Introduction to persistence
Redis is an in memory database. If the database state in memory is not saved to disk, the database state in the server will be lost once the server process exits. So redis provides persistence function!
What is persistence
The working mechanism of using permanent storage media to save data and recover the saved data at a specific time is called persistence.
Why persistence
Prevent accidental loss of data and ensure data security
What does the persistence process hold
- Save the current data state in the form of snapshot, store data results, simple storage format, and focus on data
- Save the operation process of data in the form of log and store the operation process. The storage format is complex, and the focus is on the operation process of data
- Redis has two ways of persistence
- RDB: the storage method is data (snapshot)
- AOF: stored as a procedure (log)
RDB
What is RDB
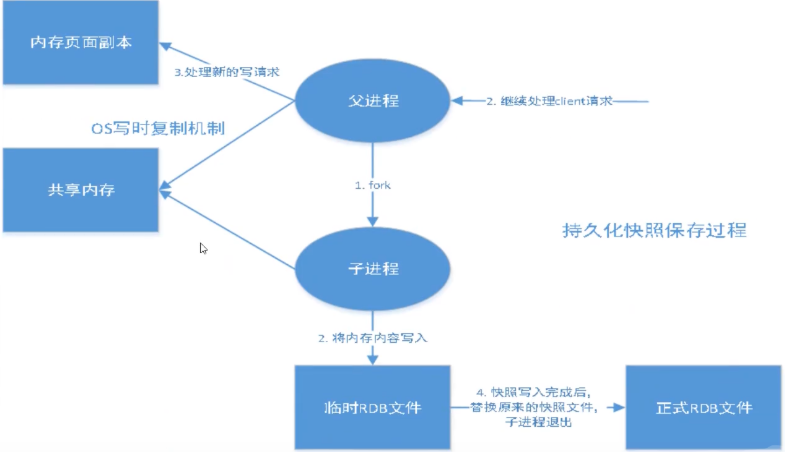
- Write the data set Snapshot in memory to disk within the specified time interval, that is, the professional Snapshot snapshot. When it is restored, it reads the Snapshot file directly into memory.
- Redis will separately create (fork) a sub process for persistence. It will first write the data to a temporary file. After the persistence process is completed, redis will use this temporary file to replace the last persistent file. In the whole process, the main process does not perform any IO operations. This ensures extremely high performance. If large-scale data recovery is needed and the integrity of data recovery is not very sensitive, RDB method is more efficient than AOF method. The disadvantage of RDB is that the data after the last persistence may be lost.
- Sometimes in the production environment, we will back up this file
RDB startup mode - save instruction
- command
save
- effect
Manually perform a save operation
127.0.0.1:6379> keys * (empty array) 127.0.0.1:6379> set name 123 OK 127.0.0.1:6379> save OK stay data One will be generated in the directory rdb file [root@maomao data]# ls 6379.log 6380.log dump.rdb We will rdb delete Once in execution save [root@maomao data]# rm -rf dump.rdb [root@maomao data]# ls 6379.log 6380.log 127.0.0.1:6379> set user maomao OK 127.0.0.1:6379> save OK Generated again dump.rdb [root@maomao data]# ls 6379.log 6380.log dump.rdb
save instruction related configuration
- dbfilename dump.rdb
Note: set the local database file name. The default value is dump rdb
Experience: usually set to dump port number rdb - dir
Description: set storage Path to rdb file
Experience: it is usually set in the directory with large storage space, and the directory name is data - rdbcompression yes
Note: set whether to compress data when stored in the local database. The default is yes and LZF compression is adopted
Experience: it is usually on by default. If it is set to no, it can save CPU running time, but it will make the stored files larger (huge) - rdbchecksum yes
Note: set whether to perform RDB file format verification. The verification process is carried out in the process of writing and reading files
Experience: it is usually on by default. If it is set to no, it can save about 10% of the time consumption of the reading and writing process, but there is a certain risk of data damage
configuration file
dbfilename dump-6379.rdb # Change the rdb file name to the port number rdbcompression yes # Turn on compression rdbchecksum yes # Turn on verification Restart the service and write a script to facilitate startup #!/bin/bash read -p 'Please enter the you want to start redis Port:' port /usr/local/bin/redis-server /usr/local/bin/redis_config/redis-$port.conf /usr/local/bin/redis-cli -p $port [root@maomao bin]# bash qidong.sh Please enter the you want to start redis Port: 6379 127.0.0.1:6379> 127.0.0.1:6379> keys * (empty array) 127.0.0.1:6379> set name zhu OK 127.0.0.1:6379> set age 18 OK 127.0.0.1:6379> save OK 127.0.0.1:6379> set gender nan OK [root@maomao data]# ls # With the newly renamed rdb file 6379.log 6380.log dump-6379.rdb
data recovery
Test whether the data can be recovered 127.0.0.1:6379> shutdown not connected> exit [root@maomao bin]# ps -ef |grep redis- root 1667 1507 0 01:15 pts/0 00:00:00 grep --color=auto redis- [root@maomao bin]# bash qidong.sh Please enter the you want to start redis Port: 6379 127.0.0.1:6379> keys * 1) "gender" 2) "name" 3) "age" Data exists!
