Sentinel sentinel mechanism of Master automatic election
In the master/slave mode mentioned earlier, in a typical one master multi-slave system, slave plays the role of redundant data backup and separation of read and write in the whole system. When the master encounters an abnormal terminal, the developer can manually select a slave database to upgrade to the master, so that the system can continue to provide services. Then this process needs manual intervention, which is more troublesome; redis does not provide the function of automatic master election, but needs to be monitored with the help of a sentry.
1. What is a sentry
As the name suggests, the role of Sentry is to monitor the operation of Redis system. Its functions include two
- Monitor whether the master and slave are running normally
- When the master fails, the slave database is automatically upgraded to master
Sentinel is an independent process. The architecture after using sentinel is shown in the figure below. At the same time, in order to ensure the high availability of sentinel, we will make cluster deployment for sentinel. Therefore, sentinel will not only monitor all master-slave nodes of Redis, but also monitor each other.
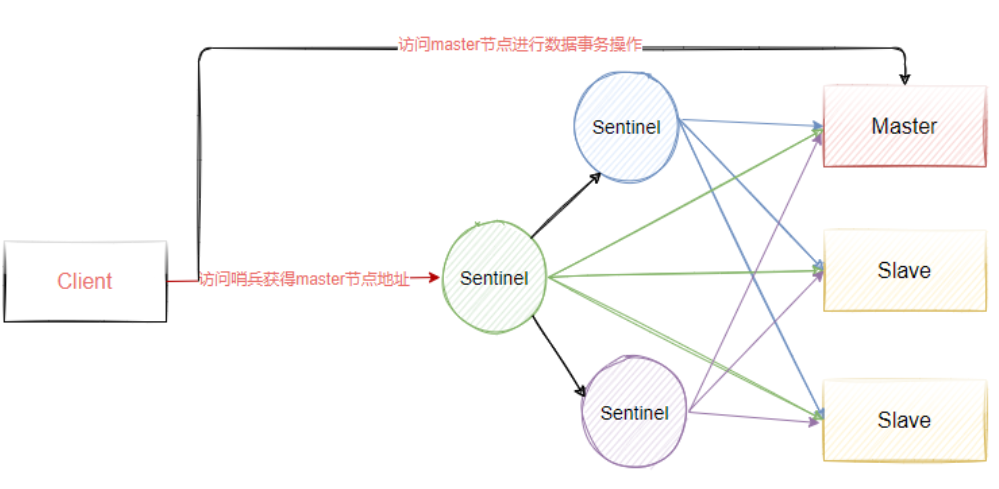
2. Configure sentinel cluster
Based on the previous master-slave replication, three sentinel nodes are added to realize the function of master election in redis.
- 192.168.183.130(sentinel )
- 192.168.183.131(sentinel )
- 192.168.183.132(sentinel )
sentinel Sentry is configured as follows:
- Copy the sentinel.conf file from the redis source package to the redis/bin installation directory
cp sentinel.conf /usr/local/redis/bin/sentinel.conf
- Modify the following configuration
# Where name refers to the name of the master to be monitored. The name is self-defined. ip and port refer to the ip and port number of the master. The last 2 represents the minimum number of votes, that is, at least several sentinel nodes need to think that the master is offline before it is really offline sentinel monitor mymaster 192.168.183.130 6379 2 sentinel down-after-milliseconds mymaster 5000 # Indicates that if mymaster does not respond within 5s, it is considered SDOWN sentinel failover-timeout mymaster 15000 # It means that if mysaster still doesn't live after 15 seconds, start failover and upgrade one of the remaining slave to master logfile "/usr/local/redis/logs/sentinels.log" # Files need to be created in advance
- Start sentinel with the following command
./redis-sentinel sentinel.conf
- After successful startup, get the following information, indicating that the sentinel is started successfully and starts monitoring the cluster nodes
127461:X 27 Nov 2021 19:30:51.035 # +sdown sentinel f40bd964ad08ae0665f9644e4f372082726a8bf0 192.168.183.131 26379 @ mymaster 192.168.183.130 6379 34322:X 27 Nov 2021 19:31:02.189 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 34322:X 27 Nov 2021 19:31:02.189 # Redis version=5.0.3, bits=64, commit=00000000, modified=0, pid=34322, just started 34322:X 27 Nov 2021 19:31:02.189 # Configuration loaded 34323:X 27 Nov 2021 19:31:02.205 * Running mode=sentinel, port=26379. 34323:X 27 Nov 2021 19:31:02.205 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128. 34323:X 27 Nov 2021 19:31:02.205 # Sentinel ID is 978f5f62b49eed8795e05f8ea8cb8472a922c473 34323:X 27 Nov 2021 19:31:02.205 # +monitor master mymaster 192.168.183.130 6379 quorum 2
The configuration of the other two nodes is exactly the same as the above. Just monitor the master node. Mainly, the ip of the master node in the sentinel.conf file must not be 127.0.0.1, otherwise other sentinel nodes cannot communicate with it
When other sentinel sentinel nodes are started, the first started sentinel node will also output the following log, indicating that other sentinel nodes have joined.
