long long expiretime) { /* If there is expiration information */ if (expiretime != -1) { /* Save expiration information identification */ if (rdbSaveType(rdb,RDB_OPCODE_EXPIRETIME_MS) == -1) return -1; /* Save expired specific data content */ if (rdbSaveMillisecondTime(rdb,expiretime) == -1) return -1; } /* Save type, key, value */ /* Save identification of key-value pair type */ if (rdbSaveObjectType(rdb,val) == -1) return -1; /* Save the contents of a key-value pair key */ if (rdbSaveStringObject(rdb,key) == -1) return -1; /* Save the contents of key-value pair values */ if (rdbSaveObject(rdb,val) == -1) return -1; return 1; }
Write different formats depending on the type of key, and the types and formats of the various key values are shown below.
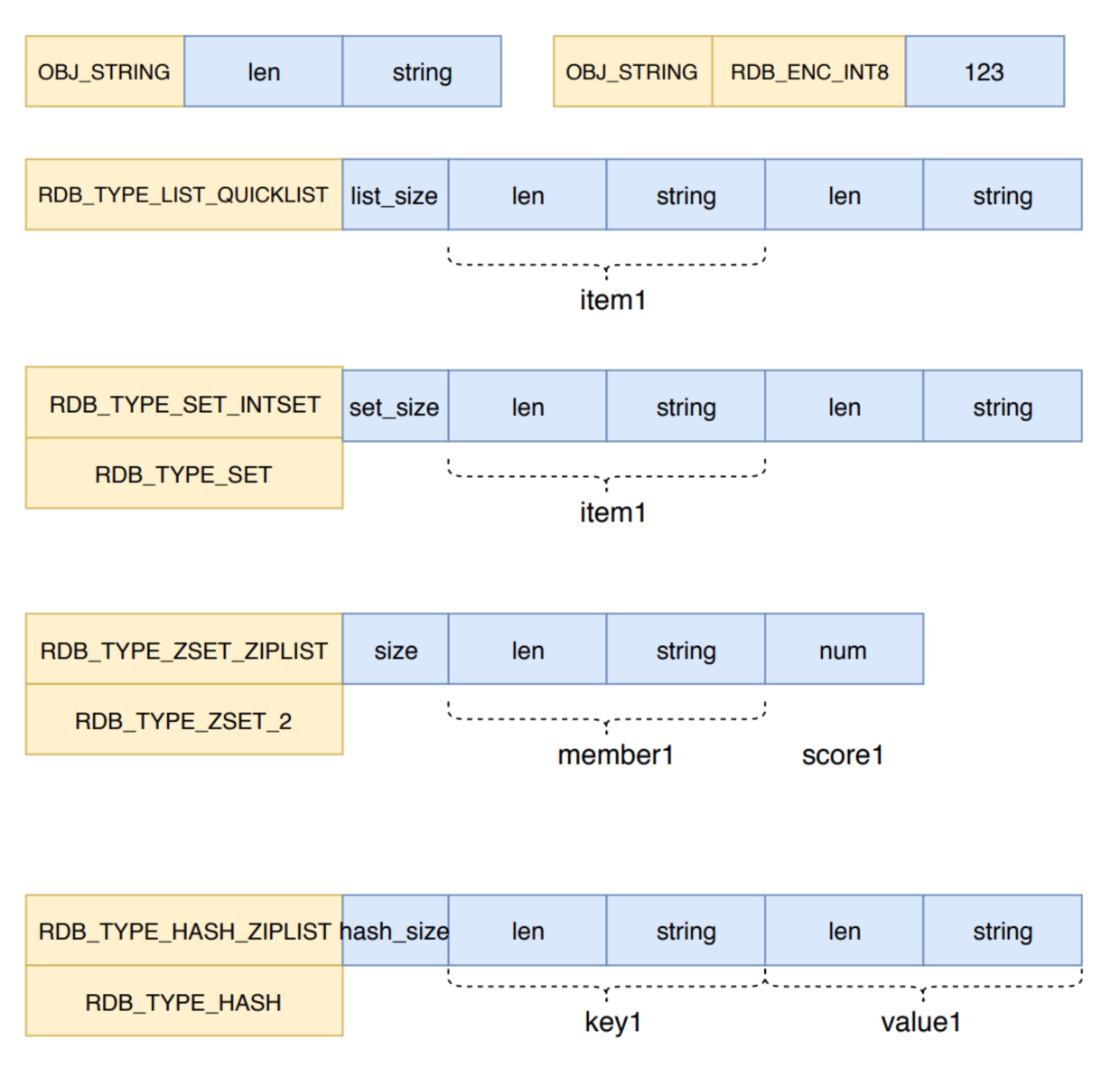
Redis has a huge object and data structure system. It uses six underlying data structures to build an object system that contains string objects, list objects, hash objects, set objects, and ordered set objects.Interested students can refer to Twelve Charts Understanding Redis's Data Structure and Object System One article.
Different data structures have different formats for RDB persistence.Let's just look at how collection objects are persisted today.
ssize_t rdbSaveObject(rio *rdb, robj *o) { ssize_t n = 0, nwritten = 0; .... } else if (o->type == OBJ_SET) { /* Save a set value */ if (o->encoding == OBJ_ENCODING_HT) { dict *set = o->ptr; // Collection Iterator dictIterator *di = dictGetIterator(set); dictEntry *de; // Write Collection Length if ((n = rdbSaveLen(rdb,dictSize(set))) == -1) return -1; nwritten += n; // Traversing through collection elements while((de = dictNext(di)) != NULL) { sds ele = dictGetKey(de); // Write as a string, because it is SET, so only Key can be written if ((n = rdbSaveRawString(rdb,(unsigned char*)ele,sdslen(ele))) == -1) return -1; nwritten += n; } dictReleaseIterator(di); } ..... return nwritten; }