Trigger mechanism
- When the save rule is satisfied, the rdb rule will be triggered automatically
- Executing the flush command will also trigger our rdb rules
- Exiting redis will also generate rdb files
How the save instruction works
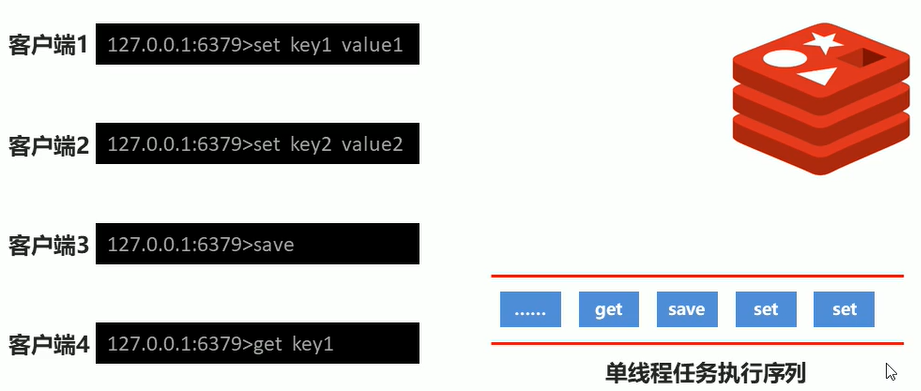
Note: the execution of the save instruction will block the current Redis server until the current RDB process is completed, which may cause long-term blocking. It is not recommended to use it in the online environment
RDB startup mode - bgsave instruction
-
command
bgsave
-
effect
Start the background save operation manually, but not immediately
127.0.0.1:6379> set addr chengdu OK 127.0.0.1:6379> bgsave Background saving started view log cat 6379.log 1671:M 18 Apr 2021 01:23:58.455 * Background saving started by pid 1678 1671:M 18 Apr 2021 01:23:58.482 * Background saving terminated with success
Working principle of bgsave instruction

Note: the bgsave command is optimized for save blocking. All RDB related operations in Redis adopt bgsave, and the Save command can be abandoned.
bgsave instruction related configuration
dbfilename dump-6379.rdb # Change the rdb file name to the port number rdbcompression yes # Turn on compression rdbchecksum yes # Turn on verification stop-write-on-bgsave-error yes # An error occurred. Do you want to stop saving
- stop-write-on-bgsave-error yes
Note: if an error occurs in the background stored procedure, do you want to stop saving
Experience: usually the default is on
RDB automatic execution
save configuration
-
to configure
save second changes
-
effect
If the number of key s changes within a limited time range reaches the specified number, it will be persisted -
parameter
- second: monitoring time range
changes: monitors the change amount of the key
- second: monitoring time range
# save 3600 1 # save 300 100 # save 60 10000 save 60 5 # If the key is modified five times within 60s, rdb operation will be triggered 127.0.0.1:6379> set name mao OK 127.0.0.1:6379> set age 18 OK 127.0.0.1:6379> set gender nv OK 127.0.0.1:6379> set addr chengdu OK 127.0.0.1:6379> set subject python OK [root@maomao data]# ls # rdb file generated 6379.log 6380.log dump-6379.rdb
Within the time range, as long as the set number of key s changes, the system will execute bgsave
save configuration principle
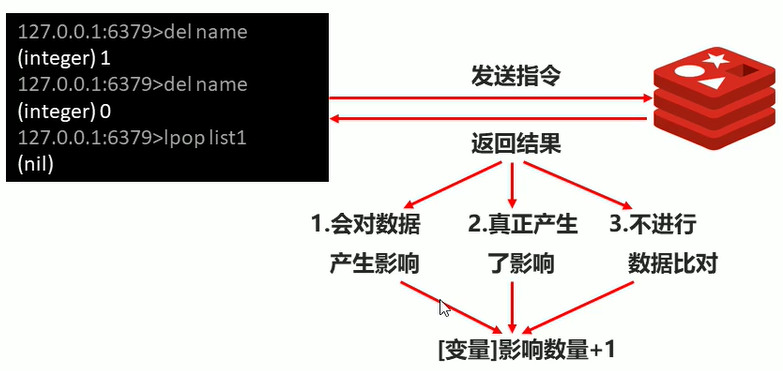
- Instructions that have an impact on the data will not have an impact
- The value in key needs to change
- Without data comparison, if the same value is set twice, the affected quantity will also be + 1
be careful:
- The save configuration should be set according to the actual business situation. If the frequency is too high or too low, performance problems will occur, and the result may be disastrous
- The settings of second and changes in the save configuration usually have complementary correspondence. Try not to set them as inclusive