34323:X 27 Nov 2021 19:31:32.246 # +sdown sentinel e027f28d80277b6d626ea6251a3f6a263dc96f11 192.168.183.132 26379 @ mymaster 192.168.183.130 6379 34323:X 27 Nov 2021 19:31:32.247 # +sdown sentinel f40bd964ad08ae0665f9644e4f372082726a8bf0 192.168.183.131 26379 @ mymaster 192.168.183.130 6379
Related questions:
- You may encounter insufficient allowed links, which can be solved by the following methods;
#View system limits [root@centos224]# ulimit -a #Set the number of "open files" [root@centos224]# ulimit -n 10032
- When setting the log path, you need to create the path in advance, otherwise it will fail to start.
3. Simulate master node failure
We directly copy the master node of the redis master-slave cluster and stop it with the. / redis cli shutdown command. Then we observe the logs of the three sentinel sentinels. First, we look at the sentinel logs of the first sentinel, and get the following results.
34323:X 27 Nov 2021 19:34:53.843 # +new-epoch 1 34323:X 27 Nov 2021 19:34:53.845 # +vote-for-leader f40bd964ad08ae0665f9644e4f372082726a8bf0 1 34323:X 27 Nov 2021 19:34:53.861 # +odown master mymaster 192.168.183.130 6379 #quorum 3/2 34323:X 27 Nov 2021 19:34:53.862 # Next failover delay: I will not start a failover before Sat Nov 27 19:40:54 2021 34323:X 27 Nov 2021 19:34:54.106 # +config-update-from sentinel f40bd964ad08ae0665f9644e4f372082726a8bf0 192.168.183.131 26379 @ mymaster 192.168.183.130 6379 34323:X 27 Nov 2021 19:34:54.107 # +switch-master mymaster 192.168.183.130 6379 192.168.183.132 6379 34323:X 27 Nov 2021 19:34:54.107 * +slave slave 192.168.183.131:6379 192.168.183.131 6379 @ mymaster 192.168.183.132 6379 34323:X 27 Nov 2021 19:34:54.107 * +slave slave 192.168.183.130:6379 192.168.183.130 6379 @ mymaster 192.168.183.132 6379 34323:X 27 Nov 2021 19:35:24.138 # +sdown slave 192.168.183.130:6379 192.168.183.130 6379 @ mymaster 192.168.183.132 6379
+sdown indicates that the sentinel subjectively thinks that the master has stopped serving.
+odown said that the sentinel objectively believed that the master stopped serving.
Then the sentinel starts fault recovery, selects a slave to upgrade to master, and logs of other sentinel nodes.