- The bgsave operation is executed after the save configuration is started
Comparison of three RDB startup modes
| mode | save instruction | bgsave instruction |
|---|---|---|
| Reading and writing | synchronization | asynchronous |
| Blocking client instruction | yes | no |
| Additional memory consumption | no | yes |
| Start a new process | no | yes |
rdb special startup form
- Full replication
Write in master-slave copy
- Restart during server operation
debug reload
- Specify save data when closing the server
shutdown save
By default, the shutdown command is executed automatically
Bgsave (if AOF persistence is not enabled)
Advantages and disadvantages of RDB
RDB benefits
- RDB is a compact compressed binary file with high storage efficiency
- The internal storage of RDB is the data snapshot of redis at a certain point in time, which is very suitable for data backup, full replication and other scenarios
- RDB recovers data much faster than AOF
- Application: execute bgsave backup every X hours in the server, and copy RDB files to remote machines for disaster recovery.
Rdb disadvantages
- RDB mode, whether executing instructions or using configuration, can not achieve real-time persistence, which is likely to lose data
- Each time the bgsave instruction runs, it needs to perform a fork operation to create a child process, sacrificing some performance
- Among many versions of Redis, RDB file format is not unified, which may lead to incompatibility of data formats between various versions of services
AOF
Disadvantages of RDB storage
- The amount of data stored is large and the efficiency is low
- Based on the idea of snapshot, every read and write is all data. When the amount of data is huge, the efficiency is very low
- Low IO performance under large amount of data
- Creating subprocesses based on fork causes additional memory consumption
- Risk of data loss due to downtime
Solution ideas
- Do not write all data, only record some data
- Reduce the difficulty of distinguishing whether the data is changed, and change the recorded data to the recorded operation process
- All operations are recorded to eliminate the risk of data loss
What is AOF
- AOF(append only file) persistence: record each write command in an independent log, and re execute the command in the AOF file when restarting
Achieve the purpose of restoring data. Compared with RDB, it can be simply described as the process of changing recorded data to recorded data generation - The main function of AOF is to solve the real-time of data persistence. At present, it has become the mainstream way of Redis persistence
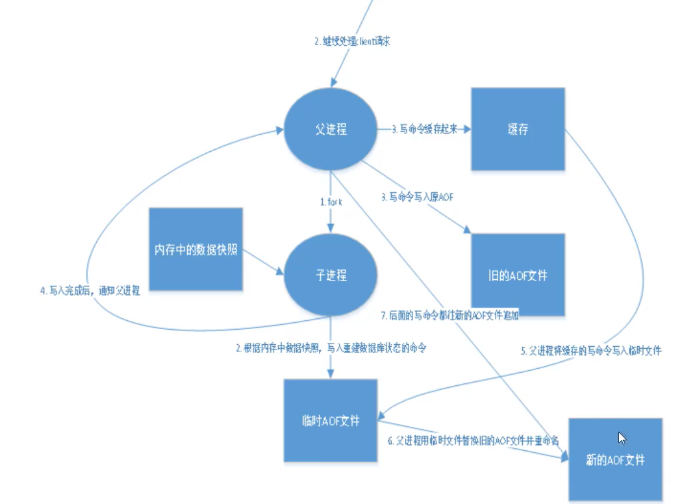
Each write operation is recorded in the form of a log. All instructions executed by redis are recorded (read operations are not recorded). Only files can be added, but files cannot be overwritten. Redis will read the file at the beginning of startup and rebuild the data. In other words, if redis restarts, the write instructions will be executed from front to back according to the contents of the log file to complete the data recovery