21754:X 27 Nov 2021 19:34:53.731 # +sdown master mymaster 192.168.183.130 6379 21754:X 27 Nov 2021 19:34:53.833 # +odown master mymaster 192.168.183.130 6379 #quorum 2/2 21754:X 27 Nov 2021 19:34:53.833 # +new-epoch 1 21754:X 27 Nov 2021 19:34:53.833 # +try-failover master mymaster 192.168.183.130 6379 21754:X 27 Nov 2021 19:34:53.836 # +vote-for-leader f40bd964ad08ae0665f9644e4f372082726a8bf0 1 21754:X 27 Nov 2021 19:34:53.843 # beb6d7194480914f61d81d7624b07c1484697f66 voted for f40bd964ad08ae0665f9644e4f372082726a8bf0 1 21754:X 27 Nov 2021 19:34:53.843 # 978f5f62b49eed8795e05f8ea8cb8472a922c473 voted for f40bd964ad08ae0665f9644e4f372082726a8bf0 1 21754:X 27 Nov 2021 19:34:53.891 # +elected-leader master mymaster 192.168.183.130 6379 21754:X 27 Nov 2021 19:34:53.892 # +failover-state-select-slave master mymaster 192.168.183.130 6379 21754:X 27 Nov 2021 19:34:53.963 # +selected-slave slave 192.168.183.132:6379 192.168.183.132 6379 @ mymaster 192.168.183.130 6379 21754:X 27 Nov 2021 19:34:53.963 * +failover-state-send-slaveof-noone slave 192.168.183.132:6379 192.168.183.132 6379 @ mymaster 192.168.183.130 6379 21754:X 27 Nov 2021 19:34:54.041 * +failover-state-wait-promotion slave 192.168.183.132:6379 192.168.183.132 6379 @ mymaster 192.168.183.130 6379 21754:X 27 Nov 2021 19:34:54.052 # +promoted-slave slave 192.168.183.132:6379 192.168.183.132 6379 @ mymaster 192.168.183.130 6379 21754:X 27 Nov 2021 19:34:54.052 # +failover-state-reconf-slaves master mymaster 192.168.183.130 6379 21754:X 27 Nov 2021 19:34:54.101 * +slave-reconf-sent slave 192.168.183.131:6379 192.168.183.131 6379 @ mymaster 192.168.183.130 6379 21754:X 27 Nov 2021 19:34:54.953 # -odown master mymaster 192.168.183.130 6379 21754:X 27 Nov 2021 19:34:55.105 * +slave-reconf-inprog slave 192.168.183.131:6379 192.168.183.131 6379 @ mymaster 192.168.183.130 6379 21754:X 27 Nov 2021 19:34:55.105 * +slave-reconf-done slave 192.168.183.131:6379 192.168.183.131 6379 @ mymaster 192.168.183.130 6379 21754:X 27 Nov 2021 19:34:55.163 # +failover-end master mymaster 192.168.183.130 6379 21754:X 27 Nov 2021 19:34:55.163 # +switch-master mymaster 192.168.183.130 6379 192.168.183.132 6379 21754:X 27 Nov 2021 19:34:55.163 * +slave slave 192.168.183.131:6379 192.168.183.131 6379 @ mymaster 192.168.183.132 6379 21754:X 27 Nov 2021 19:34:55.163 * +slave slave 192.168.183.130:6379 192.168.183.130 6379 @ mymaster 192.168.183.132 6379
+Try failover indicates that the sentinel begins to recover from the failure
+Failover end indicates that the sentinel has completed failure recovery
+Slave means to list new masters and slave servers. We can still see the stopped masters. The sentry does not clear the stopped service instances. This is because the stopped servers may be restored at some time. After restoration, they will join the whole cluster as slave.
4. Implementation principle
1) : each Sentinel sends a PING command once per second to the Master/Slave and other Sentinel instances it knows
2) : if the time between the last valid reply to the PING command and an instance exceeds the value specified by the down after milliseconds option, the instance will be marked as offline by Sentinel.
3) : if a Master is marked as subjective offline, all sentinels monitoring the Master should confirm that the Master has indeed entered the subjective offline state once per second.
4) : when a sufficient number of sentinels (greater than or equal to the value specified in the configuration file: quorum) confirm that the Master has indeed entered the subjective offline state within the specified time range, the Master will be marked as objective offline.
5) : in general, each Sentinel will send INFO commands to all known masters and Slave every 10 seconds
6) : when the Master is marked as offline objectively by Sentinel, the frequency of INFO commands sent by Sentinel to all Slave of the offline Master will be changed from once every 10 seconds to once per second. If there is not enough Sentinel consent that the Master has been offline, the objective offline status of the Master will be removed.
8) : if the Master returns a valid reply to Sentinel's PING command again, the Master's subjective offline status will be removed.
**Subjective offline: * * Subjectively Down, SDOWN for short, refers to the offline judgment made by the current Sentinel instance on a redis server.
**Objective offline: * * Objectively Down, referred to as ODOWN for short, means that multiple sentinel instances make SDOWN judgment on the Master Server and obtain the judgment of Master offline through communication between sentinel. Then start failover recovery.
5. Who will complete the failover?
When the master node in redis is judged to be offline objectively, it is necessary to re select one from the slave node as the new master node. Now there are three sentinel nodes. Who should complete the failover process? Therefore, the three sentinel nodes must reach an agreement through some mechanism, and the Raft algorithm is adopted in redis to realize this function.