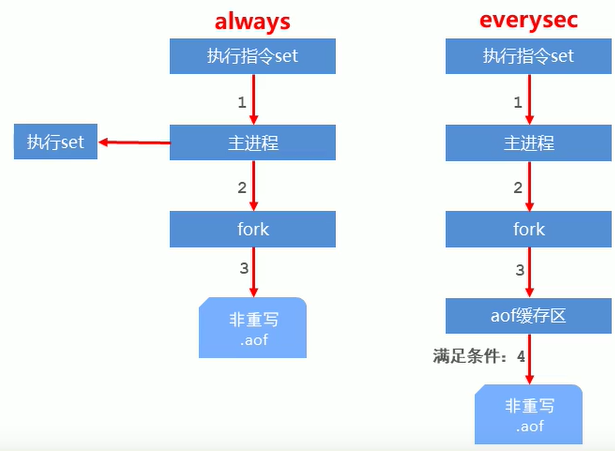
Three AOF write data strategies (appendfsync)
- Always
- Each write operation is synchronized to the AOF file, with zero data error and low performance. It is not recommended
- everysec (per second)
- The instructions in the buffer are synchronized to the AOF file every second, which has high data accuracy and high performance
- Loss of data within 1 second in case of sudden system downtime
- no (system control)
- The operating system controls the cycle of each synchronization to AOF file, and the overall process is uncontrollable
AOF function on
-
to configure
appendonly yes|no
-
effect
Whether to enable the AOF persistence function. It is not enabled by default -
to configure
appendfsync always|everysec|no
-
effect
AOF write data policy
appendonly yes # Enable AOF function appendfilename "appendonly-6379.aof" # File name appendfsync always # Test always first
Test always
127.0.0.1:6379> keys * (empty array) 127.0.0.1:6379> set name zhuer OK 127.0.0.1:6379> lpush list a b c d e (integer) 5 There it is aof file [root@maomao data]# ls 6379.log 6380.log appendonly-6379.aof dump-6379.rdb see [root@maomao data]# cat appendonly-6379.aof *2 $6 SELECT $1 0 *3 $3 set $4 name $5 zhuer *7 $5 lpush $4 list $1 a $1 b $1 c $1 d $1 e
Test everysec
vim redis-6379.conf appendfsync everysec [root@maomao bin]# bash qidong.sh Please enter the you want to start redis Port: 6379 127.0.0.1:6379> set abc abc OK see aof file $3 abc $3 abc Persistence success
AOF rewrite
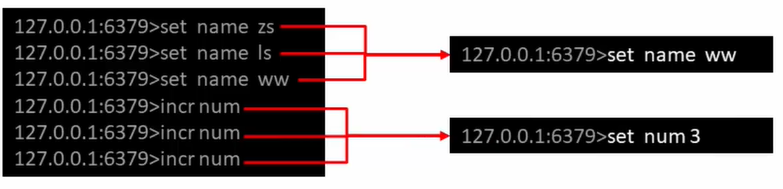
As commands continue to write to AOF, the file will become larger and larger. In order to solve this problem, Redis has introduced AOF rewriting mechanism to compress the file volume. Aof file redo
Write is the process of converting data in Redis process into write commands and synchronizing them to new AOF files. In short, it is to convert the execution results of several commands on the same data into the instructions corresponding to the final result data for recording.
AOF rewriting
- Reduce disk usage and improve disk utilization
- Improve persistence efficiency, reduce persistence write time and improve IO performance
- Reduce data recovery time and improve data recovery efficiency
AOF rewrite rule
- The data that has timed out in the process is no longer written to the file
- Ignore the invalid instructions and use the in-process data to generate directly during rewriting, so that the new AOF file only retains the write command of the final data
- Such as del key1, hdel key2, srem key3, set key4 111, set key4 222, etc
- Multiple write commands for the same data are combined into one command
- For example, lpush list1 a, lpush list1 b and lpush list1 c can be transformed into: lpush list1 a b c.
- In order to prevent client buffer overflow caused by excessive data volume, each instruction can write up to 64 elements for list, set, hash, zset and other types
AOF rewrite mode
-
Manual override
bgrewriteaof
-
Auto rewrite
auto-aof-rewrite-min-size size
auto-aof-rewrite-percentage percentage
Modify profile appendfsync always appendfilename "appendonly-6379.aof" Delete previous data [root@maomao data]# ls 6379.log 6380.log appendonly-6379.aof dump-6379.rdb [root@maomao data]# rm -rf appendonly-6379.aof [root@maomao data]# rm -rf dump-6379.rdb start-up redis 127.0.0.1:6379> set name a OK 127.0.0.1:6379> set name b OK 127.0.0.1:6379> set name c OK 127.0.0.1:6379> get name "c" 127.0.0.1:6379> lpush list a (integer) 1 127.0.0.1:6379> lpush list b (integer) 2 127.0.0.1:6379> lpush list c (integer) 3 see aof file set $4 name $1 a *3 $3 set $4 name $1 b *3 $3 set $4 name $1 c $5 lpush $4 list $1 a *3 $5 lpush $4 list $1 b *3 $5 lpush $4 list $1 c *2 $3 del $4 name rewrite 127.0.0.1:6379> bgrewriteaof View again aof file *2 $6 SELECT $1 0 *3 $3 SET $4 name $3 c RPUSH $5 list $1 c $1 b $1 a
After rewriting, the file size becomes smaller and useless instructions are ignored

AOF auto rewrite mode
-
Auto override trigger condition setting

-
Automatically rewrite trigger comparison parameters (run the instruction info Persistence to obtain specific information)

-
Auto override trigger condition

auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb If aof File greater than 64 m,It's too big! fork A new process is to rewrite our files
AOF workflow
rewrite
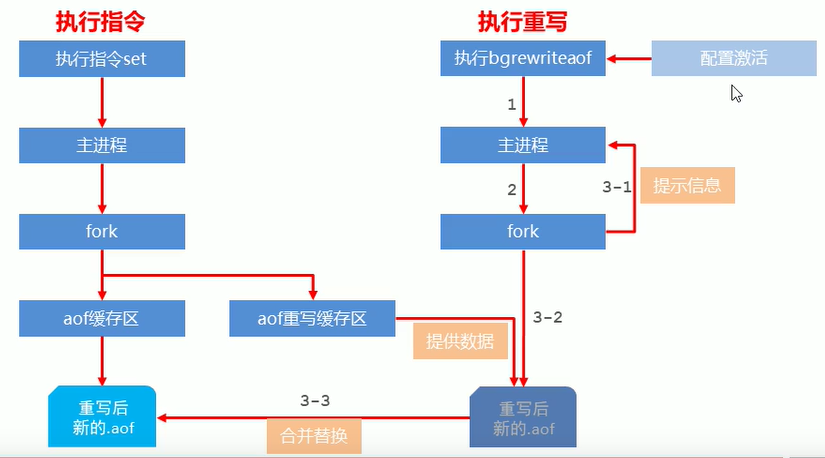
The AOF buffer synchronization file policy is controlled by the parameter appendfsync
- Description of system call write and fsync:
- The write operation will trigger the delayed write mechanism. Linux provides a page buffer in the kernel to improve the IO performance of the hard disk. The write operation returns directly after writing to the system buffer. Synchronous hard disk operation depends on the system scheduling mechanism, such as the buffer page space is full or reaches a specific time period. Before synchronizing files, if the system fails and goes down at this time, the data in the buffer will be lost.
- fsync enforces hard disk synchronization for single file operations (such as AOF files). fsync will block and return after writing to the hard disk to ensure data persistence.
- In addition to write, fsync and Linx, sync and fdatasync operations are also provided
Difference between RDB and AOF
| Persistence mode | RDB | AOF |
|---|---|---|
| Occupied storage space | Small (data level: compression) | Large (instruction level: override) |
| Storage speed | slow | fast |
| Recovery speed | fast | slow |
| Data security | Data will be lost | Determined by strategy |
| resource consumption | High / heavyweight | Low / lightweight |
| boot priority | low | high |
Selection of RDB and AOF
- It is very sensitive to data. It is recommended to use the default AOF persistence scheme
- The AOF persistence policy uses everysecond, fsync every second. With this strategy, redis can still maintain good processing performance. When a problem occurs, data within 0-1 seconds will be lost at most.
- Note: due to the large storage volume of AOF files and slow recovery speed
- For the validity of data presentation phase, it is recommended to use RDB persistence scheme
- The data can be well maintained without loss in the stage (this stage is manually maintained by developers or operation and maintenance personnel), and the recovery speed is fast. RDB scheme is usually adopted for stage point data recovery
- Note: using RDB to realize compact data persistence will make Redis drop very low
- Comprehensive comparison
- The choice between RDB and AOF is actually a trade-off. Each has advantages and disadvantages
- If you can't bear the loss of data within a few minutes and are very sensitive to business data, choose AOF
- If you can withstand data loss within a few minutes and pursue the recovery speed of large data sets, RDB is selected
- RDB is selected for disaster recovery
- Double insurance strategy, enable RDB and AOF at the same time. After restart, Redis gives priority to using AOF to recover data and reduce the amount of lost data