Every time the master fails, the raft algorithm will be triggered to select a leader to complete the master election function in the redis master-slave cluster.
5.1 data consistency
Before we understand the raft algorithm, let's look at a Byzantine general problem.
Byzantine failures is a basic problem in point-to-point communication proposed by Leslie Lambert. The specific meaning is that it is impossible to achieve consistency through message transmission on the unreliable channel with message loss.
Byzantium, located in Istanbul, Turkey, is the capital of the Eastern Roman Empire. At that time, the Byzantine Roman Empire had a vast territory. In order to achieve the purpose of defense, each army was far apart. Generals and generals could only send messages by messenger. During the war, all the generals and adjutants in the Byzantine army must reach a consensus to decide whether there is a chance to win before they attack the enemy's camp. However, there may be traitors and enemy spies in the army, which will influence the decisions of the generals and disrupt the order of the whole army. When consensus is reached, the results do not represent the views of the majority. At this time, when it is known that some members have rebelled, how the other loyal generals reach an agreement without being influenced by traitors is the famous Byzantine problem.
The Byzantine general problem essentially describes a protocol problem in the computer field. The generals of the Byzantine imperial army must unanimously decide whether to attack an enemy. The problem is that these generals are geographically separated and there are traitors among them. Traitors can act at will to achieve the following goals:
- Deceive some generals into offensive action;
- Facilitate a decision that not all generals agree, such as an offensive action when generals do not want to attack;
- Or confuse some generals so that they can't make a decision.
If the traitor achieves one of these goals, the result of any attack is doomed to failure, and only the efforts of complete agreement can win.
Byzantine hypothesis is a model of the real world. Due to hardware errors, network congestion or disconnection and malicious attacks, computers and networks may have unpredictable behavior. Therefore, how to achieve consistency in such an environment is the so-called data consistency problem.
Back to Sentinel, for the three Sentinel nodes, you need to select a node to be responsible for fault recovery for the redis cluster. Who among the three nodes can do this? Therefore, it is also necessary to reach a consensus based on a certain mechanism.
Data consistency algorithms need to be used in many middleware. The most intuitive component is a component like zookeeper. Its high availability design is composed of leader and follow. When the leader node goes down abnormally, a new leader node needs to be elected from the following node, then the election process needs to be agreed by all nodes in the cluster, That is, only when all nodes agree that a follow node becomes a leader can it become a leader node. The premise of this consensus is that all nodes need to reach an agreement on a voting result, otherwise they will not be able to elect a new leader. Therefore, consensus algorithm must be used here.
5.2 common data consistency algorithms
- paxos, paxos should be the earliest and most orthodox data consistency algorithm, and it is also the most complex algorithm.
- Raft, raft algorithm should be the most easy to understand consistency algorithm. It is used in nacos, sentinel, consumer and other components.
- zab protocol is a consistency algorithm evolved from paxos algorithm in zookeeper
- Distro, distro protocol. Distro is a private agreement of Alibaba. At present, the popular Nacos service management framework adopts distro protocol. Distro protocol is positioned as a consistency protocol for temporary data
5.3 Raft protocol description
Raft algorithm animation demonstration address: http://thesecretlivesofdata.com/raft/
The core idea of Raft algorithm: first come, first served, and the minority obeys the majority.
5.4 failover process
How to make an original slave node the master node?
- After the Sentinel Leader is selected, the Sentinel Leader sends the slave of no one command to a node to make it an independent node.
- Then send replicaof x.x.x.x xxxx (native service) to other nodes to make them child nodes of this node, and the failover is completed.
How to select the appropriate slave node to become the master? There are four factors.
- The duration of disconnection. If the connection with the sentry is disconnected for a long time and exceeds a certain threshold, the right to vote will be lost directly
- Priority ranking. If you have the right to vote, it depends on who has the highest priority. This can be set in the configuration file (replica priority 100). The smaller the value, the higher the priority
- The number of copies, if the priority is the same, depends on who copies the most data from the master (the largest copy offset)
- Process id. if the number of copies is the same, select the one with the smallest process id
5.5 Sentinel function summary
Monitoring: Sentinel will constantly check whether the master server and slave server are running normally.
Notification: Sentinel can send a notification through the API if a monitored instance has a problem.
Automatic failover: Sentinel can start the failover process if the primary server fails. Upgrade a server to the primary server and issue a notification.
Configuration management: the client connects to Sentinel and obtains the address of the current Redis master server.